はじめに
ついにAzure OpenAI ServiceでもCode Interpreterが使えるようになりました。早速色々作ってみようと思っているのですが、プログラムを作っていくにあたって、ある程度呼び出し側の仕組みなどを理解した方が良いなと思い整理してみました。
なお、実装するにあたって参考にしたのは以下の公式サイトです。
- Quickstart: Get started using Azure OpenAI Assistants (Preview)
- Getting started with Azure OpenAI Assistants (Preview)
- Azure OpenAI Assistants Code Interpreter (Preview)
※なお、2個目の公式サイトですが、2/7現在以下の2点で不都合がありました。いずれ修正されるかと思いますが、ご注意ください
- イメージファイルのID取得の際の配列の場所が違う
(誤) image_file_id = data['data'][1]['content'][0]['image_file']['file_id']
(正) image_file_id = data['data'][0]['content'][0]['image_file']['file_id']
- ファイルへの書き込みメソッドが違う
(誤) write_to_file
(正) stream_to_file
全体像
Code Interpreterを実装するにあたって、必要となる全体像は以下です。
四角ブロックで表記したものが作成するもので、赤で表記しているものは作成時に振られるもの、丸は引数として受け取るものになります。
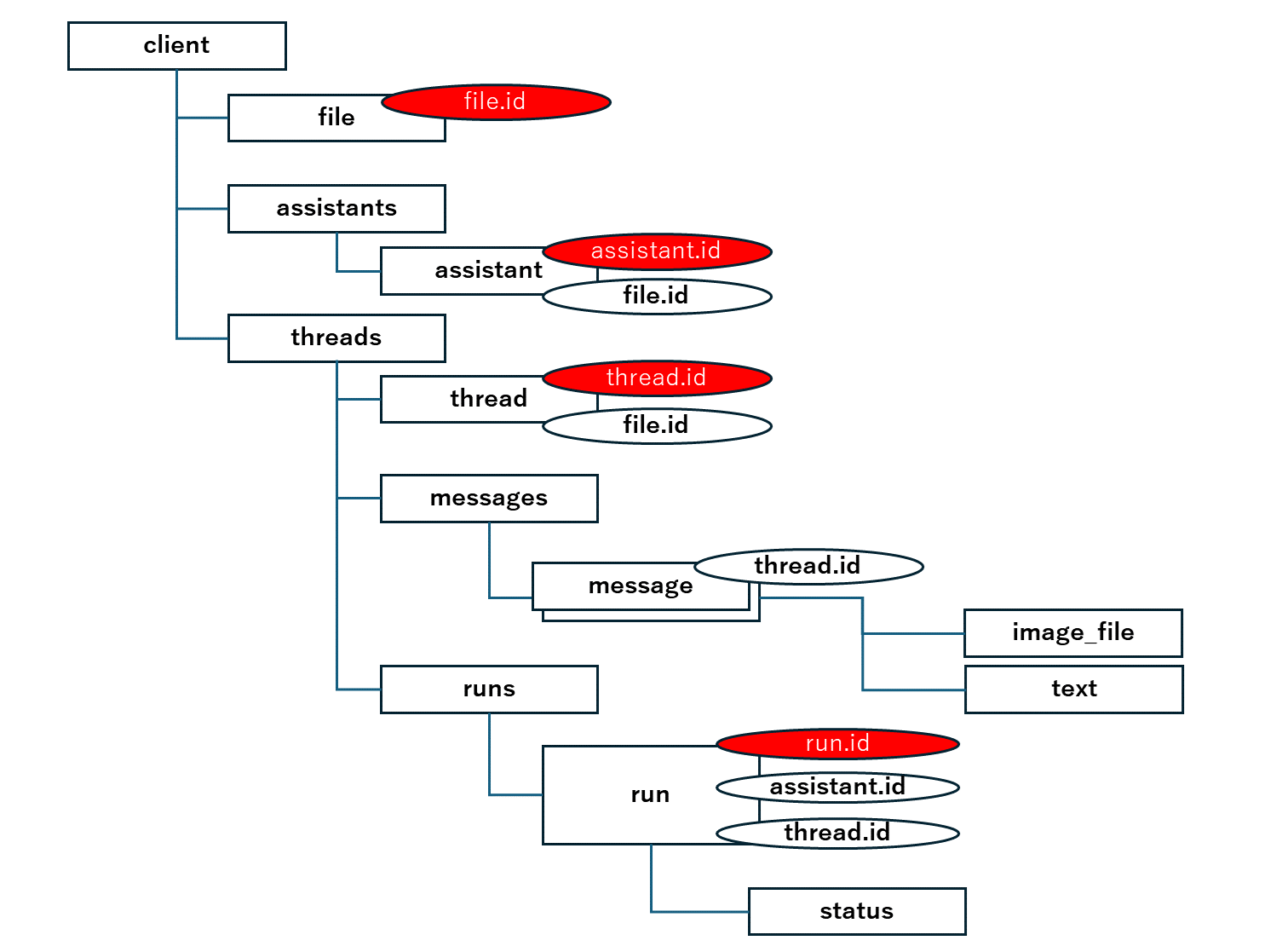
ざっくり以下な感じです。
| クラス | 説明 |
|---|---|
| client | OpenAIのクライアント。すべての源流 |
| file | Code Interpreterで使いたいファイル |
| assistant | 実行環境と基本指示 |
| thread | 処理の実行プロセス |
| message | 入力と出力のメッセージなどのやりとり |
| run | 処理の実行 |
おおまかな流れ
1. 必要な環境を準備する
まずはクライアントです。普通のclientとして作成します。APIバージョンだけはご注意を。
client = AzureOpenAI(
api_key=os.getenv("AOAI_API_KEY"),
api_version="2024-02-15-preview",
azure_endpoint = os.getenv("AOAI_ENDPOINT"),
timeout=60
)
読み込ませたいファイルがあればファイルも読み込みます。これでfile.idが取得できるようになるのでそれを使っていきます。(assistantやthraedに入れる)
file = client.files.create(
file=open("ほにゃららデータ.csv", "rb"),
purpose='assistants'
)
次にアシスタントをつくります。ここには基本指示とCode Interpreterであること、ならびに必要であれば先につくったfile.idを入れます。これでassistant.idがとれるようになります。
なお、AOAIのモデルとしてはgpt-4-turboで作ったモデル名を指定します。
assistant = client.beta.assistants.create(
name="ほにゃららデータ分析",
instructions="あなたはほにゃららのデータ分析官です。",
tools=[{"type": "code_interpreter"}],
model=os.getenv("AOAI_MODEL"),
file_ids=[file.id]
)
次に実行するためのスレッドを作成します。これでthread.idがとれるようになります。
thread = client.beta.threads.create()
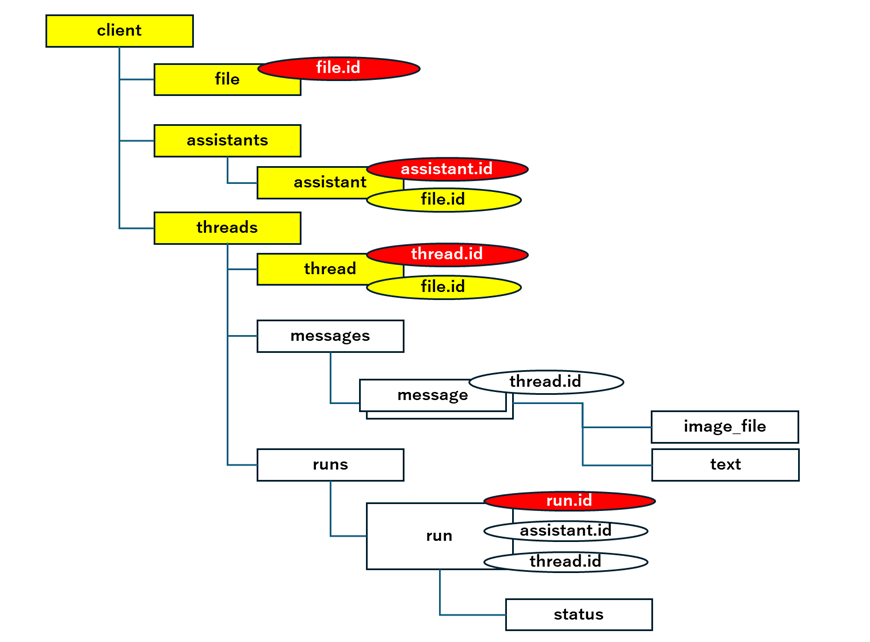
ここまでで以下の黄色部分ができます。事前準備は完了です
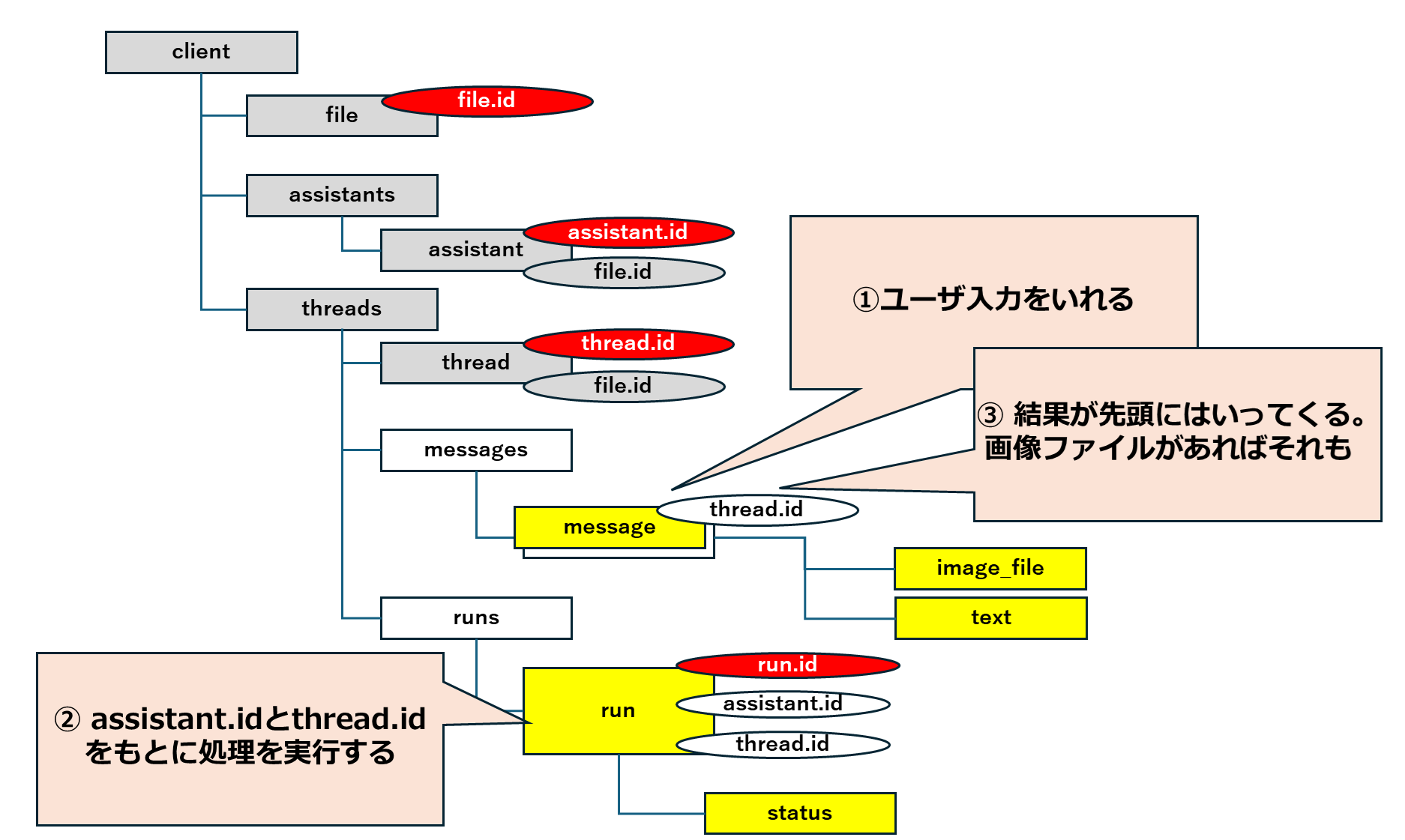
2. ユーザ入力をmessageに追加する
処理させたい内容をmessageとしてthread.idを指定して追加します。(createですが、messagesの先頭にmessageが追加されます)
message = client.beta.threads.messages.create(
thread_id=thread.id,
role="user",
content="ほにゃららの推移をグラフ化してください"
)
3. 実行する
事前準備もメッセージもできたので、ここで実行です。thread.idとasssitant.idを元に処理を指定して実行します。
run = client.beta.threads.runs.create(
thread_id=thread.id,
assistant_id=assistant.id,
)
処理の実行は非同期に行われます。thread.idとrun.idから実行状況を取得することができます。このstatusがcompletedになれば処理が完了です。
run = client.beta.threads.runs.retrieve(thread_id=thread.id,run_id=run.id)
status = run.status
4. 結果をmessagesから取得する
処理結果はmessagesに追加されてきます。statusがcompletedであることを確認したうえで、thread.idを指定してmessagesから取得できます。
messages = client.beta.threads.messages.list(
thread_id=thread.id
)
#JSONにします。
data = json.loads(messages.model_dump_json(indent=2))
応答がテキストのみであればテキストだけをとりますが、グラフを作成させた場合などはイメージファイルが入っています。(イメージファイルが先)
それぞれ以下のように取得できます。
image_file_id = data['data'][0]['content'][0]['image_file']['file_id']
reply_message = data['data'][0]['content'][1]['text']['value']
画像ファイルはstream_to_fileを使ってファイルに落とすことができます。
content = client.files.content(image_file_id)
image= content.stream_to_file("graph.png")
あとは表示すればうまくいっていれば期待の画像ができているはずです。(画像はイメージです)
※必要に応じて、2.から4.を繰り返します。
おわりに
とりあえずサンプルなどをもとに実装してみることは簡単にできたものの、file.idだとかassistant.idだとかthread.idだとか、messageだとかがあってどうなってるのかしらと混乱してしまったので、整理してみました。
特段難しい作りではないかもですが、仕組みの概要がわかると実装もしやすいですしね。