はじめに
地理空間データの勉強を始めようとして、村上大輔さんの「Rではじめる地理空間データの統計解析入門」(2022年4月6日発売)を読み初めました。まだ半分も読んでないのですが、間違い無く良書(英語でも名称が翻訳されていてさらに好き)なので、本の中で紹介されていた手法を使い手を動かしてみました。分析テーマは「新型コロナウィルスの感染者の割合は、近隣の都道府県に影響するのか」です。本書で紹介されているモランI統計量(Moran's I Statistics)を用い、分析しています。なお、扱うデータは違えど、書いているコードの9割は本書に記載されている物を使います。
警告
以下分析はあくまで試験的な物です。このデータ分析結果に対して一切の責任を負いかねます。
ネットの情報に惑わされず正確な情報を信じましょう。
モラン I 統計量(Moran's I Statistics)
モラン I 統計量(Moran's I Statistics)とは空間相関(地理的に近いところと遠いところのデータの相関)を評価するものです。「エリアAの数値と全体の平均の差が、エリアAの近隣のエリアの差と近しいか」を比べています。以下の式で表されます。
$$
I = \dfrac{N}{\sum_i \sum_j w_{ij}}\dfrac{\sum_i \sum_jw_{ij}(y_j-\bar{y})(y_i-\bar{y})}{\sum_i(y_i-\bar{y})^2}
$$
$w_{i,j}$は近接行列を表し、ゾーン$i$と$j$の近さを表す重みです。
※詳しくは本書を読んでください
モランI統計量は相関係数のように「1に近づくほど正の相関が強い」ということになります。この場合の「正の相関」とは、空間相関が強い、つまり、周りのゾーンに数値が依存するという事です。
例)大阪府のたこ焼きの消費量が高ければ、大阪府近隣の県も高い
実装
データ
データは以下のオープンソースと、NipponMapライブラリの日本地図データを使用します。
コード
library(rgdal)
library(spdep)
library(RColorBrewer)
library(NipponMap)
library(dplyr)
df = read.csv('nhk_news_covid19_prefectures_daily_data.csv')
df = df %>%
filter(日付 == "2022/4/20") %>%
filter(都道府県名 != "沖縄県")
shp = system.file('shapes/jpn.shp', package = 'NipponMap')[1] #日本地図読込
pref = read_sf(shp) #日本地図読込
pref = pref[pref$name != "Okinawa",] #可視化の都合上沖縄県を除外(ごめんなさい!!)
st_crs(pref) = 4326 #WGS84のEPSGコードを指定(地域のコードの形式を指定)
pref = st_transform(pref, crs = 6677) #軽度緯度情報をメートルに変換
pref$jiscode = as.integer(pref$jiscode)
df = merge(df, pref, by.x = c('都道府県コード'), by.y = c('jiscode'))
EPSGコードについてはこちらに詳しい解説が記載されています。
可視化
昨日(2022/4/20)の各地の直近1週間の人口10万人あたりの感染者数を表示しています。
Plot = data.frame(region = tolower(df$name), value = df$各地の直近1週間の人口10万人あたりの感染者数)
non_oki = c(Plot$region)
admin1_choropleth(country.name = "japan",
df = Plot,
title = paste("mean:", mean(Plot$value)),
legend = "",
num_colors = 4,
zoom = non_oki)
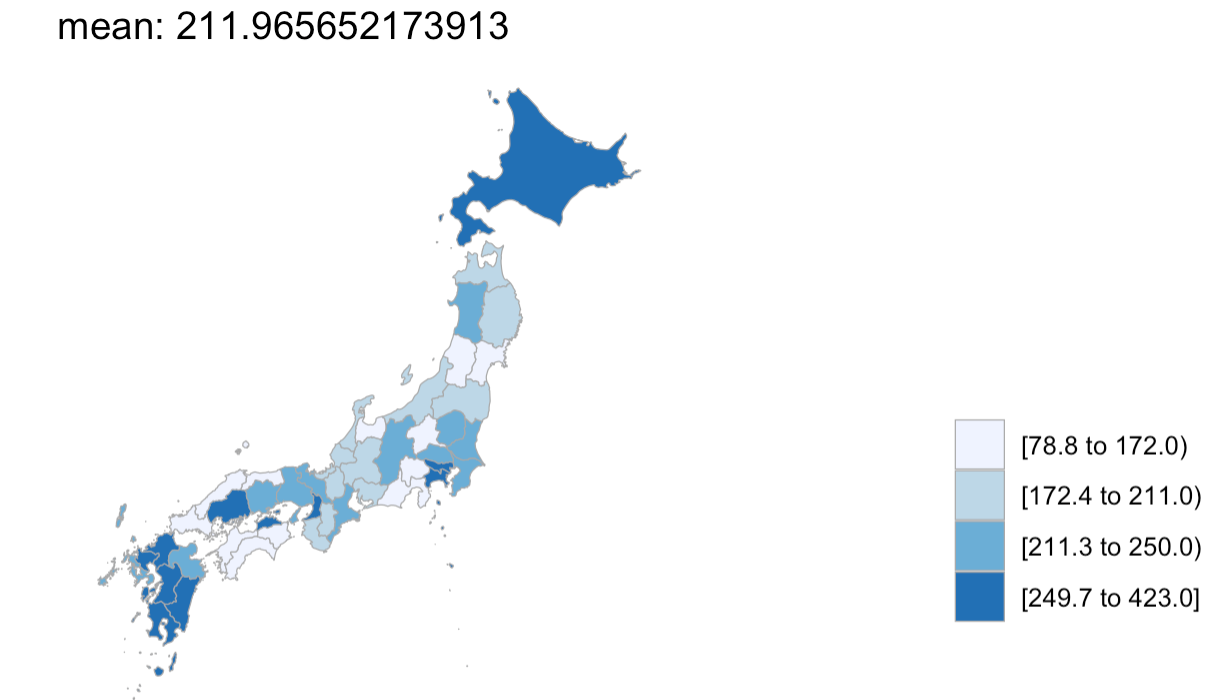
むむ、可視化だと何とも言えない...
検定
可視化だと何とも言えないので検定をしてみましょう。
coords = st_coordinates(st_centroid(pref)) #都道府県の中心を算出
knn = knearneigh(coords, 4) #近隣4ゾーンを指定
nb2 = knn2nb(knn)#nb形式に変換(近接情報を格納する型)
w = nb2listw(nb2) #近接情報をマトリクス形式に変換(距離に対しての相関係数行列的なもの)
近隣ゾーンについてはこちらを参照してみてください。要はKNNです。
モランI統計量検定はmoran.testで行えます。
moran.testはデフォルトで「H0(帰無仮説):$I \le E(I)$」「Ha(対立仮説):$I>E(I)$」が、設定されています。
moran = moran.test(df$各地の直近1週間の人口10万人あたりの感染者数, list = w)
moran
結論
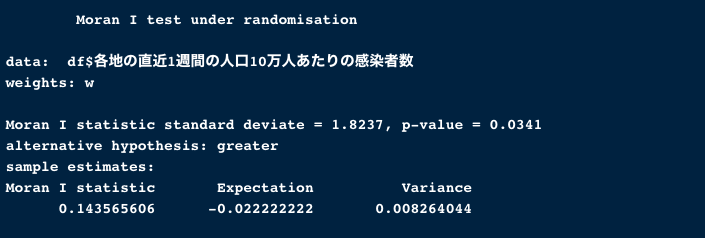
p-valueを見てみると0.05より小さい事がわかります。
よって、「H0(帰無仮説):$I \le E(I)$」は棄却されます(Reject Null)
つまり、「Ha(対立仮説):$I>E(I)$を採用し、「5%の有意水準に基づき、ある県の新型コロナウィルスの感染者の割合(各地の直近1週間の人口10万人あたりの感染者数)は、近隣の都道府県に影響する」
要は、「新型コロナウィルスの感染者の割合は、近隣の都道府県に影響する」
おわりに
村上大輔さんの「Rではじめる地理空間データの統計解析入門」で紹介されている、モラン I 統計量(Moran's I Statistics)を用い、「新型コロナウィルスの感染者の割合は、近隣の都道府県に影響するのか」という検定をしたところ、「新型コロナウィルスの感染者の割合は、近隣の都道府県に影響する」 という分析結果がでました!(あくまでモランI統計量検定を用いた私個人の見解です。ネットの情報に惑わされず正確な情報を信じましょう)
参考文献