はじめに
Python 3.7以降で登場したdataclassesモジュールは、シンプルなデータ構造を扱う際に非常に強力なツールです。
この記事ではdataclassesモジュールを活用することでPythonコードをより読みやすく、保守しやすいものにするためのデータクラスの使い方や活用のメリットなどを解説します。
dataclassesはPython 3.7以降標準ライブラリで使用できるため、追加のインストールは不要です。
dataclasses.dataclassを活用するメリット
1. dataclassでデータを扱うことでコードの簡潔さと可読性の向上
dataclassのデコレーターを付けたclassはデフォルトで__init__()、__repr__() 、__eq__() メソッドを定義してくれます。
そのため簡潔にオブジェクトの型を定義でき、printするときやアサーションするときなどに便利です。
以下はdataclassを使用しない場合と使用した場合を比べてみました。
dataclassを使用しない場合
オブジェクトの内容を出力したり、同じ内容のオブジェクトをassertする場合は別途__init__()や__repr__()、__eq__()メソッドを定義する必要があります。
class Person:
def __init__(self, name: str, age: int):
self.name = name
self.age = age
p1 = Person(name='佐藤', age=30)
p2 = Person(name='佐藤', age=30)
print(p1) # => <__main__.Person object at 0x1068d0f10>のようにメモリアドレスが表示される
assert p1 == p2 # => 違うオブジェクトとしてAssertionErrorが発生する
dataclassを使用した場合
__init__()が不要になり、__repr__()と__eq__()が定義されていることで、オブジェクトの内容が綺麗にprintされ、アサーションで同じ内容であればTrueになります。
from dataclasses import dataclass
@dataclass
class Person:
name: str
age: int
p1 = Person(name='佐藤', age=30)
p2 = Person(name='佐藤', age=30)
print(p1) # => Person(name='佐藤', age=30)
assert p1 == p2 # OK
2. dictやtupleへの変換が容易
標準のclassオブジェクトをdictやtupleに変換しようとすると上手く変換できなかったりして別途実装が必要になりますが、dataclassesモジュールではasdictというdictに変換する便利な関数を用意してくれています。
tupleへの変換などは記事内のasdictやastupleのユーティリティ関数の活用で説明を記載しています。
以下はdataclassを使用しない場合と使用した場合を比べてみました。
dataclassを使用しない場合
ネストしていると綺麗にdictへ変換されない。
class Person:
def __init__(self, name: str, age: int):
self.name = name
self.age = age
class Article:
def __init__(self, person: Person, title: str, category: str):
self.person = person
self.title = title
self.category = category
person = Person(name='佐藤', age=30)
article = Article(person=person, title="サンプルのタイトル", category="Python")
print(article.__dict__)
# 出力結果
# {'person': <__main__.Person object at 0x1069c43d0>, 'title': 'サンプルのタイトル', 'category': 'Python'}
dataclassを使用した場合
asdictを使うことで綺麗にdictへ変換してくれます。
from dataclasses import asdict, dataclass
@dataclass
class Person:
name: str
age: int
@dataclass
class Article:
person: Person
title: str
category: str
person = Person(name='佐藤', age=30)
article = Article(person=person, title="サンプルのタイトル", category="Python")
print(asdict(article))
# 出力結果
# {'person': {'name': '佐藤', 'age': 30}, 'title': 'サンプルのタイトル', 'category': 'Python'}
3. データの属性をIDEが補足してくれるようになる
dataclassを使用せずにdictの型情報だけの場合
dictの型情報だけではIDE側もkeyとなる属性情報をサジェストしてくれません。
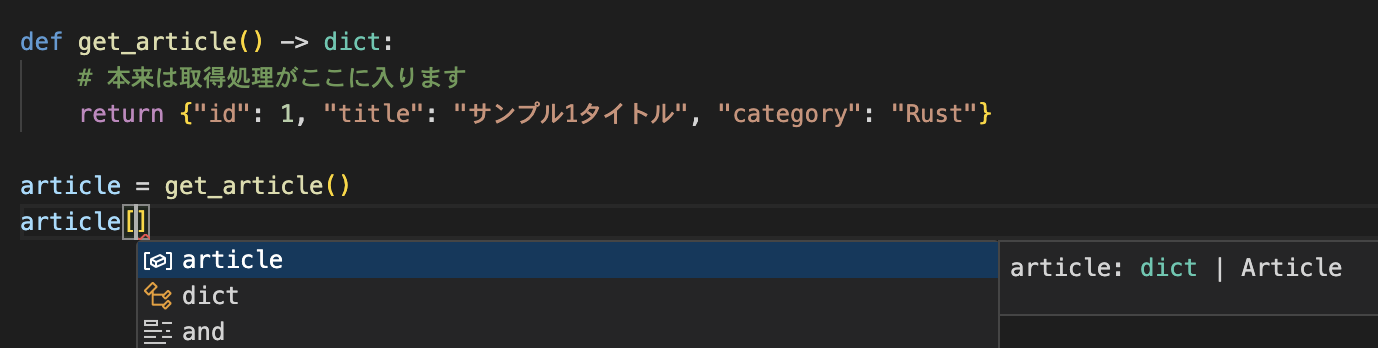
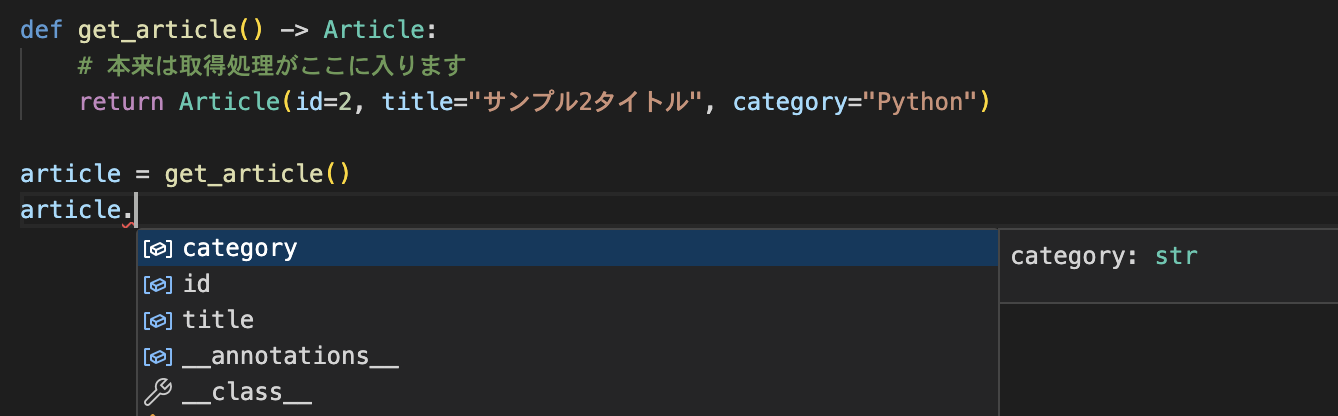
dataclassの型情報を活用する場合
.アクセスが可能になり、IDEが型情報とともに属性をサジェストしてくれます。
dataclassの使い方
dataclassはdataclassesからimportすることで使用できます。
以下は記事(Article)をdataclassで表現した場合の実装です。
from dataclasses import dataclass
@dataclass
class Article:
id: int
title: str
category: str
インスタンス化する方法は以下です。
# 引数を指定してインスタンス化する場合
article1 = Article(id=1, title="サンプル1のタイトルです", category="Python")
print(article1)
# 引数を指定せずインスタンス化する場合
article2 = Article(2, "サンプル2のタイトルです", "Rust")
print(article2)
# dictからインスタンス化する場合
article3 = Article(**{"id": 3, "title": "サンプル3のタイトルです", "category": "Ruby"})
print(article3)
# tupleからインスタンス化する場合
article4 = Article(*(4, "サンプル4のタイトルです", "PHP"))
print(article4)
# 出力結果
# Article(id=1, title='サンプル1のタイトルです', category='Python')
# Article(id=2, title='サンプル2のタイトルです', category='Rust')
# Article(id=3, title='サンプル3のタイトルです', category='Ruby')
# Article(id=4, title='サンプル4のタイトルです', category='PHP')
インスタンス化したデータクラスの属性を使用する場合は.フィールド名で使用できます。
article = Article(id=1, title="サンプル1のタイトルです", category="Python")
print(article.id)
print(article.title)
print(article.category)
# 出力結果
# 1
# サンプル1のタイトルです
# Python
dataclassの注意点
dataclassは型安全性を保証するものではなく、型アノテーションはあくまでヒントに過ぎません。
そのため定義した型とは違うデータでデータクラスを初期化した場合もエラーなく実行されてしまいます。
型安全性を保証する場合は、別途型チェックの自作する、もしくはpydanticのような厳密な型チェックを行えるサードパーティのライブラリを使用するなどが必要になります。
型チェックを自作する方法もこの記事内で紹介しているので参考にしてください。
from dataclasses import dataclass
@dataclass
class Article:
id: int
title: str
category: str
article = Article(id=None, title=200, category=None)
print(article)
# 出力結果(エラーなく実行される)
# Article(id=None, title=200, category=None)
継承
共通の属性や処理を継承でき、コードの再利用性を高めるこができます。
from typing import Any
@dataclass
class Base:
x: Any
y: int
@dataclass
class C(Base):
x: int # 基底クラスのxをオーバーライド
z: int
c = C(x=1, y=2, z=3)
print(c)
# 出力結果
# C(x=1, y=2, z=3)
__post_init__でインスタンス化後に処理を追加
__post_init__は、Pythonのdataclassesモジュールで定義された特別なメソッドで、データクラスのインスタンス生成後に追加の初期化処理を行うために使用されます。
__post_init__を活用することでバリデーション処理を追加したり、フィールドの値を動的に計算する処理を作るなどができます。
以下はバリデーション処理を追加したケースです。
@dataclass
class Product:
name: str
price: int
discount_rate: float # 割引率
def __post_init__(self):
# 割引率が0〜1の範囲外ならエラーを発生させる
if not (0 <= self.discount_rate <= 1):
raise ValueError(f"割引率が無効な数値です: {self.discount_rate}")
# 想定外なインスタンス生成
product = Product(name="スマホケース", price=1000, discount_rate=1.5)
# エラーが出力される
# ValueError: 割引率が無効な数値です: 1.5
__post_init__を活用してタイプチェックのバリデーション処理を追加
基礎クラスを作成し__post_init__内にタイプチェックをする処理を書くことで、そのクラスを継承したデータクラスでタイプチェックをしてくれるdataclassを作成することも可能です。
from dataclasses import dataclass, fields
@dataclass
class Base:
def __post_init__(self) -> None:
self.validate_fields()
def validate_fields(self):
for field in fields(self):
value = getattr(self, field.name)
# タイプチェック
field_type = field.type
if not isinstance(value, field_type):
raise TypeError(f"{self.__class__.__name__}インスタンス化処理: {field.name}が設定していタイプと一致しませんでした。: {value=}")
@dataclass
class User(Base):
id: int
name: str
age: int
user = User(id="543af591-bb5b-2970-e5be-095abbd33e85", name="佐藤", age=24)
# タイプのバリデーションでエラーが出力される
# TypeError: Userインスタンス化処理: idが設定していタイプと一致しませんでした。: value='543af591-bb5b-2970-e5be-095abbd33e85'
デフォルト値の設定
デフォルト値の設定もできます。
注意することは、リストなどの可変オブジェクトにはdefault_factoryを使用する必要があります。
from dataclasses import dataclass, field
@dataclass
class Product:
name: str
price: float
in_stock: bool = True # デフォルト値の設定
tags: list = field(default_factory=list) # 可変オブジェクトにはdefault_factoryにて設定
product = Product(name="Mouse", price=1200.0)
print(product)
# 出力結果
# Product(name='Mouse', price=1200.0, in_stock=True, tags=[])
ネストしたdataclassの活用
dataclassは、別のdataclassをフィールドとして持つことも可能です。
例えば、顧客情報と注文情報をネストして持つようなデータ構造を作成できます。
from dataclasses import dataclass
@dataclass
class Customer:
id: int
name: str
@dataclass
class Order:
order_id: int
customer: Customer # 他のdataclassをネスト
amount: float
customer = Customer(id=1, name="Yamada")
order = Order(order_id=101, customer=customer, amount=250.0)
print(order)
# 出力結果
# Order(order_id=101, customer=Customer(id=1, name='Yamada'), amount=250.0)
このようにネストしたdataclassを利用することで、複雑なデータ構造を持つクラスもシンプルに記述できます。
これにより、関連するデータをまとめて扱いやすくなり、コードの可読性が向上します。
データの不変性を保つ (frozen)
dataclassのfrozen=Trueオプションを使用すると、インスタンスが不変(イミュータブル)になり、インスタンス生成後にフィールドの値を変更できなくなります。
これにより、設定値や定数を保持するデータクラスに適しています。
from dataclasses import dataclass
@dataclass(frozen=True)
class Config:
host: str
port: int
config = Config(host="localhost", port=8080)
# config.port = 9090 # 変更しようとするとFrozenInstanceErrorが発生する
また、frozen=Trueを使用すると集合操作(和集合や積集合など)を行ったりすることもできます。便利ですね!
from dataclasses import dataclass
@dataclass(frozen=True)
class User:
id: int
name: str
email: str
a_group_users = {
User(id=1, name="Yamada", email="yamada@example.com"),
User(id=2, name="Tanaka", email="tanaka@example.com"),
User(id=3, name="Asai", email="Asai@example.com"),
}
b_group_users = {
User(id=1, name="Yamada", email="yamada@example.com"), # 重複データ
User(id=4, name="Morita", email="morita@example.com"),
}
# 和集合で重複データが省かれている!
print(a_group_users | b_group_users)
# 出力結果
# {
# User(id=1, name='Yamada', email='yamada@example.com'),
# User(id=2, name='Tanaka', email='tanaka@example.com'),
# User(id=3, name='Asai', email='Asai@example.com'),
# User(id=4, name='Morita', email='morita@example.com')
# }
# 積集合で重複したデータを取得できる!
print(a_group_users & b_group_users)
# 出力結果
# {
# User(id=1, name='Yamada', email='yamada@example.com')}
# }
asdictやastupleのユーティリティ関数の活用
dataclassでインスタンスしたものをdictやtupleなどに変換したい時がよくあります。
そんな時はasdict, astupleで簡単に実現できます。
asdictによるdataclassインスタンスから辞書(dict)への変換
dataclassesモジュールのasdict関数を使うと、dataclassのインスタンスを辞書(dict)に変換できます。
これにより、各フィールドの名前と値がキーとバリューのペアとして辞書に格納されます。
from dataclasses import dataclass, asdict
@dataclass
class User:
id: int
name: str
email: str
user = User(id=1, name="Yamada", email="yamada@example.com")
# dataclassインスタンスを辞書に変換
user_dict = asdict(user)
print(user_dict)
# 出力結果 => {'id': 1, 'name': 'Yamada', 'email': 'yamada@example.com'}
astupleによるdataclassインスタンスからタプル(tuple)への変換
dataclassesモジュールのastuple関数を使うと、dataclassのインスタンスをタプル(tuple)に変換できます。
from dataclasses import dataclass, astuple
@dataclass
class User:
id: int
name: str
email: str
user = User(id=1, name="Yamada", email="yamada@example.com")
# dataclassインスタンスを辞書に変換
user_dict = astuple(user)
print(user_dict)
# 出力結果 => (1, 'Yamada', 'yamada@example.com')
参考
まとめ
今回はdataclassesのモジュールについて説明する記事を書いてみました。
dataclass便利なのでぜひ使ってみてください!