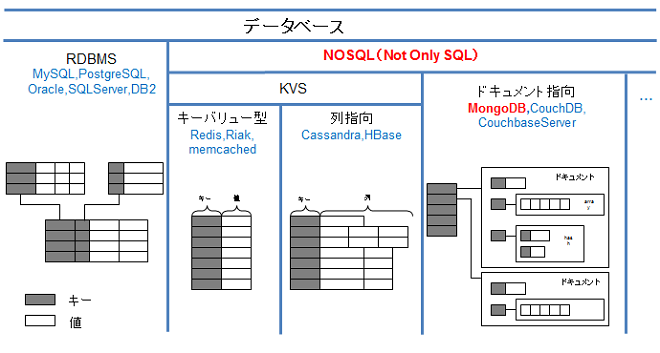
NoSQLとは何か?
NOSQLとは?
SQL以外のDBの総称
SQLではないものを指す。しかしこれはNotOnlySQLであって、「SQLの時代が終わった。」とか「SQLは不要になった。」というわけではない。
「SQLだけではなくて新しいDB技術を使う必要があるというムーブメントの総称。」
なぜSQLだけではダメなのか?
SQLでは充分ではない?
「SQLでは充分ではない。」悟られ始めた背景にはビッグデータの存在があることは間違いない。RDBは単体のハードウェアの上で利用するには最適。しかし、それを複数台並べてデータを分散して管理することは不得意。NOSQLであれば汎用的なハードウェアを並べてあたかも一つのシステムのように膨大なデータを格納して処理することができる。
ビッグデータに対応するとは?
ビッグデータへの対応とは3つのVに対応することを意味する。
3つのV...
- Volume(膨大な量)
- Velocity(速さ)
- Variety(多種多様)
膨大な量
膨大な量というのはデータサイズが大きいものではない。(これはラージオブジェクトという)ビッグデータと言うときには個々のデータサイズが小さくても、それが膨大に集まり、データの大きな塊になってしまうようなケースが多い。そして、こうした大きなデータの塊は近年クラウドの普及などにより増え続けている。現在は回線速度も整い、かつインターネットに繋がる端末も増えた影響で増え、さらに位置情報端末やセンサー等の機器間通信によっても増え続けている。従来はデータ量が増えた場合にはハードウェアの性能を向上させることで対応(スケールアップ)しかしハードウェアの性能向上よりも汎用的なハードウェアを複数台並べて1台の高性能なハードウェアのように利用できればトータルコストを大きく引き下げることになる。
速さ
「ビッグデータに対応する」とは膨大なデータの塊を速く、そしてリアルタイムに近い形式で処理する必要があることも含む。
例として「Twitterには日次12TBものデータが発生し、仮にハードディスクの書き込み速度が毎秒約80メガバイトのマシンを1台だけ使うとしたら、全てのデータを格納するだけでも約42時間(12TB/80MB)かかることになる」と述べている。1日分のデータ格納に2日もかけてられないので、複数台のマシンを並行して使うことを実現し膨大な量のデータを早く処理するソフトウェア技術は必須。
多種多様
ビッグデータはデータ同士の構造が複雑化してきていることも特徴の1つである。クラウドに集まるビッグデータは、単純なログデータ、文章、写真や動画だけではなく位置情報やセンサーデータ(センサーが拾った情報)、友人同士のつながり等を示すソーシャルグラフやリンク情報などデータの形が多種多様であり、相互の関係も複雑である。またネットサービスの多くで発生するように突発的なアクセスの増加が頻繁に起こり、量や質が激しく変化する。そのビッグデータにはSQLで前提となる構造化は困難であるためNOSQLが求められてきた。
WebサービスがNOSQLを採用した理由
大規模Webサービスの技術者は多くのブログなどで採用した理由を述べている。
高い処理能力が欲しい
NOSQLはRDBと比較してかなり高い処理能力を提供する
データベースクラスタを設定する際に水平拡張したい
多くのNOSQLはノードを追加して水平方向に拡張できる
汎用的なハードウェアを利用したい
NOSQLデータベースは汎用的なハードウェアでクラスタを簡単に作ることができるように設計されている
複雑で多種多様に変化するデータ構造に対応したい
1部のデータベースではRDBでは表現しにくいドキュメント指向型やグラフ型といったデータ構造をサポート。スキーマ定義を持たないためデータの構造を事前に定義する必要がなく、多種多様に変化するデータ構造に柔軟に対応出来る。
高可用性と高信頼性が必要
多くのNOSQLでは複数のサーバーにデータを複製、分割することで高い可用性と信頼性を確保している。
SQLと比べてNOSQLが劣っている点
機能が豊富ではない
SQLが集合論に基づいている完成度の高いデータベース言語であるのと同時にRDBMSは豊富な機能を備えている。一方でNOSQLは主に「書き込み」「読み込み」のシンプルな動作をするにすぎない。「結合(Join)」をはじめとする様々な演算子も通常はサポートされていない。
データの整合性が緩い
RDBMSはデータの更新をかける際には「排他制御」の仕組みを備えている。しかしNOSQLはこの考え方を緩めている。
結果整合性で良いという考え
ビッグデータの環境では多数の人が同時にアクセスを行う都度に排他制御を実施していては大量に速く処理するのは難しくなってしまう。速さを優先するために「データの整合性は、全てのアプリケーションにおいて必ずしも必要であるわけではない」とする考え方である。
一時的にデータの整合性が保持されない状態を許容するが結果的に整合性が取れていればいいという考えである。
SQLとNOSQLの長所を組み合わせて上手に使い分けることが重要
NOSQLデータモデル分類
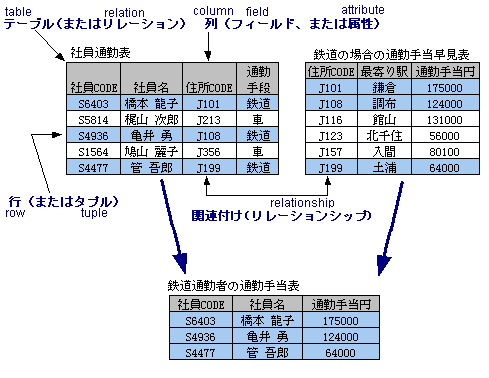
SQL
RDBでは行と列で構成されるテーブル(表)の形でデータ構造の設計をして、その上でテーブル間の関係性を定義する。RDBでは定型のデータ同士の関係性をあらかじめ定義することによりデータの結合、検索、集計や並び替えなどSQL分で書かれた問い合わせ内容に応じるための豊富な機能が使えるようになっている。
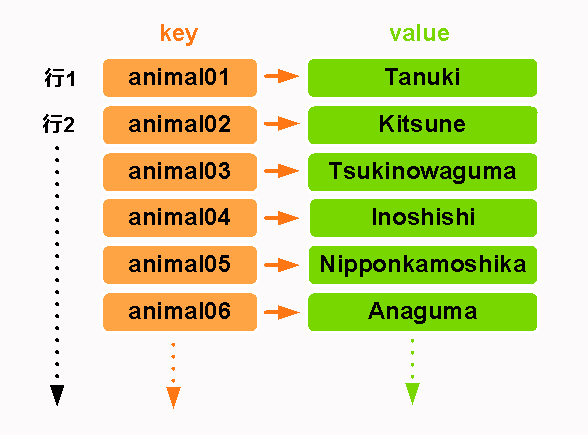
キーバリュー型
「キー」と「バリュー」という組み合わせからなるシンプルなデータモデルを基本とする。
ここでいうキーはRDBにおけるキーの概念とはやや異なり、バリューにつけた識別番号のようなもの。バリューは個々のキーに紐付いたデータである。このキーとバリューを1対1で管理する。新しいデータが追加されるたびに行が増えるイメージ。
該当するDB:Dynamo,Redisなど
特徴
スケールアウトに最適
RDBの場合・・・データ関係性が厳密に定義されるので1つのテーブルの列定義を変更している最中に何らかの読み書きが発生した場合に他のテーブルとの整合性を保つための排他制御が必要になる。大規模に分散された複数のサーバーがネットワークを介してそれぞれのデータの関係性を維持するのが難しい。
キーバリュー型の場合・・・数十台、数百台にサーバーが増えたとしても容易に分割することができる。キーの管理を担当するサーバーなどがどこにキーがあるかを把握していれば良い。
カラム指向型
キーバリュー型を少し高度にしたデータモデルがカラム指向型である。カラム指向型はキーがバリューと1対1ではなく行に対してのキー(row key)が複数のカラムを持つことができる。また行キーごとのカラム数は動的に増やすことができる。またキーバリュー型と異なる全てのカラムにバリューが挿入されていないことも許容する。
該当するDB:Cassandra,Bigtable,HBaseなど

特徴
キーバリュー型を拡張したようなデータ構造
行と列の概念を持たせたデータモデルである。しかしRDBのような表ではなくて、複数のキーとバリューを行キーという識別子で持たせることができるもの。グループ化したキーバリューをカラムと呼んでいる。
ドキュメント指向型
ドキュメント指向型はJSONやXMLといったデータ形式で記述されたドキュメントの形でデータを管理する。各ドキュメントは階層構造を持たず、相互の関係が横並びに管理される。
該当するDB:MongoDB,CouchDBなど
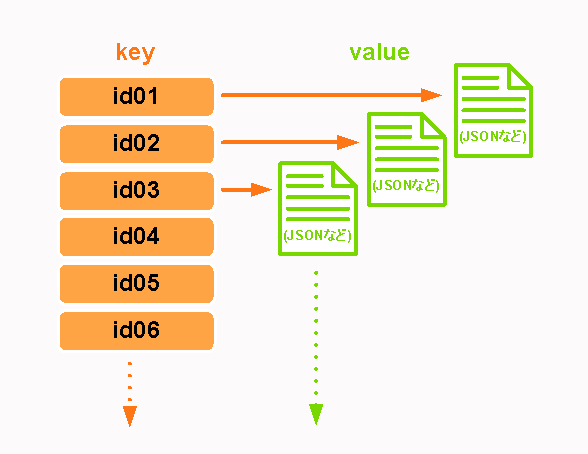
特徴
ドキュメントをユニークIDで特定できる
JSONなどのドキュメントを階層構造を持たずフラットに管理されていることによりデータアクセスをユニークIDで行える。ニュースサイトやブログなどはドキュメント指向のデータモデルをそのまま自然に表現できることからもWebアプリケーションなどで多用されている。
ザックリまとめると下記のような...