はじめに
こんにちは!Shungiku です。
今回は超よわよわだった当時の自分に向けて、「分かりやすい関数を書く方法」を説明したいと思います。
分かりやすい関数にする方法は様々ありますが、本稿では「型ヒント」に着目し、型ヒントのない関数をリファクタリングする形で説明を進めていきます。
モチベーション
ある日、自分が書いた過去のコードを改築している時、私は以下のような箇所に遭遇します。
users = load_users("/path/to/your/file/")
「あー、半年前くらいにこの関数を書いた気がするなぁ」
「"load_users"... たしかファイル名を引数に渡して、そのファイルに載ってるユーザーの一覧情報を返してくれる関数だったような...?」
「でもどんなデータが返ってくるか覚えてないぞ...実装を見に行くか」
def load_users(filepath):
users = []
# これ以降つらつらと処理が書かれていると想定。
# 例えば以下のような処理が書かれている。
# - filepath のファイルを読み込む
# - 一行ずつ読み込み、それを辞書型にマッピング -> user = { key: value, ... }
# - その辞書をリストに追加 -> users.append(user)
return users
読み始めて数分後...
「あーなんとなく思い出してきた...!たしか、ユーザーの名前とか年齢とかの情報を持つ辞書をリストで返す関数だったかな?」
「う〜ん、確証がないから print で確認してみるか」
users = load_users("/path/to/your/file/")
print(users)
# [
# {
# "name": "Ken",
# "age": 15,
# "address": "Tokyo"
# },
# {
# "name": "Taro",
# "age": 25,
# "address": "Kyoto"
# },
# ...
# ]
「あーこれこれ!思い出した。よし、じゃあこのusersに対して続きの処理を書いていくか」
めでたし、めでたし...???
何が問題だったか
先ほどの関数(load_users)の問題点は何だったでしょう?
それは「関数の仕様(入出力)がパッと分からない」ということです。
先程のエピソードでは以下のアクションによってようやく load_users の仕様を思い出すに至りました。
- 実装の詳細を読みに行く
-
printで確認
毎回こんなことをしていたのでは、せっかく関数に切り出している意味がありません。コードを改築する度に余計な思い出しコストがかかってしまいます。
関数の可読性を型ヒントで改善する
型ヒントのおさらい
型ヒント is 何? という方はこちらを開いてください
基本
まずは型ヒントの基本からです。
変数名の横に :型 の形式で型ヒントを付与することで、その変数がどんな型なのか明示することが出来ます。
price: int
price = 1000
# or
price: int = 1000
型ヒントがない場合、「price には整数しか格納したくない!」という意図で実装したとしても、その変数に文字列を代入したところで怒られることはありません。
price = 1000
price = "文字列だよ~ん"
しかし、型ヒントを付与することで、IDE(Vscodeなど)上でちゃんと怒られるようになります。

発展
リストや辞書の型ヒントも確認していきましょう。
まずはリストからです。
文字列を格納するリストとして、str_list変数に型ヒントを付与してみます。
str_list: list = ["a", "b", "c"]
実はこれだと不十分です。
リストの「要素の型」が明示されていないため、要素に整数値を突っ込んでもしまっても怒られません。
str_list: list = [1, 2, 3]
要素の型を指定するには list[要素の型] の形式で指定することが出来ます。
今回の例でいうと、要素の型はstr型にしたいので、list[str]とすれば要素に文字列以外(例えば整数値)を指定するとちゃんと怒られるようになります。

次に辞書ですが、dict[keyの型, valueの型] という形式で型ヒントを付与します。
user: dict[str, str] = {
"name": "Ken",
"address": "Tokyo"
}
ちなみに、key として複数の型が混在するようなケースもあるでしょう。
例えば以下のケース。
user = {
"name": "Ken",
"age": 26,
"address": "Tokyo"
}
この変数に dict[str, str] を付与するのは不適切です。なぜなら、ageという key の値は str型ではなくint型だからです。
このように「◯ または △」のように型を指定したい場合は、◯ | △ のように縦棒を使うことで指定ができます。
今回の例だと以下のように型ヒントを付与すると良いでしょう。
user: dict[str, str | int] = {
"name": "Ken",
"age": 26,
"address": "Tokyo"
}
型ヒントを付与して可読性をあげていく
それでは、冒頭の load_users を改善していきましょう。
引数はstr型であり、関数の返り値は list型です。
それらの型ヒントを関数に付与すると以下のようになります。
def load_users(filepath: str) -> list:
users = []
# これ以降つらつらと処理が書かれていると想定。
return users
続いて、返り値の型ヒントがlistだけだとその要素の型がパッと分からないため、それを改善していきます。
要素は以下のような辞書なので、dict[str, str|int] という型ヒントで表現できます。
{
"name": "Ken",
"age": 15,
"address": "Tokyo"
}
それを返り値の型ヒントに適用すると以下のような感じ。
def load_users(filepath: str) -> list[dict[str,str|int]]:
ここまですれば、関数の中身を読まずともこの関数の仕様は...
- 引数に
str型の値を渡す - 返り値として、
dict[str, str|int]の辞書を要素とするリストが得られる
ということが分かります。
しかし、これでは不十分です。問題なのは返り値の型ヒントです。
dict[str, str|int] を見たところで、"name", "age", "address" を key とする以下のような構造の辞書であることはイメージできません。
{
"name": "Ken",
"age": 15,
"address": "Tokyo"
}
dict[str, str|int]が意味するのは、あくまでも「key がstr型であること」と「value がstr型またはint型であること」だけです。
この型ヒントの制約を満たすデータ構造はいくらでも存在します。
例えば以下のようなものだってOKです。
{
"date": "2020/11/11",
"score": 80,
}
現状のままだと型ヒントとしての制約がユルユル過ぎるのです。
クラスでさらに可読性を上げる
個々のユーザーを辞書ではなく「クラス」を使って表現するようにしてみましょう。
まず、関数とは別に User クラスを定義します。
class User:
def __init__(self, name: str, age: int, address: str):
self.name = name
self.age = age
self.address = address
load_users 関数はこのUserクラス(のインスタンス)を要素とするリストを返すことになるので、型ヒントは以下のようになります。
def load_users(filepath: str) -> list[User]:
こうしてあげれば、関数の中身を読まずとも返り値を容易に把握することが可能です。
実際にコードリーディングする際には以下のような流れで把握することになると思います。
- 「ふむふむ、
load_usersという関数はUser型のlistを返すのか」 - 「
User型ってなんだろう?型定義へ移動して確認しよう(※ IDE上で右クリックすれば型定義への移動が選択できます)」 - 「なるほど!"name" ,"age", "address"を持つデータなのね〜」
また、ここまでしてあげると、load_users を利用する側のコーディング体験も格段に良くなります!
.(ドット)を入力するだけで、"name" や "age" などが補完されるようになるのです。
これは嬉しい!
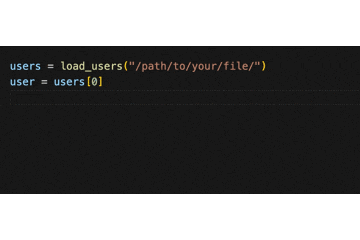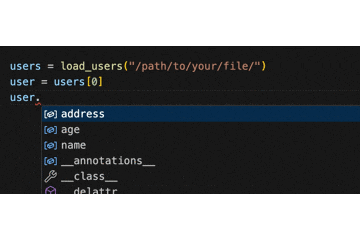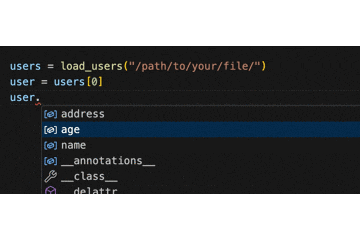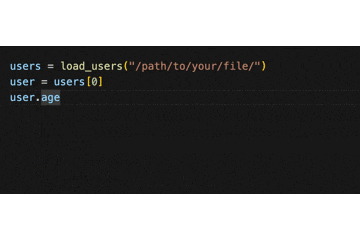
念の為補足ですが、辞書からクラスに変更するにあたって、型ヒントの箇所をただ修正するだけで load_users が動作する訳ではありません。
以下はあくまでも擬似コードですが、辞書を使っていた箇所をクラスに変更してあげる必要があります。
def load_users(filepath: str) -> list[User]:
users = []
# これ以降つらつらと処理が書かれていると想定。
# 以下は擬似コード。
# for line in lines:
- # user = {
- # "name": line[0],
- # "age": line[1],
- # "address": line[2]
- # }
+ # user = User(line[0],line(1),line(2))
return users
どうしても辞書が良ければ TypedDict を使う
クラスではなく、あくまでも辞書を使いたいんだ!という場合は TypedDict という選択肢があります。
User クラスを定義したときと似ていますが、辞書の型ヒント用のクラスを以下のように定義します。
from typing import TypedDict
class User(TypedDict):
name: str
age: int
address: str
load_users に付与する型ヒントはクラスの時と同様です。
def load_users(filepath: str) -> list[User]:
TypedDictを使っても、classの時と同様に高い開発体験を享受することができます。
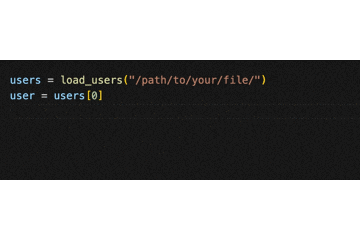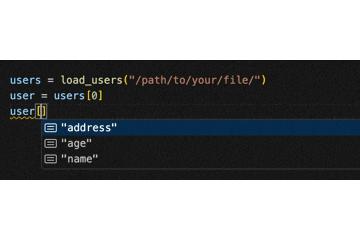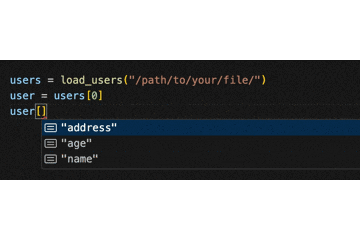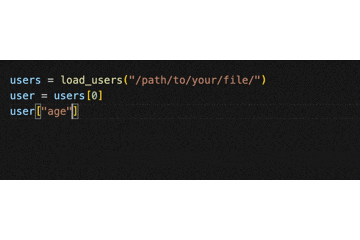
[(ブラケット)を入力するだけで、以下のように補完されます。
(返り値の要素はクラスではなくあくまでも辞書なので、.(ドット)ではなく []でアクセスする)
まとめ
分かりやすい関数というのは、以下の3要素が明示され、それを見ただけで関数の挙動がおおよそ予測できるものです。
- 関数名
- 引数名とその型
- 返り値の型
Pythonは型をあまり意識せずとも書ける言語であるため、最初はいちいち型ヒントを付与するのが面倒だと感じるでしょう。
しかし、同じプロダクトを開発しているチームメンバーのため、もしくは数カ月後の自分自身ためにも、型ヒントを付与して書く習慣をつけることは重要です。
特に本稿の例のように、関数の入出力には必ず型ヒントを付与したほうが良いでしょう。
そうすることで、いちいち実装の詳細を読まずともその関数の挙動を容易に予測することが出来るようになります。
IDEでの開発体験が上がることも大きなメリットですね。