結論
本記事が長くなってしまったため、結論だけ読みたい方向けに、冒頭に結論を書いておきます。
- 削除の仕方により付与されるTombstoneの数が異なるので、適切な削除を心がける
- 特定のPartitionにTombstoneが溜まらないように、適切なパーティショニングをする(Partition内に行・カラムを持ちすぎない)
- Partition内のすべての行を取得するようなクエリはなるべく避け、特定の行のみを取得するようなクエリを心がける
- gc_grace_secondsを適切な値に設定する
-
TombstoneScannedHistogramなどで、Tombstoneがどのくらい読み込まれているかの監視をする
削除の仕方によるTombstoneの付き方の違い
CassandraのTombstoneには6種類あることが以下のDataStaxのドキュメントで紹介されています。
- Partition tombstones
- Row tombstones
- Range tombstones
- ComplexColumn tombstones
- Cell tombstones
- TTL tombstones
それぞれのTombstoneにおいて付き方が異なります。
理解をしておくことで意図せずTombstoneを大量発生させてしまうことを防ぐことに役立ちます。
また、ここではよく使われるPartition tombstones, Row tombstones, Cell tombstones, TTL tombstonesの4つについて、比較していきたいと思います。
検証はCassandra 3.11のバージョンで行っています。
Partition, Row, Cellとは
まず、PartitionやRow、Cellといった用語が聞き慣れない方向けに説明します(ご存知の方は読み飛ばしてください)
Cassandraでは、Partition, Row, Cellというデータの単位があります。
Partition
Partitionはデータの分散の単位です。
Cassandraは、パーティションキーによってデータが分割され、クラスタ内のノードに分散されます。パーティションキーは、データの物理的な配置を決定するために使用され、同じパーティションキーを持つデータは同じノードに保存されます。
Row
パーティション内のデータは行(Row)として保存されます。行は、パーティションキーとクラスタリングキーによって一意に識別されます。
Cell
Cellは、行の中の個々のデータ単位です。Cellはカラム名と値のペアで構成されます。
図で表すと以下のようになります。
Partition
└── Row (Partition Key + Clustering Key)
├── Cell (Column Name: Value)
├── Cell (Column Name: Value)
└── Cell (Column Name: Value)
Partition tombstones
Partition tombstonesは、PartitionにTombstoneが1つ付き、Partition内のデータをまるごと削除します。
Partition keyのみを指定してDELETEしたときに付与されます。
実際に確認してみましょう。
tombstone.testというテーブルを定義します。
tombstone.testでは、idがPartition Keyとなり、sub_idがClustering Keyとなります。
CREATE TABLE IF NOT EXISTS tombstone.test (
id int,
sub_id int,
clm01 text,
clm02 text,
clm03 text,
clm04 text,
clm05 text,
PRIMARY KEY (id, sub_id))
WITH gc_grace_seconds = 900;
以下のように3行のデータを挿入した状態にしています。
cqlsh> INSERT INTO tombstone.test (id, sub_id, clm01, clm02, clm03, clm04, clm05) VALUES (1, 1, 'foo_1_1', 'bar_1_1', 'baz_1_1', 'qux_1_1', 'quux_1_1');
cqlsh> INSERT INTO tombstone.test (id, sub_id, clm01, clm02, clm03, clm04, clm05) VALUES (1, 2, 'foo_1_2', 'bar_1_2', 'baz_1_2', 'qux_1_2', 'quux_1_2');
cqlsh> INSERT INTO tombstone.test (id, sub_id, clm01, clm02, clm03, clm04, clm05) VALUES (1, 3, 'foo_1_3', 'bar_1_3', 'baz_1_3', 'qux_1_3', 'quux_1_3');
cqlsh> SELECT * FROM tombstone.test;
id | sub_id | clm01 | clm02 | clm03 | clm04 | clm05
----+--------+---------+---------+---------+---------+----------
1 | 1 | foo_1_1 | bar_1_1 | baz_1_1 | qux_1_1 | quux_1_1
1 | 2 | foo_1_2 | bar_1_2 | baz_1_2 | qux_1_2 | quux_1_2
1 | 3 | foo_1_3 | bar_1_3 | baz_1_3 | qux_1_3 | quux_1_3
(3 rows)
このときのSSTableの中身を確認しておきます。
[
{
"partition" : {
"key" : [ "1" ],
"position" : 0
},
"rows" : [
{
"type" : "row",
"position" : 18,
"clustering" : [ 1 ],
"liveness_info" : { "tstamp" : "2024-09-10T01:27:02.253756Z" },
"cells" : [
{ "name" : "clm01", "value" : "foo_1_1" },
{ "name" : "clm02", "value" : "bar_1_1" },
{ "name" : "clm03", "value" : "baz_1_1" },
{ "name" : "clm04", "value" : "qux_1_1" },
{ "name" : "clm05", "value" : "quux_1_1" }
]
},
{
"type" : "row",
"position" : 73,
"clustering" : [ 2 ],
"liveness_info" : { "tstamp" : "2024-09-10T01:29:55.822940Z" },
"cells" : [
{ "name" : "clm01", "value" : "foo_1_2" },
{ "name" : "clm02", "value" : "bar_1_2" },
{ "name" : "clm03", "value" : "baz_1_2" },
{ "name" : "clm04", "value" : "qux_1_2" },
{ "name" : "clm05", "value" : "quux_1_2" }
]
},
{
"type" : "row",
"position" : 131,
"clustering" : [ 3 ],
"liveness_info" : { "tstamp" : "2024-09-10T01:30:04.962950Z" },
"cells" : [
{ "name" : "clm01", "value" : "foo_1_3" },
{ "name" : "clm02", "value" : "bar_1_3" },
{ "name" : "clm03", "value" : "baz_1_3" },
{ "name" : "clm04", "value" : "qux_1_3" },
{ "name" : "clm05", "value" : "quux_1_3" }
]
}
]
}
]
DELETE文でid = 1を削除します。
すると3行のデータが削除されます。
cqlsh> DELETE FROM tombstone.test WHERE id = 1;
cqlsh> SELECT * FROM tombstone.test;
id | sub_id | clm01 | clm02 | clm03 | clm04 | clm05
----+--------+---------+---------+---------+---------+----------
(0 rows)
SSTableを確認すると、Tombstoneは一個のみであることがわかります。
[
{
"partition" : {
"key" : [ "1" ],
"position" : 0,
"deletion_info" : { "marked_deleted" : "2024-09-10T01:37:37.857703Z", "local_delete_time" : "2024-09-10T01:37:37Z" }
},
"rows" : [ ]
}
]
これがPartition tombstonesです。
Row tombstones
Row tombstonesは行ごとにTombstoneが1つ付き、行を削除します。
Partition KeyとClustering Keyを指定してDELETE文を実行すると付与されます。
実際に確認してみます。
テーブルはPartition tombstonesのときと同じtombstone.testテーブルを用います。
以下のような3行が挿入された状態にします。
cqlsh> INSERT INTO tombstone.test (id, sub_id, clm01, clm02, clm03, clm04, clm05) VALUES (2, 1, 'foo_2_1', 'bar_2_1', 'baz_2_1', 'qux_2_1', 'quux_2_1');
cqlsh> INSERT INTO tombstone.test (id, sub_id, clm01, clm02, clm03, clm04, clm05) VALUES (2, 2, 'foo_2_2', 'bar_2_2', 'baz_2_2', 'qux_2_2', 'quux_2_2');
cqlsh> INSERT INTO tombstone.test (id, sub_id, clm01, clm02, clm03, clm04, clm05) VALUES (2, 3, 'foo_2_3', 'bar_2_3', 'baz_2_3', 'qux_2_3', 'quux_2_3');
cqlsh> SELECT * FROM tombstone.test ;
id | sub_id | clm01 | clm02 | clm03 | clm04 | clm05
----+--------+---------+---------+---------+---------+----------
2 | 1 | foo_2_1 | bar_2_1 | baz_2_1 | qux_2_1 | quux_2_1
2 | 2 | foo_2_2 | bar_2_2 | baz_2_2 | qux_2_2 | quux_2_2
2 | 3 | foo_2_3 | bar_2_3 | baz_2_3 | qux_2_3 | quux_2_3
(3 rows)
このときのSSTableを確認しておきます。
[
{
"partition" : {
"key" : [ "2" ],
"position" : 0
},
"rows" : [
{
"type" : "row",
"position" : 18,
"clustering" : [ 1 ],
"liveness_info" : { "tstamp" : "2024-09-10T01:57:21.736881Z" },
"cells" : [
{ "name" : "clm01", "value" : "foo_2_1" },
{ "name" : "clm02", "value" : "bar_2_1" },
{ "name" : "clm03", "value" : "baz_2_1" },
{ "name" : "clm04", "value" : "qux_2_1" },
{ "name" : "clm05", "value" : "quux_2_1" }
]
},
{
"type" : "row",
"position" : 73,
"clustering" : [ 2 ],
"liveness_info" : { "tstamp" : "2024-09-10T01:57:26.787317Z" },
"cells" : [
{ "name" : "clm01", "value" : "foo_2_2" },
{ "name" : "clm02", "value" : "bar_2_2" },
{ "name" : "clm03", "value" : "baz_2_2" },
{ "name" : "clm04", "value" : "qux_2_2" },
{ "name" : "clm05", "value" : "quux_2_2" }
]
},
{
"type" : "row",
"position" : 131,
"clustering" : [ 3 ],
"liveness_info" : { "tstamp" : "2024-09-10T01:57:31.307171Z" },
"cells" : [
{ "name" : "clm01", "value" : "foo_2_3" },
{ "name" : "clm02", "value" : "bar_2_3" },
{ "name" : "clm03", "value" : "baz_2_3" },
{ "name" : "clm04", "value" : "qux_2_3" },
{ "name" : "clm05", "value" : "quux_2_3" }
]
}
]
}
]
DELETE文でid = 2, sub_id = 1 & id = 2, sub_id = 2 & id = 2, sub_id = 3を削除します。
すると3行が削除されます。
cqlsh> DELETE FROM tombstone.test WHERE id = 2 AND sub_id = 1;
cqlsh> DELETE FROM tombstone.test WHERE id = 2 AND sub_id = 2;
cqlsh> DELETE FROM tombstone.test WHERE id = 2 AND sub_id = 3;
cqlsh> SELECT * FROM tombstone.test;
id | sub_id | clm01 | clm02 | clm03 | clm04 | clm05
----+--------+---------+---------+---------+---------+----------
(0 rows)
SSTableを確認すると、それぞれの行にTombstoneが1つ付いており、合計で3つのTombstoneが付いているのがわかります。
[
{
"partition" : {
"key" : [ "2" ],
"position" : 0
},
"rows" : [
{
"type" : "row",
"position" : 18,
"clustering" : [ 1 ],
"deletion_info" : { "marked_deleted" : "2024-09-10T02:01:38.846318Z", "local_delete_time" : "2024-09-10T02:01:38Z" },
"cells" : [ ]
},
{
"type" : "row",
"position" : 32,
"clustering" : [ 2 ],
"deletion_info" : { "marked_deleted" : "2024-09-10T02:01:43.374781Z", "local_delete_time" : "2024-09-10T02:01:43Z" },
"cells" : [ ]
},
{
"type" : "row",
"position" : 46,
"clustering" : [ 3 ],
"deletion_info" : { "marked_deleted" : "2024-09-10T02:01:47.872016Z", "local_delete_time" : "2024-09-10T02:01:47Z" },
"cells" : [ ]
}
]
}
]
これがRow tombstonesになります。
Cell tombstones
Cell tombstonesはCellごとにTombstoneが1つ付き、Cellを削除(NULL)します。
UPDATE文でカラムをNULLに更新すると付与されます。
実際に確認してみます。
テーブルはPartition tombstonesのときと同じtombstone.testテーブルを用います。
以下のような3行が挿入された状態にします。
cqlsh> INSERT INTO tombstone.test (id, sub_id, clm01, clm02, clm03, clm04, clm05) VALUES (3, 1, 'foo_3_1', 'bar_3_1', 'baz_3_1', 'qux_3_1', 'quux_3_1');
cqlsh> INSERT INTO tombstone.test (id, sub_id, clm01, clm02, clm03, clm04, clm05) VALUES (3, 2, 'foo_3_2', 'bar_3_2', 'baz_3_2', 'qux_3_2', 'quux_3_2');
cqlsh> INSERT INTO tombstone.test (id, sub_id, clm01, clm02, clm03, clm04, clm05) VALUES (3, 3, 'foo_3_3', 'bar_3_3', 'baz_3_3', 'qux_3_3', 'quux_3_3');
cqlsh> SELECT * FROM tombstone.test ;
id | sub_id | clm01 | clm02 | clm03 | clm04 | clm05
----+--------+---------+---------+---------+---------+----------
3 | 1 | foo_3_1 | bar_3_1 | baz_3_1 | qux_3_1 | quux_3_1
3 | 2 | foo_3_2 | bar_3_2 | baz_3_2 | qux_3_2 | quux_3_2
3 | 3 | foo_3_3 | bar_3_3 | baz_3_3 | qux_3_3 | quux_3_3
(3 rows)
このときのSSTableを確認しておきます。
[
{
"partition" : {
"key" : [ "3" ],
"position" : 0
},
"rows" : [
{
"type" : "row",
"position" : 18,
"clustering" : [ 1 ],
"liveness_info" : { "tstamp" : "2024-09-10T04:07:15.109998Z" },
"cells" : [
{ "name" : "clm01", "value" : "foo_3_1" },
{ "name" : "clm02", "value" : "bar_3_1" },
{ "name" : "clm03", "value" : "baz_3_1" },
{ "name" : "clm04", "value" : "qux_3_1" },
{ "name" : "clm05", "value" : "quux_3_1" }
]
},
{
"type" : "row",
"position" : 73,
"clustering" : [ 2 ],
"liveness_info" : { "tstamp" : "2024-09-10T04:07:20.604509Z" },
"cells" : [
{ "name" : "clm01", "value" : "foo_3_2" },
{ "name" : "clm02", "value" : "bar_3_2" },
{ "name" : "clm03", "value" : "baz_3_2" },
{ "name" : "clm04", "value" : "qux_3_2" },
{ "name" : "clm05", "value" : "quux_3_2" }
]
},
{
"type" : "row",
"position" : 131,
"clustering" : [ 3 ],
"liveness_info" : { "tstamp" : "2024-09-10T04:07:25.460211Z" },
"cells" : [
{ "name" : "clm01", "value" : "foo_3_3" },
{ "name" : "clm02", "value" : "bar_3_3" },
{ "name" : "clm03", "value" : "baz_3_3" },
{ "name" : "clm04", "value" : "qux_3_3" },
{ "name" : "clm05", "value" : "quux_3_3" }
]
}
]
}
]
UPDATE文ですべての行のclm01, clm02, clm03, clm04, clm05をNULLに更新します。
cqlsh> UPDATE tombstone.test SET clm01 = NULL, clm02 = NULL, clm03 = NULL, clm04 = NULL, clm05 = NULL WHERE id = 3 AND sub_id = 1;
cqlsh> UPDATE tombstone.test SET clm01 = NULL, clm02 = NULL, clm03 = NULL, clm04 = NULL, clm05 = NULL WHERE id = 3 AND sub_id = 2;
cqlsh> UPDATE tombstone.test SET clm01 = NULL, clm02 = NULL, clm03 = NULL, clm04 = NULL, clm05 = NULL WHERE id = 3 AND sub_id = 3;
cqlsh> SELECT * FROM tombstone.test ;
id | sub_id | clm01 | clm02 | clm03 | clm04 | clm05
----+--------+-------+-------+-------+-------+-------
3 | 1 | null | null | null | null | null
3 | 2 | null | null | null | null | null
3 | 3 | null | null | null | null | null
(3 rows)
SSTableを確認すると、それぞれのCellに1つのTombstoneがついており、合計で15個のTombstoneが付いているのがわかります。
[
{
"partition" : {
"key" : [ "3" ],
"position" : 0
},
"rows" : [
{
"type" : "row",
"position" : 18,
"clustering" : [ 1 ],
"liveness_info" : { "tstamp" : "2024-09-10T04:07:15.109998Z" },
"cells" : [
{ "name" : "clm01", "deletion_info" : { "local_delete_time" : "2024-09-10T04:10:19Z" },
"tstamp" : "2024-09-10T04:10:19.513899Z"
},
{ "name" : "clm02", "deletion_info" : { "local_delete_time" : "2024-09-10T04:10:19Z" },
"tstamp" : "2024-09-10T04:10:19.513899Z"
},
{ "name" : "clm03", "deletion_info" : { "local_delete_time" : "2024-09-10T04:10:19Z" },
"tstamp" : "2024-09-10T04:10:19.513899Z"
},
{ "name" : "clm04", "deletion_info" : { "local_delete_time" : "2024-09-10T04:10:19Z" },
"tstamp" : "2024-09-10T04:10:19.513899Z"
},
{ "name" : "clm05", "deletion_info" : { "local_delete_time" : "2024-09-10T04:10:19Z" },
"tstamp" : "2024-09-10T04:10:19.513899Z"
}
]
},
{
"type" : "row",
"position" : 57,
"clustering" : [ 2 ],
"liveness_info" : { "tstamp" : "2024-09-10T04:07:20.604509Z" },
"cells" : [
{ "name" : "clm01", "deletion_info" : { "local_delete_time" : "2024-09-10T04:10:21Z" },
"tstamp" : "2024-09-10T04:10:21.898257Z"
},
{ "name" : "clm02", "deletion_info" : { "local_delete_time" : "2024-09-10T04:10:21Z" },
"tstamp" : "2024-09-10T04:10:21.898257Z"
},
{ "name" : "clm03", "deletion_info" : { "local_delete_time" : "2024-09-10T04:10:21Z" },
"tstamp" : "2024-09-10T04:10:21.898257Z"
},
{ "name" : "clm04", "deletion_info" : { "local_delete_time" : "2024-09-10T04:10:21Z" },
"tstamp" : "2024-09-10T04:10:21.898257Z"
},
{ "name" : "clm05", "deletion_info" : { "local_delete_time" : "2024-09-10T04:10:21Z" },
"tstamp" : "2024-09-10T04:10:21.898257Z"
}
]
},
{
"type" : "row",
"position" : 99,
"clustering" : [ 3 ],
"liveness_info" : { "tstamp" : "2024-09-10T04:07:25.460211Z" },
"cells" : [
{ "name" : "clm01", "deletion_info" : { "local_delete_time" : "2024-09-10T04:10:24Z" },
"tstamp" : "2024-09-10T04:10:24.116301Z"
},
{ "name" : "clm02", "deletion_info" : { "local_delete_time" : "2024-09-10T04:10:24Z" },
"tstamp" : "2024-09-10T04:10:24.116301Z"
},
{ "name" : "clm03", "deletion_info" : { "local_delete_time" : "2024-09-10T04:10:24Z" },
"tstamp" : "2024-09-10T04:10:24.116301Z"
},
{ "name" : "clm04", "deletion_info" : { "local_delete_time" : "2024-09-10T04:10:24Z" },
"tstamp" : "2024-09-10T04:10:24.116301Z"
},
{ "name" : "clm05", "deletion_info" : { "local_delete_time" : "2024-09-10T04:10:24Z" },
"tstamp" : "2024-09-10T04:10:24.116301Z"
}
]
}
]
}
]
これがCell tombstonesになります。
TTL tombstones
TTL tombstonesは、TTL(Time To Live)が切れるとCellごとにTombstoneが付与されます。
TTLの付け方としては、USING TTL句を使ってINSERTやUPDATEに付与する方法や、テーブル定義でTTLを設定する方法もあります。
実際に確認してみます。
テーブルはPartition tombstonesのときと同じtombstone.testテーブルを用います。
以下のようにTTLをつけて3行挿入します。
以下のような3行が挿入された状態にします。
cqlsh> INSERT INTO tombstone.test (id, sub_id, clm01, clm02, clm03, clm04, clm05) VALUES (4, 1, 'foo_4_1', 'bar_4_1', 'baz_4_1', 'qux_4_1', 'quux_4_1') USING TTL 300;
cqlsh> INSERT INTO tombstone.test (id, sub_id, clm01, clm02, clm03, clm04, clm05) VALUES (4, 2, 'foo_4_2', 'bar_4_2', 'baz_4_2', 'qux_4_2', 'quux_4_2') USING TTL 300;
cqlsh> INSERT INTO tombstone.test (id, sub_id, clm01, clm02, clm03, clm04, clm05) VALUES (4, 3, 'foo_4_3', 'bar_4_3', 'baz_4_3', 'qux_4_3', 'quux_4_3') USING TTL 300;
cqlsh> SELECT * FROM tombstone.test ;
id | sub_id | clm01 | clm02 | clm03 | clm04 | clm05
----+--------+---------+---------+---------+---------+----------
4 | 1 | foo_4_1 | bar_4_1 | baz_4_1 | qux_4_1 | quux_4_1
4 | 2 | foo_4_2 | bar_4_2 | baz_4_2 | qux_4_2 | quux_4_2
4 | 3 | foo_4_3 | bar_4_3 | baz_4_3 | qux_4_3 | quux_4_3
3 | 1 | null | null | null | null | null
3 | 2 | null | null | null | null | null
3 | 3 | null | null | null | null | null
(6 rows)
このときのSSTableを確認しておきます。
[
{
"partition" : {
"key" : [ "4" ],
"position" : 0
},
"rows" : [
{
"type" : "row",
"position" : 18,
"clustering" : [ 1 ],
"liveness_info" : { "tstamp" : "2024-09-10T09:02:11.608874Z", "ttl" : 300, "expires_at" : "2024-09-10T09:07:11Z", "expired" : false },
"cells" : [
{ "name" : "clm01", "value" : "foo_4_1" },
{ "name" : "clm02", "value" : "bar_4_1" },
{ "name" : "clm03", "value" : "baz_4_1" },
{ "name" : "clm04", "value" : "qux_4_1" },
{ "name" : "clm05", "value" : "quux_4_1" }
]
},
{
"type" : "row",
"position" : 75,
"clustering" : [ 2 ],
"liveness_info" : { "tstamp" : "2024-09-10T09:02:20.823631Z", "ttl" : 300, "expires_at" : "2024-09-10T09:07:20Z", "expired" : false },
"cells" : [
{ "name" : "clm01", "value" : "foo_4_2" },
{ "name" : "clm02", "value" : "bar_4_2" },
{ "name" : "clm03", "value" : "baz_4_2" },
{ "name" : "clm04", "value" : "qux_4_2" },
{ "name" : "clm05", "value" : "quux_4_2" }
]
},
{
"type" : "row",
"position" : 135,
"clustering" : [ 3 ],
"liveness_info" : { "tstamp" : "2024-09-10T09:02:43.793184Z", "ttl" : 300, "expires_at" : "2024-09-10T09:07:43Z", "expired" : false },
"cells" : [
{ "name" : "clm01", "value" : "foo_4_3" },
{ "name" : "clm02", "value" : "bar_4_3" },
{ "name" : "clm03", "value" : "baz_4_3" },
{ "name" : "clm04", "value" : "qux_4_3" },
{ "name" : "clm05", "value" : "quux_4_3" }
]
}
]
}
]
TTLが切れた後に再度確認してみます。
TTLを付与した行が削除されていることがわかります。
cqlsh> SELECT * FROM tombstone.test ;
id | sub_id | clm01 | clm02 | clm03 | clm04 | clm05
----+--------+-------+-------+-------+-------+-------
3 | 1 | null | null | null | null | null
3 | 2 | null | null | null | null | null
3 | 3 | null | null | null | null | null
(3 rows)
SSTableを確認してみると、それぞれのCellにTombstotneが付いており、合計で15個のTombstoneが付いていることがわかります。
[
{
"partition" : {
"key" : [ "4" ],
"position" : 0
},
"rows" : [
{
"type" : "row",
"position" : 18,
"clustering" : [ 1 ],
"liveness_info" : { "tstamp" : "2024-09-10T09:02:11.608874Z", "ttl" : 300, "expires_at" : "2024-09-10T09:07:11Z", "expired" : true },
"cells" : [
{ "name" : "clm01", "deletion_info" : { "local_delete_time" : "2024-09-10T09:02:11Z" }
},
{ "name" : "clm02", "deletion_info" : { "local_delete_time" : "2024-09-10T09:02:11Z" }
},
{ "name" : "clm03", "deletion_info" : { "local_delete_time" : "2024-09-10T09:02:11Z" }
},
{ "name" : "clm04", "deletion_info" : { "local_delete_time" : "2024-09-10T09:02:11Z" }
},
{ "name" : "clm05", "deletion_info" : { "local_delete_time" : "2024-09-10T09:02:11Z" }
}
]
},
{
"type" : "row",
"position" : 79,
"clustering" : [ 2 ],
"liveness_info" : { "tstamp" : "2024-09-10T09:02:20.823631Z", "ttl" : 300, "expires_at" : "2024-09-10T09:07:20Z", "expired" : true },
"cells" : [
{ "name" : "clm01", "deletion_info" : { "local_delete_time" : "2024-09-10T09:02:20Z" }
},
{ "name" : "clm02", "deletion_info" : { "local_delete_time" : "2024-09-10T09:02:20Z" }
},
{ "name" : "clm03", "deletion_info" : { "local_delete_time" : "2024-09-10T09:02:20Z" }
},
{ "name" : "clm04", "deletion_info" : { "local_delete_time" : "2024-09-10T09:02:20Z" }
},
{ "name" : "clm05", "deletion_info" : { "local_delete_time" : "2024-09-10T09:02:20Z" }
}
]
},
{
"type" : "row",
"position" : 143,
"clustering" : [ 3 ],
"liveness_info" : { "tstamp" : "2024-09-10T09:02:43.793184Z", "ttl" : 300, "expires_at" : "2024-09-10T09:07:43Z", "expired" : true },
"cells" : [
{ "name" : "clm01", "deletion_info" : { "local_delete_time" : "2024-09-10T09:02:43Z" }
},
{ "name" : "clm02", "deletion_info" : { "local_delete_time" : "2024-09-10T09:02:43Z" }
},
{ "name" : "clm03", "deletion_info" : { "local_delete_time" : "2024-09-10T09:02:43Z" }
},
{ "name" : "clm04", "deletion_info" : { "local_delete_time" : "2024-09-10T09:02:43Z" }
},
{ "name" : "clm05", "deletion_info" : { "local_delete_time" : "2024-09-10T09:02:43Z" }
}
]
}
]
}
]
これがTTL tombstonesの特徴になります。
削除の仕方のまとめ
このように同じ3行のデータの削除でも、それぞれTombstoneのつき方や数が異なります。
削除する際はCell tombstonesではなくRow tombstones、Row tombstonesではなくPartition tombstonesで削除できないかを考えましょう。
特にTTLで削除する場合は、想定以上にTombstoneが溜まっていることが多いので、注意が必要です。
以下に3行のデータをそれぞれの方法で削除した際のTombstoneの数を表でまとめておきます。
| 削除方法 | Tombstoneの個数 |
|---|---|
| Parition tombstones | 1 |
| Row tombstones | 3 |
| Cell tombstones | 15 |
| TTL tombstones | 15 |
Scanned over 100001 tombstonesによるリクエスト失敗が起きる条件
次の条件を満たすとScanned over 100001 tombstonesによりリクエストが失敗します。
- 1つのクエリで10万を超えるTombstoneをスキャンした場合
- gc_grace_secondsの期限が切れる前の状態である場合
それぞれ説明します。
インフォメーション
Scanned over 100001 tombstonesは、cassandra.yamlのtombstone_failure_thresholdという設定によって閾値を変更することができます。
デフォルトは100000となっています。
Cassandra 4.1でも同じデフォルト値となっていることを確認しています。
1つのクエリで10万を超えるTombstoneをスキャンした場合
Scanned over 100001 tombstonesによるリクエスト失敗は、クエリを実行した際に、Tombstoneを100,001個以上スキャンすると発生します。
そのため、広範囲なデータを読み取るようなクエリでは、Tombstoneを大量にスキャンする可能性が高まるので、Scanned over 100001 tombstonesによるリクエスト失敗を招きやすいです。
特に特定のPartition内に10万を超えるTombstoneが存在している場合は要注意です。
適切なパーティショニングを行い、削除した時にTombstoneが分散するように心がけましょう。
逆に、広範囲なデータではなく、特定のデータを読み込むクエリであれば、Scanned over 100001 tombstonesによるリクエスト失敗は起こりません。
例えば、ある特定のPartition内に15万行のデータが存在し、そのうちの11万行を削除した状態を考えます。
このとき、Clustering Keyを指定して1行のみ取得するような操作であれば、リクエスト失敗はおきません。
しかし、Clustering Keyを指定せず、Partition Keyのみを指定して、Partition内の全ての行を取得するようなクエリを叩くとリクエストは失敗します。
そのため、Partition内のすべての行を取得するようなクエリはなるべく避け、特定の行のみを取得するようなクエリを心がけることが重要になります。
検証
Cassandra 3.11のバージョンで検証をしています。
Partition内の全ての行を取得すると失敗し、特定の行のみを取得すると失敗しないことの検証内容
実際に確認してみます。
以下のようなテーブルを作成します。
CREATE TABLE IF NOT EXISTS tombstone_100k.test04 (
key int,
sub_key int,
data text,
PRIMARY KEY (key, sub_key))
WITH gc_grace_seconds = 3600;
key = 1のPartitionに15万行のデータを挿入します。
INSERT INTO tombstone_100k.test04 (key, sub_key, data) VALUES (1, 1, '100k tombstones test: key = 1 sub_key = 1');
INSERT INTO tombstone_100k.test04 (key, sub_key, data) VALUES (1, 2, '100k tombstones test: key = 1 sub_key = 2');
INSERT INTO tombstone_100k.test04 (key, sub_key, data) VALUES (1, 3, '100k tombstones test: key = 1 sub_key = 3');
:
INSERT INTO tombstone_100k.test04 (key, sub_key, data) VALUES (1, 149998, '100k tombstones test: key = 1 sub_key = 149998');
INSERT INTO tombstone_100k.test04 (key, sub_key, data) VALUES (1, 149999, '100k tombstones test: key = 1 sub_key = 149999');
INSERT INTO tombstone_100k.test04 (key, sub_key, data) VALUES (1, 150000, '100k tombstones test: key = 1 sub_key = 150000');
11万行を削除します。
DELETE FROM tombstone_100k.test04 WHERE key = 1 AND sub_key = 1;
DELETE FROM tombstone_100k.test04 WHERE key = 1 AND sub_key = 2;
DELETE FROM tombstone_100k.test04 WHERE key = 1 AND sub_key = 3;
:
DELETE FROM tombstone_100k.test04 WHERE key = 1 AND sub_key = 109998;
DELETE FROM tombstone_100k.test04 WHERE key = 1 AND sub_key = 109999;
DELETE FROM tombstone_100k.test04 WHERE key = 1 AND sub_key = 110000;
その後、key = 1のPartitionをすべて取得するとリクエストが失敗することがわかります。
cqlsh> SELECT * FROM tombstone_100k.test04 WHERE key = 1;
ReadFailure: Error from server: code=1300 [Replica(s) failed to execute read] message="Operation failed - received 0 responses and 2 failures" info={'failures': 2, 'received_responses': 0, 'required_responses': 1, 'consistency': 'ONE'}
しかし、Clustering keyであるsub_keyを指定して1行のみ取得するといったリクエストであれば失敗しないことが確認できます。
cqlsh> SELECT * FROM tombstone_100k.test04 WHERE key = 1 AND sub_key = 1;
key | sub_key | data
-----+---------+------
(0 rows)
shuishih@cqlsh> SELECT * FROM tombstone_100k.test04 WHERE key = 1 AND sub_key = 150000;
key | sub_key | data
-----+---------+------------------------------------------------
1 | 150000 | 100k tombstones test: key = 1 sub_key = 150000
(1 rows)
メトリクスを確認してみると、約105,000のTombstoneがスキャンされているのが見て取れます。

全件取得, ALLOW FILTERING, SECONDARY INDEX, IN句の場合
全件取得, ALLOW FILTERING, SECONDARY INDEX, IN句 などによる広範囲クエリでもScanned over 100001 tombstonesを引き起こすか気になったため、検証してみました。
検証では、15万のPartitionのデータを挿入し、そのうち11万のPartitionをPartition tombstonesで削除しました。(各Partitionには1つのTombstoneがある状態)
この状態で、全件取得, ALLOW FILTERING, SECONDARY INDEX, IN句で削除された11万のPartitionを読み込むクエリを実行してみました。
私の検証では、Scanned over 100001 tombstonesによるリクエスト失敗は起きませんでした。
また最後に紹介するTombstoneScannedHistogramのメトリクスで確認してみてもTombstoneは1個しかスキャンされていないことを確認しています。
ただし、cqlshの制限(LIMITやpagingなど)によって、削除された11万のPartitionを1度に読み込めていないなどが原因である可能性もあるため、全件取得, ALLOW FILTERING, SECONDARY INDEX, IN句ではScanned over 100001 tombstonesが発生しないという確証は得られていないです。
検証
Cassandra 3.11のバージョンで検証をしています。
全件取得, ALLOW FILTERING, SECONDARY INDEX, IN句でリクエスト失敗が起きないことの検証内容
全件取得, ALLOW FILTERING, SECONDARY INDEX, IN句でScanned over 100001 tombstonesによるリクエスト失敗が発生するかの確認をします。
テーブルは、以下のような定義にします。
CREATE TABLE IF NOT EXISTS tombstone_100k.test01 (
key int PRIMARY KEY,
data int)
WITH gc_grace_seconds = 3600;
このテーブルに以下のように15万件のデータを挿入した状態にします。
cqlsh> SELECT * FROM tombstone_100k.test01;
key | data
--------+---------
1 1
2 2
3 3
:
(省略)
:
150000 150000
(150000 rows)
ここから11万件のデータを削除します。
cqlsh> DELETE FROM tombstone_100k.test01 WHERE key = 1;
cqlsh> DELETE FROM tombstone_100k.test01 WHERE key = 2;
cqlsh> DELETE FROM tombstone_100k.test01 WHERE key = 3;
:
(省略)
:
cqlsh> DELETE FROM tombstone_100k.test01 WHERE key = 109998;
cqlsh> DELETE FROM tombstone_100k.test01 WHERE key = 109999;
cqlsh> DELETE FROM tombstone_100k.test01 WHERE key = 110000;
全件取得をしてみます。
クエリは失敗せずidが110001 ~ 150000のデータが取得できることがわかります。
cqlsh> SELECT * FROM tombstone_100k.test01;
key | data
--------+---------
110001 110001
110002 110002
110003 110003
:
(省略)
:
150000 150000
(40000 rows)
ALLOW FILTERINGで取得してみます。
リクエストは失敗しないことがわかります。
cqlsh> SELECT * FROM tombstone_100k.test01 WHERE data <= 110000 ALLOW FILTERING;
key | data
-----+------
(0 rows)
後ほど紹介するTombstoneScannedHistogramというメトリクスを見てみると、全件取得とALLOW FILTERINGそれぞれTombstoneが1件しか読み込まれていないことが確認できます。

SECONDARY INDEXについても確認してみます。
以下のようなテーブルを定義します。
CREATE TABLE IF NOT EXISTS tombstone_100k.test02 (
key int PRIMARY KEY,
data text,
class int)
WITH gc_grace_seconds = 3600;
次にINDEXを作成します。
CREATE INDEX rclass ON tombstone_100k.test02 (class);
15万件のデータを挿入します。class = 1が11万件 class = 2が4万件となるように挿入します。
cqlsh> SELECT * FROM tombstone_100k.test02 WHERE key = 1;
key | class | data
-----+-------+-------------------------------
1 | 1 | 100k tombstones test: key = 1
(1 rows)
cqlsh> SELECT * FROM tombstone_100k.test02 WHERE class = 2 LIMIT 1;
key | class | data
--------+-------+------------------------------------
121478 | 2 | 100k tombstones test: key = 121478
(1 rows)
class = 1の11万件のデータを削除します。
DELETE FROM tombstone_100k.test02 WHERE key = 1;
DELETE FROM tombstone_100k.test02 WHERE key = 2;
DELETE FROM tombstone_100k.test02 WHERE key = 3;
:
(省略)
:
DELETE FROM tombstone_100k.test02 WHERE key = 109998;
DELETE FROM tombstone_100k.test02 WHERE key = 109999;
DELETE FROM tombstone_100k.test02 WHERE key = 110000;
SECONDARY INDEXを使って取得してみます。
リクエストは失敗しないことがわかります。
cqlsh> SELECT * FROM tombstone_100k.test02 WHERE class = 1;
key | class | data
-----+-------+------
(0 rows)
SECONDARY INDEXにおいてもメトリクスを見てみると、Tombstoneが1件しか読み込まれていないことが確認できます。

IN句についても確認してみます。
IN句で10万のkeyを指定することはできないため、以下のように1000個のカラムを持つテーブルを定義し、それぞれのカラムをCell tombstonesで削除し、IN句で100件以上取得して合計でTombstoneが10万個以上になるようにします。
CREATE TABLE IF NOT EXISTS tombstone_100k.test03 (
key int PRIMARY KEY,
clm0001 int,
clm0002 int,
clm0003 int,
clm0004 int,
clm0005 int,
:
clm0996 int,
clm0997 int,
clm0998 int,
clm0999 int,
clm1000 int)
WITH gc_grace_seconds = 3600;
クエリが長いので途中の挿入や削除については省きますが、150件のデータを挿入して、そのうちの最初の110件のデータについてそれぞれのカラムをNULLに更新します(Cell tombstones)
その後IN句で110件取得すると問題なく取得できることを確認できます。
cqlsh> SELECT * FROM tombstone_100k.test03 WHERE key IN(1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,32,33,34,35,36,37,38,39,40,41,42,43,44,45,46,47,48,49,50,51,52,53,54,55,56,57,58,59,60,61,62,63,64,65,66,67,68,69,70,71,72,73,74,75,76,77,78,79,80,81,82,83,84,85,86,87,88,89,90,91,92,93,94,95,96,97,98,99,100,101,102,103,104,105,106,107,108,109,110);
key | clm0001 | clm0002 | clm0003 | clm0004 | clm0005 | clm0006 | clm0007 ...(省略)...
1 NULL NULL NULL NULL NULL NULL NULL
:
(省略)
:
(110 rows)
IN句ついて、メトリクスを確認するとTombstoneが約1000件スキャンされていることがわかります。これは、それぞれ1000個のカラムがあり、それらをNULLに更新したことでCell tombstonesが1000個ついたためです。
なぜメトリクスではぴったり1000件と表示されないのかについては、後ほど説明します。
gc_grace_secondsの期限
Tombstoneはgc_grace_secondsの期限が切れるとスキャンされなくなります。
CompactionなどでTombstoneを除去しなくても、gc_grace_secondsが切れたTombstoneは読み込まれなくなるため、Scanned over 100001 tombstonesによるリクエスト失敗は解消されます。
そのため、gc_grace_secondsが長く設定されていると有効なTombstoneが溜まりScanned over 100001 tombstonesのリクエスト失敗が起きやすくなるため、gc_grace_secondsは適切な値に調整することが重要です。(デフォルトは10日間です)
検証
Cassandra 3.11のバージョンで検証をしています。
gc_grace_secondsの期限が切れるとリクエスト失敗が起きないことの検証内容
先ほどの「1つのクエリで10万を超えるTombstoneをスキャンした場合」のときの検証で使用したtombstone_100k.test04について、gc_grace_secondsの期限が切れてからkey = 1のPartition内の全てのデータを取得するとリクエストの失敗なく取得できることが確認できます。
cqlsh> SELECT * FROM tombstone_100k.test04 WHERE key = 1;
key | sub_key | data
-----+---------+------------------------------------------------
:
(省略)
:
1 | 110795 | 100k tombstones test: key = 1 sub_key = 110795
1 | 110796 | 100k tombstones test: key = 1 sub_key = 110796
1 | 110797 | 100k tombstones test: key = 1 sub_key = 110797
1 | 110798 | 100k tombstones test: key = 1 sub_key = 110798
1 | 110799 | 100k tombstones test: key = 1 sub_key = 110799
1 | 110800 | 100k tombstones test: key = 1 sub_key = 110800
---MORE---
Tombstoneの監視
Tombstoneが意図せず多くなっていないかを確認するためのメトリクスやユーティリティコマンドを紹介します。
TombstoneScannedHistogram
Cassandraには、Tombstoneの監視メトリクスとしてTombstoneScannedHistogramがあります。公式ドキュメントはこちらです:
概要
TombstoneScannedHistogramは、クエリの実行時に読み込まれたTombstoneの数をヒストグラム形式で表示するメトリクスです。このメトリクスを使用することで、読み込み時にどれだけのTombstoneが検出されたかを監視できます。
特徴と機能
- 読み込んだTombstoneの検出: クエリ実行時に読み込まれたTombstoneの数を検出します。
- PartitionごとのTombstoneの個数: PartitionごとにTombstoneの個数を検出します。
- MemtableとSSTableの両方に対応: MemtableとSSTableのどちらにTombstoneがあっても検出することができます。
メトリクスの詳細
具体的には以下のようなメトリクスを取得できます。
Cassandra_Table_TombstoneScannedHistogram{keyspace="tombstone",table="test",value="Max:",} 0.0
Cassandra_Table_TombstoneScannedHistogram{keyspace="tombstone",table="test",value="Count:",} 5.0
Cassandra_Table_TombstoneScannedHistogram{keyspace="tombstone",table="test",value="Min:",} 0.0
Cassandra_Table_TombstoneScannedHistogram{keyspace="tombstone",table="test",value="Mean:",} NaN
Cassandra_Table_TombstoneScannedHistogram{keyspace="tombstone",table="test",value="99thPercentile:",} 0.0
Cassandra_Table_TombstoneScannedHistogram{keyspace="tombstone",table="test",value="999thPercentile:",} 0.0
Cassandra_Table_TombstoneScannedHistogram{keyspace="tombstone",table="test",value="StdDev:",} 0.0
Cassandra_Table_TombstoneScannedHistogram{keyspace="tombstone",table="test",value="50thPercentile:",} 0.0
Cassandra_Table_TombstoneScannedHistogram{keyspace="tombstone",table="test",value="75thPercentile:",} 0.0
Cassandra_Table_TombstoneScannedHistogram{keyspace="tombstone",table="test",value="98thPercentile:",} 0.0
Cassandra_Table_TombstoneScannedHistogram{keyspace="tombstone",table="test",value="95thPercentile:",} 0.0
例えばMaxであれば、スキャンされたTombstoneの最大値がわかります。
Meanであれば、スキャンされたTombstoneの平均値がわかります。
Countについては、Tombstoneの数ではなく、Tombstoneをスキャンしたクエリの数になります。
注意
正確な数字ではなくbinの値が表示される
このメトリクスは正確なTombstoneの数ではなく、ヒストグラムのbinの値で表示されます。
Cassandraのヒストグラムでは、
1,2,3,4,5,6,7,8,10,12,14,17,20,24,29,...,12108970,14530764,17436917,20924300,25109160
というように途中から約1.2倍ずつbinの幅が増えていくものとなっています。
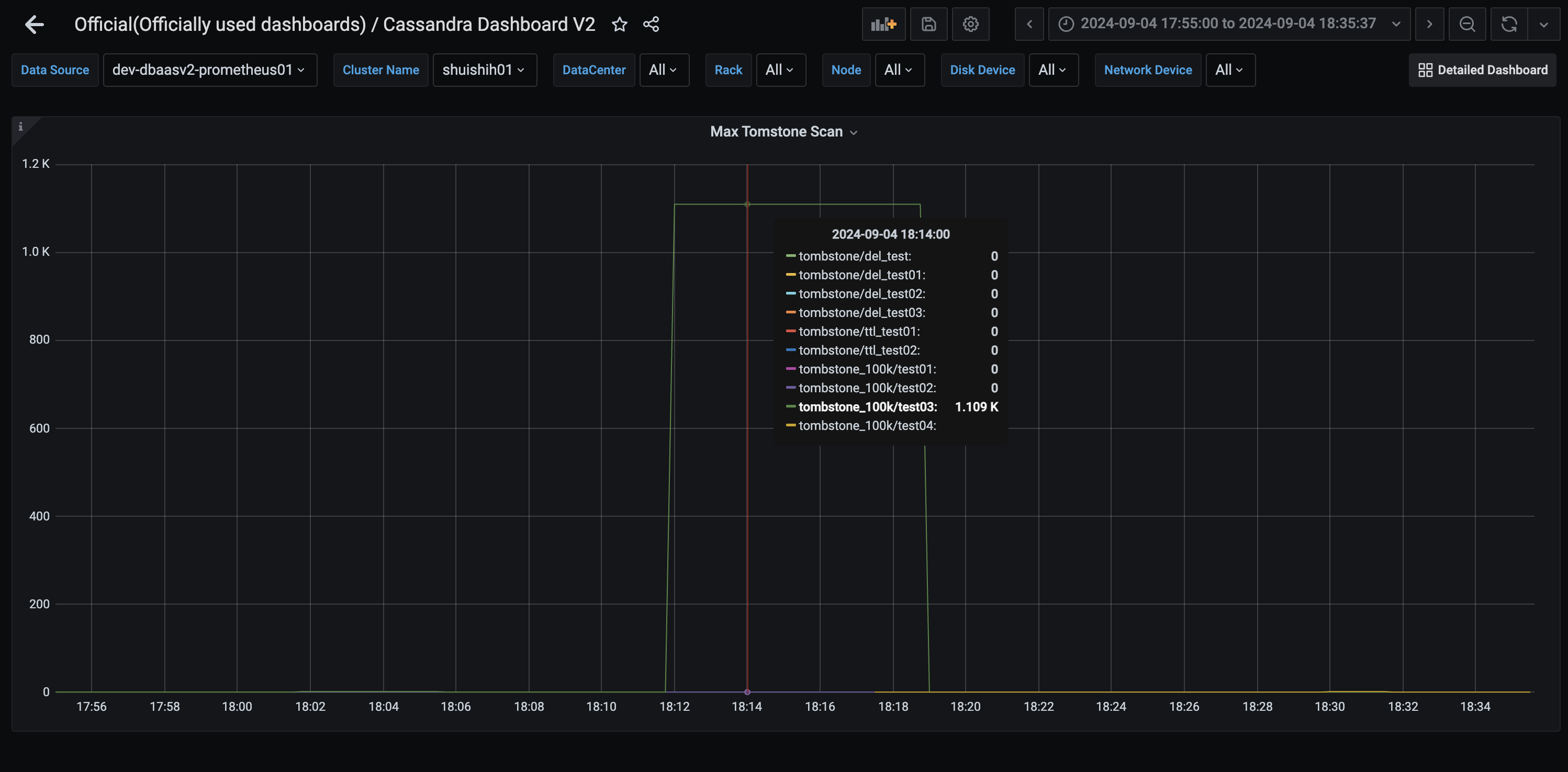
以下の画像では、1000個のTombstoneを含むPatitionを取得したときのメトリクスです。
このダッシュボードでは、Max(最大値)を見ています。
Tombstoneは1000個のみのはずですが、メトリクスでは1.109Kと表示されています。
これは、ヒストグラムのbinの値で表示されているためです。
クラスタ全体やTable全体のTombstone個数の監視はできない
このメトリクスはあくまでクエリによって読み込んだ(スキャンした)Tombstoneのみ監視することが可能です。そのため、クラスタ全体に存在するTombstoneの個数やTable全体に存在するTombstoneの個数を監視することはできません。
nodetool tablestats
TombstoneScannedHistogram以外にもnodetool tablestatsというコマンドを使うことでテーブルの統計情報を取得することができ、その中にTombstoneの情報も確認することができます。
例
Total number of tables: 49
----------------
Keyspace : tombstone
Read Count: 0
Read Latency: NaN ms
Write Count: 0
Write Latency: NaN ms
Pending Flushes: 0
Table: test
SSTable count: 1
Space used (live): 5261
Space used (total): 5261
Space used by snapshots (total): 0
Off heap memory used (total): 40
SSTable Compression Ratio: 0.6056338028169014
Number of partitions (estimate): 1
Memtable cell count: 0
Memtable data size: 0
Memtable off heap memory used: 0
Memtable switch count: 0
Local read count: 0
Local read latency: NaN ms
Local write count: 0
Local write latency: NaN ms
Pending flushes: 0
Percent repaired: 0.0
Bloom filter false positives: 0
Bloom filter false ratio: 0.00000
Bloom filter space used: 16
Bloom filter off heap memory used: 8
Index summary off heap memory used: 16
Compression metadata off heap memory used: 16
Compacted partition minimum bytes: 125
Compacted partition maximum bytes: 149
Compacted partition mean bytes: 149
Average live cells per slice (last five minutes): 1.0
Maximum live cells per slice (last five minutes): 1
Average tombstones per slice (last five minutes): 1.0
Maximum tombstones per slice (last five minutes): 1
Dropped Mutations: 0
----------------
まとめ
この記事では、CassandraにおけるTombstoneの種類とその発生を抑える方法について詳しく解説しました。以下に要点をまとめます。
-
Tombstoneの種類とその特性:
- Partition tombstones: パーティション全体を削除する際に1つのTombstoneが生成されます。
- Row tombstones: 行単位で削除する際に各行ごとにTombstoneが生成されます。
- Cell tombstones: カラムをNULLに更新する際に各セルごとにTombstoneが生成されます。
- TTL tombstones: TTLが切れた際に各セルごとにTombstoneが生成されます。
-
Tombstoneの削減方法:
- 可能な限り、Partition tombstonesやRow tombstonesを使用することで、Tombstoneの数を減らすことができます。
- Cell tombstonesやTTL tombstonesは大量のTombstoneを生成しやすいので注意が必要です。
-
Scanned over 100001 tombstonesエラーの回避方法:
- 特定のPartition内に10万を超えるTombstoneが存在しないように、データのパーティショニングを適切に行うことが重要です。
- Partition内のすべての行を取得するようなクエリは避け、特定の行のみを取得するクエリを心がけましょう。
-
gc_grace_secondsの値を適切に設定し、Tombstoneが長期間残らないようにします。
-
Tombstoneの監視:
-
TombstoneScannedHistogramやnodetool tablestatsを使用して、Tombstoneの数やその影響を監視することができます。
-
Tombstoneの管理はCassandraのパフォーマンスに直結する重要な要素です。適切な削除方法と監視方法を実践し、Cassandraのパフォーマンスを最大限に引き出しましょう。