はじめに
(今後ステートフルなAPIが出てきたり、入力トークンの制限が大幅に解除されると状況は変わるかもしれません。2023/6現在での試行錯誤となりますことご理解下さい。)
(※6/15追記 16kバージョン出てきましたね。日本語だと1万語くらいでしょうか。500トークン(300文字くらい?) x 20 往復くらいまでなら対応できるようになりましたが、これでも足りないケースとか、もしくは(3)の方式の要約情報を他でも使う、とかならまだまだ有効な内容かなと思います。)
ChatGPTでアプリを作ると、会話履歴が大量に入らないことに困るタイミングがあると思います。よくある方法は過去10往復の会話のみ保持するとかになると思うんですが、それだと困るシーンも結構ありますよね。
そもそもなんで無限に会話が入らないかというとChatGPT(gpt-35-turboを対象)では、4096トークンという上限があるためです。(実際はもう少し入ったりとかありますけど、動作保証的に)
で、4096トークンって大体日本語だと3000文字ないくらいなので、まぁ長い文章が続くとすぐに到達してしまいます。あと、トークンをたくさん入れると処理が遅くなるというのも困りポイントになるかと思います。
そこで今回はEmbeddingによるベクトル検索を使ったり使わなかったりしながら、長期記憶を持たせる仕組みを作って検証してみたという記事になります。
今回試したのは3つの構成です。
(1) 会話履歴を全部ベクトルにする方式
会話を都度ベクトル化して保存しておき、最新の入力に近しい過去会話を複数件入れ込む
(2) 会話履歴の要約をベクトルにする方式
ある程度の会話のまとまり(n件)を要約した上でベクトル化して保存しておき、最新の入力に近しい過去会話要約を複数件入れ込む
(3) 会話の要約を都度更新する方式
過去会話の要約情報を保持し(Not ベクトル)、ある程度の会話のまとまり(n件)で要約を更新しながら、都度要約情報を入れ込む
結果は以下の表にまとめました。細かいところとかはあるかもしれませんが、だいたいこんな感じです。あえて〇✕△の3段階に区切りましたが、実際は△△とか〇✕とかもう少しファジーです。
| (1)会話全部ベクトル方式 | (2)会話の要約ベクトル方式 | (3)会話要約更新方式 | |
|---|---|---|---|
| 記憶精度 | ✕ (会話の文脈がおかしくなる+検索次第) |
△ (検索次第) |
〇 |
| 超長期記憶 | 〇 | 〇 | △ (要約の規模に依存) |
| パフォーマンス | 〇 | ✕ (要約+検索) |
△ (要約処理) |
| コスト | 〇 (Embeddingのみ) |
✕ (要約+検索) |
△ |
正直、最初はEmbeddingを活用した仕組みが一番いいかと思ったのですが、基本に返って要約を都度更新しながら使いまわす方式が一番使い勝手が良さそうという結果になりました。
いずれもどんな会話なのか、保持したい会話履歴の情報はなんなのかによるんですけどね。
以降は、それぞれの具体的な処理の流れとコードの抜粋の紹介です。
なお、今回検証はすべてメモリ上で行いベクトルDBなどは使っていません&コードはポイントを絞っての抜粋となるのでご注意ください。
(1) 会話を都度ベクトル化して検索させる方式
ChatGPTは入力として過去会話の情報をいれることができますので、以下の図のように、前回の会話往復(入力と出力)を都度Embeddingしてベクトル化してベクトルDBに保存させます。ChatGPTの入出力の詳細についてなどは端折ってます。もしあまり知らないよ、ということでしたら色々参考情報はあると思いますので、調べてみて下さい。
ベクトル化(Embedding)の処理をした上で、最新の入力(図中では、N+1)のEmbeddingから近似度検索を行い、類似した過去会話を複数件(図では3件)取得し、入力のデータとして入れ込む形をとりました。
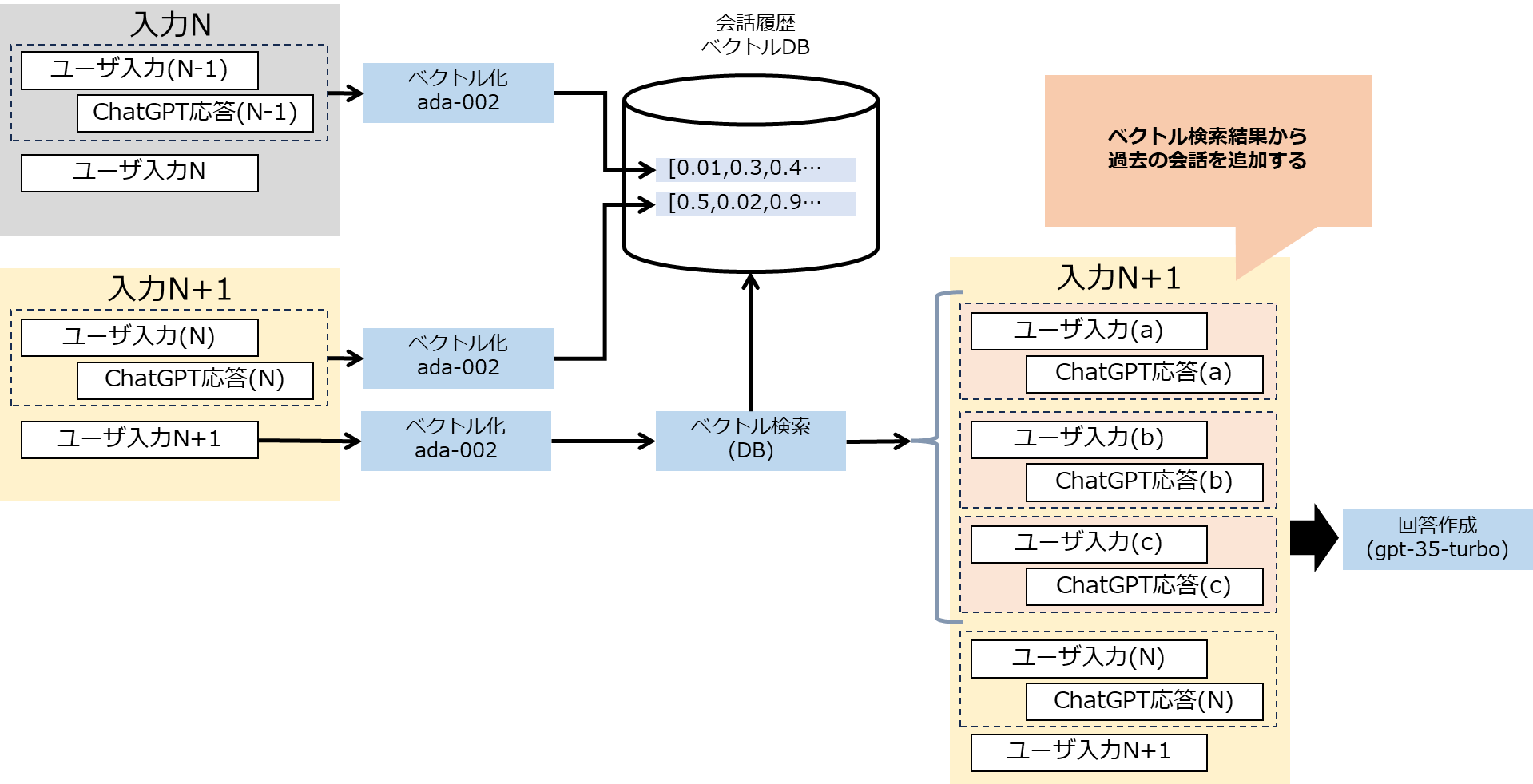
最新の入力の1個前の往復はメッセージの配列全体から取得します。その上で、これより古い情報は不要なので適宜消しちゃってOKです。
# messagesの要素が3以上の場合前回会話往復を保存する(前回入力、前回応答、入力)
if len(messages) >= 3:
saveConvMemory(messages[-3:-1])
saveConvMemoryはこんな感じです。
def saveConvMemory (messages):
# 過去会話往復のjsonをまんまベクトル化する
embedding = get_embedding(json.dumps(jsonable_encoder(messages),ensure_ascii=False), settings.AOAI_EMB_MODEL)
#本当はベクトルDBに保存しないとですね
chatgpt_memory.append({"id":len(chatgpt_memory),"content":messages.copy(),"embedding":embedding})
保存したベクトル情報から、入力のベクトルをとって、さらに近似の3件を取得します。最終的にはremember_memory配列に、検索で近似とされた会話(往復)と直後の往復を3セットとります。(計Max 6往復)
その上でこの配列を、会話の過去履歴に入れ込む方式です。
embedding = get_embedding(message, settings.AOAI_EMB_MODEL)
# ここから先の処理は、本当はベクトルDBに任せる処理
# chatgpt_memoryの各要素にsimilarityを追加
for i in range(len(chatgpt_memory)):
chatgpt_memory[i]["similarity"] = cosine_similarity(embedding, chatgpt_memory[i]["embedding"])
# similarityでソートした上で、先頭の3要素を取得
top3_memory = sorted(chatgpt_memory, key=lambda x: x["similarity"], reverse=True)
top3_memory = top3_memory[:3]
remember_memory = []
for i in range(len(top3_memory)):
remember_memory.extend(top3_memory[i]["content"])
# top3_memory[i]["id"]がリストの最後の要素でなければ
if top3_memory[i]["id"] != len(chatgpt_memory)-1:
remember_memory.extend(chatgpt_memory[top3_memory[i]["id"]+1]["content"])
(1)の方式の考察
例えば最初に名前を伝えておいて、何十往復も会話を重ねた上で、「私の名前を言ってください」とやるとベクトル検索した上で、名前を返してくれるようにはなりました。
ただ、ChatGPTへ伝える会話の履歴がベクトル検索結果によって決まるため、Aの話題、Bの切り出し、Cの結論、みたいな感じで会話が脈絡もない感じとなってしまう結果、今何の会話をしているのかChatGPTにとっても理解不能となり、結果として回答の精度が若干落ちたような動きをしました。
検索対象として個別の会話往復は粒度が小さすぎたことが原因かなと思います。またベクトル検索で類似の高い会話往復を取得してくるのですが、「え?なんでしたっけ?」みたいな会話は検索にふさわしくないという問題もありました。
(2) 会話要約をベクトル化して検索させる方式
(1)では粒度が小さすぎたことが問題と判断したため、ある程度の会話(図中では、5往復)を一度ChatGPTで要約し、要約したものをEmbeddingをつかってベクトル化して、検索対象としたのが(2)の方式です。
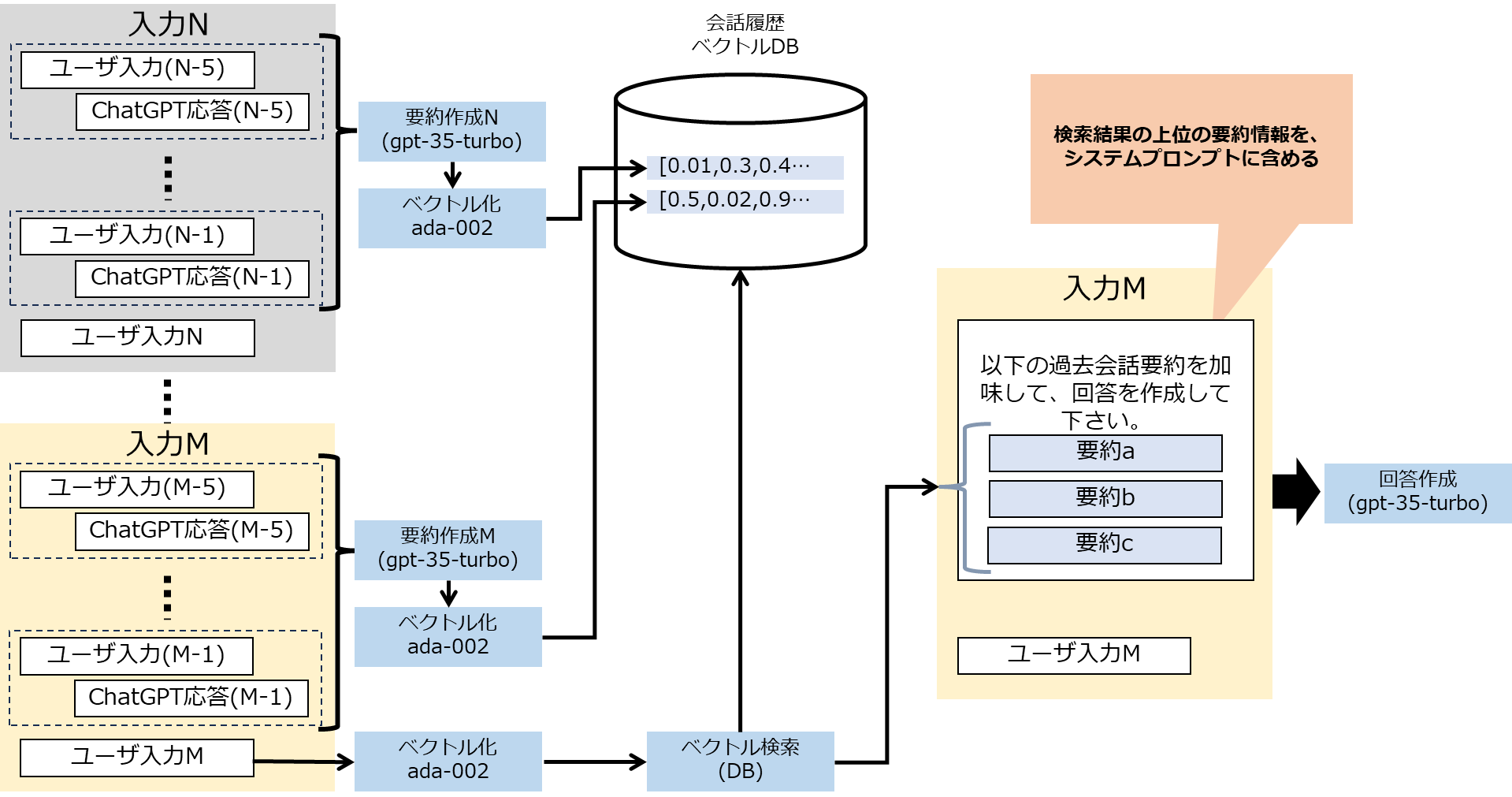
過去5往復(10個の入出力)の会話の履歴を、平文にしたうえで、要約を作成します。処理やプロンプトは以下の通りです。特にテクニックは使っていませんが、この要約のさせ方を変えることで、例えばユーザ属性に絞ってようやくさせたりすることができます。実際の会話の目的や想定に応じて変更すべき部分となります。
if len(chatgpt_conv_history) >= 10:
# message_from_sessionの内容を平文に変換する
text_message = ""
for m in chatgpt_conv_history:
if m.role == "user":
text_message += "ユーザ: " + m.content + "\n"
if m.role == "assistant":
text_message += "ChatGPT: " + m.content + "\n"
# System Prompt
system_prompt = f"""あなたは会話ログの要約生成マシーンです。
入力された会話ログから、簡潔な要約を作成してください。
特に固有名詞は必ず含めてください。
入力される会話ログは以下の形式です。
ユーザ: こんにちは
ChatGPT: こんにちは、あなたのお名前は何ですか?
ユーザ: 私は山田太郎です。
ChatGPT: 山田さん、始めまして。今日は何かお困りですか?
要約例:
ユーザの名前は山田太郎
"""
ベクトルの保存や取り出しはほぼ(1)と同じなため割愛します。
その上で、取り出した情報を回答作成のためのシステムプロンプトに入れ込みます。以下ではpast_summaryという変数に、ベクトル検索の結果近似度の高い3つの要約を入れ込んでいます。
system_prompt = f"""あなたは聞き上手な会話エキスパートです。
会話に関係する適切な質問をたまに入れてください。なお、過去の会話要約情報があればその情報を参考にしてください。
###過去の会話要約情報
{past_summary}
"""
(2)の方式の考察
(1)に比べて意味のある文章が入ってくるため、回答が変になることはありませんでした。が、何十往復も会話を重ねることで、要約情報の数が増えるため、検索にひっかからないと要約できないという問題は発生しました。
また「え?なんでしたっけ?」というような会話はやはり検索にはふさわしくなく、大体うまくいくけど、会話の流れ次第で期待しない要約を使った文章を回答することがある、という形になりました。うーん。。
(3) 会話要約を更新する方式
(1)も(2)も入力次第で期待していない過去会話履歴の情報をベクトル検索の結果持ってきてしまうことがあるため、もう検索は捨てて、会話の要約を都度Updateする方式にしたのが(3)になります。1つの会話要約を更新し続けることで整合性を保ちつつ、検索という揺れる要素を排除した形です。
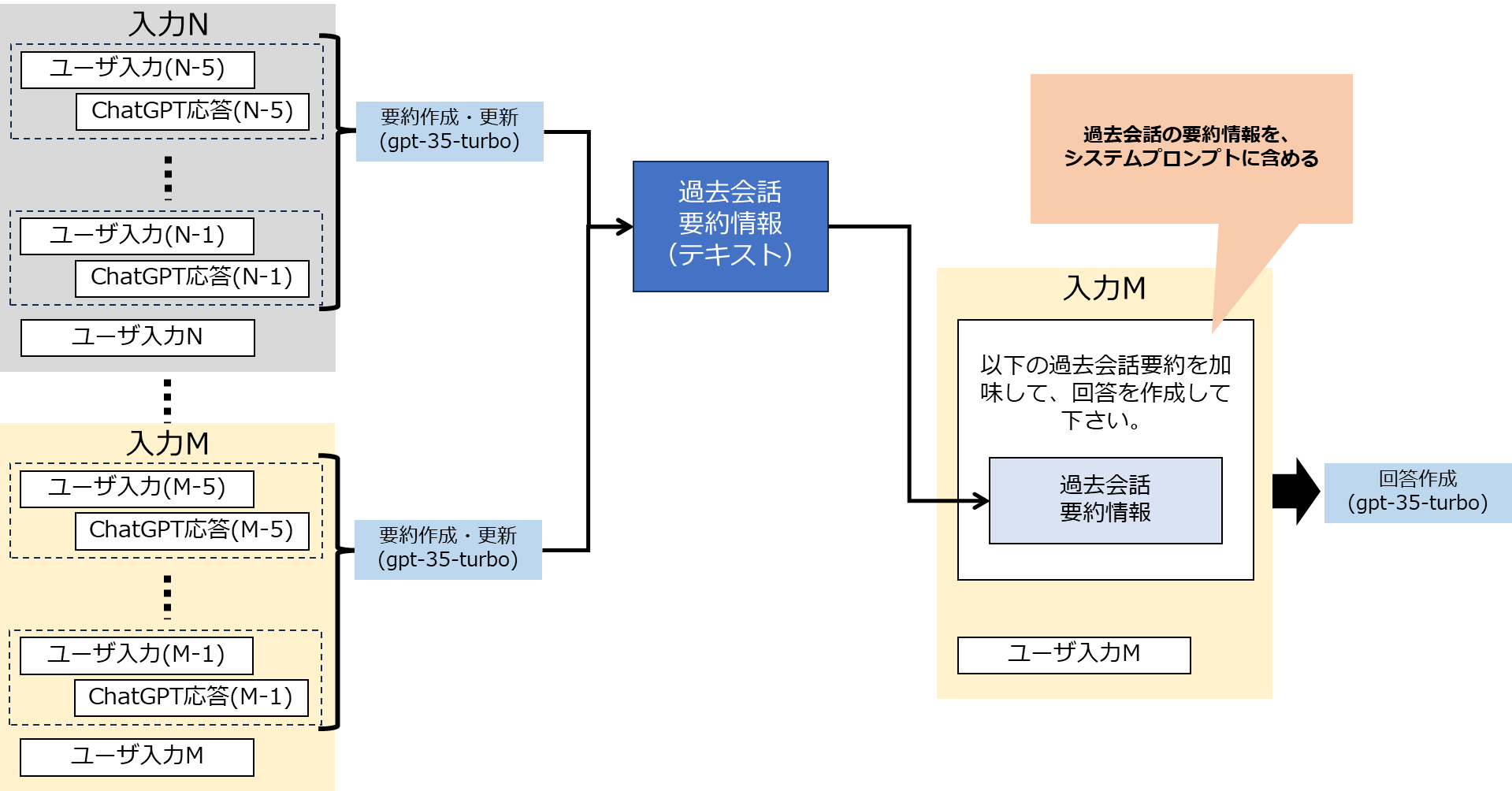
5往復の入出力の会話データを平文にしたうえで、要約し、history_summaryを更新し続けます。
# chatgpt_conv_historyの長さが6以上の場合(5往復ある場合)
if len(chatgpt_conv_history) >= 6:
# message_from_sessionの内容を平文に変換する
text_message = ""
for m in chatgpt_conv_history:
if m.role == "user":
text_message += "ユーザ: " + m.content + "\n"
if m.role == "assistant":
text_message += "ChatGPT: " + m.content + "\n"
# System Prompt
system_prompt = f"""あなたは会話ログの要約生成・更新マシーンです。
入力された会話ログから、簡潔な要約を作成し、以下の###既存の要約情報を更新してください。
特に固有名詞は必ず含めてください。
入力される会話ログは以下の形式です。
ユーザ: こんにちは
ChatGPT: こんにちは、あなたのお名前は何ですか?
ユーザ: 私は山田太郎です。
ChatGPT: 山田さん、始めまして。今日は何かお困りですか?
要約例:
ユーザの名前は山田太郎
###既存の要約情報
{history_summary}
"""
# ChatGPTを呼び出す
summary = call_chatgpt([m.dict() for m in [Message(role="system", content=system_prompt),Message(role="user", content=text_message)]])
# 履歴を更新する
history_summary = summary
あとは以下のプロンプトで、ユーザからの入力に対して、これまでの過去要約情報を参考に回答させます。
# System Prompt
system_prompt = f"""あなたは聞き上手な会話エキスパートです。
会話に関係する適切な質問をたまに入れてください。なお、過去の会話要約情報があればその情報を参考にしてください。
###過去の会話要約情報
{history_summary}
"""
(3)の方式の考察
過去の要約情報が都度更新されていくため、会話が長くなればなるほどこの情報が大きくなっていきます。そのため数百の会話往復をするとトークン制限が気になりだします。が、まぁ数十くらいなら気にならない程度なので普通の用途では問題なさそうです。
また会話の流れによって要約情報が変わるということもなく、(1),(2)と比べて安定した結果を返してきました。
さらにこの要約でどのような情報を持たせるのかを、会話の用途に合わせて設計することで、システム的にも有用な情報となることも期待できます。例えばユーザ属性、例えば注文情報など。
Embeddingを使ったら会話の過去履歴を簡単に取れるだろうと思って始めた検証ですが、結果としてEmbeddingを使わない方式が一番よかったというのは、なんというか面白い結果でした。
考察、おわりに
ChatGPTのトークン制限(4096)があるため、会話が長期にわたり続いた場合、過去の会話情報をどう持てば忘れずに会話を続けられるだろうかと始めた検証でしたが、結果としては(3)の要約情報を都度更新し続け、また要約情報は会話プロンプトに標準的に組み込む方法が一番期待する成果が出ました。
| (1)会話全部ベクトル方式 | (2)会話の要約ベクトル方式 | (3)会話要約更新方式 | |
|---|---|---|---|
| 記憶精度 | ✕ (会話の文脈がおかしくなる+検索次第) |
△ (検索次第) |
〇 |
| 超長期記憶 | 〇 | 〇 | △ (要約の規模に依存) |
| パフォーマンス | 〇 | ✕ (要約+検索) |
△ (要約処理) |
| コスト | 〇 (Embeddingのみ) |
✕ (要約+検索) |
△ |
ただ唯一、要約が大きくなる問題が最終的には解決できておりませんため、中~長期間は(3)+超長期間は(2)の方式を組み合わせるなどは解答としてはアリかなという感触です。
また要約情報を都度更新し続けることで、この情報をシステム的に有意な情報にしておくことで、会話履歴としても使いつつ、システム的にも使うことなどはとても有効かと感じています。例えば注文ボットの場合、会話履歴から注文サマリーを作成するなどできますが、この要約情報を注文サマリーの形式にしてしまうなどです。
このあたりは会話の目的やシステムの用途によって変わるところではありますが、ChatGPTを使ったシステムの設計においては考慮すべきポイントになるかと思います。
実際問題として、会話をしたい、は目的ではなく、その会話によって目的を達成したい、ということになると思いますので。
というわけで、長期の記憶を持たせたかったら、要約情報を都度更新し、入れ込むスタイルが精度的に良いうえに、システム的に有意になりそうなので、考えるなら(3)という結論です。
将来的にトークン制限がなくなる(なくなったとみなせる)ようになっても、ステートフルで長期会話履歴が保持されるようになっても、(3)の形式で有意な情報を都度サマリーにしておけば、使えなくなることは無いテクニックかなと思います。
またパフォーマンスに関しても都度要約する形であれば、非同期にしても良い部分になると思いますので、アーキテクチャ次第ではパフォーマンスへの影響はなしに、要約情報を持たせ続けるなんかもできそうですね。
補足)
今回の検証で「会話がおかしくなった」とか「精度が出なかった」と書いてはありますが、文脈上微妙な感じのニュアンスになりますので、この記事内で紹介するのがちょっと難しく、気になる方は是非検証してみて下さい。