はじめに
この記事は、みなさんの理解を助けるためだけに。記載しています。
きっかけ
JARファイルメモ帳で開いてみたら文字化けしてました。
文字化け???とおもったら・・・これのことかな。
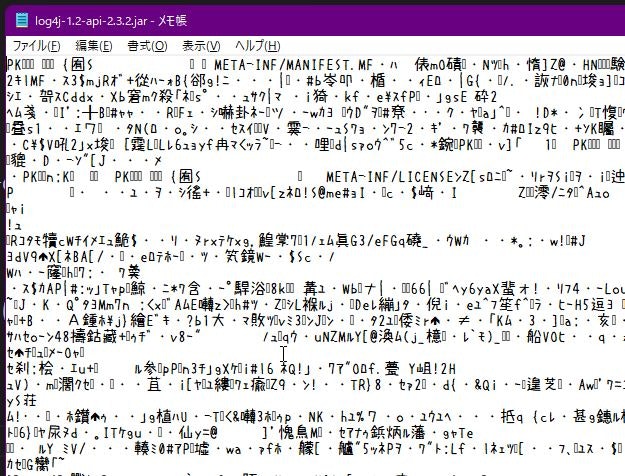
これ。文字化けじゃないんですよ?なぜなら「文字じゃない」からね。。。
バイナリエディタ使ってみようぜ
バイナリエディタとは、ファイルを「テキスト」などのファイル形式を意識せず、バイナリ列(つまりは2進数でどうあらわされているか)を見せてくれるエディタです。もちろん編集も可能です。
世界に、バイナリエディタは数多あるのですが、手ごろなVS codeの拡張機能「Hex Editor」を導入してみましょう。拡張機能で「Hex」で検索!!
詳細な手順はここ
バイナリエディタでファイルを観察する
**テキストであろうが、画像などのバイナリであろうがコンピュータにとっては01のデータの集まり。どっちも同じじゃん。**そう思ったあなた。いい感じの理解です。ここからは、なぜ「テキストエディタがバイナリファイルを見ることができないか」を知るために、それぞれのファイルの中身を見比べてみることにしましょう。
以下のコマンドでテキストファイルを作ってみましょう
mkdir c:\dev\workspace\temp
echo I have a pen > c:\dev\workspace\temp\text.txt
code c:\dev\workspace\temp
こんな感じでVSCodeが開きます。
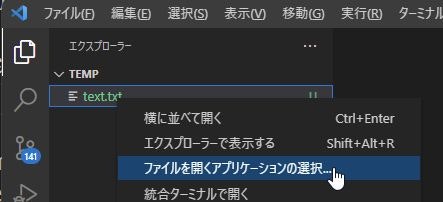
VSCodeが開いたら、「text.txt」右クリック⇒「ファイルを開くアプリケーションの選択」⇒「HEX Editor」を選択してください。
こんな感じの画面が出てくれば成功。
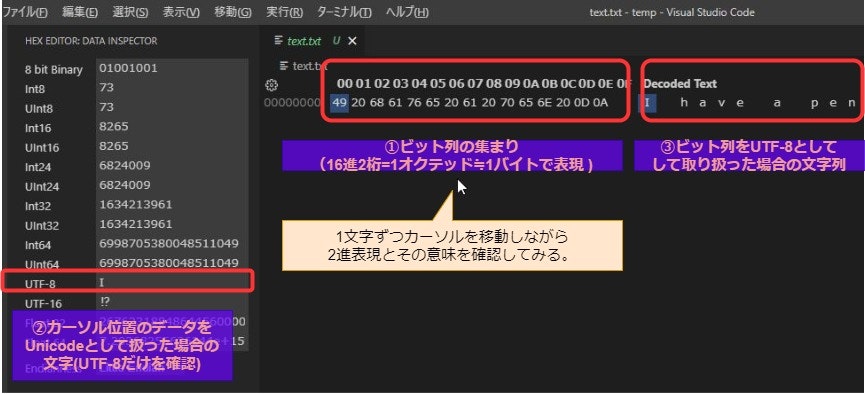
さて、データの見方ですが。
| No. | 項目 | 概要 |
|---|---|---|
| ① | データ表示、編集 | 対象のファイルを16進数で表現する。1オクテッドを基準にみるため、16進2桁で1フィールドとなっています。(1オクテット≒1バイト=16進2桁) |
| ② | データインスペクタ | ①でカーソルの当たっているオクテッドを解釈した場合、それぞれのデータ型での意味を確認できます。今回はデフォルト文字コードUTF8であることを想定して確認していきます。 |
| ③ | データのテキスト表示 | ②のデータすべてがUTF8のテキストだったらどのような文字列になるかを表示します。 |
では、1オクテッドずつ内容を見てみましょうか。
| No | 16進表現 | 2進表現 | UTF8での割り当て文字 |
|---|---|---|---|
| 00 | 49 | 01001001 | U+0049(LATIN CAPITAL LETTER I) |
| 01 | 20 | 00100000 | U+0020(SPACE) |
| 02 | 68 | 01101000 | U+0068(LATIN SMALL LETTER H) |
| 03 | 61 | 01100001 | U+0061(LATIN SMALL LETTER A) |
| 04 | 76 | 00110110 | U+0076(LATIN SMALL LETTER V) |
| 05 | 65 | 01100101 | U+0065(LATIN SMALL LETTER E) |
| 06 | 20 | 00100000 | U+0020(SPACE) |
| 07 | 61 | 01100001 | U+0061(LATIN SMALL LETTER A) |
| 08 | 20 | 00100000 | U+0020(SPACE) |
| 09 | 70 | 01110000 | U+0070(SPACE) |
| 0A | 65 | 01100101 | U+0065(LATIN SMALL LETTER E) |
| 0B | 6E | 01101110 | U+006E(LATIN SMALL LETTER N) |
| 0C | 20 | 00100000 | U+0020(SPACE) |
| 0D | 0D | 00100000 | U+00OD(CR 別サイトで補完) |
| 0F | 0A | 00001010 | U+00OA(LF 別サイトで補完) |
UTF8のコード値はここをみると確認できます。
表をみると、テキストファイルではファイルを構成するデータ(バイト)が全て「文字列」であることが分かります。つまり **「テキストデータ」とはデータを構成するすべての情報が「文字コード」**だけのデータのことを総じて「テキストデータ」「テキストファイル」と呼んでいるのです。(CR/LFも文字コード表に含まれるので、文字コードとして理解してください。)
さて、なんだか狐につままれたような話ですね。いまいち実感が分からないのではないでしょうか?
すこし、別のデータをいじってみましょう。
Java class ファイルの中を観察してみよう
なんか、いいネタはないものか。。。と思ったのですが。普段慣れ親しんでいるjavaのファイルに着目します。ここから先は
「Log4j2をとりあえず javacで動かす話」を一通りやっていることを前提とします。最低、パッケージの導入までは終わらせておいてください。
ではファイルを開いてみます。コマンドプロンプトで。。。
code c:\dev\workspace\java\libconfirm\bin\cococlub
先ほどと同じ手順でこんどは「MyApp.class」を右クリック⇒「ファイルを開くアプリケーションの選択」⇒「HEX Editor」を選択してください。
こんな感じに出てきます。真ん中に文字が割り当てられていて、読めそうな部分が、先頭と後半は何がなにやらわかりません。
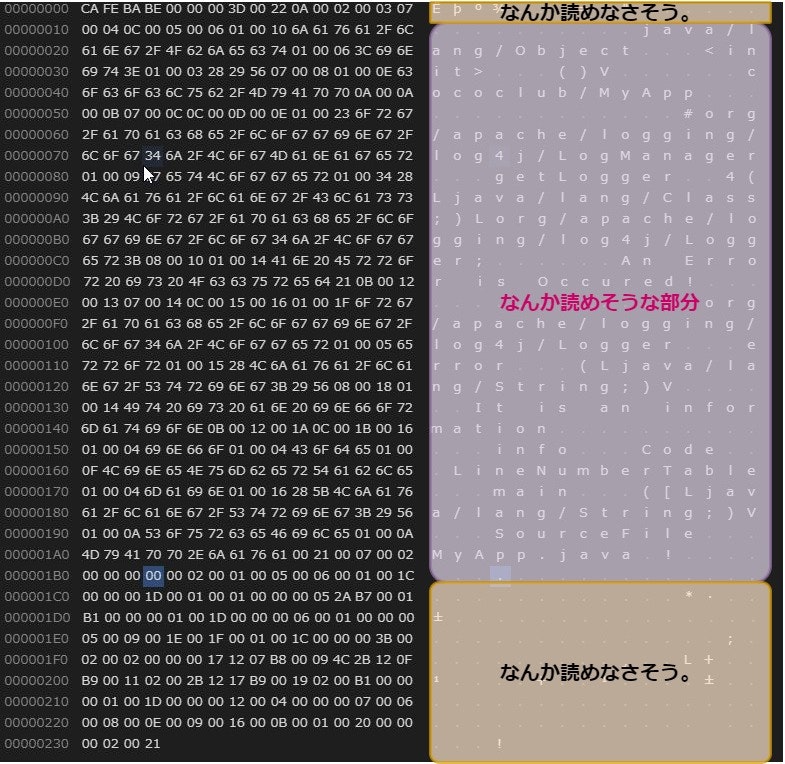
一番わかりやすい、先頭部分を確認してみましょう。詳細はWikipedia Javaクラスファイルの項目を参照

| No. | アドレス | 意味 | 値(16進) | 値(10進) |
|---|---|---|---|---|
| ① | 0-15 | クラスファイルフォーマットに適合するファイルを識別するために使用されるマジックナンバー | CAFEBABE1 | 202,254,186,190 |
| ② | 16-31 | 使用されるクラスファイルフォーマットのマイナーバージョン数 | 00 | 0,0 |
| ③ | 32-47 | 使用されるクラスファイルフォーマットのメジャーバージョン数 | 3D | 61(JDK 17向けのバイナリ) |
これらの情報から、classファイルを扱うプログラムはこのファイルがJAVA(CAFEBABE)のクラスファイルで、JDK17以上のJAVAで利用できることを知ることができます。このように、データの「位置」に意味があり、切り分け方もテキストファイルとは異なり、画一的に切れないデータ形式は「バイナリ」と呼びます。中にはテキストデータも入ることがありますが、「全てがテキスト」ではありません。つまり。
- テキストファイル=全てのデータが「文字列」であることが前提のファイル
- バイナリファイル=「文字列」が入っていたりその他の情報が入っていたり、入り乱れているファイル。
となります。実際にコンピュータからすれば 「全てのファイル・データがバイナリデータ」で一部の全てのデータを「テキスト」であることを前提として扱えるファイルを「テキストファイル・データ」として区別して扱うということになります。
なぜテキストファイルだけ分けて扱うの?
プログラムで利用するのが容易だからです。全てのデータができすとデータであるため、テキストファイル・データを扱うプログラムは
- ファイルを先頭から呼んで、オクテット毎にきっていく
- 必要な文字列処理を実施する。(たとえば文字としてユーザに見せる)
それだけのシンプルな処理になります。「全部、どこを切ってもテキスト」というのはとても便利なのです。
「文字列」は人間の扱うI/Fとして特別な意味を持ちます。コンピュータの理解するバイナリの世界を人は直接理解することはできません。でも、「テキスト」ならば読んで、書いて、変更して、また読んでと、便利に使うことができるのです。だからシンプルな構成で、色々なプログラムが楽に使えることだけを優先して作られたフォーマットが「テキスト形式」であると理解すればまずはよいかと思います。
-
Wikipedia Javaクラスファイルの項目にはCAFEBABEの由来が記載されています。興味のあることはご覧ください。 ↩