はじめに
ChatGPT Code Interpreter いいですよね。でもAzure OpenAIではまだまだ使えなさそう(そもそも使えるようになるのか?)なので、Jupyter Notebookと組み合わせて同じようなことを実現してみました。
Function Callingが使えるようになれば、ちょっと実装を変えたほうがよいところもありますが、とりあえず生ChatGPTで進めます。gpt-35-turbo(0613)です。お安くできますね。
環境準備
Jupyter Notebookを使える環境はお好みの方法でご用意ください。
あと、openai、matplotlib, pandas, numpyとか必要なものもお好きな環境にどうぞ。なお、日本語でグラフを作成したいので、japanize-matplotlibはいれておいてください。
Code Interpreterを実現する関数
Jupyter Notebookに以下の関数群を定義します。
import os
import openai
import time
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv())
openai.api_key = os.getenv('AOAI_API_KEY')
openai.api_type = "azure"
openai.api_base = os.getenv('AOAI_ENDPOINT')
openai.api_version = "2023-05-15"
def get_completion_from_messages(messages,temperature=0):
response = openai.ChatCompletion.create(
engine=os.getenv('AOAI_MODEL'),
messages=messages,
temperature=temperature,
)
return response.choices[0].message["content"]
prompt_w_history = []
def execChatGPT(user_prompt,filename="",pandas_df=None):
system_prompt = f"""あなたはJupyterNotebookを使うPythonデータサイエンティストです。
入力されたデータや指示をもとに、ユーザのリクエストに応じたPythonプログラムを作成してください。
なお、回答には1つのPythonコードブロックのみを含めてください。
またグラフ作成においては、japanize_matplotlibも使ってください。
"""
if filename != "":
system_prompt += f"""
# 入力データ:ファイルパス
{filename}
なお、データはUTF-8で読み込んでください。
"""
if pandas_df is not None:
system_prompt += f"""
# 入力データ:データフレーム
{pandas_df}
"""
messages = [
{'role':'system', 'content':system_prompt},
]
prompt_w_history.append({'role':'user', 'content':user_prompt})
messages.extend(prompt_w_history)
try:
response = get_completion_from_messages(messages, temperature=0)
except Exception as e:
print(e)
time.sleep(3)
response = get_completion_from_messages(messages, temperature=0)
print(response)
python = response.split("```python")[1].split("```")[0]
try:
out = get_ipython().run_cell(python)
prompt_w_history.append({'role':'assistant', 'content':response+'\n'+str(out.result)})
except Exception as e:
print(e)
prompt_w_history.append({'role':'assistant', 'content':response+'\n'+str(out.error)})
あとは環境ファイル(.env)を定義します。
AOAI_API_KEY={AOAIのキー}
AOAI_ENDPOINT={AOAIのエンドポイント}
AOAI_MODEL={GPT35もしくは4のデプロイしたモデル名}
これで準備は完了です。
自家製Code Interpreter試してみる
検証用のデータ準備
とりあえずデータを準備します。今回は気象庁の過去の気象データ・ダウンロードサイトから、東京の1年分のデータをダウンロードします。
ただ色々と情報入っているので、わかりやすいように以下の形で適当に整形します。
これをtokyo.csvとして保存しておきます。UTF-8で保存しておいてくださいね。
日付,最高気温(℃),最低気温(℃),降水量の合計(mm),平均蒸気圧(hPa),平均現地気圧(hPa),平均雲量(10分比),日照時間(時間),平均風速(m/s),最多風向(16方位)
2022/7/18,32.2,23.1,0,28.8,1000.7,8,7.3,2.2,南
2022/7/19,31.6,25.6,0,30,999,10,0.4,3.1,南南西
2022/7/20,34.5,24.8,0,25.9,999.6,8.5,8.1,3.3,北西
・・・
まずはデータ確認
Jupyter Notebookで上記で登録した関数を呼び出すだけです。まずはデータの確認をします。
execChatGPT("入力ファイルのデータを読み込み、どんな内容が入っているか教えて下さい","../private/tokyo.csv",None)
そうすると以下の結果がでてきます。
以下のコードを実行してください。データの最初の5行を表示します。
`` ``` ``python #バッククォート3つが表現できませんでした・・
import pandas as pd
# ファイルパス
file_path = "../private/tokyo.csv"
# データ読み込み
data = pd.read_csv(file_path, encoding="utf-8")
# 最初の5行を表示
data.head()
`` ``` `` #バッククォート3つが表現できませんでした・・
これにより、データの最初の5行が表示されます。
日付 最高気温(℃) 最低気温(℃) 降水量の合計(mm) 平均蒸気圧(hPa) 平均現地気圧(hPa) 平均雲量(10分比) 日照時間(時間) 平均風速(m/s) 最多風向(16方位)
0 2022/7/18 32.2 23.1 0.0 28.8 1000.7 8.0 7.3 2.2 南
1 2022/7/19 31.6 25.6 0.0 30.0 999.0 10.0 0.4 3.1 南南西
2 2022/7/20 34.5 24.8 0.0 25.9 999.6 8.5 8.1 3.3 北西
3 2022/7/21 32.8 25.0 0.0 28.1 1002.6 9.8 6.3 3.6 南南東
4 2022/7/22 32.8 26.1 1.5 31.2 997.0 5.8 7.2 4.5 南南東
データの概況はわかりました。また履歴にこの結果も含まれるので次にグラフを作成させてみます。同じくJupyter Notebookで以下を実行します。履歴にファイル情報などが入ってるため、今回は抜きで関数を呼び出します。
execChatGPT("日付と最高気温、最低気温の推移をグラフ化してください。","",None)
そうすると以下の結果がでてきます。
以下のコードを実行してください。日付と最高気温、最低気温の推移を折れ線グラフで表示します。
`` ``` ``python
import pandas as pd
import matplotlib.pyplot as plt
import japanize_matplotlib
# ファイルパス
file_path = "../private/tokyo.csv"
# データ読み込み
data = pd.read_csv(file_path, encoding="utf-8")
# 日付をdatetime型に変換
data["日付"] = pd.to_datetime(data["日付"])
# グラフ作成
plt.figure(figsize=(10, 6))
plt.plot(data["日付"], data["最高気温(℃)"], label="最高気温")
plt.plot(data["日付"], data["最低気温(℃)"], label="最低気温")
plt.xlabel("日付")
plt.ylabel("気温(℃)")
plt.title("東京の気温推移")
plt.legend()
plt.xticks(rotation=45)
plt.show()
`` ``` ``
これにより、日付と最高気温、最低気温の推移を折れ線グラフで表示します。
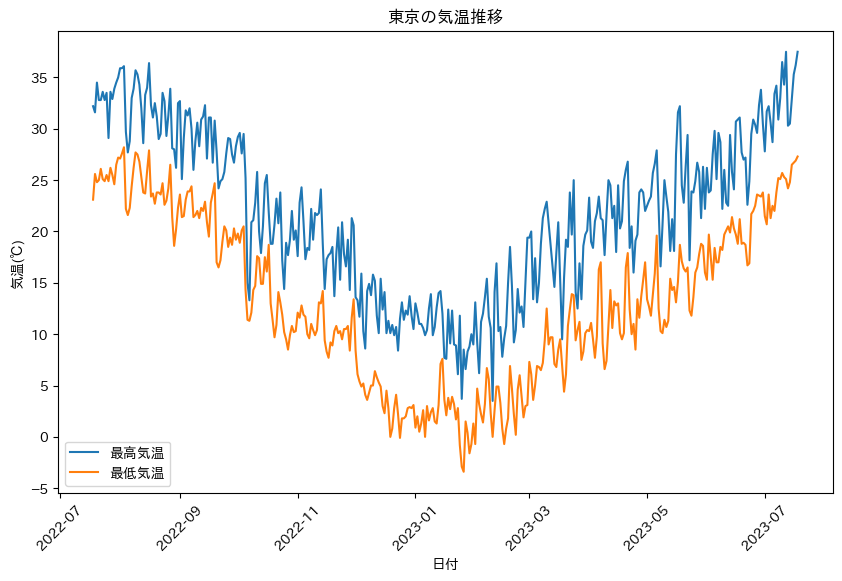
いい感じでグラフが出てきました。import文とか2回呼ばなくてもいいのに…と思わないでもないですが、やりたいことはできているのでよしとします。
もうちょっと複雑なグラフを作成させてみます。
execChatGPT("降水量のある日に絞って、最高気温と最低気温の推移をグラフ化してください。降水量は棒グラフで表示してください。","",None)
コード出力は省略しますが、できてます。いいですね。
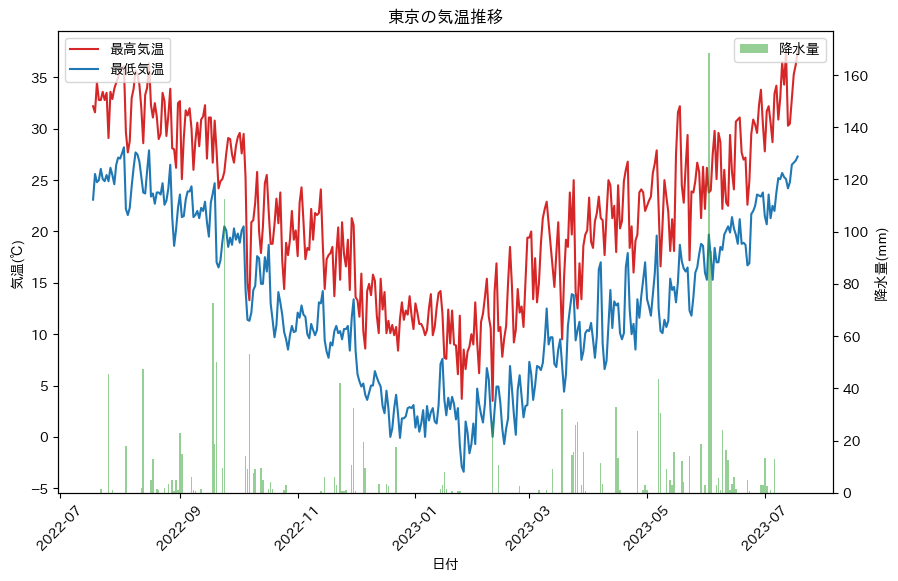
ついでに温度差も出してみます。
execChatGPT("最高気温と最低気温の差分の推移をグラフ化してください。なお横軸は見やすいように月単位の表記をお願いします。","",None)
出力結果は省略しますが、以下のグラフが生成できました。
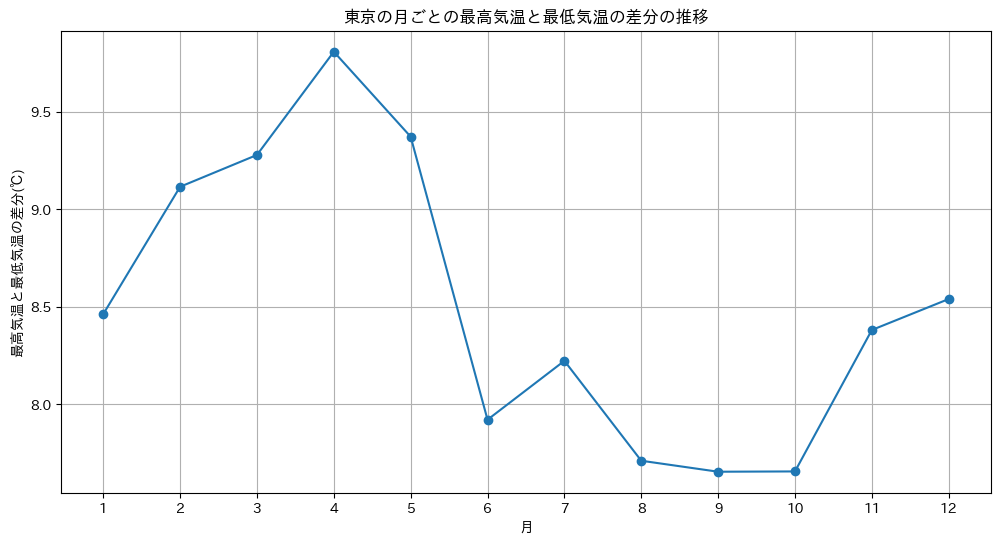
いや、これはなかなか便利そうです。このくらいの分析なら自前で書けばいいじゃないという話もあるかもしれませんが、とっても楽です。
心配ならコードを見て直してもいいですね。
まとめ
Azure OpenAIのChatGPTを使って、Code Interpreterと同じような動きをするJupyter Notebookを作ってみました。結果として、中々いい動きしてると思います。なお、今回はとりあえずサクッと動かしてしまいましたので、ちゃんとやるなら、気になる点、課題は以下です。
- 例外処理してないです。500エラーとか返ってきたりするので、ハンドリング必須ですね。
- 会話履歴が無限保存になっているので、そのあたりの制御も必要です。
- 今回はPythonコードブロックを1つに指定してますが、複数ブロックの取り扱いも考えたいところ
- 変数名などを引き継ぐ形でChatGPTに回答させることを検討したいところ
あたりでしょうか。
とりあえずJupyter Notebook環境とAzure OpenAI(別に素のOpenAIでもいいですが)環境があれば、Code Interpreter のような動きを実現できましたので、Code Interpreter 使いたいけど使えないとか、使えるけど興味あるという方は是非試してみて下さい。