はじめに
AI Centerでプリセットされている機械学習モデル「TPOT AutoML Classification」を検証してみます。
AI Centerの大まかな使い方は以下の記事で説明しています。
つかうもの
※クラウド環境は2022年12月時点のもの
- Automation Cloud(AI Center) Enterprise版
モデルの概要
このモデルは、表形式データ(csv)を入力として、分類を実行するモデルです。
デプロイ前にパイプライン(学習)をしてから使用する必要があります。
GPUに対応しています。
このモデルは、「AutoML」という機械学習モデルの構築を自動的に行える仕組みをもったものになり、高度な知識を持っていなくても機械学習モデルを扱うことができます。
モデルには、「分類」と「回帰」があり、今回は「分類」を使用します。
「分類」とは、クラス(離散値)を予測することで、0または1,2,...や、True or False、犬か猫かのように仕分けを行うものです。一方、「回帰」は数値(連続値)を予測するもので、売上分析のように「いくら売り上げることができるか」など実業務に使用されています。
また、AI CenterにおけるAutoMLの分類・回帰モデルには、「XGBoost」を使用したモデルも用意してされています。まだ未検証なので詳細は割愛しますが、いずれ記事にしようと思っています。
今回の検証は「顧客離脱分析」をやってみようと思っています。顧客離脱分析とは、あるサービスに関する顧客情報や契約情報のデータをインプットして、顧客がサービスを解約するかしないかを予測するものです。今回はKaggleにあるオープンデータを活用します(Telco Customer Churn)。
データセット
このモデルがサポートしているデータセットは、CSVファイルのみとなります。用意するCSVファイルは以下の条件に従います。
- 1行目は必ずヘッダー行とする
- target_column以外のすべての列は数値 (整数または小数) とする
target_columnは予測結果を示す列です。今回の顧客離脱分析だと、顧客が離脱したかどうかを示す「Churn」列になります。
target_column以外のすべての列は数値とする必要があるので、数値以外の文字が入っている場合はデータの整形を行います。
データの整形方法には、いくつかの方法がありますが、今回は「One-Hotエンコーディング」を使用して、データを変換します。
One-Hotエンコーディング

One-Hotエンコーディングとは、上記例の通り、列名をカテゴリ(A型、B型、O型、AB型)にして、一致した場合は1、それ以外を0にする方法です。この場合、列数はデータカテゴリの数だけ増えることになります。上記例は血液型なので、カテゴリは4つだけですが、ユニークな値が多い場合、列数が膨大になる可能性もあります。
最終的にデータの列数は、メモリ使用量と直結し計算速度に影響を与えるので、列数が多くなりそうな場合は別の方法を使って整形するか、そもそも該当の列を削除(機械学習に列を使用しない)するかします。
今回の検証では、元のデータは20列(予測に不必要な顧客IDは削除)でしたが、One-Hotエンコーディングを行った結果、40列になりました。
パイプライン
このモデルは、フルパイプラインとGPUをサポートしています。
パイプライン実行時に使用できる環境変数は以下の通りです。
| パラメータ | 説明 |
|---|---|
| max_time_mins | パイプラインを実行する時間。時間が長いほど探索時間が増え、適切なモデルを見つけられる可能性が上がる(デフォルトは2) |
| target_column | target_columnの列名(デフォルトはtarget) |
| scoring | パイプライン画面に表示されるスコアを決める評価関数。accuracy(正解率)の他、recall(再現率)やAUC(ROC曲線の下の領域)などを選択できる(デフォルトはaccuracy) |
| keep_training | 途中でパイプラインを中断する場合はTrueを設定すると、中断した個所からパイプラインを再開できる(デフォルトはFalse) |
今回の検証では、以下のように実行しました。
用意した学習用データは7,000件です。

実行結果は以下の通りです。
実行時間は15分ほど、スコアは0.8(まあ良しとするレベル)です。

もし、学習データの中に数値以外が入っていた場合は、パイプラインはエラーとなります。学習に使用するデータは綺麗なものは少なく、例外的なデータが混入している可能性が多いので、注意して除去しないといけません。今回使用したデータにも、空値としてスペースが混入していました。

※max_time_minsを10にしてパイプラインを実行してみましたが、今回の検証では実行時間もスコアも、max_time_minsがデフォルトの時と変わりませんでした。データの件数やバラツキなどの諸条件によって結果が変わってくるものだと思います。
実行結果
デプロイしたMLスキルを使ってみます。
以下のように実装しました。
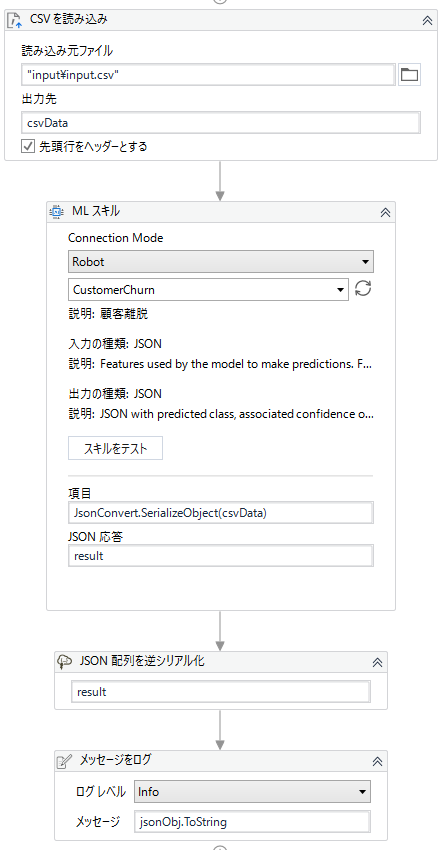
このモデルのインプットはJSONなので、インプットデータ(CSV)を「CSVを読み込み(ReadCsvFile)」アクティビティにてDataTable型で読み取った後、JSONに変換します。
JsonConvert.SerializeObject(DataTable型変数)
インプットデータとなるCSVファイルですが、学習用に用意したCSVファイルからtarget_column(今回の検証ではChurn列)を削除したものになります。target_column列が残っていたら実行時エラーとなるので注意してください。
以下が実際の検証結果です。
インプットは3件(0が離脱しない、1が離脱する)で、1件目:0、2件目:1、3件目:0になるのが正解です。
結果は3件とも正解でした。

おわりに
モデルの使い方に関しては難易度は高くなく、初心者でも使えるものだと思います。
ちなみに今回、学習データの整形にもUiPathを使いました。データの整形は機械学習のプロセスで最も面倒なものですが、UiPathのように簡単にプログラムを組めると作業が捗ります。
参考