はじめに
最近、異常検知に関する案件に関わって、結構苦労しました。
その理由の一つとして、異常検知の手法については一部本がでているもののそこまで多くはなく、また、異常検知プロジェクトの進め方という意味では情報があまり見つけられなかったというのがあります。
そこで、プロジェクト実施前に、こんな情報があればよかったなという内容についてまとめました。
自分が関わった案件は、設備のセンサーデータを用いた異常検知だったため、その内容に偏っていますが、全体の流れや考え方としてはあまりドメインや異常検知によらないものと思います。
なお、個別の異常検知のアルゴリズムについては話しません。
また、読者の対象しては、異常検知に興味がある人、機械学習プロジェクトに興味がある人を想定しています。
異常検知を取り巻くコミュニケーション
前提として、「異常検知」という言葉でイメージするものは人によって違います。関係者で、用語が何を指すかは明確にした方がよいです。
今、この記事を読んでくださっている方の異常検知のイメージも様々だと思いますので、はじめに異常検知という言葉を明確にしたいと思います。
用語の定義
設備や機械を用いた業界で、異常検知という言葉を使うとき、以下の可能性があります。
業界や取り扱うデータによって別のことを指す場合もあるかもしれません。
- 故障予知:故障発生前に故障を予知すること。
- 故障検知:故障が発生していることを検知すること。
- 異常検知:異常を検知(それが特定の故障と関係するかは不明)すること。
工場や設備関係の業界では、予知保全という言葉があることから、異常検知という言葉が故障予知を想定していることが多いように思います。
他のドメインではわかりませんが、例えば、1時間あたりのサポートメールの件数をカウントしていて、ある時、急激にメールの件数が増えたとしたとき、「故障予知」、「故障検知」、「異常検知」はそれぞれ以下のイメージとなります。
- 異常検知は、メールの件数が増えたことをアラートしてくれること。
- 故障検知は、メールの件数が増えた原因は、〇〇です。と、特定できること。
- 故障予知は、先取りする指標があればそれを計測して〇〇が発生しそうです。と教えてくれること。
故障予知は通常難易度が高いですが、機械の場合、動くけど異常は発生しているという状態が存在します。
機械の故障とは、いきなり壊れるのではなく、例えば部品に亀裂が入り、亀裂が大きくなり、いずれ壊れます。
この時の亀裂の長さを計測すれば、亀裂の長さが〇cmに達したので、動かなくなる前に部品を交換しましょう(故障予知)ということができますし、亀裂の長さ以外の情報でも亀裂によって発生した振動の歪み等でもデータを逐次獲得していることで故障を予見できる場合があります。
異常検知のための手法
異常検知(故障検知、故障予知)では、大きく分けて以下の手法が使われます。
- ルールベース:ある指標がいくつを超えたら異常とみなす等の人間が定めたルールをもとに異常を検知する。
- 教師あり学習:正常データと異常データを学習させ、正常と異常を分別する。
- 異常検知:正常データのみを学習させ、正常データに似ていないものを検知する。
「異常検知をやりたい」と言われた場合、手法としての異常検知ではなく、工場や製造業なら「AIを使った予知保全をしたい」くらいの意味で使われている可能性があります。ほかの業界でも、見つけたいものは「異常」なのか、特定の何かなのかは明確にする必要があります。
特定の故障を見つけるためには、基本的には教師あり学習(明確な規則があればルールベースでも)にする必要があります。異常検知という言葉から手法としての異常検知にとらわれず、ビジネス目的にあった手法を選択する必要があります。
コミュニケーションの注意点
上記でも記載しましたが、だれかが「異常検知やりたい!」といったとした場合、手法を指しているのか、単に異常を検知することを指しているのか、故障予知を指しているのか不明です。こういうコミュニケーションのミスによって、ルールベースで済むものを、異常検知の手法を使ったシステムを検討してしまうなんてことが起こります。
また、エンジニアやDS同士の会話では、画像系か時系列系かでも話がかみ合わない場合がありますし、当然ドメインでも話がかみ合わない場合があります。今回の例では「異常検知」ですが、機械学習プロジェクトのコミュニケーションではメンバー内の理解やイメージが異なる場合が多くあります。逐一用語の確認をするなど、丁寧なコミュニケーションを心がけましょう。
異常検知プロジェクトの進め方
この辺は以下の本や情報が役立ちます。
詳細はこれらを見ていただきたいですが、異常検知(機械学習)プロジェクトでは、以下のことを行います。
- プロジェクトの企画
- テーマ検討と目的の決定
- 目標の決定
- 体制決定
- 機械学習システムを含めた業務検討
- システム構成検討
- データの確認
- 分析方法案の検討
- PoC
- 分析内容詳細検討
- 分析
- 評価
- 評価後の方針検討
- ビジネス適用
- 業務要件見直し
- システム設計
- システム構築
- プレ運用
- プレ運用後評価
- 運用
以下では、各項目で特に気を付けたほうがよいことや、自分がプロジェクト実施中に気が付いたことなどをまとめます。
プロジェクトの企画
機械学習システム全般にいえる話ですが、まずはビジネス目的を明確にしましょう。
AIを使うことに意味を見出す場合がありますが、それではビジネス適用までいきません。
よくみるのが、「データがある→AIしたい→このビジネスに使えそう」という形です。
これだと、無理やりデータとビジネスを結び付けてしまうことがあり、PoCやビジネス適用時に失敗するケースが多いようです。(ただ、このケースが必ず悪いというつもりはありません。)
特に、人間がデータを見て異常時に異常とわかったり、故障時に故障とわからないデータでもまずできません。
また、故障予知は故障予知をすることを想定していないデータではできません。
故障予知は、故障予知をするためのセンシングをする必要があります。
「こういうビジネス課題がある→AIを使わないと解決できない→そのためのデータはこういうデータが必要」という順序が正しい順序です。
もちろん、データがない場合も多くあるでしょう。これらの場合、データを取得するところから始めましょう。
過去には戻れないので、今からデータを取得するのが一番早く成功する秘訣だと思います。
機械学習はデータを基にモデルが作られます、「garbage in garbage out」というように、入力データの特に大事です。
目的に合わせたデータがあるのか、データがないならそれは取得できるのか、取得も含めて投資する価値があるものなのか、企画時には丁寧に話し合う必要があります。
なお、データがない場合、最終的な目的に異常検知があってもデータの可視化だけでもビジネス価値がある場合もありますので、その場合はまずは手の届きやすいデータの可視化から始める方が良いかもしれません。
また、企画時にわかっている課題があれば、プロジェクトメンバーで共有し、見える形に書きだしておきましょう。
課題への対応はどうすれば可能なのかも検討しましょう。対応できなさそうなものがあれば、いずれそれは表面化します。
PoC
PoCは適切な目標がたっていれば、分析を実施するだけです。
ここで、特に気をつけるべきは評価指標についてだと思います。
これは、ビジネス的なKPIとは異なります。そのため、評価指標ばかりを気にするのはあまりよくありません。
また、PoCの中盤以降に初めに決めた評価指標が適切でなかったことがわかるケースもあります。
そのため、データと出力される異常度の値を直接確認したり、様々な角度で可視化することで評価指標が適切なのかを確認することもよいと思います。
以下に、正常と異常の2値分類と見た時に使われる評価指標の例を示ます。
AUC
二値分類で使われる一般的な評価指標です。tp-fp曲線(ROC)の下部面積です。
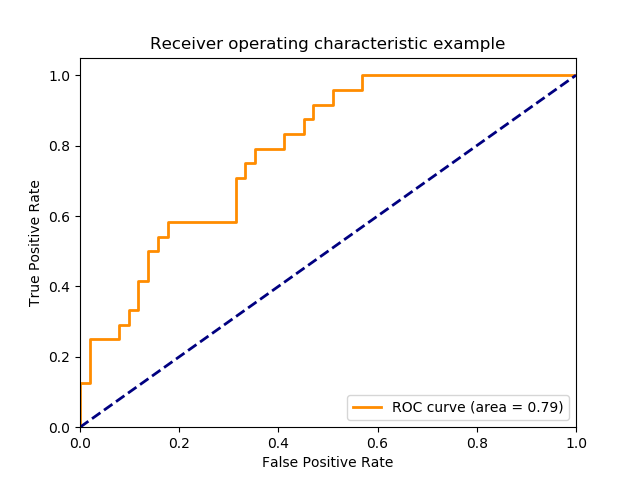
※引用 https://scikit-learn.org/stable/auto_examples/model_selection/plot_roc.html#sphx-glr-auto-examples-model-selection-plot-roc-py
異常検知では、基本的に不均衡データとなります。
不均衡データでAUCを使うことは、否定的な意見が多いようですが、私は必ずしもAUCを使うことが悪いとは思いません。
不均衡データだからと盲目に避けるのではなく、都度ビジネス目的と照らし合わせて検討すべきだと思います。
ただし、AUCは「異常を異常と分別できたか」と「正常を正常と分別できたか」を同じ比重で見ます。
正常が大多数の不均衡データの場合、だいたいの正常データは正しく分かれるので、「異常を異常と分別できたか」に注目したくなります。
その場合、以下の二つの評価指標が使われます。
PRAUC
不均衡データの二値分類で使われる評価指標。
不均衡データでは、よくPRAUCが使われます。
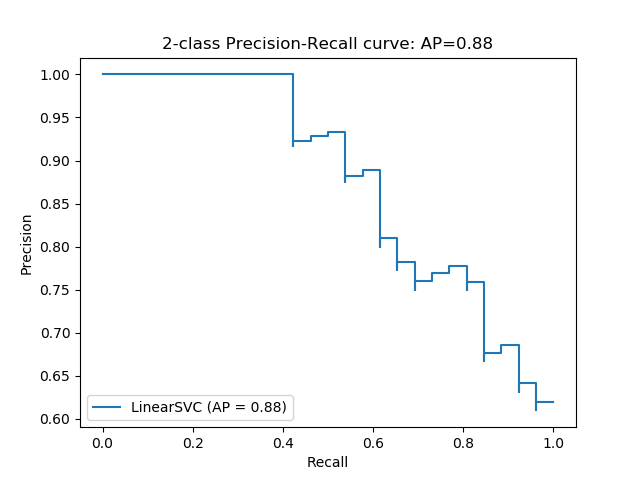
※引用 https://scikit-learn.org/stable/auto_examples/model_selection/plot_precision_recall.html#sphx-glr-auto-examples-model-selection-plot-precision-recall-py
PRAUCは「異常を異常と分別できたか」のみに注目し、正常データがどうであるかは見ません。
あまり指摘されることが少ないように思いますが、PRAUCは正常データと異常データの比率が変わると評価指標の値が変わります。
以下の図は、以下の条件でrecallが1の時のみプロットしたPR曲線(2点だから直線だけど)です。
①異常データが1%存在するとき。
②異常データが50%存在するとき。
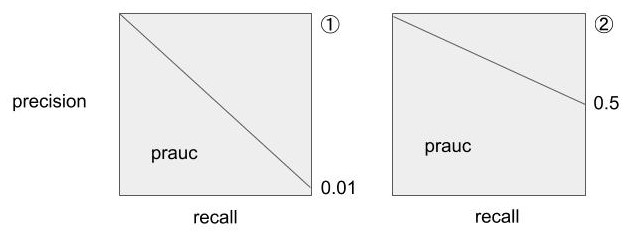
図から見てもわかる通り、異常データの比率によってPRAUCのスコアが変わります。
そのため、前処理等によって、正常と異常のデータ数が変わる場合にはPRAUCで適切に評価できない場合があります。
p-AUC
不均衡データの二値分類で使われる評価指標。
p-AUCはAUCのfprに制限を設けたものです。以下の図は、p値を0.2とした場合であり、赤枠の中のみの下部面積をスコアとします。
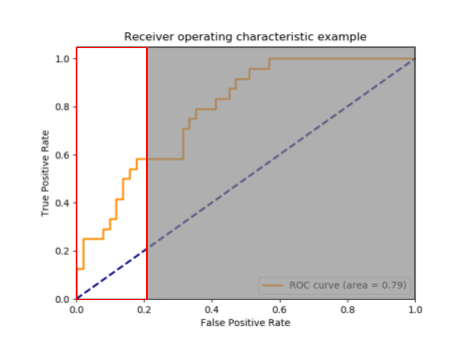
※上記scikit-learnの図に追記
この場合、大多数の分離が容易な(右側はスコアの高くなりやすい)正常データを無視することで、その不均衡データに合わせて「異常を異常と分別できたか」と「正常を正常と分別できたか」をバランスよく評価することができます。
一方で、p値をどう設定するかについては検討する必要があります。
ビジネス適用
正直、プロジェクトの企画が特に重要でそこがうまく行けば、ビジネス適用まで行く可能性は低くないと思います。
多くのプロジェクトがうまくいかないのは企画の時点ですでに問題を抱えている場合が多いからだと思います。
ところで、ビジネス適用時の課題の一つに、機械学習を組み込むとシステム構築や運用に費用が思いの外かさむことがあげられると思います。
企画時にシステム構成の検討はしても、保守や運用まで検討するケースは少ないのかなと思っています。ある程度はこの辺をあらかじめ検討することも大事だと思います。
一方で、PoC実施後に当初の計画とは違うけど条件付きでうまくいきそうとなる場合もあり、そうした場合に果たして本当にビジネス適用するのか、今一度確認する必要があるかと思います。
手法としての異常検知
ここでは、手法としての異常検知について、簡単に説明します。
すでに書いていますが、異常検知をしたいと言われたときに、手法としての異常検知を想像して話を進めると間違った方向に進む可能性があります。
あくまで、ビジネス課題にあったプロジェクトとする必要があるので、状況に応じて教師あり学習やルールベースも検討しましょう。
手法としての異常検知に関しては以下の本が参考になります。
どちらも硬派な本ですが、「異常検知と変化点検知」は「入門 機械学習による異常検知」の続編的な位置らしいので、入門の方から読むとよいと思います。
また、shinmura0さんの記事は最近のトレンドをつかんでおり、とても参考になります。
異常検知の概要
手法としての異常検知は、以下の手順で行います。(詳細は上記本に任せます。)
- 学習時には、正常データのみを学習し、正常データの分布(構造、学習済みモデル)を求める。
- 評価時には、評価データが正常データの分布からどの程度離れているか(異常度)を計算する。
- しきい値を設け、しきい値以上、異常度の大きいデータを異常とする。
従って、正常データと異常データの近さが問題となります。繰り返しますが、正常データと異常データを人が見て区別しやすいものなのかは直感的な指標になりますので、難易度を測れると思います。
当然ですが正常データが明確じゃない場合や正常データに異常データが入っている場合には、正しく異常を分別できなくなります。
異常検知ライブラリ
異常検知のためのライブラリはあまり多くないと思いますが、以下があります。
細かい話ですが、scikit-learnや自作のライブラリで複数のモデルをためそうと思うと、異常度という形で出力するようにラップする形となります。
つまり、例えば、kNNなら学習データからの距離を異常度とみなしますが、これを距離という前提でコードを書くと別のモデル(例えば、予測値からの差が異常度となるモデル)を試したいときに、変数名と実態が合わなくなるため、異常度を出力するという形でラップする方が好ましいと思います。
その点、PyODは異常度を出力する形に予めなっているため、この辺の煩わしさが減り、また、異常検知のための引数も揃っているため、いろいろ試したいときにも実装の手間が省けます。
まとめ
異常検知(機械学習自体も)は、ビジネス適用も含めるまだまだ挑戦的で難しい分野だと思います。
しかし、企画やデータ取得というはじめのところから丁寧に実施することで、ビジネス適用まで行きやすくなると思います。