今回の内容
これまで、テキスト分類編では機械学習の学習と分類のコア機能を、WebAPI編ではその分類機能をRESTのWebAPIとして提供する手順を説明してきました。
今回はこれらの内容を踏まえて、仕上げにサービスのフロントエンドを作ります。RubyやPythonなどで作るWebサーバサイドのアプリではなく、JavaScriptを用いたSPA(Single Page Application)として作っていきます。
Vue.jsのボイラープレートを基に、手を加えた行数は100行程度です。
ソースはhttps://github.com/shuukei-imas-cg/imas_cg_words で公開しています。
動作確認環境
フロントエンドの開発のため、これまでの記事と違いWindows上で開発・動作確認しています。
- Windows10
- node.js 7.5.0
- npm 4.1.2
- Vue.js 2.2.2
- vue-resource 1.3.1
- Bootstrap 3.3.7
- Chrome バージョン57
Vue.jsを使用するため、IE8以下のバージョンでは動作しません。
使用するフレームワークについて
Vue.js
Vue.jsはWebサイトのユーザインターフェースを構築するためのフレームワークです。AngularやReactと比べると覚えなければならない仕様がコンパクトにまとまっており、既存のWebサイトの動作をすこしリッチにしたい、という用途で部分的に導入していくことにも向いています。
今回はWebpackを用いたボイラープレート(雛形)でVue.jsを導入するため、割とがっつりとJSのエコシステムに浸かることになりますが、開発時のLintやホットリローディングが便利なのでぜひチャレンジしてみてください。
サンプルを動かすだけであれば特に迷う部分はありません。
Bootstrap
BootstrapはTwitter社が開発したCSSのフレームワークです。今回は最低限の体裁を整え、PCとスマートフォン両方から利用するために使用しています。
サンプル実行手順
node.jsが必要です。あらかじめ開発環境にあわせたバイナリをインストールしておいてください。
cd imas_cg_words/ (初回でcloneしたディレクトリ)
git pull
cd frontend/imas_cg_words/
# 必要パッケージのインストール。node_modules/ ディレクトリ以下にインストールされる(時間がかかります)
npm install
# ローカルサーバで起動
npm run dev
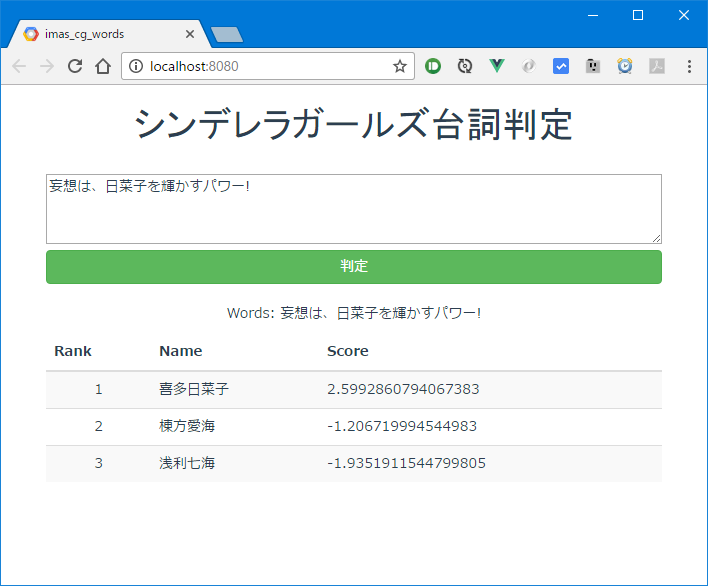
npm run devを実行すると、ブラウザが起動し、http://localhost:8080 でページが開きます。
frontend/imas_cg_words/src/main.jsの、Vue.http.options.rootの値を、自分で起動したWebAPIのURIに書き換えてください。エディタでmain.jsを書き換えた時点でブラウザが自動でリロードします。
TEXTAREAに適当なテキストを入力して判定ボタンを押し、結果が表示されれば成功です。
ビルドとデプロイ
npm run build
frontend/imas_cg_words/dist/ 以下にビルドされたhtml, js, cssなどのファイルが生成されますので、適当なWebサーバに配置してください。index.htmlをローカルでブラウザから読み込んでも動作しません。
解説
ソースファイルの構成
frontend/imas_cg_words/ ディレクトリのうち、このSPAを構成しているのは主に以下の5つのファイルです。
- index.html
- src/main.js
- src/App.vue
- components/Predict.vue
- modules/Words.js
index.html
いわゆる普通のindex.htmlです。titleタグやmetaタグ、また、Google Analyticsのスクリプト等はこのファイルに記述します。<div id="app"></div> が含まれていることが重要で、このdivタグの中にApp.vueの内容が展開されます。
src/main.js
JavaScriptのメインプログラム的なファイルです。エントリポイントと呼ばれます。
Vue.js自体と、App.vueというファイル(このファイル名はお約束的に決まっています)、Vue.jsのライブラリとしてvue-resouceをインポートしています。vue-resouceはHTTP通信(いわゆるXHR)を行うためのものです。
Vue.http.options.rootの値を適切に設定してください。
import Vue from 'vue'
import App from './App'
import VueResource from 'vue-resource'
Vue.use(VueResource)
Vue.http.options.root = 'http://(YOUR WebAPI HOST And PORT)/imas_cg-words/v1'
src/App.vue
このファイル中のtemplateタグで記述された内容が、index.htmlの<div id="app">タグ内に反映されます。
Vue.jsをWebpackで使用する場合、HTML、JS、CSSを「コンポーネント」単位で一つの.vueファイルにまとめることができます。これによりコンポーネント単位でプログラムが部品化でき、CSSの名前空間にスコープを適用することができます。
内容的には、<h1>タグを記述して、/components/Predict.vueを読み込んでいるだけです。<predict>タグの部分にPredictコンポーネントの内容が反映されます。
<template>
<div id="app" class="container-fluid">
<div id="header" class="container-fluid">
<h1>シンデレラガールズ<wbr>台詞判定</h1>
</div>
<predict></predict>
</div>
</template>
<script>
import Predict from './components/Predict'
export default {
name: 'app',
components: {
Predict
}
}
</script>
<style>
(省略)
</style>
src/components/Predict.vue
このファイルが今回のSPAの主な機能を担っています。templateタグの内容から見ていきましょう。
textareaタグに入力された内容は、v-modelによってwordsという変数に双方向バインディングされています。入力された内容はリアルタイムに変数wordsに反映されます。
button id="predict"は「判定」ボタンです。v-onによって、押されたときのイベントに関数hantei_btnをアタッチします。また、v-bind:disabled=により、変数btn_disableの値がfalseのときはボタンが押せないようdisableされます。
v-ifは変数の値によって(評価結果がtrueかfalseか)、要素の表示/非表示を制御します。v-forは繰り返し構文で、<tr v-for="ret in predict_results">は、変数predict_resultsから値を一つずつ変数retに取り出し、その内部でtdタグとその内容を描画しています。
<template>
<div class="predict container-fluid">
<div class="wordsinput container">
<textarea id="words" v-model="words" v-on:keyup.ctrl.enter="hantei_btn" placeholder="台詞を入力してください"></textarea>
<br>
<button id="predict" v-on:click="hantei_btn" type="button" class="btn btn-success btn-block" v-bind:disabled="btn_disable">判定</button>
</div>
<div v-if="error" class="container">
<p class="bg-danger">APIサーバの反応がありません。サービスはメンテナンス中です。</p>
</div>
<div class="input_words container" v-if="input_words != ''">
<p>Words: {{ input_words }}</p>
</div>
<div class="idol-results container">
<table id="results" class="table table-striped">
<thead v-if="predict_val != ''">
<tr>
<th>Rank</th><th>Name</th><th>Score</th>
</tr>
</thead>
<tbody>
<tr v-for="ret in predict_results">
<td class="number">{{ ret.number }}</td><td class="name">{{ ret.name }}</td><td class="score">{{ ret.score }}</td>
</tr>
</tbody>
</table>
</div>
</div>
</template>
次にscriptタグの範囲です。
import文でWordsNormalizationという関数をインポートしています。
Vue.jsのコンポーネントでは、変数を定義するdata ()は関数である必要があるため、returnで値を返すようにしています。
methods:の中括弧内ではコンポーネントの関数を定義します。
predictが実際にWebAPIに問い合わせを行っている関数です。変数wordsにTEXTAREAに入力したテキストが反映されており、それを文字列の正規化(WordsNormalization)したうえでURLエンコードし、WebAPIにクエリします。
this.$http.get(param)後の処理は成功時のコールバックとエラー時のコールバックに分けて記述します。HTTP GET成功時かつコンテンツの長さが0でない時に、変数predict_valにWebAPIの返り値response.bodyを代入します。
computed:の中括弧内では、「算出プロパティ」を定義しています。算出プロパティpredict_resultsは、それが依存するpredict_valの値が変更されたときだけ自動的に再計算されて値がセットされるプロパティです。
ここでは、単にWebAPIで取得したJSONに連番numberを振るために使っています。
<script>
import WordsNormalization from '../modules/Words.js'
export default {
name: 'predict',
data () {
return {
words: '',
input_words: '',
predict_val: '',
error: false
}
},
methods: {
hantei_btn: function () {
this.predict()
},
predict: function (event) {
if (this.words === '') {
return
}
var param = 'predict/' + encodeURIComponent(WordsNormalization(this.words))
this.$http.get(param).then(response => {
// success callback
if (response.body.length === 0) {
this.predict_val = ''
this.input_words = WordsNormalization(this.words)
return
}
this.predict_val = response.body
this.input_words = WordsNormalization(this.words)
this.error = false
}, response => {
// error callback
this.error = true
this.predict_val = ''
})
}
},
computed: {
predict_results: function () {
if (this.predict_val === '') {
return ''
}
var ret = []
for (var i = 0; i < this.predict_val.length; i++) {
ret[i] = {'number': i + 1, 'name': this.predict_val[i]['name'], 'score': this.predict_val[i]['score']}
}
return ret
},
btn_disable: function () {
return this.words === ''
}
}
}
</script>
src/modules/Words.js
半角カタカナから全角カタカナへの変換や、一部の文字列の正規化(中黒"・"の3連を3点リーダ"…"に変換するなど)を行う関数を定義しています。
Predict.vueからインポートされています。
まとめ
ノンプログラミングで機械学習サービスが作りたい! テキスト分類編
ノンプログラミングで機械学習サービスが作りたい! WebAPI編
ノンプログラミングで機械学習サービスが作りたい! フロントエンド編 (本記事)
3回に分けて機械学習を用いたサービスを構築する手順を説明しました。機械学習もフロントエンドも詳しい記事はたくさんありますが、バックエンドからフロントエンドまで一気通貫に説明した記事はあまりないような気がします。
ざっくりとした全体のイメージを掴んでいただければ幸いです。
負荷分散について
JubatusはZooKeeperを用いて複数のサーバプロセスを協調動作させる分散モードに対応しています。これを用いて複数のサーバに分散し、それらに対してWebAPIサーバも複数個用意することで、一般的なWebサーバと同様の負荷分散手法が適用できます。
今後の発展
テキスト分類を行う機械学習のアルゴリズム部分には様々な工夫の余地があります。Jubatusの設定ファイルの内容を変えてみたり、学習データの前処理を行うことでも正答率が変わってきます。実は、単に高い正答率を求めるのであればMeCabを使わず、文字2-gramを特徴としたほうが成績は良かったりします。
Jubatusの真骨頂はオンライン機械学習(分類サービスを提供しながら学習できる)なので、それを用いて新規データの学習機能をエンドユーザに開放することも考えられます。
オリジナルの台詞データを集めてあなただけの台詞判定サービスを作ってみましょう(?)
最後に(重要)
もしこの記事を気に入っていただけたら、あなたが「いい」と思った分だけ、アイドルマスターシンデレラガールズで2018年4月頃に開催されると思われる「第7回シンデレラガール総選挙」で喜多日菜子に投票してください。