Summary
Encoder-Decoderモデルが具体的に何を学習しているのかを、品詞タグ付け(POS)と形態素分類(Morphology)の観点から調査した。
また、調査対象のEncoder-Decoderモデルは以下の2種類とした。
- RNN based seq2seq[Luong+15]・・・単語単位
- CNN with highway network over charactesr[Kim+15]・・・文字単位
結論は以下の通り。
- 文字単位の表現は単語単位の表現よりもPOS/Morphology/MTのタスクで優れた成果を挙げた
- 低次の層は単語の文法的な構造を学習し、高次の層は意味を学習する
- MTとPOS/Morphologyの質はそれぞれ独立している
- AttentionはEncoderの表現を大きく改善するが、Decoderに与える影響は少ない
Data
IWSLT2016で提供されたTED talksのパラレルコーパスを用いる。
タグ付けは以下のツールを使用した。
| 言語 | ツール |
|---|---|
| Arabic | MADAMIRA[Pasha+14] |
| Czech | Tree-Tagger[Schmid94] |
| French | Tree-Tagger[Schmid94] |
| German | LoPar[Schmid00] |
| English | MXPOST[Ratnaparkhi96] |
Model Settings
RNNベースのモデルでは、seq2seq-attnの実装を用いた2層のLSTMからなるEncoder-Decoderモデルを使用した。LSTMのセルと埋め込み層は500次元で、学習係数の初期値は1.0、減衰値0.5のSGDを用い、dropoutは0.3を用いた。
訓練は20エポック行い、validation lossが最も低かったモデルを利用した。
また、PoS/Mophological classifierのタスクでは、MTタスクで学習した隠れ層のうちのひとつを取り出し、一層のFFNNとreluを接続してclassifierを作成した。
Evaluation
Effect of word representation
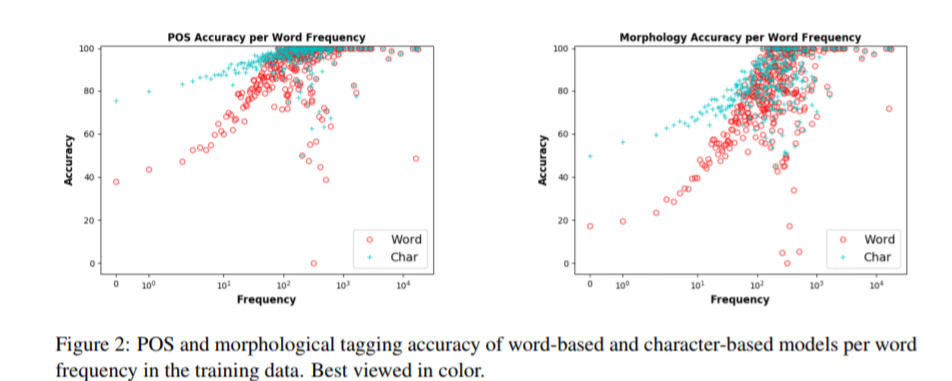
POSにおいても、Morphologyにおいても、単語単位よりも文字単位の方がよい正答率であった。
Impact of word frequency, Analyzing specific tags
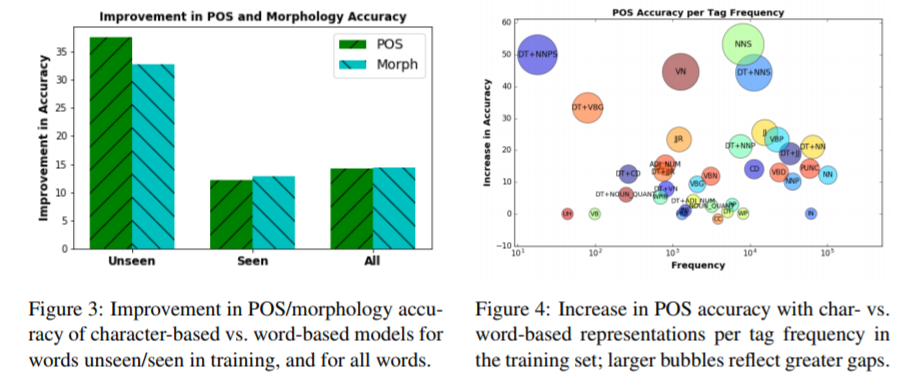
単語単位から文字単位に切り替えた際に特に改善した点として、未知語(Out Of Vocabulary words)や複数形名詞(NNS, DT+NNS)のケースが挙げられる。
Effect of encoder depth
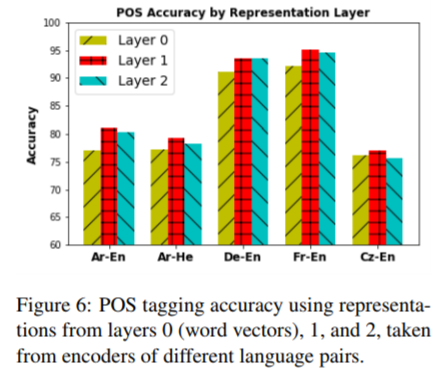
layer0(word embedding layer)とlayer1, layer2を比較したところ、最も低次のLSTM層であるlayer1の特徴が他の層よりも良い正答率を示した。
これは、RNNにおいて低次の層が文法を学習し、高次の層は文法ではない要素(意味表現)を学習するためだと考えられる。
Effect of target language
ひとつの単語が多様な変化をする言語(morphologically-rich languages, i.e. Arabic)の翻訳に焦点を当て、目的言語が原言語の特徴の学習にどういった影響を与えるのかを調べた。
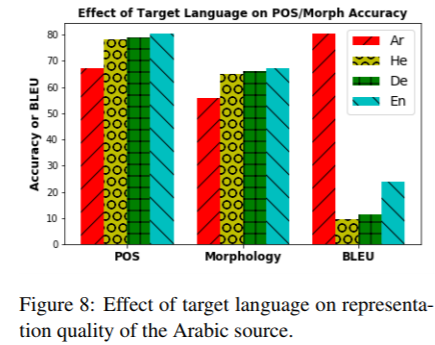
原言語をArabicで固定したとき、目的言語をArabic/English/Hebrew/GermanにしてPOS/Morphology/MTの3タスクを行い評価を行ったところ、ArabicのBLEUが最も良いのに対し、ArabicのPOS/Morphologyは多言語よりも低かった。
このことから、翻訳の質には品詞の情報は不要であること、原言語と目的言語が同一である(あるいは、似通っている?)場合には品詞や形態素の推定に必要な情報が十分に得られないことがわかった。
Effect of attntion
Attentionのあるモデルとないモデルで比較したとき、Encoderの表現を使ったPOS AccuracyはDecoderの表現を使った場合に比べて著しく悪く、Attentionの影響が強いと考察される。
Effect of word representation
基本的に、文字単位のモデルから得た特徴は単語単位から得た特徴よりも優れた成果を示したが、Engllish-to-ArabicのMTにおいては単語単位の方が高いBLEUスコアを示した。
これは、文字単位のものでは未知語が多く出現しやすいためだと思われる。
References
- What do Neural Machine Translation Models Learn about Morphology?[Belinkov+17]
- Effective Approaches to Attention-based Neural Machine Translation[Luong+15]
- MADAMIRA: A Fast, Comprehensive Tool
for Morphological Analysis and Disambiguation of Arabic[Pasha+14] - Probabilistic Part-of-Speech Tagging Using Decision Trees[Schmid94]
- LoPar: Design and Implementationp[Schmid00]
- A Maximum Entropy Model for Part-Of-Speech Tagging[Ratnaparkhi96]