はじめに
自分で見返せるようにまとめたものを残す(with 本文和訳)
元記事:Software 2.0
ソフトウェア2.0とは
- ニューラルネットワーク(以下、NN)を単なる「数ある機械学習の内の一つ」として見るのは、木を見て森を見ないのと同じだ
- NNは、「数ある機械学習の一つ」ではなく、「ソフトウェア開発方法の根本的な変革の始まり」を表しており、それこそがソフトウェア2.0である
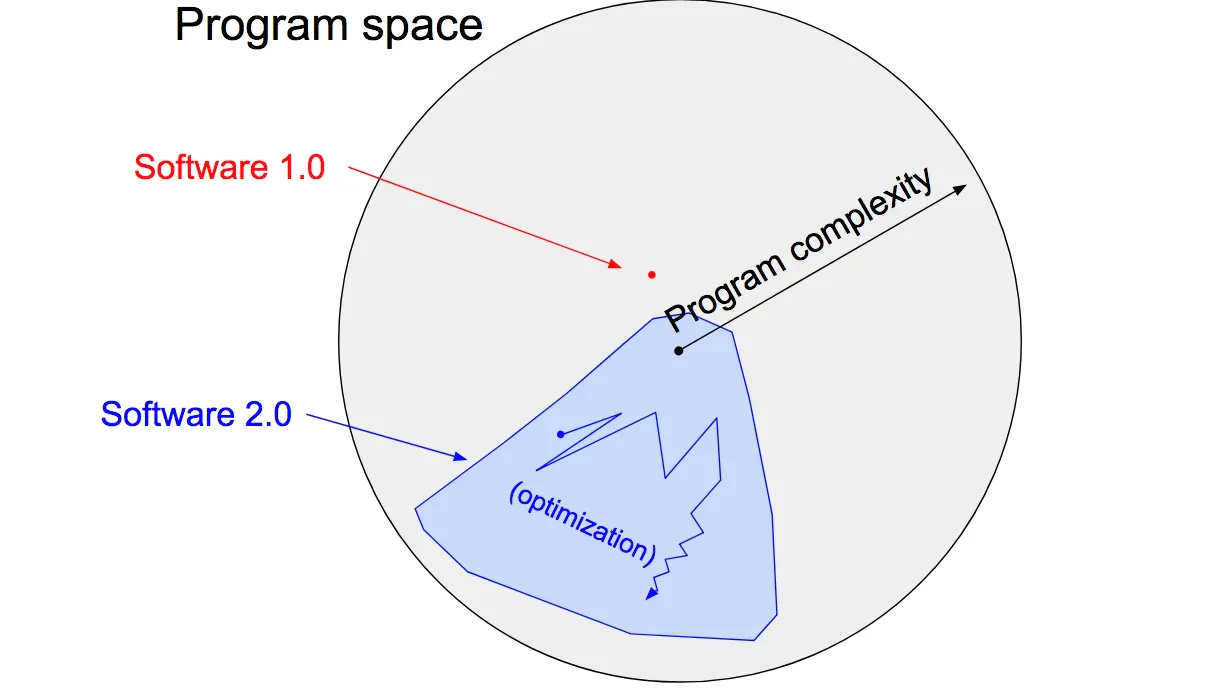
- ソフトウェア1.0は、私たちが読むことのできる言語でコードを書き、プログラム可能な範囲から特定のポイントと望ましい動作と結びつける
- 上記に対し、ソフトウェア2.0は、人間が読むこともできず、コードの記述に関与さえもしていない代わりに、プログラム可能な範囲から特定のポイントを検索するための骨組み(アーキテクチャ)を書くことで、効率的に検索を行うようにさせる
- 実際問題、コードを書くよりもデータを収集する方のが用意であり、ソフトウェア1.0から2.0への移行は始まっている
引用:Software 2.0
ソフトウェア2.0に置き換わっているもの
- 画像認識:以前は人の手で調整された特徴と少しの機械学習を合わせたもの(SVM)だったのが、現在では畳み込みNNによって、より強力な画像認識を実現した
- 音声認識:以前は多くの前処理や、ガウス混合モデル、隠れマルコフモデルを必要としていたが、現在ではほとんどがNNによるものだ
- 音声合成:(以下略)
- 機械翻訳
- ゲーム
- データベース
ソフトウェア2.0の利点
- 計算の均一性:NNは、行列乗算とゼロでの閾値処理で構成されているため、正確性/パフォーマンスの保証を行うことがはるかに容易
- チップへの組み込みやすさ:NNのコードが比較的小さいことから、チップへの実装が容易である
- 実行時間が一定:典型的なNNの各イテレーションは、正確に同じ量のFLOPSであり、意図しない無限ループに入ることも殆どない
- メモリ使用量が一定:動的に割り当てられるメモリはないので、ディスクへのスワップやメモリリークを心配する必要がない
- 高い移植性:従来のプログラムは特定の言語やコンピュータに依存するが、NNは行列乗算であるため特定の対象に依存せず実行できる
- 高い柔軟性:C++コードで正確性を犠牲にして実行速度を2倍にすることの調整は困難を極めるが、NNではネットワークのチャンネルの半分を削除し、再トレーニングさせるだけで、2倍の速度で実行させることができる
- モジュールの全体最適:従来のソフトウェアはAPIやエンドポイントを通して通信するモジュールに分割されており独立しているが、トレーニングされたモデルを連携させるソフトウェア2.0では、全体の動作に合わせてチューニングさせることができる
- 君が書くコードよりも優れている:NNは、画像/ビデオや音声/音声に関連する分野の大部分で、私たちやあなたが考えるよりも優れた結果を出すコードを書く
ソフトウェア2.0の制限
- ソフトウェア2.0の欠点としては、中身がブラックボックスであるということ
- 今後のアプリ開発での選択肢としては、中身が理解可能な精度90%のアプリか、中身が理解不可能な精度99%のアプリかになるだろう
- また、トレーニングデータにバイアスがある時、それに引っ張られてしまうという欠点がある
ソフトウェア2.0でのプログラミング
- 2.0におけるプログラミングはデータセットの蓄積、整形、クリーニングになるだろう
- 同様に2.0でのGithubでは、リポジトリはデータセットになり、コミットの対象はラベルの追加や編集になるだろう
- 2.0での、パッケージマネージャー(npm)や開発インフラ(docker)に相当するものはなんだろうか?
- 長期的に見れば、ソフトウェア2.0のパラダイムの未来は明るい
- なぜならAGIが開発される時、それは確実にソフトウェア2.0で書かれることが明らかになってきているからだ
(本文〜Google翻訳〜)
ニューラル ネットワークを単に「機械学習ツールボックスのもう1つのツール」と呼んでいる人を時々見かける。
これらにはいくつかの長所と短所があり、あちこちで機能し、時にはKaggleコンテストで勝つために使用できることもある。
残念ながら、この解釈では木を見て森を完全に見落としている。
ニューラル ネットワークは単なる分類器ではなく、ソフトウェアの開発方法における根本的な変化の始まりを表している。
それらは、ソフトウェア2.0です。
ソフトウェア 1.0の「クラシック スタック」は、私たち全員がよく知っているものだ。
これは、Python、C++ などの言語で書かれている。
これは、プログラマによって書かれたコンピュータへの明示的な命令で構成されている。
コードの各行を記述することにより、プログラマは、望ましい動作を行うプログラム空間内の特定の点を特定します。

引用:Software 2.0
対照的に、ソフトウェア2.0は、ニューラル ネットワークの重みなど、はるかに抽象的で人間には不親切な言語で書かれています。
多くの重みがあり(通常のネットワークには数百万ある可能性があります)、重みを直接コーディングするのは難しいため、このコードの作成には人間は関与しません。
引用:Software 2.0
代わりに、私たちのアプローチは、望ましいプログラムの動作に関する何らかの目標を指定し、
(例:「例の入出力ペアのデータセットを満たす」、または「囲碁のゲームに勝つ」)、
コードの大まかな骨格を書くことです(つまり、ニューラル ネットワーク アーキテクチャ)。
それは、検索するプログラム空間のサブセットを特定し、自由に使える計算リソースを使用して、この空間で動作するプログラムを検索します。
ニューラル ネットワークの場合、検索をプログラム空間の連続サブセットに制限します。そこでは、バックプロパゲーションと確率的勾配降下法を使用して検索プロセスを (少し驚くべきことに) 効率的に行うことができます。
引用:Software 2.0
類似性を明確にするために、ソフトウェア1.0では、人間が操作したソース コード (たとえば、一部の .cpp ファイル) は、有用な機能を実行するバイナリにコンパイルされます。
ソフトウェア 2.0 では、ほとんどの場合、ソース コードは、1) 望ましい動作を定義するデータセット、2) コードの大まかな骨格を与えるニューラル ネットワーク アーキテクチャで構成されますが、多くの詳細 (重み) を入力する必要があります。
ニューラル ネットワークをトレーニングすると、データセットがバイナリ (最終的なニューラル ネットワーク) にコンパイルされます。
今日のほとんどの実用的なアプリケーションでは、ニューラル ネット アーキテクチャとトレーニングシステムがますます商品として標準化されているため、アクティブな「ソフトウェア開発」のほとんどは、ラベル付きデータセットのキュレーション、成長、マッサージ、クリーニングという形をとっています。
これにより、ソフトウェアを反復処理するプログラミング パラダイムが根本的に変わります。チームが 2 つに分かれ、2.0 プログラマー(データラベラー) がデータセットの編集と拡張を行い、数人の 1.0 プログラマーが周囲のトレーニングコードインフラストラクチャの保守と反復を行います。
分析、視覚化、およびラベル付けインターフェイス。
現実の問題の大部分には、プログラムを明示的に記述するよりもデータを収集する (より一般的には、望ましい動作を特定する) 方がはるかに簡単であるという特性があることがわかりました。
これと、以下で説明する Software 2.0 プログラムの他の多くの利点により、多くの 1.0 コードが 2.0 コードに移植されるという、業界全体にわたる大規模な移行を目の当たりにしています。
ソフトウェア (1.0) が世界を飲み込み、今では AI (ソフトウェア 2.0) がソフトウェアを食べています。
進行中の移行
この進行中の移行の具体的な例をいくつか簡単に見てみましょう。
これらの各領域では、ここ数年、明示的なコードを作成して複雑な問題に対処することを諦め、代わりにコードを
2.0 スタックに移行することで改善が見られました。
視覚認識
は、最後に少しの機械学習が散りばめられた、エンジニアリングされた機能で構成されていました (SVM など)。
それ以来、私たちは大規模なデータセット (ImageNet など) を取得し、畳み込みニューラル ネットワーク アーキテクチャの空間で検索することにより、さらに強力な視覚的特徴を発見しました。
最近では、アーキテクチャを手作業でコーディングできるかどうかさえ自信がなくなり、アーキテクチャについても調査し始めました。
音声認識
には、かつては多くの前処理、混合ガウス モデル、隠れマルコフモデルが含まれていましたが、現在ではほぼ完全にニューラルネットのもので構成されています。
1985年のフレッド ジェリネックによる、よく引用される、非常に関連したユーモラスな引用に、「言語学者を解雇するたびに、音声認識システムのパフォーマンスが向上します」というものがあります。
音声合成
には、歴史的にさまざまなステッチングメカニズムが使用されてきましたが、現在最先端のモデルは、生のオーディオ信号出力を生成する大規模な ConvNet(例: WaveNet ) です。
機械翻訳
は通常、フレーズベースの統計手法を使用したアプローチでしたが、ニューラル ネットワークが急速に主流になりつつあります。
私のお気に入りのアーキテクチャは、単一のモデルが任意のソース言語から任意のターゲット言語に翻訳する多言語設定、および弱い教師あり (または完全に教師なし) 設定でトレーニングされています。
ゲーム
明示的にハンドコーディングされた囲碁対局プログラムは長い間開発されてきましたが、AlphaGo Zero (盤の生の状態を調べて手を打つ ConvNet) が、今ではこのゲームの中で最も強力なプレーヤーになりました。
他の分野、例えばDOTA2やStarCraftでも非常に似たような結果が見られると思います。
データベース
人工知能以外のより伝統的なシステムにも、移行の初期の兆候が見られます。たとえば、「学習されたインデックス構造のケース」では、データ管理システムのコアコンポーネントをニューラル ネットワークに置き換え、キャッシュ最適化 B ツリーを最大70%上回る速度でパフォーマンスを向上させながら、桁違いにメモリを節約します。
上記の私のリンクの多くは、Google で行われた研究に関係していることに気づくでしょう。
これは、Google が現在、自社の大規模な部分を Software 2.0 コードに書き直す最前線にあるためです。
「それらすべてを支配する 1 つのモデル」は、個々のドメインの統計的強度が世界の 1 つの一貫した理解に統合される、これがどのようなものであるかについての初期のスケッチを提供します。
ソフトウェア 2.0 の利点
なぜ複雑なプログラムを Software 2.0 に移植することを好むのでしょうか?
明らかに、簡単な答えの1つは、実際にはそれらの方がうまく機能するということです。ただし、このスタックを好む便利な理由は他にもたくさんあります。
ソフトウェア 1.0 (実稼働レベルの C++コードベースと考えてください) と比較したソフトウェア 2.0 (ConvNet と考えてください) の利点のいくつかを見てみましょう。ソフトウェア 2.0 は次のとおりです。
計算的には均一
典型的なニューラル ネットワークは、一次的に、行列乗算とゼロ閾値処理 (ReLU) という 2 つの演算のみのサンドイッチで構成されています。
これを、はるかに異質で複雑な従来のソフトウェアの命令セットと比較してください。
少数のコア計算プリミティブ (行列乗算など) に対してソフトウェア 1.0 実装を提供するだけでよいため、さまざまな正確性/パフォーマンスの保証を行うことがはるかに簡単になります。
シリコンに焼き付けるだけの簡単作業
当然のことながら、ニューラルネットワークの命令セットは比較的小さいため、カスタムASICやニューロモーフィック チップなどを使用して、これらのネットワークをシリコンに非常に近づけて実装することが非常に簡単になります。
低能力の知性が私たちの周りに浸透すると、世界は変わります。
たとえば、小型で安価なチップには、事前学習済みの ConvNet、音声認識装置、WaveNet 音声合成ネットワークが搭載されており、これらはすべて小さなプロトブレインに統合されており、物に取り付けることができます。
一定の稼働時間
一般的なニューラルネットの順方向パスの各反復には、まったく同じ量のFLOPSがかかります。
広大なC++コードベース内でコードがたどる可能性のあるさまざまな実行パスに基づく変動はゼロです。
もちろん、動的な計算グラフを使用することもできますが、通常、実行フローは依然として大幅に制約されます。
このようにすることで、意図しない無限ループに陥ることもほぼ確実になくなります。
一定のメモリ使用量
上記に関連して、動的に割り当てられるメモリがどこにもないため、ディスクへのスワップや、コード内で追跡する必要があるメモリ リークの可能性もほとんどありません。
携帯性に優れています
一連の行列乗算は、従来のバイナリやスクリプトと比較して、任意の計算構成で実行するのが大幅に簡単です。
非常に機敏です
C++コードがあり、誰かがそれを(必要に応じてパフォーマンスを犠牲にして)2倍の速度にすることを要求した場合、新しい仕様に合わせてシステムを調整するのは非常に簡単ではありません。
しかし、Software 2.0 では、ネットワークを取り込み、チャネルの半分を削除し、再トレーニングすると、正確に 2 倍の速度で実行されますが、動作は少し悪くなります。
魔法です。
逆に、より多くのデータ/コンピューティングを取得した場合は、チャネルを追加して再トレーニングするだけで、プログラムの動作をすぐに改善できます。
モジュールは最適な全体に融合できます
当社のソフトウェアは多くの場合、パブリック関数、API、またはエンドポイントを通じて通信するモジュールに分解されます。
ただし、元々別々にトレーニングされた 2 つの Software 2.0 モジュールが相互作用する場合、全体を簡単に逆伝播できます。
Web ページの読み込み効率を高めるために、Webブラウザーが10スタックの低レベルのシステム命令を自動的に再設計できたら、どれほど素晴らしいことになるか考えてみましょう。
または、インポートしたコンピュータービジョンライブラリ(OpenCV など)を特定のデータに合わせて自動調整できる場合。
2.0 では、これがデフォルトの動作です。
それはあなたよりも優れています
最後に、そして最も重要なことは、ニューラル ネットワークは、現時点では少なくとも画像/ビデオと音声/音声に関係する貴重な分野の大部分において、あなたや私が思いつくコードよりも優れたコードであるということです。
ソフトウェア 2.0 の制限
2.0 スタックには、独自の欠点もいくつかあります。
最適化の最後には、うまく機能する大規模なネットワークが残りますが、その方法を判断するのは非常に困難です。
多くのアプリケーション分野において、理解している90% 正確なモデルを使用するか、理解していない99%正確なモデルを使用するかの選択が残されます。
2.0スタックは、直感的ではなく恥ずかしい方法で失敗する可能性があり、さらに悪いことに、トレーニングデータにバイアスを黙って採用することによって「静かに失敗」する可能性があります。
データのサイズが数百万単位に達する場合、適切に分析して調べるのは非常に困難です。ほとんどの場合。
最後に、このスタックの特異な特性のいくつかをまだ発見中です。
たとえば、敵対的な例や攻撃の存在は、このスタックの直感的ではない性質を浮き彫りにしています。
2.0 スタックでのプログラミング
ソフトウェア 1.0 は私たちが書くコードです。
Software 2.0は、「この訓練データを正しく分類する」などの評価基準に基づいて最適化して記述されたコードです。
プログラムが明らかではないが、そのパフォーマンスを繰り返し評価できる設定 (例 - いくつかの画像を正しく分類しましたか? 囲碁のゲームに勝てますか?) は、この移行の対象となる可能性があります。
人間が書くよりもはるかに優れたコードを見つけることができます。
引用:Software 2.0
トレンドを見るレンズが重要です。単にニューラル ネットワークを機械学習技術のクラスにおける非常に優れた分類子として扱うのではなく、ソフトウェア 2.0 を新しく出現したプログラミングパラダイムとして認識すると、外挿がより明白になり、やるべきことがさらにたくさんあることは明らかです。
特に、構文の強調表示、デバッガー、プロファイラー、def への移動、git統合などの機能を備えた強力なIDEなど、人間による1.0コードの作成を支援する膨大な量のツールを構築してきました。
2.0 スタックでは、プログラミングは、データセットの蓄積、マッサージ、クリーニングによって行われます。
たとえば、ハードケースまたはまれなケースでネットワークに障害が発生した場合、コードを作成することで予測を修正するのではなく、それらのケースのラベル付きの例をさらに含めることによって、その予測を修正します。
データセットの蓄積、視覚化、クリーニング、ラベル付け、およびソースのすべてのワークフローを支援する最初の Software 2.0 IDE を開発するのは誰でしょうか?
おそらくIDEは、例ごとの損失に基づいてネットワークが誤ってラベル付けされていると疑われる画像をバブルアップしたり、ラベルに予測をシードしてラベル付けを支援したり、ネットワークの予測の不確実性に基づいてラベル付けに役立つ例を提案したりします。
同様に、Githubは Software1.0コードの拠点として非常に成功しています。
Software2.0Github用のスペースはありますか?
この場合、リポジトリはデータセットであり、コミットはラベルの追加と編集で構成されます。
従来のパッケージ マネージャーと、pip、conda、dockerなどの関連サービスインフラストラクチャを使用すると、バイナリのデプロイと作成がより簡単になります。
Software2.0バイナリを効果的に導入、共有、インポート、操作するにはどうすればよいでしょうか?
ニューラル ネットワークのcondaに相当するものは何ですか?
短期的には、ソフトウェア2.0は、反復評価が可能で安価であり、アルゴリズム自体を明示的に設計することが難しいあらゆる分野でますます普及するでしょう。
ソフトウェア開発エコシステム全体と、それをこの新しいプログラミングパラダイムにどのように適応させるかを検討する刺激的な機会がたくさんあります。
そして、AGIを開発する際には必ずSoftware2.0で書かれることがますます明らかになっているため、長期的にはこのパラダイムの将来は明るいです。