初めまして!
プログラミングの勉強をしているShunです。最近Pythonに興味があったので、こちら「スラスラわかるPython」を読ませて頂きました。この本ではPythonの基本的な構文を学んだり、Webスクレイピングのやり方が書いてあります。

[スラスラわかるPython 単行本]
(https://www.amazon.co.jp/%E3%82%B9%E3%83%A9%E3%82%B9%E3%83%A9%E3%82%8F%E3%81%8B%E3%82%8BPython-%E5%B2%A9%E5%B4%8E-%E5%9C%AD/dp/4798151092/ref=asc_df_4798151092/?tag=jpgo-22&linkCode=df0&hvadid=295686767484&hvpos=1o1&hvnetw=g&hvrand=17010285472902510266&hvpone=&hvptwo=&hvqmt=&hvdev=c&hvdvcmdl=&hvlocint=&hvlocphy=1009343&hvtargid=pla-526272651553&psc=1&th=1&psc=1/)
そもそもWebスクレイピングって何??
簡単に言うと、Webサイトで自分が欲しい情報を抜き出す技術です。
実際に画像を取得してみようと思う
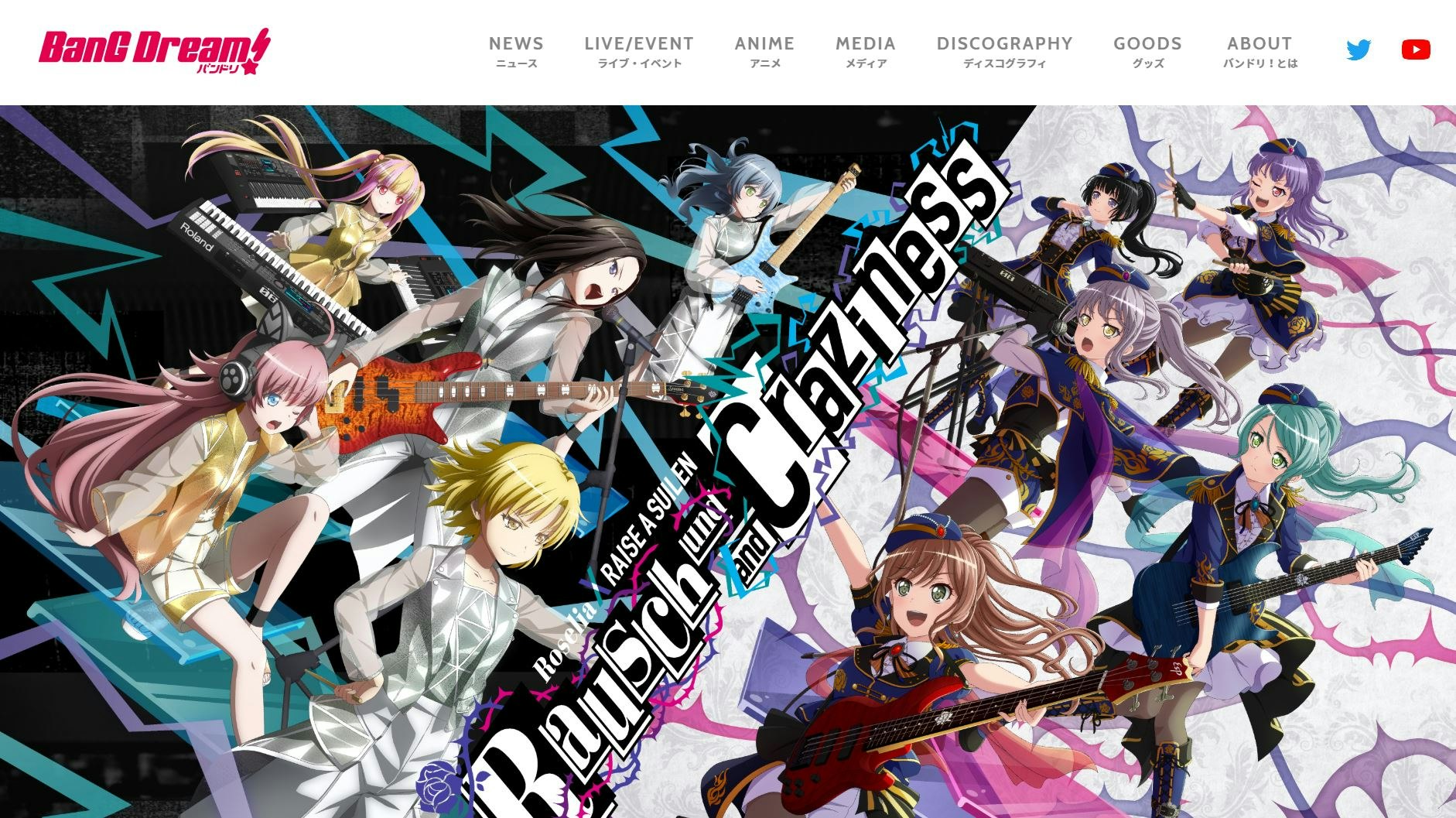
せっかくWebスクレイピングを学んだので実際にやってみようと思います。今回スクレイピングを行うサイトはバンドリの公式サイト(https://bang-dream.com/)
なぜこのサイトにしようとしたのかというと...下の画像が欲しかったからです。
準備
VScodeでQiitaというフォルダを作ってみました。このQiitaというフォルダの中に保存していきたいと思います。次にコマンドプロンプトを開いて以下のコマンドを実行してください。インストールが始まります。
$ > pip install requests --user
$ > pip install BeautifulSoup4 --user
インストールが完了したら今度はターミナルを開いて、インストールが成功しているかチェックしたいと思います。
$ >>> import requests
>>>
$ >>> from bs4 import BeautifulSoup
>>>
この時点で何もメッセージが出ていなければインストール成功です。もしここで以下のようなエラーメッセージが出てしまう場合はインストールに失敗しています。このような場合は、パソコンがインターネットに接続できてきているか確認をして、もう一度pipコマンドでインストールしてください。
$ >>> import requests
Traceback (most recent call last ) :
File "<stdin>" , line 1 , in <module>
ModuleNotFoundError : No module named " requests "
>>>
コード
以下の内容をQiitaフォルダの中にQiita01.pyという名前で保存してみました。解説も載せてあります。
import requests
from bs4 import BeautifulSoup
result = requests.get("https://bang-dream.com/")
soup = BeautifulSoup(result.text, "html.parser")
img = soup.find_all('img')
print(img)
import requests requestsライブラリを利用するための宣言
from bs4 import BeautifulSoup 外部ライブラリBeautifulSoupのインポートを行っている
result = requests.get("https://bang-dream.com/") ここでスクレイピングしたいURLを入れる
soup = BeautifulSoup(result.text, "html.parser") BeautifulSoupの処理に解析したい文字列と実際に解析するための処理の種類を指定
img = soup.find_all('img') findメゾットに[img]という文字を指定
| メゾット | 機能 |
|---|---|
| find_all() | 引用で指定されたタグを検索して、一致したものすべてを格納したリストに返す |
print(img) 出力
出力結果
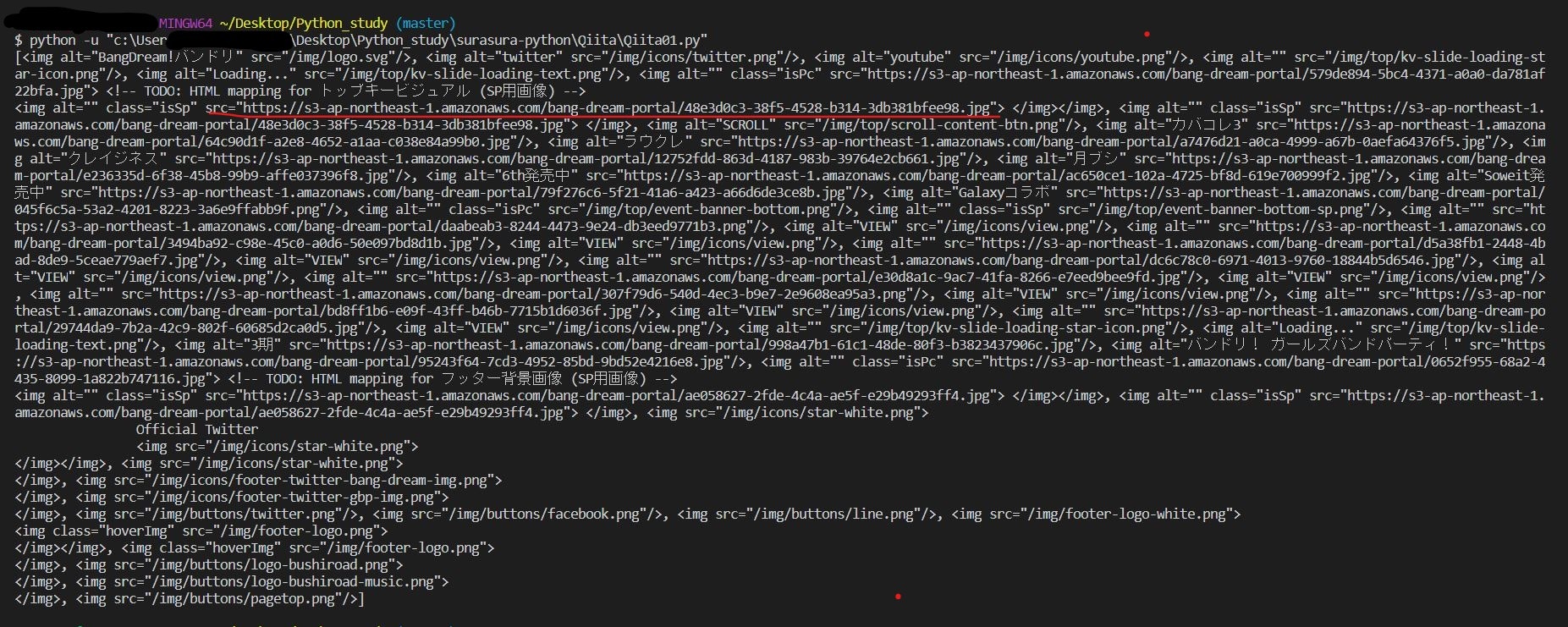
ターミナルで見てみると、このようなのが出てきます。赤線で引かれてるところのリンクを開いてみましょう。以下のような画像が出てきたら、スクレイピング成功です。

感想
なんで初歩的なことを記事にしたんですか?? って思う人もいるかもしれません。答えは簡単です、これくらいしかかける記事がありませんでした... これからもっとPythonを深めていきたいです。