はじめに
こんにちは!
皆さん、Azureでサービスを長期運用している場合、各種リソースから出力される様々なログはどのように管理されてますか?
「とりあえず長期保存目的でストレージに保存してるけど、解析や障害対応のたびに対象のファイルを探して、ダウンロードして、手元で目視あるいは手製のスクリプト、はたまた別のサービスで解析している」ということはないでしょうか。
そんな皆さんに朗報です! Azure Synapse Analytics を使えば、かなりの手間を省きストレージに眠っているログたちをスムーズかつ※ストレスフリーに解析できます!
※個人的見解です
本記事ではいくつもあるAzureSynapseAnalyticsの機能のうち、スポットでの解析や障害対応にぴったりな完全従量課金のServerlessSQLPoolについて紹介します。
本記事のゴール
ストレージに貯めたCSV,その他区切り文字ファイル、JSONファイルをSQL(※)でクエリできるようになる
※正確にはT-SQLですが、SQL関数の大部分を利用できます。
「基本はわかっているから、各ファイルフォーマットごとのクエリの書き方が知りたい!」という方はファイル形式ごとのクエリの書き方からお読みいただけると良いと思います。
Azure Synapse Analytics とは
Azureが提供するデータ分析基盤でデータの収集・蓄積・解析を1つにまとめた分析プラットフォームです。
Azure Synapse Analytics は、データ統合、エンタープライズ データ ウェアハウス、ビッグ データ分析が一つになった制限のない分析サービスです。
Serverless SQL Poolとは
AzureSynapseAnalyticsが持つ機能の1つで、AzureDataLake(ストレージ)に保存されたファイルに対してクエリを実行できるサーバーレスリソースです。AWSでいうAthenaに相当するサービスになります。
サーバーレス SQL プールは、大規模なデータとコンピューティング機能を対象として構築された分散データ処理システムです。 サーバーレス SQL プールでは、ワークロードに応じて数秒から数分でビッグ データを分析することができます。 クエリ実行のフォールトトレランスが組み込まれているため、大規模なデータ セットを対象とする実行時間の長いクエリの場合でも、高い信頼性と成功率が実現します。
サーバーレス SQL プール - Azure Synapse Analytics
AWSとAzureリソースの対応表
AWS サービスと Azure サービスの比較 - Azure Architecture Center
対応ファイル形式
- CSV
- 任意の区切り文字
- JSON
- Parquet
- Delta Lake
本記事では以下を扱います
- CSV
- tab区切り
- スペース区切り
- JSON
-
JSON
{"a":1,"b":2} -
複数行JSON
{"a":1,"b":2} {"a":1,"b":3} {"a":3,"b":4} {"a":1,"b":5} -
JSON配列
[ {"a":1,"b":2} {"a":1,"b":3} {"a":3,"b":4} {"a":1,"b":5} ]
-
料金体系
処理したデータ量に応じて$6/TBの課金が発生します。
2022/12/17現在は、毎月1TBまでの無料枠が付いてきます。(2023/6/30まで)
使い方
セットアップ
リソース作成までの手順は言葉よりキャプチャが良いと思ったのですが少々長くなるので記事末尾に掲載しています。これからセットアップされる方はこちらをご覧ください。
とりあえず適当なCSVファイルにクエリを投げてみる
ここでは作成後、適当なCSVファイルを読み込んでクエリを投げる方法を紹介します。
まずはAzureSynapseStudioを開き、左のサイドメニューからDataを選びます。
DataページでLinkedタブを開くと、リソース作成時に作成or紐付けをしたDataLakeStorageが表示されると思います。Uploadを選択し、適当なCSVファイルをアップロードします。
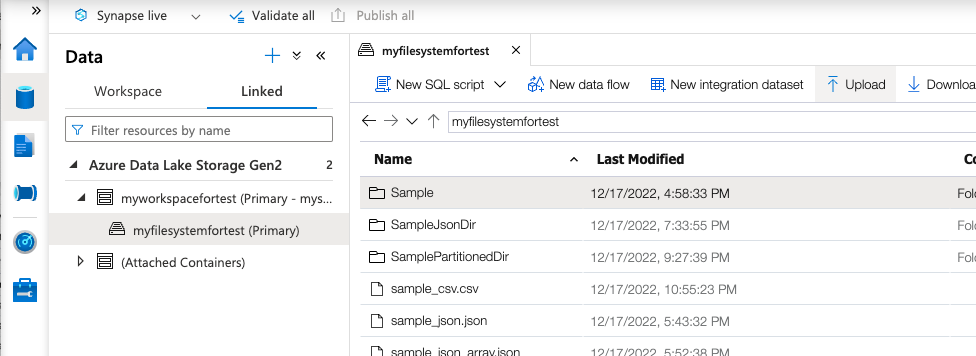
アップロードが完了したら右クリックでファイルを選択し、Select TOP 100 rows を選択します
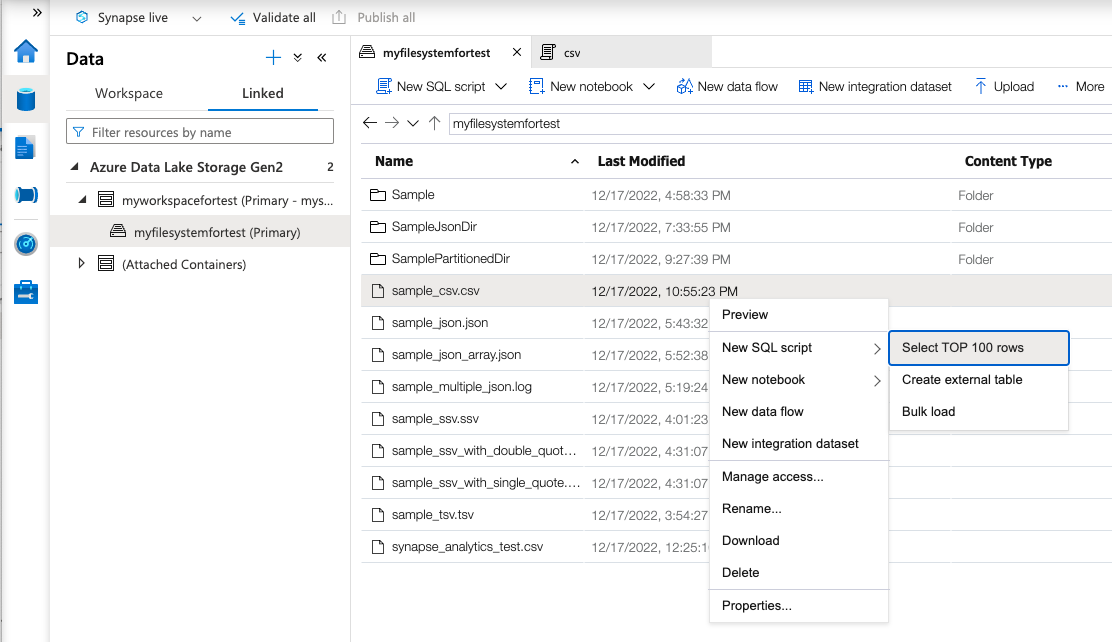
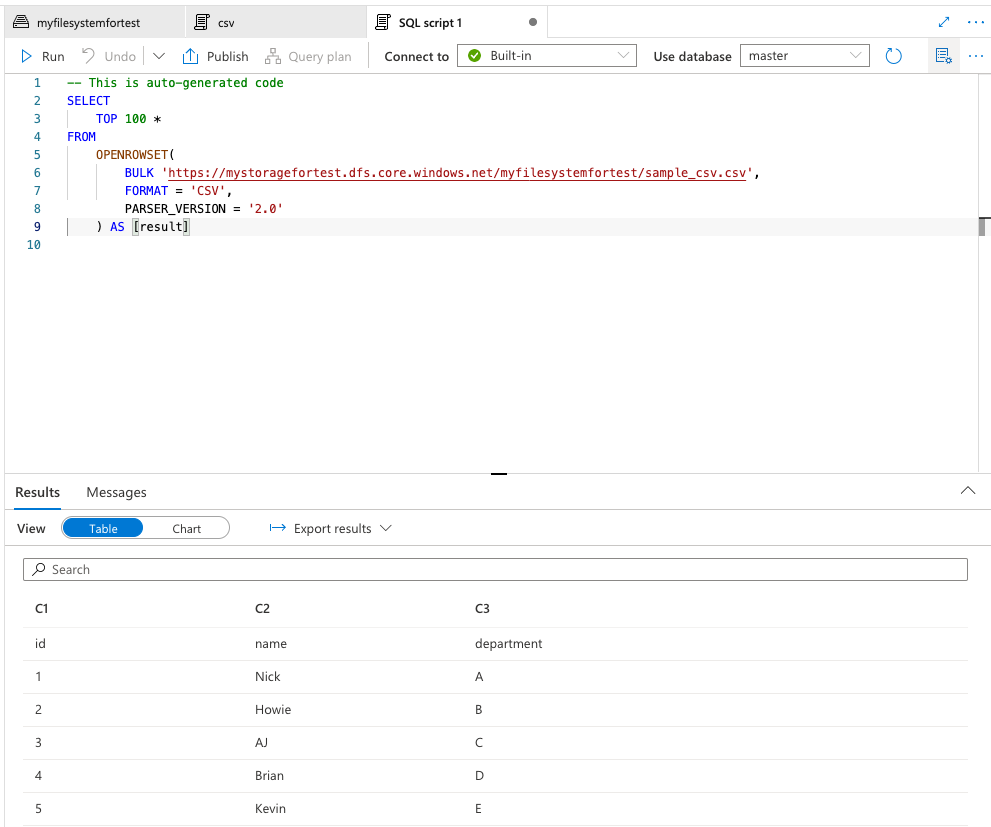
すると以下のように自動でクエリが作成され、Runをクリックすると自分が私たcsvの中身が取得できるはずです。
ファイル形式ごとのクエリの書き方
カンマ区切り(CSV)
-
設定値
FORMATをCSVにする -
自動生成可能か
可能。
CSV同様にファイルを右クリックしてSelect TOP 100 rowsを選択するだけで自動生成可能 -
クエリ
SELECT TOP 100 * FROM OPENROWSET( BULK 'https://xxxx/myfilesystemfortest/sample_csv.csv', FORMAT = 'CSV', PARSER_VERSION = '2.0' ) AS [result]
タブ区切り(TSV)
-
設定値
FORMATはCSVのまま、FIELDTERMINATORに’\t’を指定 -
自動生成可能か
可能。
CSV同様にファイルを右クリックしてSelect TOP 100 rowsを選択するだけで自動生成可能 -
クエリ
SELECT TOP 100 * FROM OPENROWSET( BULK 'https://xxxx/myfilesystemfortest/sample_tsv.tsv', FORMAT = 'CSV', PARSER_VERSION = '2.0', FIELDTERMINATOR ='\t' ) AS [result]
スペース区切り(SSV)
-
設定値
FORMATはCSVのまま、FIELDTERMINATORに’ ’(半角スペース)を指定 -
自動生成可能か
不可。 -
クエリ
SELECT TOP 100 * FROM OPENROWSET( BULK 'https://xxxx/myfilesystemfortest/sample_ssv.ssv', FORMAT = 'CSV', FIELDTERMINATOR =' ', PARSER_VERSION = '2.0' ) AS [result]
スペース区切りの中に引用符が含まれる場合
- 引用符がダブルクオートの場合
デフォルトのままでOK - 引用符がダブルクオート以外の場合
-
入力例
id name department 1 'Nick Carter' A 2 Howie B 3 AJ C 4 Brian D 5 Kevin E指定しない場合、以下のように列がずれてしまいます。
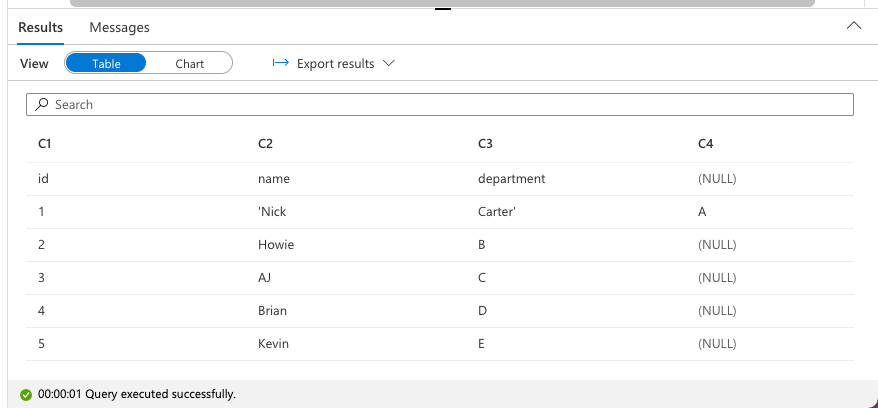
-
設定値
上記を回避するためには、FIELDQUOTEに引用符を指定します。シングルクオートの場合はエスケープの必要あるので’’としています。 -
クエリ
SELECT TOP 100 * FROM OPENROWSET( BULK 'https://xxxx/myfilesystemfortest/sample_ssv_with_single_quote.ssv', FORMAT = 'CSV', FIELDTERMINATOR =' ', FIELDQUOTE='''', PARSER_VERSION = '2.0' ) AS [result] -
出力
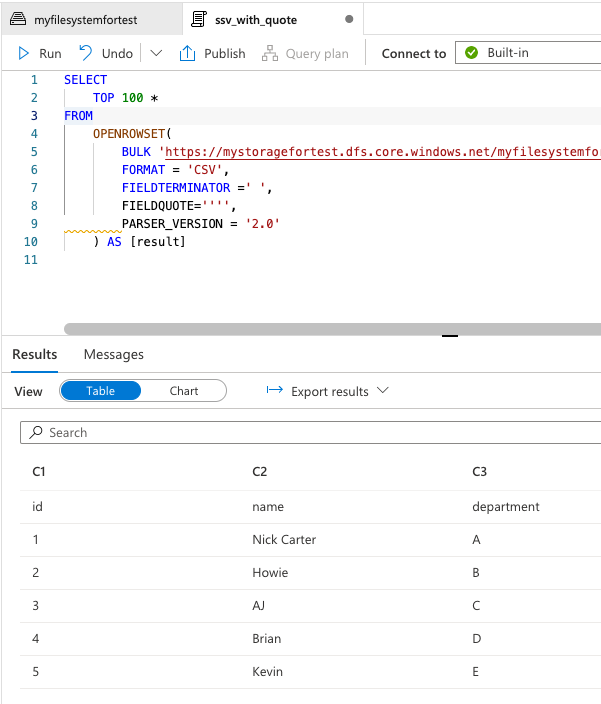
-
JSON
json拡張子を持つファイルはCSV同様にSelect TOP 100 rows を選択することで雛形を自動生成することはできますが、自動生成されたファイルは1カラムに全てのキー・バリューを含むため、クエリには適した形ではありません。このセクションではこれをキーをカラムとしたテーブルとして取り出す方法を紹介します。
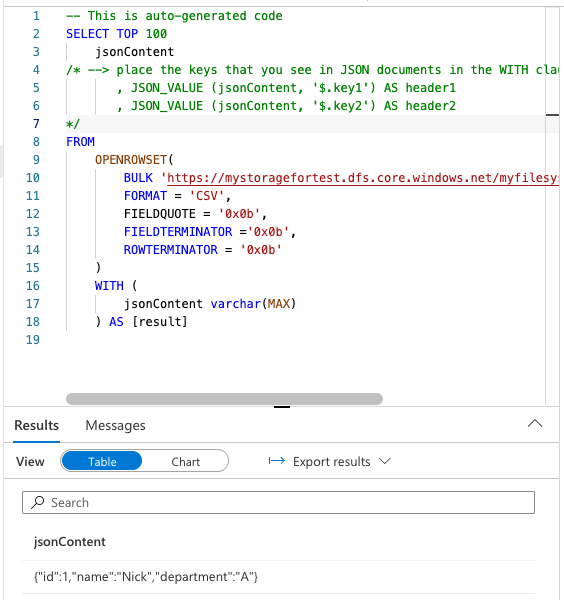
目指す出力
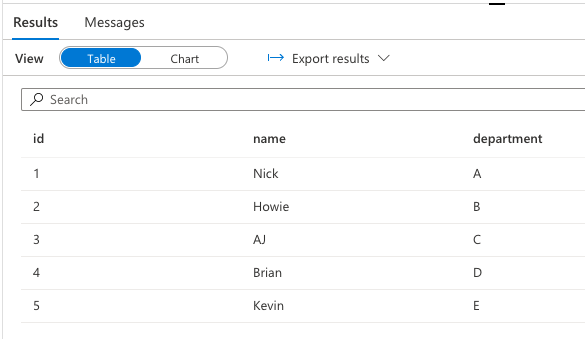
参考
サーバーレス SQL プールを使用して JSON ファイルに対してクエリを実行する - Azure Synapse Analytics
上記の出力を得るための各フォーマットでのクエリの書き方
-
JSONあるいは複数行のJSONを含むファイル
-
入力例
JSON{"id":1,"name":"Nick","department":"A"}複数行JSON
{"id":1,"name":"Nick","department":"A"} {"id":2,"name":"Howie","department":"B"} {"id":3,"name":"AJ","department":"C"} {"id":4,"name":"Brian","department":"D"} {"id":5,"name":"Kevin","department":"E"} -
設定値
FIELDQUOTEとFIELDTERMINATORに’0x0b’を設定します。 -
クエリ
select id, name, department from openrowset( BULK 'https://xxxx/myfilesystemfortest/sample_json.json', FORMAT = 'CSV', FIELDQUOTE = '0x0b', FIELDTERMINATOR ='0x0b' ) with (jsonContent nvarchar(max)) AS [result] cross apply openjson (jsonContent, '$') with( id VARCHAR(30) '$.id', name VARCHAR(30) '$.name', department VARCHAR(30) '$.department' )
-
-
JSON配列
-
入力例
[ {"id":1,"name":"Nick","department":"A"}, {"id":2,"name":"Howie","department":"B"}, {"id":3,"name":"AJ","department":"C"}, {"id":4,"name":"Brian","department":"D"}, {"id":5,"name":"Kevin","department":"E"} ] -
設定値
FIELDQUOTEとFIELDTERMINATORに加え、ROWTERMINATORに’0x0b’を設定します。 -
クエリ
select id, name, department from openrowset( BULK 'https://xxxx/myfilesystemfortest/sample_json_array.json', FORMAT = 'CSV', FIELDQUOTE = '0x0b', FIELDTERMINATOR ='0x0b', ROWTERMINATOR = '0x0b' ) with (jsonContent nvarchar(max)) AS [result] cross apply openjson (jsonContent, '$') with( id VARCHAR(30) '$.id', name VARCHAR(30) '$.name', department VARCHAR(30) '$.department' )
-
複数ファイルを取り込む方法
*を利用することで可能です。
例. yyyyディレクトリ配下の全てのcsvファイルをクエリ対象とする場合
FIRST_ROWは、各ファイルを何行目から読み込むかを指定するものです。
出力結果に複数のヘッダーが含まれるのは望ましくないのでこのようにしてます。
クエリ
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK 'https://xxxxxxxxxx/yyyy/*.csv',
FORMAT = 'CSV',
FIRST_ROW = 2,
PARSER_VERSION = '2.0'
) AS [result]
出力
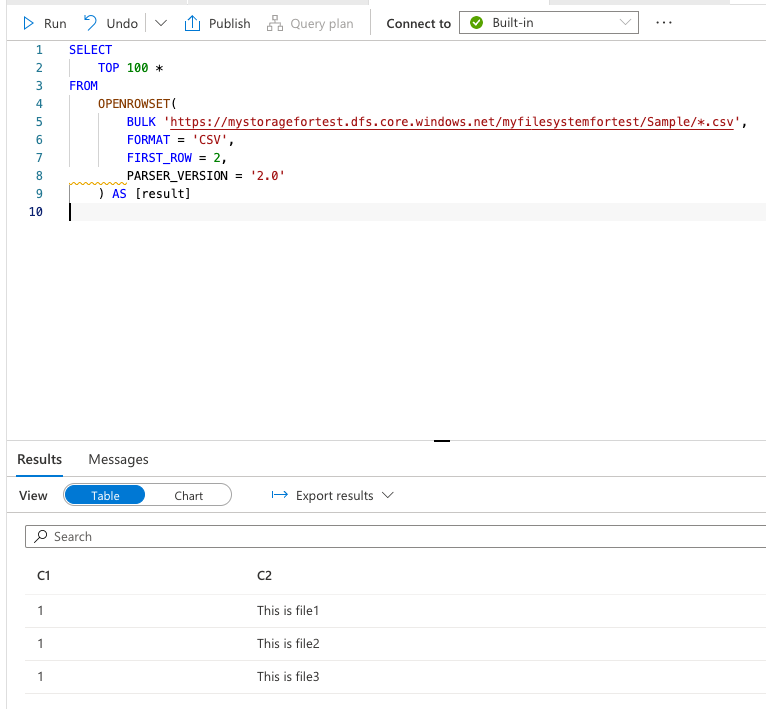
サーバーレス SQL プールを使用してデータ ストレージにクエリを実行する - Azure Synapse Analytics
外部テーブルを利用する
ここまでで1つまた複数のファイルに対してクエリをかける方法を紹介しましたが、クエリの中にopenrowsetの長い定義文が含まれるのは少し冗長な感じがしますよね。そんな時は外部テーブルを定義すると以下のようにより普段使うSQLに近い形で解析を行うことができます。
select * from '定義した外部テーブル名';
ただし、サーバーレスSQLプールで外部テーブルを定義できるのはCSV、Parquet、Delta Lakeファイルのみとなります。従って、今回紹介したJSONやスペース区切りのファイルをクエリする際のopenrowsetの記述を再利用するためにはVIEWを作成する必要があります。こちらは次のセクションで説明します。
サーバーレス SQL プール: 区切り形式 (CSV)、Parquet、Delta Lake
専用 SQL プール: Parquet (プレビュー)
Synapse SQL で外部テーブルを使用する - Azure Synapse Analytics
-
CSVでの外部テーブルの定義の仕方
-
対象のcsvファイルを複数含んだディレクトリを作成
例- Sample - file1.csv //ヘッダー除いた中身:1,This is file1 - file2.csv //ヘッダー除いた中身:2,This is file2 - file3.csv //ヘッダー除いた中身:3,This is file3 -
ディレクトリを右クリックし、
Create external tableを選択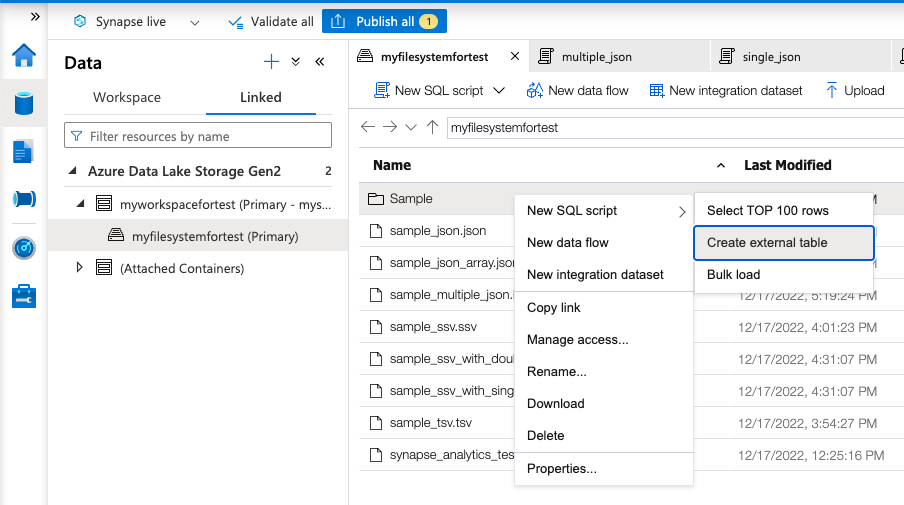
-
次に各種設定項目が出てくるので本来はここでFirst rowに2を設定したいのですが、2022/12/17現在はここで設定しても生成されるSQLには反映されないので後で手動で修正します。
Continueを選択し、次の画面に行きます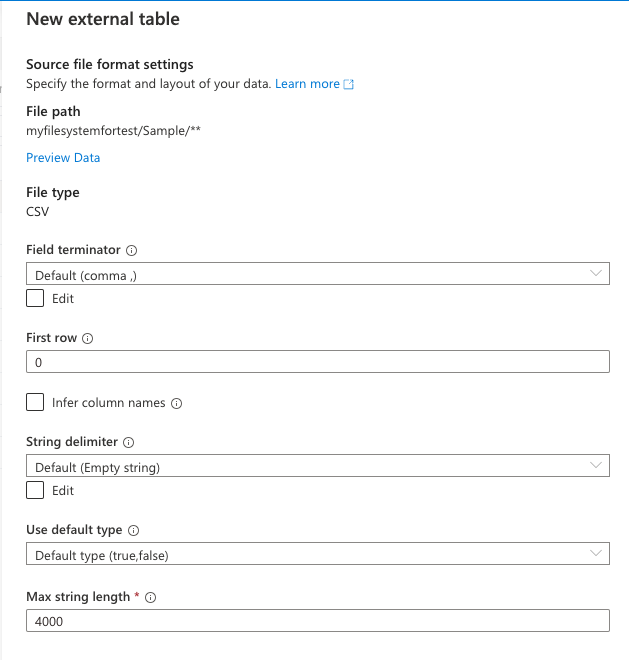
-
Using SQL script を選択
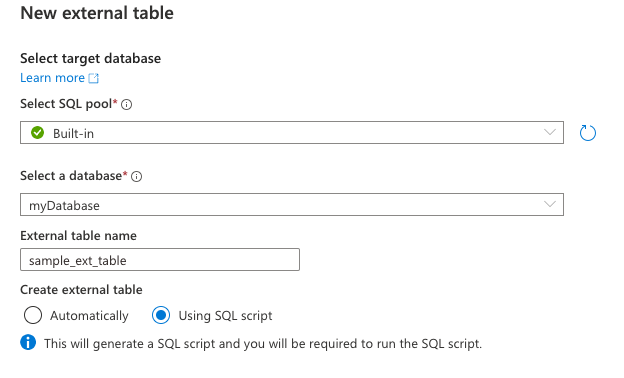
-
クエリを実行(first rowが設定されていない時は、ここで手動で入力)
次のような雛形が出力されると思います。IF NOT EXISTS (SELECT * FROM sys.external_file_formats WHERE name = 'SynapseDelimitedTextFormat') CREATE EXTERNAL FILE FORMAT [SynapseDelimitedTextFormat] WITH ( FORMAT_TYPE = DELIMITEDTEXT , FORMAT_OPTIONS ( FIELD_TERMINATOR = ',', USE_TYPE_DEFAULT = FALSE )) GO IF NOT EXISTS (SELECT * FROM sys.external_data_sources WHERE name = 'myfilesystemfortest_mystoragefortest_dfs_core_windows_net') CREATE EXTERNAL DATA SOURCE [myfilesystemfortest_mystoragefortest_dfs_core_windows_net] WITH ( LOCATION = 'abfss://myfilesystemfortest@mystoragefortest.dfs.core.windows.net' ) GO CREATE EXTERNAL TABLE sample_ext_table ( [C1] nvarchar(4000), [C2] nvarchar(4000) ) WITH ( LOCATION = 'Sample/**', DATA_SOURCE = [myfilesystemfortest_mystoragefortest_dfs_core_windows_net], FILE_FORMAT = [SynapseDelimitedTextFormat] ) GO SELECT TOP 100 * FROM dbo.sample_ext_table GO上記に、
FIRST_ROWの設定の追加とカラム名の変更を加えます(変更部分のみ抜粋)//FIRST_ROW = 2 を追加 IF NOT EXISTS (SELECT * FROM sys.external_file_formats WHERE name = 'SynapseDelimitedTextFormat') CREATE EXTERNAL FILE FORMAT [SynapseDelimitedTextFormat] WITH ( FORMAT_TYPE = DELIMITEDTEXT , FORMAT_OPTIONS ( FIELD_TERMINATOR = ',', FIRST_ROW = 2, USE_TYPE_DEFAULT = FALSE )) //カラム名を実際のファイルのヘッダーに合わせて修正します。 CREATE EXTERNAL TABLE sample_ext_table ( id nvarchar(4000), message nvarchar(4000) ) WITH ( LOCATION = 'Sample/**', DATA_SOURCE = [myfilesystemfortest_mystoragefortest_dfs_core_windows_net], FILE_FORMAT = [SynapseDelimitedTextFormat] ) -
実行します
スクリプト末尾に以下のようなセレクト文があるので、うまくいけば結果が表示されるはずです。SELECT TOP 100 * FROM "外部テーブル名"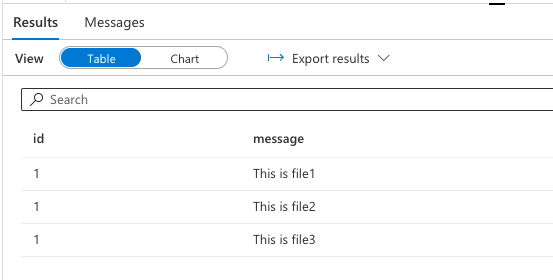
また、Dataページで
External tablesとExternal data sources、External file formatsが追加されるのが確認できるはずです。表示されない場合はデータベース右クリックでRefreshを行ってみてください。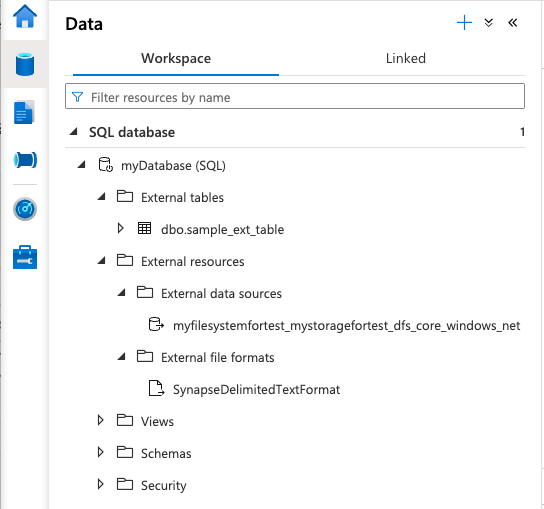
これで以降はスクリプト内でopenrowsetを都度書かず、外部テーブル名を使ってクエリを行うことができるようになります!
-
-
外部テーブルの削除方法
作成した外部テーブルを削除する際は以下のコマンドで削除します。
※DROP TABLEではなく、DROP EXTERNAL TABLEであることに注意-- UI上でデータベースを選択している場合。 DROP EXTERNAL TABLE [スキーマ].[外部テーブル名] -- データベースを選択してない場合はこちら DROP EXTERNAL TABLE [データベース名].[スキーマ].[外部テーブル名]DROP EXTERNAL TABLE (Transact-SQL) - SQL Server
外部テーブルを作り直す際は、
External data sources、External file formatsも消しておかないと変更が反映されないので以下で削除するようにしてください。自分はこれに気づかず時間を溶かしました。。DROP EXTERNAL FILE FORMAT 外部ファイルフォーマット名; DROP EXTERNAL DATA SOURCE 外部データソース名;
Viewの作成
前セクションでお伝えしたようにJSONやCSV以外の区切り文字ファイルは外部テーブルを作成することができません。その代わりビューを作成することができます。
以下では、JSONファイルを例にとってVIEWの作成方法を説明します。
-
作成方法
-
(任意)対象のjsonファイルを含んだ適当なディレクトリを作成します。
単体のファイルに対してviewを作成してもいいですが、テーブルのように扱いたい場合は複数ファイルを対象にクエリしたい場合かと思いますので、その場合はこの手順を行ってください。
例SampleJsonDir - file1.json//中身:{"id":1,"name":"Nick","department":"A"} - file2.json//中身:{"id":2,"name":"Howie","department":"B"} - file3.json//中身:{"id":3,"name":"AJ","department":"C"} -
クエリ対象のファイルパスを持つselect文を作成
select id, name, department from openrowset( BULK 'https://xxxx/myfilesystemfortest/SampleJsonDir/*.json', FORMAT = 'CSV', FIELDQUOTE = '0x0b', FIELDTERMINATOR ='0x0b' ) with (jsonContent nvarchar(max)) AS [result] cross apply openjson (jsonContent, '$') with( id VARCHAR(30) '$.id', name VARCHAR(30) '$.name', department VARCHAR(30) '$.department' -
上記のクエリにVIEW作成の構文を付け足す。
CREATE VIEW sample_json_view AS select id, name, department from openrowset( BULK 'https://xxxx/myfilesystemfortest/SampleJsonDir/*.json', FORMAT = 'CSV', FIELDQUOTE = '0x0b', FIELDTERMINATOR ='0x0b' ) with (jsonContent nvarchar(max)) AS [result] cross apply openjson (jsonContent, '$') with( id VARCHAR(30) '$.id', name VARCHAR(30) '$.name', department VARCHAR(30) '$.department' ) -
実行
DataページにViewが追加されるはずです。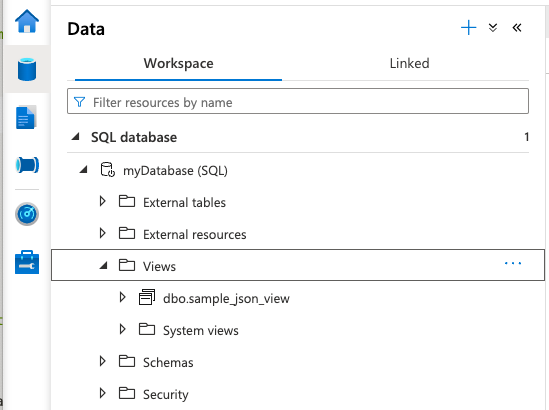
-
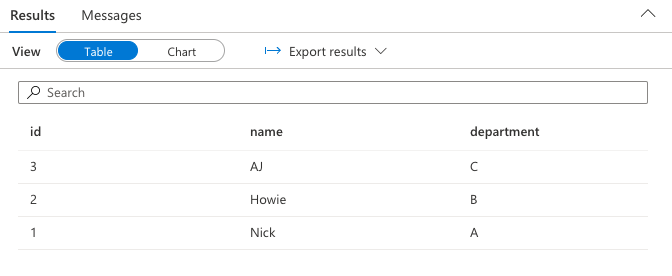
VIEWを呼び出す
select * from dbo.sample_json_view;以下のような出力が得られれば成功です!
-
-
削除方法
外部テーブルの場合と違いDROPするのはVIEW1つで大丈夫です。DROP VIEW IF EXISTS [スキーマ名].[VIEW名];
パーティションの利用
各種リソースにより吐かれるログがyear=yyyy,month=MM,day=ddなどにディレクトリ分けされて出力されている場合、ServerlessSQLプールではパーティション分割を利用することができます。
実運用では大量のデータがストレージに保存されていることもあり、パーティション分割を用いないと処理時間と料金の両方が膨れ上がることになるので利用必須になると思います。
ただし、外部テーブルではパーティション分割を利用することができないため、パーティション”ビュー”を作成する必要があります。
フォルダー パーティションの除外は、Synapse Spark プールから同期されるネイティブ外部テーブルで使用できます。 データ セットをパーティション分割し、作成した外部テーブルでパーティションの除外を活用する場合は、外部テーブルではなくパーティション ビューを使用します。
Synapse SQL で外部テーブルを使用する - Azure Synapse Analytics
パーティションビューは、本記事で作成したCSV,その他区切り文字ファイル、JSONの全てのファイル形式で作成することが可能です。
- 作成方法
-
ファイルパスに次のようにワイルドカードを入れます
your_directory/year=*/month=*/day=*/*.csv今回の例では以下のようなディレクトリ構成、ファイルの中身を想定しています
SamplePartitionedDir - year=2022 - month=1 -day=1 - file1.json//中身:{"id":1,"message":"It is 1/1/2022"} -day=2 - file2.json//中身:{"id":1,"message":"It is 2/1/2022"} - month=2 -
VIEWを作るスクリプトでSELECT対象にワイルドカードで表現した箇所をyear,monthなど名前付きで定義します。
各パラメータはopenrowsetの結果から,filepath関数と1から始まるインデックスを使って取り出すことができます。CREATE VIEW sample_partitioned_json_view AS select id, message, result.filepath(1) AS year, result.filepath(2) AS month, result.filepath(3) AS day from openrowset( BULK 'https://xxxx/myfilesystemfortest/SamplePartitionedDir/year=*/month=*/day=*/*.json', FORMAT = 'CSV', FIELDQUOTE = '0x0b', FIELDTERMINATOR ='0x0b' ) with (jsonContent nvarchar(max)) AS [result] cross apply openjson (jsonContent, '$') with( id VARCHAR(30) '$.id', message VARCHAR(30) '$.message' ) -
ビューに対してクエリを実行
-
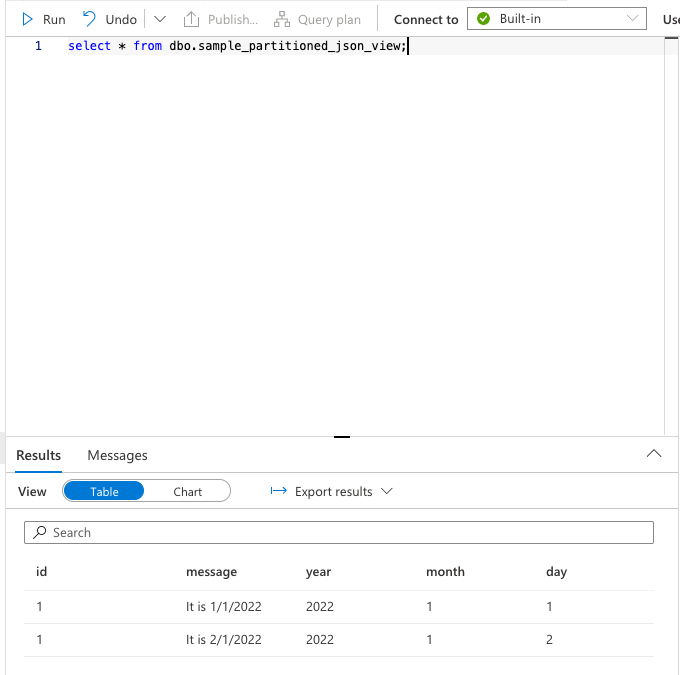
whereを利用しない場合
select * from dbo.sample_partitioned_json_view;全てが返ります
-
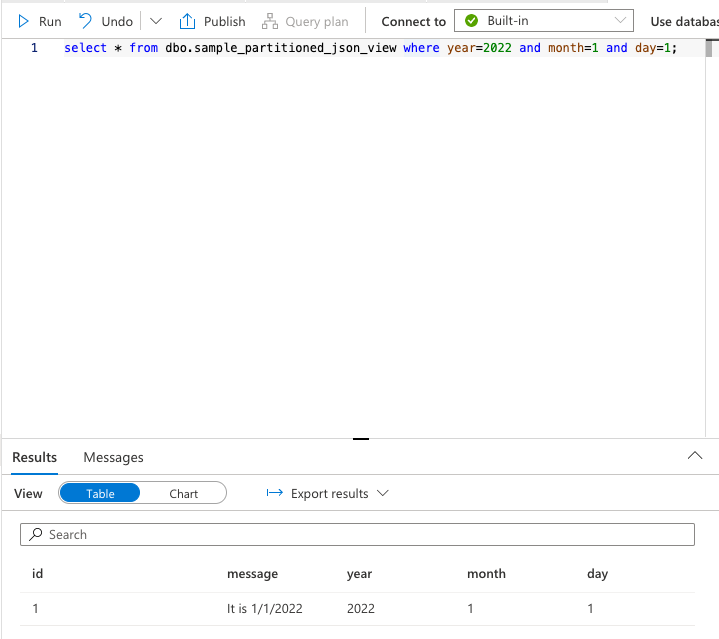
whereで年月日を絞る場合
select * from dbo.sample_partitioned_json_view where year=2022 and month=1 and day=1;指定した年月日のものだけが検索対象となり条件に当てはまるもののみが表示されます。
-
-
現在のコストの確認方法
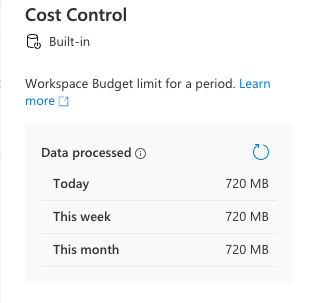
サイドメニューのManage項目から利用しているプールのお札アイコンをクリックすると現在の処理されたデータ量が分かります。これを1TBで割ったものに$6をかけたものが料金です。(2022/12/17現在の料金)
クリック箇所

処理済みデータ量
コスト節約術
-
パーティション分割ビューを使って不必要なデータを検索対象に含めない
ServerlessSQLPoolでは処理データ量に対して課金が行われるので、あらかじめ検索範囲が絞れるのであればなるべく絞り、最適な量のデータをクエリするのがおすすめです。 -
毎月の利用を無料枠内に収める
2022/12/17現在は、2023/6/30まで1月あたり1TBまでのクエリが無料になるので、データの処理量をこれ以下に抑えれば無料で利用することができます。2023 年 6 月 30 日まで 1 か月あたり 1 TB の無料クエリ
-
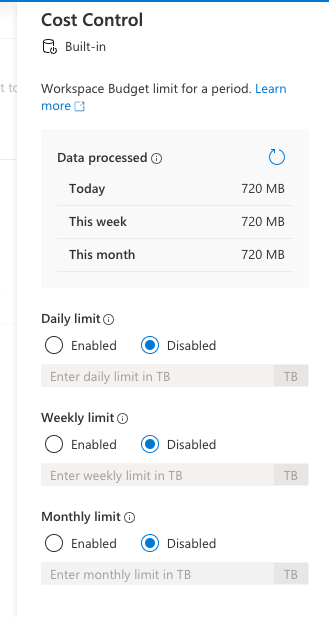
予算を設定する
処理されたデータ量を確認できるパネルと同じパネルで1TB単位で予算を設定することができます。
予算を超えた状態では新しいクエリを実行することはできなくなるので、予算を超過したことを知らずに使いすぎることを防ぐことができます。クエリの実行中に制限を超えた場合、クエリは終了されません。
制限を超えた場合、新しいクエリは拒否され、エラー メッセージには、期間に関する詳細情報、その期間に定義された制限、およびその期間の処理済みデータが含まれています。
トラブルシュート
- 設定値が正しいはずなのにファイルが存在しないと怒られる。
実行ユーザーにファイル参照権限が不足している可能性があります。
以下を参考に権限を付与してみてください. 自分の場合はStorageBlobReaderを付与するとうまく行ったりしました。
ID を使用してデータにアクセスするには、Storage Blob データの所有者/共同作成者/閲覧者のロールを持っている必要があります。 または、細かい設定が可能な ACL 規則を指定して、ファイルやフォルダーにアクセスすることもできます。
サーバーレス SQL プールのストレージ アカウント アクセスを制御する - Azure Synapse Analytics
- Contributorロールを持ってるのにファイルが存在しないと怒られる
自分もよくわかってないのですが、この場合も上記の権限を明示的に付与すると解決するので試してみてください
終わりに
いかがでしたでしょうか。
自分と同じように障害対応のたびにいくつものログファイルをダウンロードして解析する苦しみを味わっている誰かの役に立てれば幸いです。
参考:セットアップ方法
-
Marketplaceで Azure Synapse Analyticsをみつけて作成します。
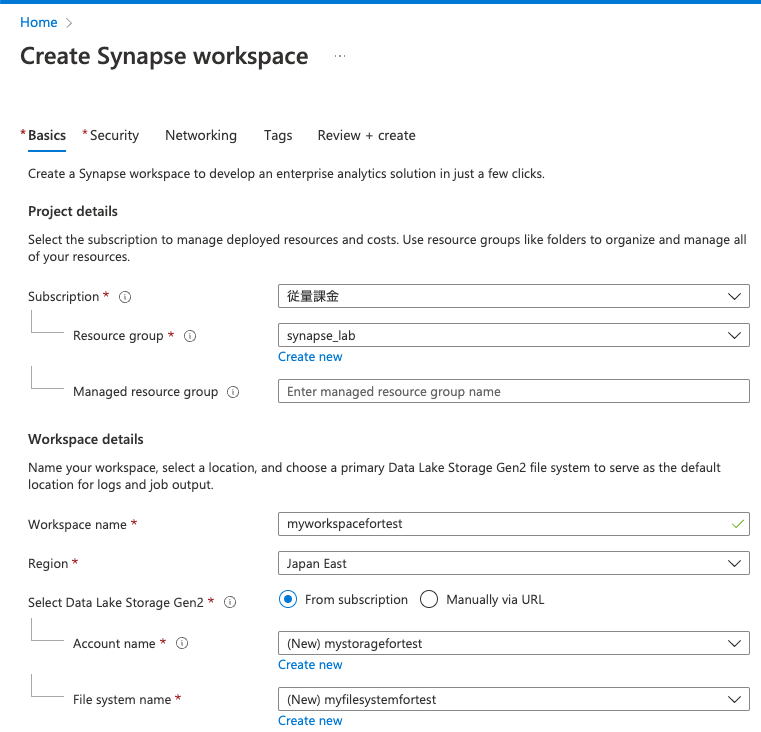
もし下記のようなエラーが出た場合は、Microsoft.SynapseリソースプロバイダをRegisterしてください

ResourceProviderの一覧画面
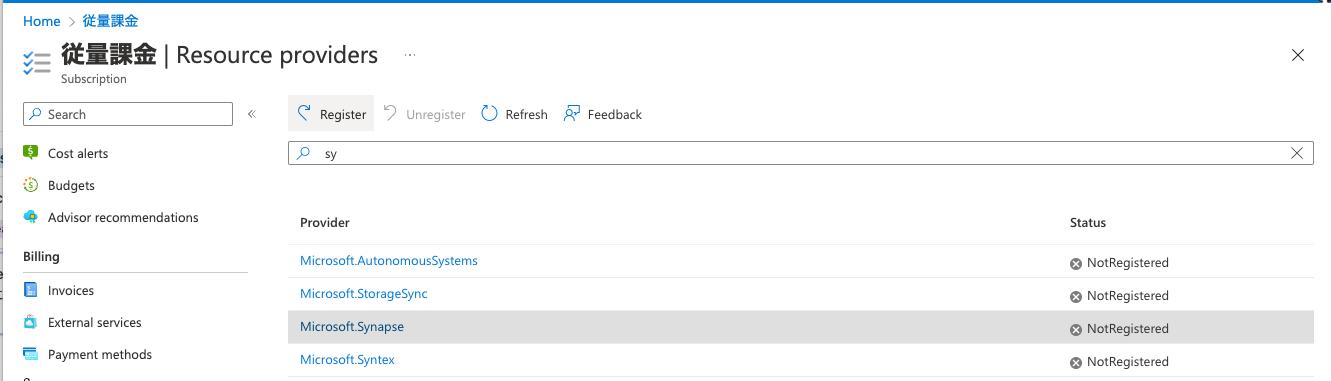
-
セキュリティタブを入力
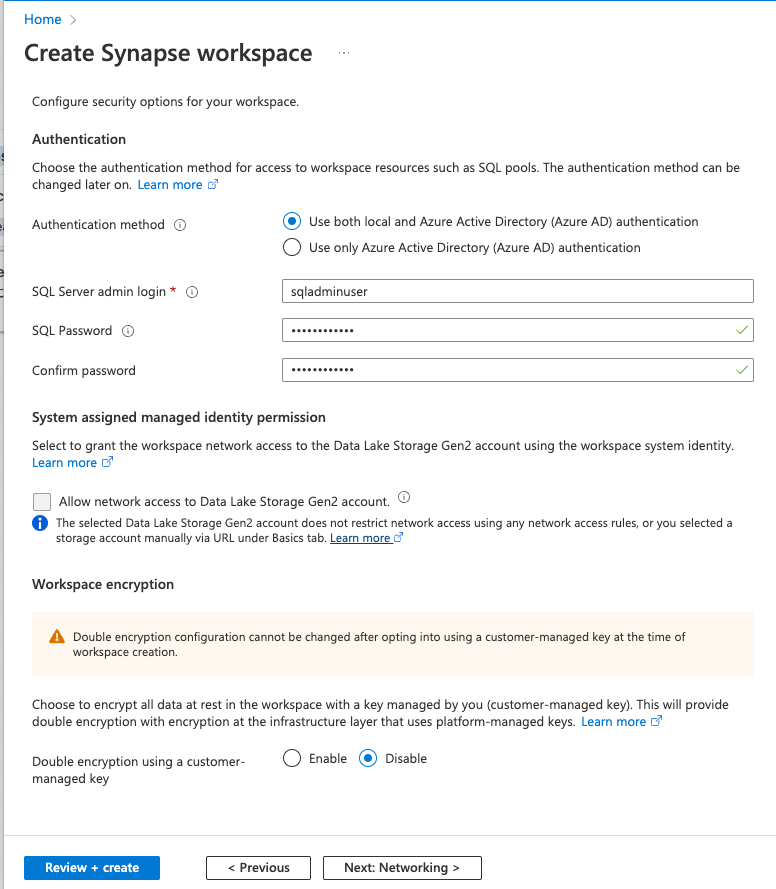
-
ネットワーク(デフォルト)
必要に応じてVnetを使ってください。
-
Review+ create をクリック。 以上です。