おそらく最後の Drizzle ORM。
テスト用のデータを流し込むシーダーについて。
こちらもちゃんと用意されている。(まだテスト版みたい)
適当にテストデータを作成する
$ npm i drizzle-seed
前の記事で作成した users - posts テーブルについて、データを流し込んでみる。
db/seed.ts
import { reset, seed } from "drizzle-seed"
import * as schema from './schema'
import { db } from '@/db'
async function main() {
await reset(db as any, schema)
await seed(db as any, schema).refine((f) => ({
users: {
count: 5,
with: {
posts: 10
}
}
}))
}
main()
これを tsx で実行する。
$ npx tsx ./db/seed.ts
# 確認する
$ npx drizzle-kit studio
実行時にこのエラーが出てくることがある。
その時は npm i pg をするとよい。
まだテスト版のせいか、PostgreSQL モジュールが必須になってるみたい。
Error: Cannot find module 'pg'
studio で見てみたらこんな感じ!
個数しか指定していないのに、いい感じにデータが流し込めている。すごい。
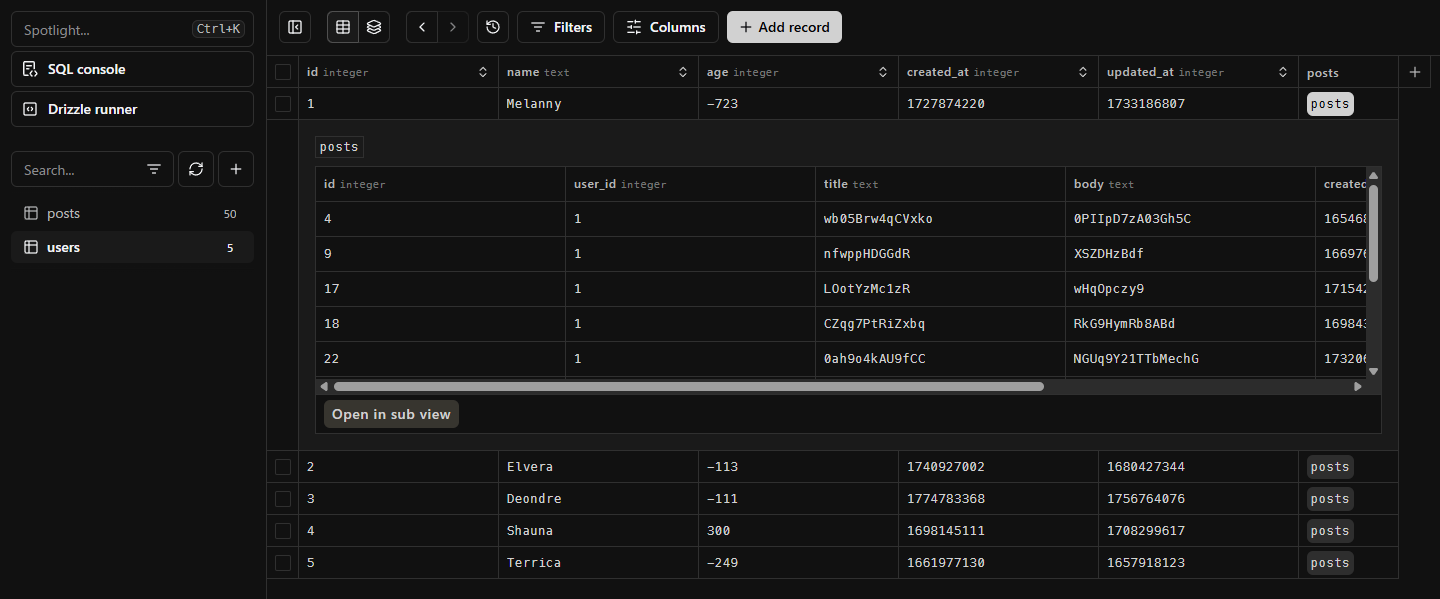
実はもっとハイテクで、疑似乱数ジェネレーターが組み込まれていて、シード値に基づいていい感じにしているみたい。
でも、そこまで細かく使うことはないかなぁ...
Generator と Faker を用いて、適当にテストデータを作成する
標準で int や string、またよく使いそうな値に関して、ランダム生成用の関数が用意されている。
通常の用途ではこれで十分だが、日本語にはまだ対応していないので、有名な faker ライブラリを併用するとよさそう。
$ npm install @faker-js/faker --save-dev
db/seed.ts
import { reset, seed } from "drizzle-seed"
import * as schema from './schema'
import { db } from '@/db'
import { fakerJA } from '@faker-js/faker'
const faker = fakerJA
async function main() {
await reset(db as any, schema)
await seed(db as any, schema).refine((f) => ({
users: {
count: 10,
columns: {
name: f.valuesFromArray({
values: [...Array(100)].map(() => faker.person.fullName()),
isUnique: true,
}),
age: f.weightedRandom([
{
weight: 0.3,
value: f.int({ minValue: 18, maxValue: 30 })
},
{
weight: 0.7,
value: f.int({ minValue: 31, maxValue: 80 })
}
]),
},
},
posts: {
count: 100,
columns: {
userId: f.int({ minValue: 1, maxValue: 10 }),
title: f.valuesFromArray({
values: [...Array(100)].map(() => faker.lorem.sentence()),
isUnique: true,
}),
body: f.valuesFromArray({
values: [...Array(100)].map(() => faker.lorem.paragraph()),
isUnique: true,
}),
}
}
}))
}
main()
まだこのライブラリは SQLite に対応していないみたいなので、db は any で差し込む必要がある。
reset() でいわゆる truncate ができる。
結果はこんな感じ。
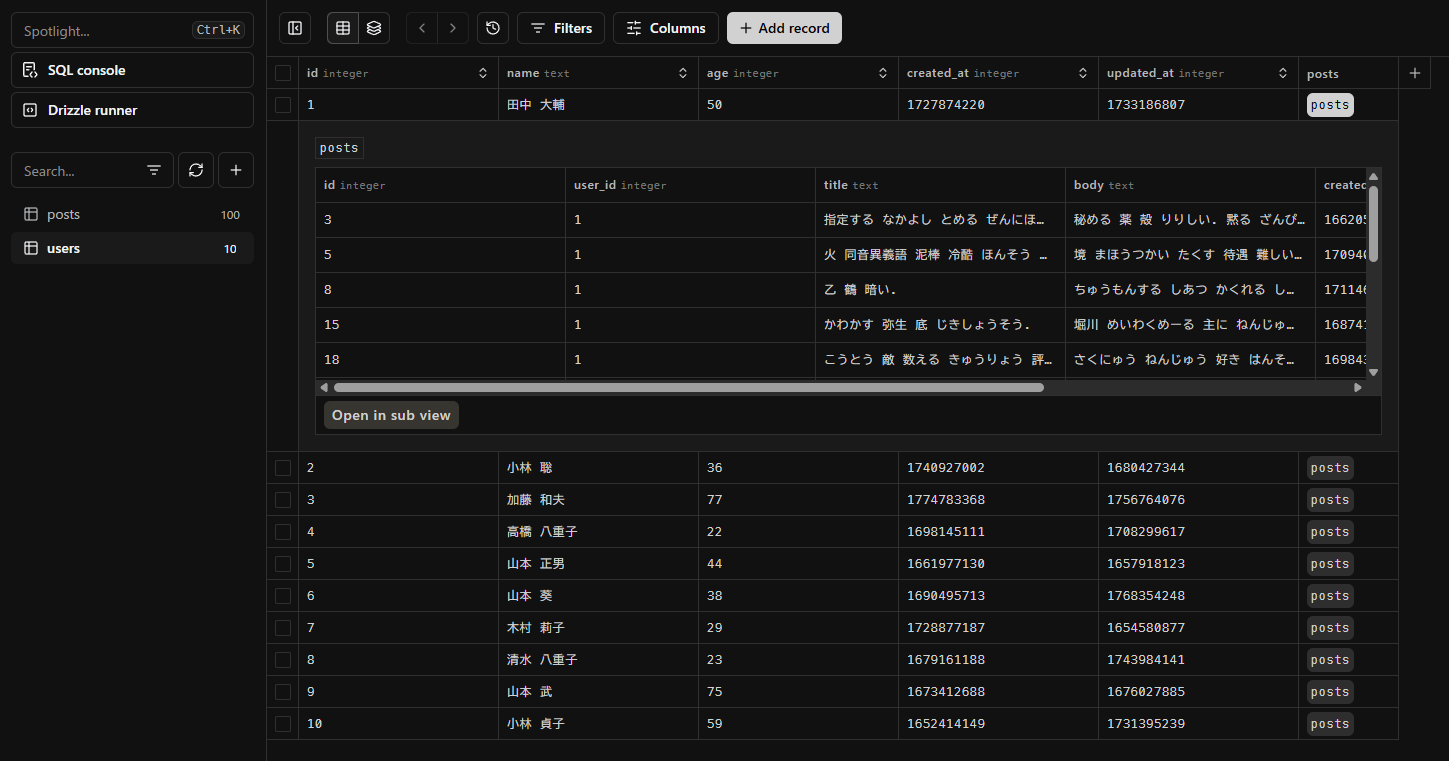
これが Drizzle の最適解になりそう。
ただ正直ランダムにする理由も特にないので、べた書きSQLでも十分かとも思う今日この頃。