はじめに
今回はHTTPリクエストを送信することのできるrequestsライブラリと, HTMLの解析を得意とするBeatifulSoupライブラリを用いて画像を収集する試みです. 内容としてはCookpadから特定の料理検索で表示される画像の自動収集を行います. これらの実装を通してrequestsとBeautifulSoupの理解がより深まることを期待します.
確認事項
クローリングを禁止しているサイトもあるので注意
記事概要
- requestsの基本
- BeautifuruSoupの基本
- 画像の収集と保存
必要事項
・ pythonの実行環境( GoogleColabratoryでもよい )
・ pythonの基本操作
requestsの基本
requestsはpythonからのHTTP通信をより手軽に行うことを可能にしてくれるライブラリです. 以下を実行することでインストールが可能です.
$ python -m pip install requests
HTTP通信について
「HTTP」の仕組みをおさらいしよう(その1) (ITmedia 2015) を参照させていただくと, HTTP通信は以下のようになものです.
またリクエストには以下のような種類があります.
参考 : https://atmarkit.itmedia.co.jp/ait/articles/1508/31/news016_3.html
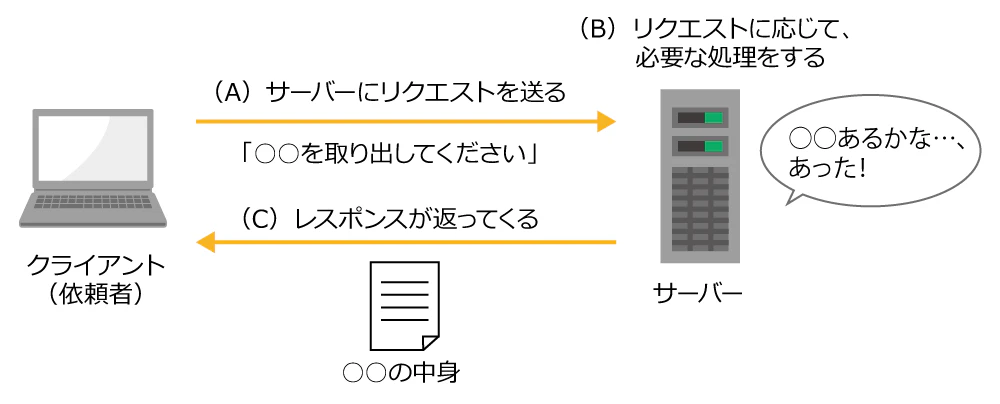

さて, 通信の仕組みもざっと分かったところでCookpadに向けたGETリクエストを送信してみましょう. requestsでGETリクエストを行うには以下を実行します.
import requests
response = requests.get('https://cookpad.com/')
このresponseの中身はHTML構造の文字列になっています.中身を表示してみましょう. レスポンスにcontentメソッドをつけることで表示できます.
import requests
response = requests.get('https://cookpad.com/')
print(response.content)
出力結果

このようにrequestsを用いるとGETリクエストやPOSTリクエストなどのHTTP通信を手軽に行うことができます. その他機能はこちらを参照してください.
しかし一方で, このままの出力結果だと必要な要素 (今回であれば画像) を探すのは大変そうですね. ここで役立つのがBeautifulSoupなどの解析器です.
BeautifulSoupの基本
ビューティフルソープと呼んでしまいそうなこのライブラリ, 正しくはビューティフルスープです. HTMLの文字列からスープ (概念) を作るイメージですね.
BeatifulSoupのインストール
BeautifulSoupは以下を実行することでインストールができます
python -m pip install beautifulsoup4
BautifulSoupの役割
さて話を戻します, BeautifulSoupはHTMLの解析器として使用されます. ではここでの解析器とはどのようなものでしょうか.
まずHTML (Hyper Text Markup Language)は構造化データです. テキスト全体がいくつかの階層にわけられ, またタグというラベルがつけられています. 解析器はその構造を把握し, 指定した要素へのアクセスを可能にしてくれます. つまり解析器を用いることでそのテキスト全体から必要なデータを取得することができるわけです.
ここで, 事前にアクセスする要素を探す必要がでてくるわけですが, それは手持ちのwebブラウザ(Edge,Chrome,FireFox,Operaなど)を用いて行います. webブラウザには開発者ツールが備え付けられており, 開いているwebサイトの構成を確認することができます. スクレイピングで用いるのは主に要素機能ですが, ここで開発者ツールの使い方について少し抑えておきます.
開発者ツールの使い方について
開発者ツールの開き方は様々ありますが, 一般的には右クリックを行うと選択できるものが多いです. 開発者ツールを開くと要素,CSSの概要,コンソール,ソースなどが出てきますが, 今回用いるのは要素のみになります. ( Edgeを使用 )
そして, 最近のwebブラウザであれば必要なデータにマウスカーソルを置くだけで要素を見つけてくれる機能がついています. それがこちらです.
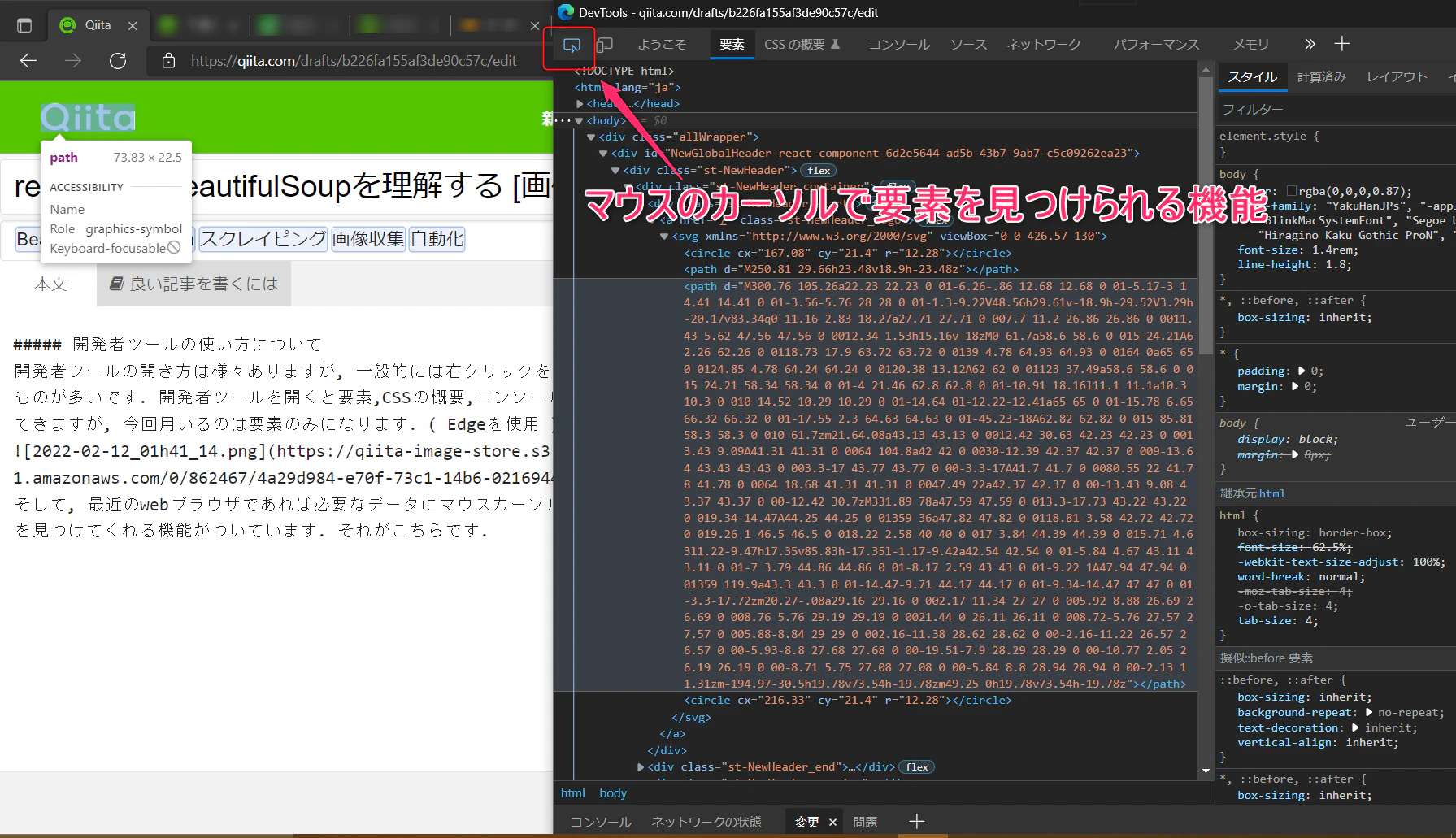
こうして取得した要素をもとにスクレイピングを実装していきます.
BeautifulSoupの使い方
開発者ツールで自身の取得したい要素を見つけた場合, いくつかの方法で要素をコピーする必要があります. 方法はいくつかあるのですが,今回は2つ紹介します.
-
class名を用いる方法
HTMLには<div>や<span>,<p>,<li>などタグと呼ばれるラベルがつけられています. また, それぞれのタグにclass名やidといった識別子が割りつけられています. 例えば<div class="main">といった感じです. そのclass={この部分}を用いることでデータにアクセスすることができます. -
css_selectorを用いる方法
開発者ツールで要素を選択しているとき, 右クリックを押すことでコピー方法を変更することができます. そこでselectorを選択するとタグの絶対位置を示したような文字列をコピーすることができます. その文字列を用いることでデータにアクセスすることができます. ( 今回は使用していません )
見れば使い方が分かると思うので, 早速実装の方をしていきたいと思います.
画像の収集と保存
このコードではCookpadの料理画像を自動収集することができます. 上で取り上げたrequestsやBeautifulSoupを用いており, その使い方を参考にしてもらえばと思います.
まずは画像URLを取得するサンプルコードです.
root_url = "https://cookpad.com"
root_page = "https://cookpad.com/search/"
query = input("検索したい料理")
# save_file = input("保存先ファイル")
page_num = 1
recipe_url = []
# 1000件集めるとき,1ページ当たり役10レシピ載っているので
total_pages = 1000 / 10
for _ in range(total_pages):
time.sleep(1.5)
response = requests.get(f"{root_page}{query}?order=date&page={page_num}")
# soupの作成
soup = BeautifulSoup(response.content)
# タグとclass名を用いて要素を取得
div_list = soup.find_all("div",class_="recipe-preview")
# レシピ詳細のurlを確認
for div in div_list:
try:
# タグとclass名を用いて要素を取得
recipe_page = div.find("div",class_="recipe-image wide").find("a")["href"]
print("レシピ詳細url : {}\n".format(root_url+recipe_page))
recipe_url.append(root_url+recipe_page)
except:
continue
page_num += 1
print(f"次のURL : {root_page}?order=date&page={page_num}")
print("このページのレシピ数 : {}\n".format(len(div_list)))
time.sleep(1)
出力例

次に画像URLから画像をダウンロードして保存するコードです.
# # 画像URLから画像を保存する
for i,url in enumerate(recipe_url):
try:
time.sleep(1)
response = requests.get(url)
# ファイルを直接開いて保存する
with open("/content/drive/MyDrive/get_image_test/{:04}.png".format(i+1),"wb") as f:
f.write(response.content)
time.sleep(0.5)
except:
continue
このようにして, webサイトから画像を収集することができます.
おわりに
スクレイピングやクローリングといった情報の自動収集は非常に魅力的な側面がある一方で, 一つ間違えるとサイバー攻撃とみなされる可能性があります. 規定でスクレイピングが禁止されていないか, 一定の間隔を開けてリクエストを飛ばせているかといった配慮を行うことが必要です. 適度を守ってスクレイピングを楽しんでいきましょう.
参考URL