結論
Notion APIのレスポンス結果をいい感じにしようとした。
作成コード
# client.py
from notion_client import Client
from typing import Any, Dict, Optional, Union
class NotionClient(Client):
"""Notion API クライアント"""
def __init__(
self,
options: Optional[Union[Dict[Any, Any], dict]] = None,
client: Optional[Any] = None,
**kwargs: Any,
) -> None:
super().__init__(options, client, **kwargs)
def query_database(self, database_id: str, **kwargs: Any):
response = self.databases.query(database_id=database_id, **kwargs)
return (NotionPageObject(data) for data in response.get("results", []))
def get_page_block(self, block_id):
return self._extract_content_dict(block_id)
def _extract_content_dict(self, block_id: str, parent_idx: str = "1") -> dict:
children = self.blocks.children.list(block_id=block_id)["results"]
content = {}
for child_idx, block in enumerate(children, start=1):
current_index = f"{parent_idx}-{child_idx}"
content[current_index] = self._parse_block_dict(block)
if block["has_children"]:
child_content = self._extract_content_dict(block["id"], current_index)
content.update(child_content)
return content
def _parse_block_dict(self, block: dict) -> dict:
block_type = block["type"]
parsed = {"id": block["id"], "type": block_type}
match block_type:
case (
"paragraph"
| "heading_1"
| "heading_2"
| "heading_3"
| "callout"
| "toggle"
| "bulleted_list_item"
| "numbered_list_item"
):
parsed["value"] = "".join(
rt["plain_text"] for rt in block[block_type]["rich_text"]
)
case "image":
parsed["value"] = (
block["image"]
.get("file", {})
.get("url", block["image"].get("external", {}).get("url", ""))
)
case _:
parsed["value"] = None
return parsed
class NotionPageObject:
"""Notion のページオブジェクト"""
def __init__(self, data: dict) -> None:
self.id: str = data.get("id", "")
self._properties: Dict[str, Any] = self._extract_properties(data)
def _to_snake_case(self, name: str) -> str:
return name.lower().replace(" ", "_")
def _extract_properties(self, data: dict) -> Dict[str, Any]:
properties = data.get("properties", {})
parsed_properties = {}
parsed_properties["url"] = data.get("url", None)
for name, prop in properties.items():
attr_name = self._to_snake_case(name)
parsed_properties[attr_name] = self._parse_property(prop)
return parsed_properties
def _parse_property(self, prop: dict) -> Any:
type = prop.get("type")
match type:
case "title" | "rich_text":
return prop[type][0]["text"]["content"] if prop[type] else ""
case "number" | "checkbox" | "rollup":
return prop.get(type)
case "select" | "status" | "date":
key = "name" if type in ("select", "status") else "start"
return prop[type][key] if prop[type] else None
case "multi_select" | "relation":
key = "name" if type == "multi_select" else "id"
return [item[key] for item in prop.get(type, [])]
case "files":
return [
f["file"]["url"] if "file" in f else f["external"]["url"]
for f in prop.get("files", [])
]
case _:
print(prop, type)
return None
def __getattr__(self, name: str) -> Any:
if name in self._properties:
return self._properties[name]
raise AttributeError(
f"'{self.__class__.__name__}' object has no attribute '{name}'"
)
def __repr__(self) -> str:
return f"<NotionPage id={self.id}, properties={self._properties}>"
PythonでNotion APIを利用する際の基本
通常APIのリクエストにはPythonのurllibやrequestsライブラリを使う方法があるが、
Notionにはnotion-clientというライブラリが存在する。
好きな方を使えばいいが、車輪の再発明をするなという言葉を信じて今回はnotion-clientを使用。
requestを使用する方法
# リクエストのヘッダー
headers = {
"Authorization": f"Bearer {TOKEN}",
"Notion-Version": "2021-05-13", # APIのバージョン
"Content-Type": "application/json"
}
# リクエストのボディ(kwargsに相当する部分)
data = {} #任意何かあれば入れる。
# URL
url = f'https://api.notion.com/v1/databases/{database_id}/query'
# POSTリクエストを送る
response = requests.post(url, headers=headers, data=json.dumps(data))
# レスポンスの確認
if response.status_code == 200:
result = response.json()
print(result)
# レスポンスデータを処理
else:
print(f"Error: {response.status_code}")
print(response.text)
notion-clientを使用する方法
有志の方が作りいつのまにか公式になったsdkツールを使用する方法が一番簡単
from notion_client import Client
notion = Client(auth=TOKEN)
result = notion.databases.query(DB_TOKEN)
print(result)
ちなみにどちらの方法でもトークンは必要なので事前に取得する必要がある。
この方法については以下の記事で十分なので参考にしてください。
車輪の再発明をするn.....
記事にしたかったこと
基本的に上記までのリンクを読めばだいたいはAPIが使えるのだが、
じゃぁお前は今日何しにここに来たん?っていう話になってしまう。
私が言いたかったのは上記のツールを使ってもNotionの仕様上めんどくさい処理が存在する。
そのめんどくささを共有したい。
その1:取得したDBデータ見づらすぎ問題
例えば参考までに以下ゴミみたいな英単語帳を作成した。
DB
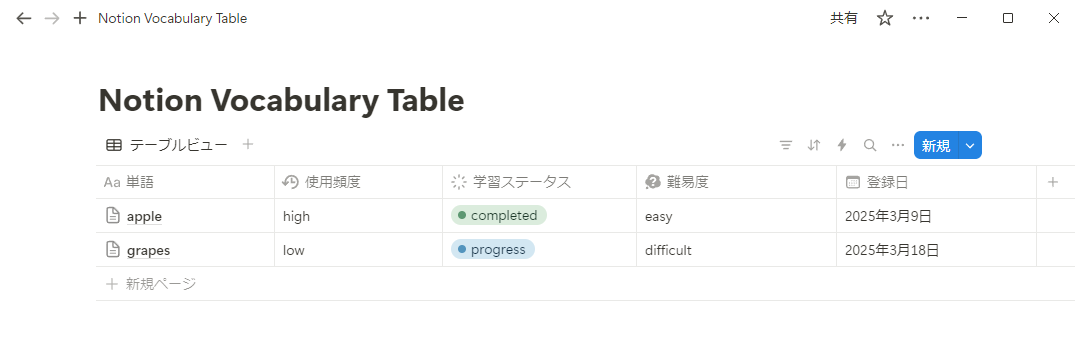
お前こんなもの作ってる暇があるならアップルって10回唱えてれば覚えるだろ。
っていう話になってしまうのだが、こんな英単語帳を英語系インフルエンサーに騙されて購入したとする。
「DBで単語を一覧で確認できます。各種ステータスがわかります!カンバンモードにすれば覚えた単語をドラッグアンドドロップですぐにステータスの変更ができます!!」
すごいのはNotionの機能であってこいつの作った英単語帳ではないのは明白なのだが、
とりあえずそんな英単語帳が存在してたと仮定する。
取得結果
でこれに対してのリクエスト投げた結果がこれ
from notion_client import Client
notion = Client(auth=TOKEN)
results = notion.databases.query(DB_TOKEN)
print(results)
リクエスト結果
{
"has_more": False,
"next_cursor": None,
"object": "list",
"page_or_database": {},
"request_id": "abc12345-6789-0123-4567-89abcdef0123",
"results": [
{
"archived": False,
"cover": None,
"created_by": {
"id": "xyz12345-6789-0123-4567-89abcdef9876",
"object": "user"
},
"created_time": "2025-03-08T22:53:00.000Z",
"icon": None,
"id": "page12345-6789-0123-4567-89abcdef0001",
"in_trash": False,
"last_edited_by": {
"id": "xyz12345-6789-0123-4567-89abcdef9876",
"object": "user"
},
"last_edited_time": "2025-03-09T07:19:00.000Z",
"object": "page",
"parent": {
"database_id": "db12345-6789-0123-4567-89abcdef0001",
"type": "database_id"
},
"properties": {
"使用頻度": {
"id": "a1b2c3d4",
"rich_text": [
{
"annotations": {
"bold": False,
"code": False,
"color": "default",
"italic": False,
"strikethrough": False,
"underline": False
},
"href": None,
"plain_text": "low",
"text": {
"content": "low",
"link": None
},
"type": "text"
}
],
"type": "rich_text"
},
"単語": {
"id": "title",
"title": [
{
"annotations": {
"bold": True,
"code": False,
"color": "default",
"italic": False,
"strikethrough": False,
"underline": False
},
"href": None,
"plain_text": "bananas",
"text": {
"content": "bananas",
"link": None
},
"type": "text"
}
],
"type": "title"
},
"学習ステータス": {
"id": "status1",
"status": {
"color": "blue",
"id": "status-id-1234abcd",
"name": "progress"
},
"type": "status"
},
"登録日": {
"date": {
"end": None,
"start": "2025-03-18",
"time_zone": None
},
"id": "date-id-5678",
"type": "date"
},
"難易度": {
"id": "diff1",
"rich_text": [
{
"annotations": {
"bold": False,
"code": False,
"color": "default",
"italic": False,
"strikethrough": False,
"underline": False
},
"href": None,
"plain_text": "medium",
"text": {
"content": "medium",
"link": None
},
"type": "text"
}
],
"type": "rich_text"
}
},
"public_url": None,
"url": "https://www.notion.so/bananas-page1234567890"
},
{
"archived": False,
"cover": None,
"created_by": {
"id": "xyz98765-4321-0987-6543-21abcdef4321",
"object": "user"
},
"created_time": "2025-03-08T06:29:00.000Z",
"icon": None,
"id": "page67890-1234-5678-1234-abcdef9876",
"in_trash": False,
"last_edited_by": {
"id": "xyz98765-4321-0987-6543-21abcdef4321",
"object": "user"
},
"last_edited_time": "2025-03-09T07:19:00.000Z",
"object": "page",
"parent": {
"database_id": "db67890-1234-5678-1234-abcdef9876",
"type": "database_id"
},
"properties": {
"使用頻度": {
"id": "e5f6g7h8",
"rich_text": [
{
"annotations": {
"bold": False,
"code": False,
"color": "default",
"italic": False,
"strikethrough": False,
"underline": False
},
"href": None,
"plain_text": "high",
"text": {
"content": "high",
"link": None
},
"type": "text"
}
],
"type": "rich_text"
},
"単語": {
"id": "title",
"title": [
{
"annotations": {
"bold": False,
"code": False,
"color": "default",
"italic": False,
"strikethrough": False,
"underline": False
},
"href": None,
"plain_text": "oranges",
"text": {
"content": "oranges",
"link": None
},
"type": "text"
}
],
"type": "title"
},
"学習ステータス": {
"id": "status2",
"status": {
"color": "green",
"id": "status-id-5678efgh",
"name": "completed"
},
"type": "status"
},
"登録日": {
"date": {
"end": None,
"start": "2025-03-09",
"time_zone": None
},
"id": "date-id-9876",
"type": "date"
},
"難易度": {
"id": "diff2",
"rich_text": [
{
"annotations": {
"bold": False,
"code": False,
"color": "default",
"italic": False,
"strikethrough": False,
"underline": False
},
"href": None,
"plain_text": "easy",
"text": {
"content": "easy",
"link": None
},
"type": "text"
}
],
"type": "rich_text"
}
},
"public_url": None,
"url": "https://www.notion.so/oranges-page6789012345"
}
],
"type": "page_or_database"
}
なげえ!!!!(怒)
たった二行のレコードでどんな結果だよ。
ってことでどうにかしてこの結果を短くしたかった。
というか本音を言うとnotion-clientというライブラリだったからにはこういうレスポンス結果もいい感じにまとめてくれているのかと思ったら全然そんなこともなかったみたい。
これじゃ目的のデータへのアクセス方法が全然わからない。
試しに単語列の値を取得するときはこんな感じ
print(results["results"][0]["properties"]["単語"]["title"][0]["text"]["content"])
# 出力: grapes
for文でも全然長い。
for result in results["results"]:
print(result["properties"]["単語"]["title"][0]["text"]["content"])
# 出力 : grapes
# 出力 : apple
その2:ページ内のブロック取得するの大変すぎ問題
その2に関してはページ内のブロックコンテンツについてである。
Notionを使ったことがない人に説明すると、NotionのDBは各レコードだけのカラムデータだけでなく詳細情報のようなレコードのごとに別のページを作成することができる。

このページはレコードからクリックするだけでとべるので、単語の学習中に詳しい情報を知りたい場合はすぐに飛べるようになっている。
だいたいの英語情報商材系インフルエンサーはここにyouglishやplayphase、またイメージなどといったものを張ることで、オリジナリティを出しているが、基本的に外部リンクになっているのですごいのはこの英単語帳ではなく外部のサイトであることは強調しておく。
で話を戻すが、Notionのこのページ内のコンテンツを取得する方法がかなり厄介である。
何が厄介というと一度ですべてのデータを取得することができないのである。
以下参考としてページ内のリンゴの画像を取得する方法を記載する。
from notion_client import Client
notion = Client(auth=TOKEN)
results = notion.databases.query(DB_TOKEN)
# ページIDを取得
page_id = results["results"][1]['id']
# ページIDのブロック情報を取得
response = notion.blocks.children.list(page_id)
# ブロック情報の子要素のブロック情報を取得
response = notion.blocks.children.list(response["results"][2]["id"])
# ブロック情報の子要素のブロック情報の子要素のブロック情報を取得
response = notion.blocks.children.list(response["results"][0]["id"])
# ブロック情報の子要素のブロック情報の子要素のブロック情報の子要素のブロック情報を取得
response = notion.blocks.children.list(response["results"][1]["id"])
# 画像URLを取得
print(response["results"][0]["image"]["file"]["url"])
めんどくせえ!!!(怒)
そうつまりページ内の階層構造になっているデータは親のデータを取得した後に子データを取得するというのを繰り返さなくてはいけない。
- [1]行目 (赤:[0]行目がぶどう)
- [2]ブロック目(緑)
- [0]ブロック目(橙)
- [1]ブロック目(黄)
- [0]ブロック目(青)

のデータを取得する必要がある。
※Pythonなのでリストは0始まり
じゃぁどうしようか
ということで上記2個のめんどくささを個人的に解消できるようにプログラムを組む。
コーディング(その1)
その1の問題点であるレコードのプロパティ情報のアクセスのしやすさを改善する。
実装方法としては以下を考慮する
1.リクエストの結果を取得
2.(1)のデータでページオブジェクトを作成する
3.(2)のpropertiesからデータを取得して、オブジェクトの属性に格納する。
というような感じである。
(2)以降を実装したクラスはこんな感じ
class NotionPageObject:
"""Notion のページオブジェクト"""
def __init__(self, data: dict) -> None:
self.id: str = data.get("id", "")
self._properties: Dict[str, Any] = self._extract_properties(data)
def _to_snake_case(self, name: str) -> str:
return name.lower().replace(" ", "_")
def _extract_properties(self, data: dict) -> Dict[str, Any]:
properties = data.get("properties", {})
parsed_properties = {}
parsed_properties["url"] = data.get("url", None)
for name, prop in properties.items():
attr_name = self._to_snake_case(name)
parsed_properties[attr_name] = self._parse_property(prop)
return parsed_properties
def _parse_property(self, prop: dict) -> Any:
type = prop.get("type")
match type:
case "title" | "rich_text":
return prop[type][0]["text"]["content"] if prop[type] else ""
case "number" | "checkbox" | "rollup":
return prop.get(type)
case "select" | "status" | "date":
key = "name" if type in ("select", "status") else "start"
return prop[type][key] if prop[type] else None
case "multi_select" | "relation":
key = "name" if type == "multi_select" else "id"
return [item[key] for item in prop.get(type, [])]
case "files":
return [
f["file"]["url"] if "file" in f else f["external"]["url"]
for f in prop.get("files", [])
]
case _:
print(prop, type)
return None
def __getattr__(self, name: str) -> Any:
if name in self._properties:
return self._properties[name]
raise AttributeError(
f"'{self.__class__.__name__}' object has no attribute '{name}'"
)
def __repr__(self) -> str:
return f"<NotionPage id={self.id}, properties={self._properties}>"
リクエストのデータを取得して使用してみる。
from notion_client import Client
notion = Client(auth=TOKEN)
results = notion.databases.query(DB_TOKEN)
records = (NotionPageObject(data) for data in results.get("results", []))
for record in records:
print("-----レコードデータ------")
print(record)
print("プロパティごとのアクセス")
print(f"{record.id=}")
print(f"{record.単語=}")
print(f"{record.難易度=}")
print(f"{record.学習ステータス=}")
print(f"{record.登録日=}")
print(f"{record.url=}")
print()
-----レコードデータ------
<NotionPage id=1b023f49-1913-80a8-ab89-faa2117b5865, url=https://www.notion.so/grapes-1b023f49191380a8ab89faa2117b5865, properties={'url': 'https://www.notion.so/grapes-1b023f49191380a8ab89faa2117b5865', '難易度': 'difficult', '登録日': '2025-03-18', '学習ステータス': None, '使用頻度': 'low', '単語': 'grapes'}>
プロパティごとのアクセス
record.id='page12345-6789-0123-4567-89abcdef0001'
record.単語='grapes'
record.難易度='difficult'
record.学習ステータス='progress'
record.登録日='2025-03-18'
record.url='https://www.notion.so/grapes-page12345-6789-0123-4567-89abcdef0001'
-----レコードデータ------
<NotionPage id=1b023f49-1913-8012-a2dc-f084ffee0573, url=https://www.notion.so/apple-1b023f4919138012a2dcf084ffee0573, properties={'url': 'https://www.notion.so/apple-1b023f4919138012a2dcf084ffee0573', '難易度': 'easy', '登録日': '2025-03-09', '学習ステータス': None, '使用頻度': 'high', '単語': 'apple'}>
プロパティごとのアクセス
record.id='page12345-6789-0123-4567-89abcdef0002'
record.単語='apple'
record.難易度='easy'
record.学習ステータス='completed'
record.登録日='2025-03-09'
record.url='https://www.notion.so/apple-page12345-6789-0123-4567-89abcdef0002'
NotionAPIのドキュメントを確認するとDBのプロパティはtypeごとに実際のデータが格納されている場所が決まっている。
そのためmatch構文(elifが好きな人はそれでも)を使用して条件ごとにデータを取得する。
そのデータをself._propertiesに格納し、実際に.アクセスされた際の処理はgetattrで決定するという仕様となった。
思い付きで書いただけなのでもっといい方法があるかもしれないし、テストもやっていないので抜けているtypeも存在しているが、現状このくそ英単語を使う上では不便ではないので見直してはいない。
やはりクラス名.カラム名でアクセスできるのはDjangoのORMのようでわかりやすい。
またこのコードは事前にカラム名を指定する必要がないので汎用性が高くとても便利なのではないかと感じた。
コーディング(その2)
その2の問題はとても簡単に解決できるが実際に利用する機会が少ないと感じた。
def get_page_block(self, block_id):
return self._extract_content_dict(block_id)
def _extract_content_dict(self, block_id: str, parent_idx: str = "1") -> dict:
children = self.blocks.children.list(block_id=block_id)["results"]
content = {}
for child_idx, block in enumerate(children, start=1):
current_index = f"{parent_idx}-{child_idx}"
content[current_index] = self._parse_block_dict(block)
if block["has_children"]:
child_content = self._extract_content_dict(block["id"], current_index)
content.update(child_content)
return content
def _parse_block_dict(self, block: dict) -> dict:
block_type = block["type"]
parsed = {"id": block["id"], "type": block_type}
match block_type:
case (
"paragraph"
| "heading_1"
| "heading_2"
| "heading_3"
| "callout"
| "toggle"
| "bulleted_list_item"
| "numbered_list_item"
):
parsed["value"] = "".join(
rt["plain_text"] for rt in block[block_type]["rich_text"]
)
case "image":
parsed["value"] = (
block["image"]
.get("file", {})
.get("url", block["image"].get("external", {}).get("url", ""))
)
case _:
parsed["value"] = None
return parsed
このコードはget_page_blockを起点に再帰的に子要素のブロックを見ていくものだ。
というのも子要素が存在する場合ブロック要素に[has_children]=Trueが存在するので、その場合は再度関数を実行するだけ。
ブロックの処理はプロパティと同じだと思ったがtypeが全然違くこれまた理解しづらかった。
そして結局再帰的に処理を実施したところで親要素に紐づけると階層が深い問題が解決されていなかったので
すべてのデータを平面化して一つのキーでアクセスできるようにした。
# 修正前
response = notion.blocks.children.list(page_id)
response = notion.blocks.children.list(response["results"][2]["id"])
response = notion.blocks.children.list(response["results"][0]["id"])
response = notion.blocks.children.list(response["results"][1]["id"])
print(response["results"][0]["image"]["file"]["url"])
print("################################")
# 修正後
contents = notion.get_page_block(page_id)
print(contents["1-3-1-2-1"]["value"])
このコードはページ内のコンテンツを再帰的に取得し、ブロックごとのキーを作成して管理している。
修正前は0→2→0→1→0と順番に処理をする必要があったが
こちらは1-3-1-2-1キーにアクセスすることで一度に取得できる。
※修正するときに1始まりにしただけで相対的には修正前と変わらない。
このコードの注意点は単純に複数のAPIを一度の実行するためくそ重い。
実用性皆無のコード。ゴミ界のゴミ。ビーレジェンドゴミ
個人的には「ページ内の情報が欲しければページのリンクだけ貼っておけばよくね?」となっているが、
現場でよくある(くそめんどくせえし全然やりたくないけど)「技術的には可能です」という回答をするために検証してみたに過ぎない。
まとめ
ということでとりあえずNotionAPIもまだまだ使うには調査が必要であるし、そもそもNotionという便利な閲覧アプリがあってなにをAPIで取得するのか疑問ではあるがなんとかなく技術調査は完了したと判断する。
最後にDjangoで作ったNotionのデータ取得するだけアプリを添付して終わる。
Notionのデータ反映するだけアプリ


コード(抜粋)
*今回作成したコード一式
- Django(views.py)
from django.shortcuts import render
from django.conf import settings
from .client import NotionClient
from django.views.generic import TemplateView
NOTION_TOKEN = getattr(settings, "NOTION_TOKEN")
DB_TOKEN = getattr(settings, "DB_TOKEN")
notion = NotionClient(auth=NOTION_TOKEN)
class VocabularyView(TemplateView):
template_name = "index.html"
def get_context_data(self, **kwargs):
context = super().get_context_data(**kwargs)
# NotionのデータベースIDを指定してページを取得
response = notion.query_database(DB_TOKEN)
# 取得したデータをコンテキストに追加
context["pages"] = response
return context
def page_detail(request, page_id):
contents = notion.get_page_block(page_id)
context = {
"name": contents["1-2"]["value"],
"define": contents["1-2-2"]["value"],
"image": contents["1-3-1-2-1"]["value"],
"example": contents["1-3-2-2-1"]["value"],
"youglish_link": contents["1-3-2-3-1"]["value"],
}
return render(
request,
"detail.html",
context,
)
- HTMLファイル
# index.html
{% extends 'base.html' %} {% block title %}Notion Vocabulary Table{% endblock %}
{%block content %}
<h1 class="text-3xl font-bold text-center mb-6">Notion Vocabulary Table</h1>
<div class="overflow-x-auto bg-white shadow-md rounded-lg">
<table class="min-w-full table-auto">
<thead class="bg-gray-200">
<tr>
<th
class="px-6 py-3 text-left text-sm font-medium text-gray-500 uppercase"
>
単語
</th>
<th
class="px-6 py-3 text-left text-sm font-medium text-gray-500 uppercase"
>
使用頻度
</th>
<th
class="px-6 py-3 text-left text-sm font-medium text-gray-500 uppercase"
>
学習ステータス
</th>
<th
class="px-6 py-3 text-left text-sm font-medium text-gray-500 uppercase"
>
難易度
</th>
<th
class="px-6 py-3 text-left text-sm font-medium text-gray-500 uppercase"
>
登録日
</th>
</tr>
</thead>
<tbody>
{% for page in pages %}
<tr class="border-b hover:bg-gray-50">
<td class="px-6 py-4 text-sm text-gray-900">
<a
href="{% url 'page_detail' page.id %}"
class="text-blue-500 hover:underline"
target="_blank"
>{{ page.単語 }}</a
>
</td>
<td class="px-6 py-4 text-sm text-gray-900">{{ page.使用頻度 }}</td>
<td class="px-6 py-4 text-sm text-gray-900">
{{ page.学習ステータス }}
</td>
<td class="px-6 py-4 text-sm text-gray-900">{{ page.難易度 }}</td>
<td class="px-6 py-4 text-sm text-gray-900">{{ page.登録日 }}</td>
</tr>
{% endfor %}
</tbody>
</table>
</div>
{% endblock %}
# detail.html
{% extends 'base.html' %} {% block title %}Vocabulary Detail{% endblock %}
{%block content %}
<!-- タイトル -->
<h2 class="text-4xl font-bold text-center text-gray-800 mb-6">
Vocabulary Detail
</h2>
<div class="bg-white p-6 rounded-lg shadow-lg">
<!-- 単語名 -->
<p class="text-2xl font-semibold text-gray-700 mb-4">{{ name }}</p>
<!-- 意味と定義 -->
<div class="mb-6">
<p class="font-semibold text-gray-800">意味:</p>
<p class="text-gray-600">{{ define }}</p>
</div>
<!-- 画像 -->
<div class="flex justify-center mb-6">
<img
src="{{ image }}"
alt="Word image"
class="w-full max-w-xs h-auto mx-auto rounded-lg shadow-md"
/>
</div>
<!-- 例文 -->
<h3 class="text-xl font-semibold text-gray-700 mb-4">例文</h3>
<p class="text-gray-600 mb-6">{{ example }}</p>
<!-- Youglishリンク -->
<div class="text-center">
<a
href="{{ youglish_link }}"
class="inline-block px-6 py-2 bg-blue-500 text-white font-semibold rounded-lg hover:bg-blue-600 transition duration-300"
>Youglishで検索</a
>
</div>
</div>
{% endblock %}
DjangoのORMのメリットは生かしていないのでDjangoで作成する必要はないです。(今回たまたま選択しただけ)