これは何?
OpenID Connectで使われるIDトークンJWTについて調べたことをまとめました。
結論だけ知りたい人向け↓
cat jwt_sample.txt
eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJzdWIiOiIxMjM0NTY3ODkwIiwibmFtZSI6IkpvaG4gRG9lIiwiaWF0IjoxNTE2MjM5MDIyfQ.SflKxwRJSMeKKF2QT4fwpMeJf36POk6yJV_adQssw5c
awk -F "." '{print $2}' jwt_sample.txt | sed 's/-/+/g; s/_/\//g' | awk '{ l=length($0) % 4; if (l > 0) printf "%s%s", $0, substr("==", 1, l); else print $0 }' | base64 -d
JWTとは
OpenID Connectで使用されるIDトークンの形式です。RFC7519で定義されています。
JWTの形式
-
- .区切りの3パートで構成される。
- ヘッダ: 署名に使われるアルゴリズムなど
- ペイロード: IDトークンの発行者,IDトークンを受け取るリライングパーティのクライアントID,エンドユーザ識別子(sub),JWTの発行時刻,IDトークンの有効期限,nonceが含まれる
- 署名: ヘッダとペイロードに対してBase64URLエンコードしたものをヘッダで決められたアルゴリズムでハッシュ化したものを再度Base64URLエンコードしたもの。
JWTのデコードサイトでデコードしてみる
自分は普段は[jwt.io](https://jwt.io]を使って普段はデコードしています。
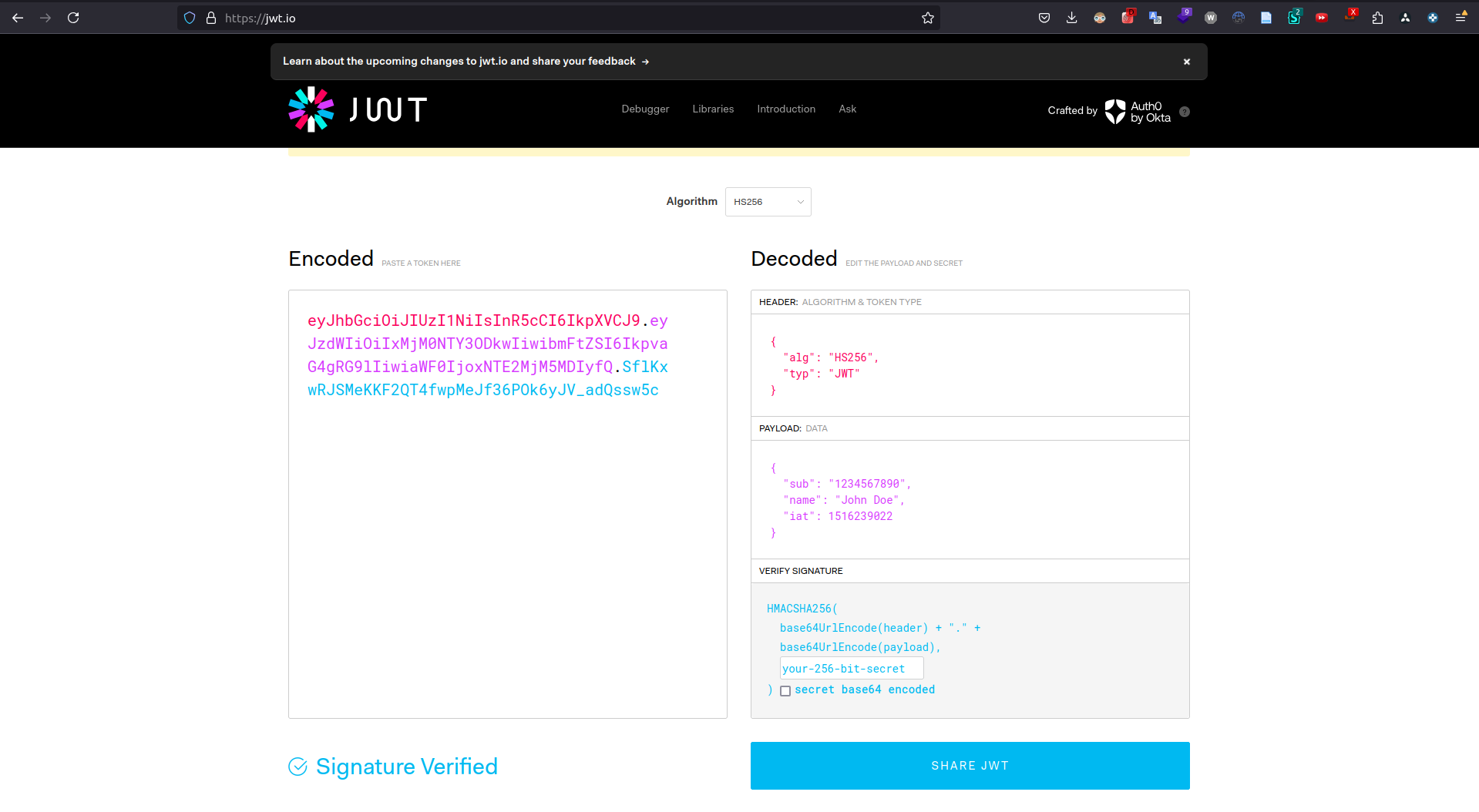
自分でやってみてハマったところ
RFC 7519 7-2
をざっくり見た感じだと普通に区切りで分割して,base64でデコードすればよいのでは?と思っていました。しかし,たまにうまくいかないケースがでてきました。
cat jwt_sample.txt
eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJzdWIiOiIxMjM0NTY3ODkwIiwibmFtZSI6IkpvaG4gRG9lIiwiaWF0IjoxNTE2MjM5MDIyfQ.SflKxwRJSMeKKF2QT4fwpMeJf36POk6yJV_adQssw5c
awk -F "." '{print $2}' jwt_sample.txt | base64 -d
{"sub":"1234567890","name":"John Doe","iat":1516239022}base64: invalid input
それっぽくできているのですが,invalid inputがでています。
原因1 base64とbase64urlは別物であった
このあたりの差分について書いてある記事があったので貼っておきます。
厳密に定義を確認したい方は,RFC4618を参照してください。
Table 1: The Base 64 Alphabet Value Encoding Value Encoding Value Encoding Value Encoding 0 A 17 R 34 i 51 z 1 B 18 S 35 j 52 0 2 C 19 T 36 k 53 1 3 D 20 U 37 l 54 2 4 E 21 V 38 m 55 3 5 F 22 W 39 n 56 4 6 G 23 X 40 o 57 5 7 H 24 Y 41 p 58 6 8 I 25 Z 42 q 59 7 9 J 26 a 43 r 60 8 10 K 27 b 44 s 61 9 11 L 28 c 45 t 62 + 12 M 29 d 46 u 63 / 13 N 30 e 47 v 14 O 31 f 48 w (pad) = 15 P 32 g 49 x 16 Q 33 h 50 y
Table 2: The "URL and Filename safe" Base 64 Alphabet Value Encoding Value Encoding Value Encoding Value Encoding 0 A 17 R 34 i 51 z 1 B 18 S 35 j 52 0 2 C 19 T 36 k 53 1 3 D 20 U 37 l 54 2 4 E 21 V 38 m 55 3 5 F 22 W 39 n 56 4 6 G 23 X 40 o 57 5 7 H 24 Y 41 p 58 6 8 I 25 Z 42 q 59 7 9 J 26 a 43 r 60 8 10 K 27 b 44 s 61 9 11 L 28 c 45 t 62 - (minus) 12 M 29 d 46 u 63 _ 13 N 30 e 47 v (underline) 14 O 31 f 48 w 15 P 32 g 49 x 16 Q 33 h 50 y (pad) =
base64で使用している+と/がurlで使えないため,base64でエンコード後に-と_置換したものがbase64urlらしいです。
awk -F "." '{print $2}' jwt_sample.txt | sed 's/-/+/g; s/\_/\//g' | base64
-d
{"sub":"1234567890","name":"John Doe","iat":1516239022}base64: invalid input
あれまだうまくいかない...
原因2: =パディング
base64ではエンコードした文字列に対して特定の条件の場合に末尾に=をつけるケースがあるようです。
以下はRFC 4648より。
Special processing is performed if fewer than 24 bits are available at the end of the data being encoded. A full encoding quantum is always completed at the end of a quantity. When fewer than 24 input bits are available in an input group, bits with value zero are added (on the right) to form an integral number of 6-bit groups. Padding at the end of the data is performed using the '=' character. Since all base 64 input is an integral number of octets, only the following cases can arise:
(1) The final quantum of encoding input is an integral multiple of 24 bits; here, the final unit of encoded output will be an integral multiple of 4 characters with no "=" padding.
(2) The final quantum of encoding input is exactly 8 bits; here, the final unit of encoded output will be two characters followed by two "=" padding characters.
(3) The final quantum of encoding input is exactly 16 bits; here, the final unit of encoded output will be three characters followed by one "=" padding character.
ここでutf-8を過程した場合には一文字あたりは8 bitなので
- 文字数を3で割ったあまりが1 --> ==
- 文字数を3で割ったあまりが2 --> =
- 文字数を3で割ったあまりが0 --> パディングなし
echo -n "a" | base64
YQ==
echo -n "ab" | base64
YWI=
echo -n "abc" | base64
YWJj
echo -n "abcd" | base64
YWJjZA==
JWTではこの=paddingを省略しているのが原因でエラーが起こっていそうです。
base64は24 bitを4文字のbase64文字列に変換するので,base64でエンコードされたデータの文字数から適切な=の数をつけてやればよいのです。
awk -F "." '{print $2}' jwt_sample.txt | sed 's/-/+/g; s/_/\//g' | awk '{ l=length($0) % 4; if (l > 0) printf "%s%s", $0, substr("==", 1, l); else print $0 }' | base64 -d
できたー!!
このスクリプトでは= paddingが0,1,2個のどれかしかありえないことを利用して,パースしたJWTの文字列の長さを4で割ったあまりの数=を連結してからbase64でデコードしています。
なので文字列を4で割ったあまりが3になるケースは存在しないはずですが例外処理等は実装していません。
また,JWTの署名部分のデコードは対応外です
次回は,JWTの署名検証をやってみます。