1.序論
よくある質問として、
- クライアントとサーバの違いって何?
- クライアントとフロントって同じ?
- サーバって何?
- 「クライアント・サーバ」と「サーバサイド・フロントエンド」のサーバって同じ意味なの?
- Webサーバって何?
というのをよく聞く。
このブログでは、これらの単語を紐解きながらサーバ・クライアントとその周辺知識の説明をしていく。
2.サーバ・クライアントとは
2-1.serveの意味
serveという英単語には、「(人や料理店が飲食物を)出す、提供する」という意味がある。
- server:(飲食物などを)提供する人。
- client:お客さん。(飲食物などを)提供される人。
技術的な話において言えば、
- server:何かを提供する人(モノ) or 何かを使える状態にしてくれる人(モノ)
- client:何かを提供される人(モノ) or 何かを利用する側の人(モノ)
というイメージをもっておけば十分である。
具体例を挙げると、
- Webサーバ:Webブラウザからコンテンツを閲覧できる状態にしてくれているモノ。
- Webクライアント:Webブラウザ。IEやChromeやSafariやFirefoxなど。
2-2.サーバ・クライアントのやりとりの流れ
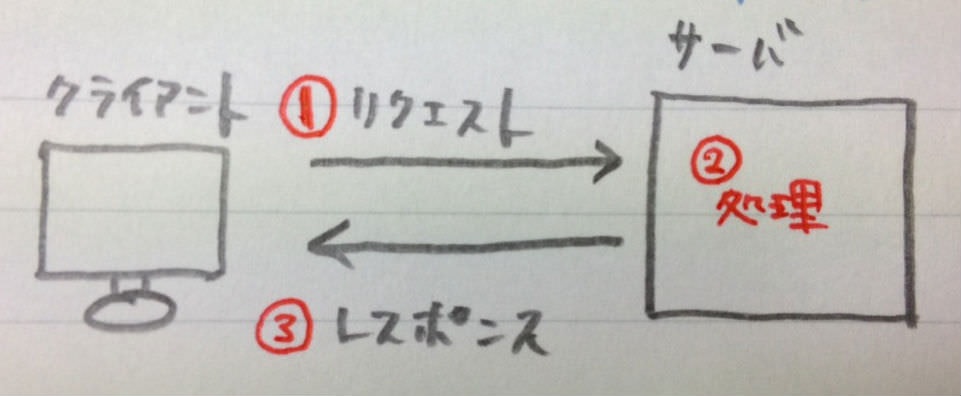
- 1.クライアント側がサーバ側に「リクエスト」を投げる
- 2.サーバ側でリクエストを解析・処理してリクエストの答えを作る
- 3.サーバ側がクライアント側に「レスポンス」を返す
3.WebサーバとWebクライアントの仕組み
サーバ・クライアントはWebに限った話ではないが、最も重要かつ頻出なサーバ・クライアントの話が「Web」の話なので、この場できちんと説明する。
3-1.HTTPとは
HTTPとは、WebサーバとWebクライアント(ブラウザ)の送受信に用いられる取り決めのことである。つまり、リクエストやレスポンスの「記述方法のルール」がHTTPだと思えばOK!
やりとりの流れは、
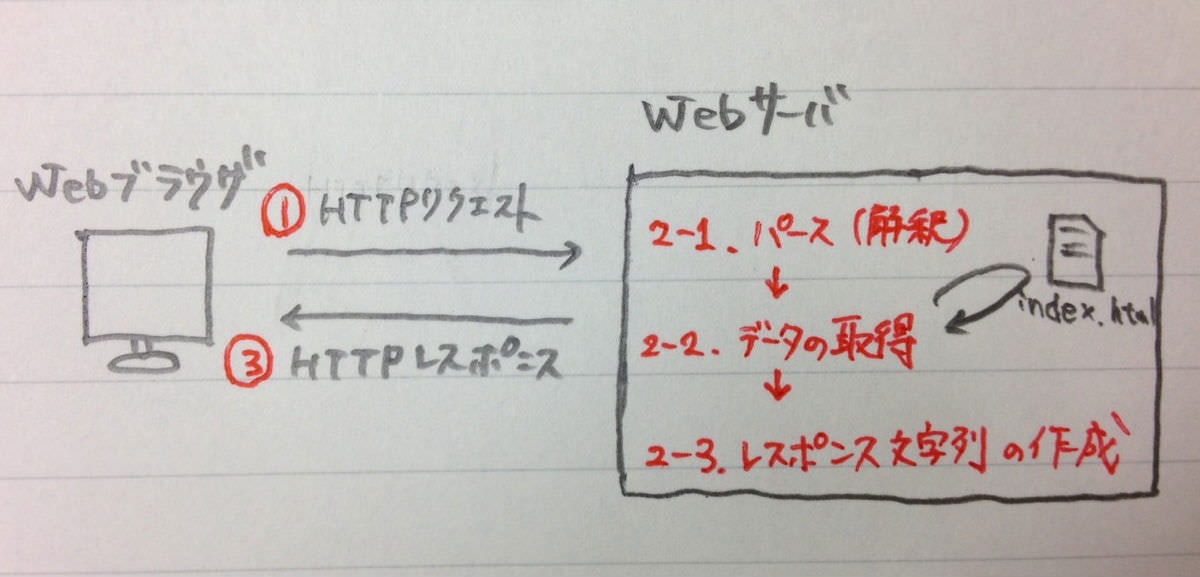
- 1.Webブラウザが「HTTPリクエスト」を投げる
- 2.サーバ側でリクエストを解析・処理してリクエストの答えを作る
- 3.Webサーバがブラウザに「HTTPレスポンス」を返す
となる。
HTTPリクエストの正体
メソッド URI(リクエストの対象) HTTPのバージョン
ヘッダ部(付加情報)
(空行)
ボディ部
具体的には、
GET /index.html HTTP/1.1
Accept: image/jpeg, text/html, application/json
Accept-Encodeing: gzip, deflate
- 1行目:リクエストライン(リクエスト行)
- 2,3行目:ヘッダ部
- この例だとボディ部は存在しない
といった具合である。
- メソッド:GET, POST, PUT, DELETEなど。
- メソッドは、CRUD(クラッド)と呼ばれる基本機能ごとに使い分ける
- Create:POSTメソッド
- Read:GETメソッド
- Update:PUTメソッド
- Delete:DELETEメソッド
- URI:Uniform Resource Identifier。インターネットにおける情報の「住所」のようなもの。
- HTTPバージョン:1.0や1.1など
- ヘッダ部(付加情報):あとで返してもらうレスポンスの形式などを記述する
HTTPレスポンスの正体
HTTPのバージョン ステータスコード 理由
ヘッダ部(付加情報)
(空行)
ボディ部
具体的には、
HTTP/1.1 200 OK
Content-Length: 4122
Server: Apache
Content-Type: text/html; charset=UTF-8
<html>
<head>
</head>
<body>
Hello!
</body>
</html>
- 1行目:ステータスライン(ステータス行)
- 2,3,4行目:ヘッダ部
- 空行より下の行:ボディ部(レスポンスの本体部分)
といった具合である。
- ステータスコード:レスポンスの意味を表す3桁の数字。
- 200:OK
- 301:Moved Permanently
- 302:Found(Moved Temporarily)
- 401:Unauthorized
- 403:Forbidden
- 404:Not Found
- 500:Internal Server Error など
- ヘッダ部(付加情報):返送オブジェクトの付加情報。
- ボディ部:レスポンスの本体部分。HTMLなどの文字列。
3-2.結局、Webサーバがやってくれてることって何??
- 1.Webブラウザが「HTTPリクエスト」を投げる
- 2.サーバ側でリクエストを解析・処理してリクエストの答えを作る
- 2-1.パース:送られてきたリクエストを解釈する
- 2-2.データの取得:送られてきたURIを元に必要なデータを取りに行く
- 2-3.レスポンス文字列の作成
- 3.Webサーバがブラウザに「HTTPレスポンス」を返す
という流れのうち、Webサーバがやってくれているのは2-1、2-2、2-3である。
3-3.「クライアント・サーバ」と「サーバサイド・フロントエンド・インフラ」ってどういう関係性???
よくあるWebエンジニアの種類には、
- フロントエンジニア:見える部分を作る人
- サーバサイドエンジニア:動的な処理を記述する人
- インフラエンジニア:各種サーバ環境を整える人
がある。
これらの言葉の定義がそもそも曖昧(サーバサイドエンジニアと呼ばれている人がインフラをいじることもあり、明確な線引ができるものではない)なので、厳密な正解を求めること自体ナンセンス。
また、「クライアント・サーバ」と「サーバサイド・フロントエンド・インフラ」の関係性については、
- フロント=フロントエンド=クライアントサイド≠クライアント
- サーバサイド≠サーバ
- クライアント・サーバの「サーバ」とサーバサイドエンジニアの「サーバ」は異なる
- 「インフラ・サーバサイド・フロント」と「クライアント・サーバ」は、関連はあるが別の単語と解釈した方が混乱を避けられる
というのが僕個人の見解である。
- (Web)サーバ:ブラウザからリクエストを受け取り、適切なレスポンスを返してくれるモノ
なので、(クライアント・サーバにおける)サーバは「サーバサイドの言語もフロントの言語も扱う」ことになる。また、
- (Web)クライアント:ブラウザ
であり、HTTPレスポンス(のボディ部)に含まれるのがフロントの言語たち(HTML、CSS、JSなど)。
クライアントサイドとはつまり、「ブラウザ側に送られる部分の技術」の事を指す。
3-4.Webサーバとアプリケーションサーバの違い
- 基本的にはWebサーバもアプリケーションサーバも似たようなもの
- アプリケーションサーバはWebサーバの拡張版
- Webサーバは「静的なもの」を返す
- アプリケーションサーバは「動的なもの」も返せる
2-2-2節でも記述した通り、Webサーバの役割は、
- 1.Webブラウザが「HTTPリクエスト」を投げる
- 2.サーバ側でリクエストを解析・処理してリクエストの答えを作る
- 2-1.パース:送られてきたリクエストを解釈する
- 2-2.データの取得:送られてきたURIを元に必要なデータを取りに行く
- 2-3.レスポンス文字列の作成
- 3.Webサーバがブラウザに「HTTPレスポンス」を返す
という流れのうち、2-1、2-2、2-3の部分である。
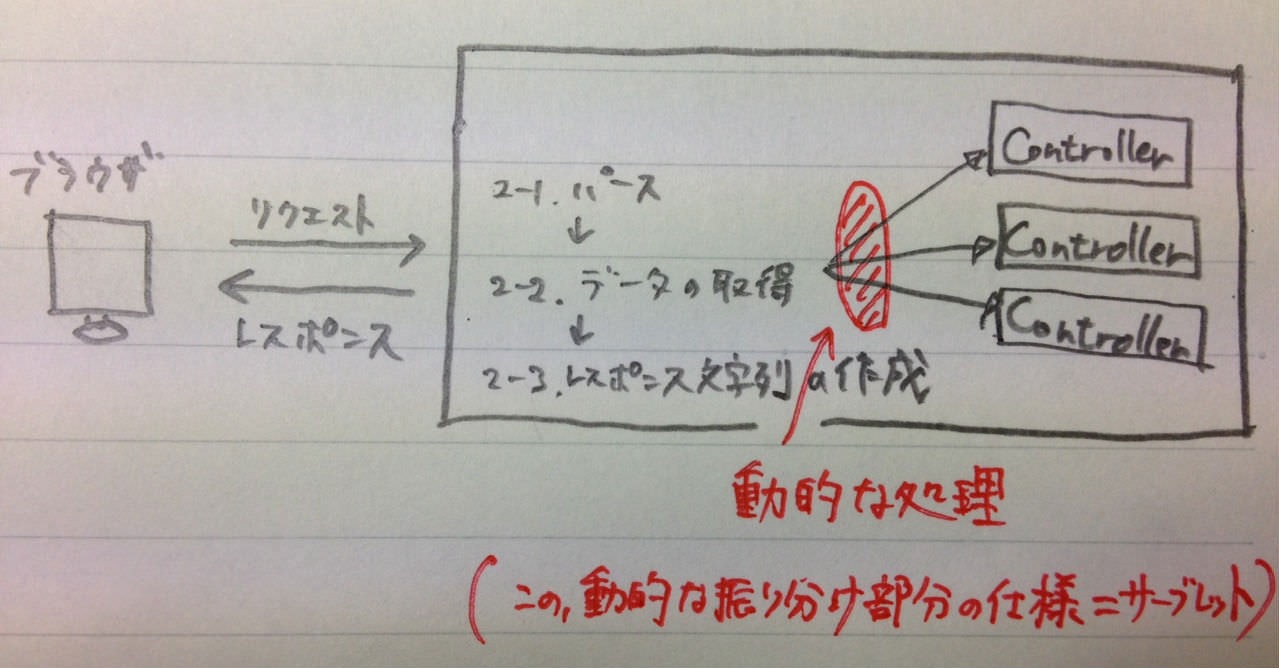
アプリケーションサーバは、
- 2-2.データの取得
の部分で動的に処理できるようになった拡張版Webサーバと認識していれば概ねOK。
具体例
- Webサーバ:Apache、Nginx、Tomcat(Coyote)など
- サーブレットコンテナ:Tomcat(Catalina)、Jettyなど
- サーブレットコンテナとは、Javaによるアプリケーションサーバのこと。数学的に言うと、アプリケーションサーバの部分集合がサーブレットコンテナ。
サーブレットとは
- WebからJavaを使えるようにするもの
- 動的な振り分け部分の仕様(インターフェース)
おまけ1:サーブレットとJSP
- JSP:htmlにJavaを埋め込んだもの。拡張子は
.jsp - サーブレット:Javaにhtmlを埋め込んだもの。拡張子は
.java - JSPの動作原理
- まずサーブレットに変換(
.jsp→.java) - 次にコンパイル(
.java→.class) - 最後に実行
- まずサーブレットに変換(
おまけ2:JavaフレームワークSpringがやってくれること
- サーブレットは動的な処理の振り分けの仕様なので、その実装は自分で書かなければならない
- Springは動的な処理の振り分けをラッピングしてくれているので、自分でサーブレットの実装を書かなくて済む
4.DBサーバとDBクライアントの仕組み
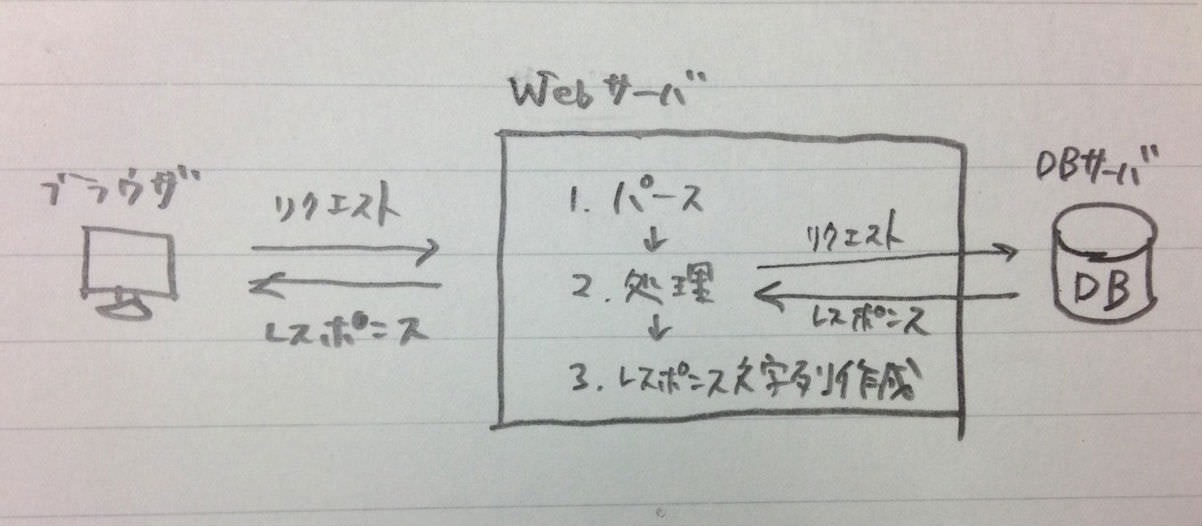
DBサーバは、DBクライアントからのリクエストを受け、適切に解析・処理をして、DBクライアントにレスポンスを返す役割を果たす。
主に、DBサーバにアクセスするのはWebサーバであることが多いので、「WebサーバはDBクライアントとも言える」場合が多い。
おまけ
- Webサーバを構築する ≒ Apacheを入れる
- DBサーバを構築する ≒ MySQLを入れる
- Webクライアントを構築する ≒ ブラウザ(IE、Chromeなど)を準備する