最近流行りのApex Legendsですが、先日Vtuber最協決定戦なる大会が開かれていました。
Apexをプレイし、Vtuberの配信をのんびり見る典型的なオタクである僕は当然見ていたのですが、大会自体は見ているこちらがApexをプレイしたくなるような、非常に熱く面白い内容でした。
そんな素晴らしい大会の終盤、ひとつの悲劇が起きました。そう、集計ミスです。
この大会の総合順位は、各試合の順位ポイントとキルポイントを合算したポイントで決定されますが、この合算する処理にミスがあったようで総合順位が変動してしまいました。
詳しい集計方法は分かりませんが、確かに全20チームの順位だけでなく、60人の出場選手全てのキルポイントをリザルト画面から記録・集計するというのはミスが起きやすそうな状況です。
しかもこのゲームにはリスポーンがあり、「全チームの合計キル数」と「60人から最後に生き残った勝利チームの人数を引いた数」とが一致するわけではない、というところがチェックをややこしくさせます。
でも、文字認識で自動集計させれば...?
そう思い立って、リザルト画面から文字認識による集計ができないか試してみました。
とりあえず、やってみる
画像から文字を抽出するといえばOCR(光学文字認識)ですが、何か良いのないかなとググってみたら出てきました。
どの程度の精度が出るかも分からないので、リファレンスを見ながら試してみます。
リファレンスではラベル検出を行っていますが、テキストを検出したいのでその部分だけ変更。
import io
import os
# Imports the Google Cloud client library
from google.cloud import vision
from google.oauth2 import service_account
# Instantiates a client
credentials = service_account.Credentials.from_service_account_file(JSON_FILE)
client = vision.ImageAnnotatorClient(credentials=credentials)
# The name of the image file to annotate
file_name = os.path.abspath(IMAGE_FILE)
# Loads the image into memory
with io.open(file_name, 'rb') as image_file:
content = image_file.read()
image = vision.Image(content=content)
response = client.text_detection(image=image)
print(response.text_annotations[0].description)
用意した画像がこちら。本配信で流れた第1試合のリザルト画面です。
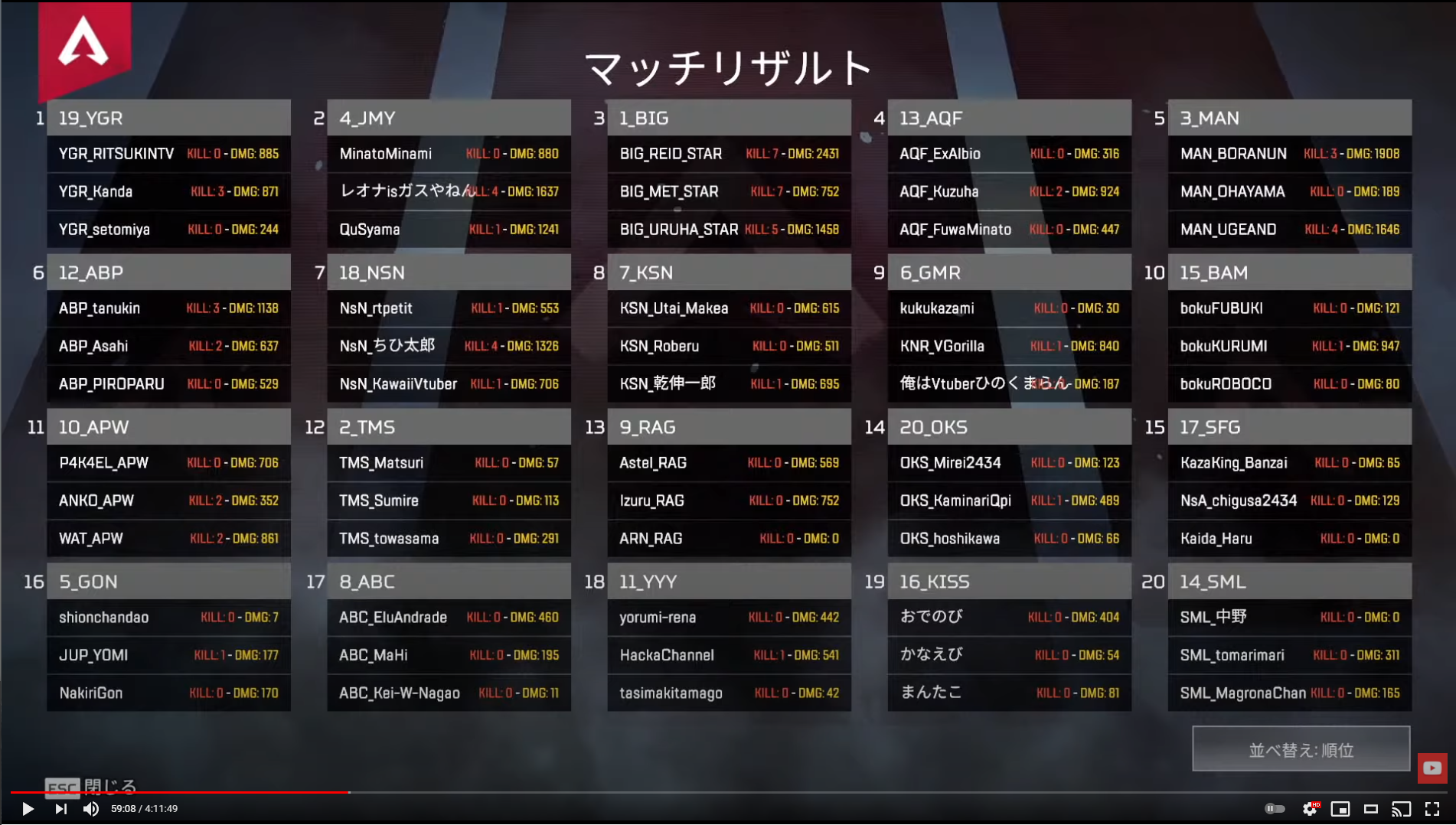
結果がこちら(一部です)。
マッチリザルト
1 19_YGR
2 4 JMY
3 1BIG
4 13_AQF
5 3_MAN
YGR RITSUKINTV KILL: 0- DMG: 885
MinatoMinami
KILL: D- DMG: 880
BIG_REID_STAR
KILL: 7 - DMG: 2431
AQF_ExAlbio
KILL: 0- DMG: 316
MAN_BORANUN KILL:3-DMG: 1908
YGR_Kanda
KILL: 3 - DMG: 871.
レオナisガスやねんL4-DMG:1637
BIG_MET_STAR
KILL: 7 - DMG: 752
AQF_Kuzuha
KILL: 2- DMG: 924
MAN_OHAYAMA
KILL: 0- DMG: 189
YGR setomiya
KILL: 0 - DMG: 244
QuSyama
KILL:1- DMG: 1241
BIG_URUHA_STAR KILL:5-OMG: 1458
AQF_FuwaMinato
KILL:0- DMG: 447
MAN_UGEAND
KILL: 4- DMG: 1646
...
名前やチーム名の「_」の読み取りが不安定ですが、かなり精度高く読み取れています。
早速この結果を各選手ごとに集計していきたいのですが、読み取りの特性上、出力される選手がチーム単位になっておらず、結果も1行だったり2行だったりしているので前処理をすることにしました。
画像の分割
1行ごとに読み取られる特性上、先程の画像ではチームがバラバラになってしまいますが、そもそもチームごとにリザルトを切り取っておけばバラバラになることはありません。
リザルト画面の構成はどの試合でも変化しないため、予め座標を測定しておけば切り取ることは難しくなさそうです。
from PIL import Image
width_rates = [0, 0.209, 0.397, 0.588, 0.781, 1]
height_rates = [0.115, 0.303, 0.491, 0.68, 0.87]
img_size = []
def cut_image(img_file):
img = Image.open(img_file)
width = img.size[0]
height = img.size[1]
for i in range(5):
left = width * width_rates[i]
right = width * width_rates[i + 1]
for j in range(4):
upper = height * height_rates[j]
lower = height * height_rates[j + 1]
image_for_save = img.crop(box=(left, upper, right, lower))
img_size.append([right - left, lower - upper])
image_for_save.save('./game' + str(game_num) + '_rank' + str(i + j * 5 + 1) + '.png')
実際に切り取ってみると、↓のような画像が20枚できあがります。
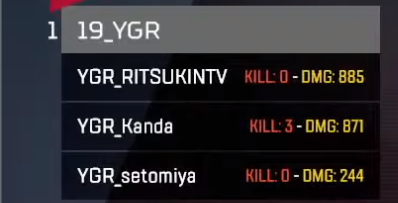
いい感じですね。
この画像を使ってもう一度読み取ってみます。
import sys
def read_image(client, file_name):
# Loads the image into memory
with io.open(file_name, 'rb') as image_file:
content = image_file.read()
image = vision.Image(content=content)
response = client.text_detection(image=image)
texts = response.full_text_annotation
return texts
if __name__ == '__main__':
img_file = sys.argv[1]
game_num = sys.argv[2]
cut_image(img_file)
# Instantiates a client
credentials = service_account.Credentials.from_service_account_file(JSON_FILE)
client = vision.ImageAnnotatorClient(credentials=credentials)
results = []
for img_num in range(20):
# The name of the image file to annotate
file_name = os.path.abspath('./game' + str(game_num) + '_rank' + str(img_num + 1) + '.png')
texts = read_image(client, file_name)
print(texts.text)
1 19 YGR
YGR RITSUKINTV KILL: 0- DMG: 885
YGR_Kanda
KILL: 3 - DMG: 871
YGR setomiya
KILL: 0 - DMG: 244
Good.
データの整形
チームごとに戦績を抽出できたので、次は選手ごとにまとめていきます。
取得できるデータは選手名、キル数、ダメージ数なのでこの3つを1つのリストにまとめます。
まず、1選手のデータは1行に収まっているので、読み取った文字のy座標を元に判定すれば良さそうです。
def format_to_list(img_num, texts):
team_result = []
y = 0
formatted_list = ['', '', '']
for page in texts.pages:
for block in page.blocks:
for paragraph in block.paragraphs:
for word in paragraph.words:
coordinates = word.bounding_box.vertices[0]
if y - 15 < coordinates.y and coordinates.y < y + 15:
formatted_list = add_to_list(img_num, word, coordinates, formatted_list)
continue
team_result = process_end_of_line(team_result, formatted_list)
formatted_list = ['', '', '']
y = coordinates.y
formatted_list = add_to_list(img_num, word, coordinates, formatted_list)
team_result = process_end_of_line(team_result, formatted_list)
return team_result
def process_end_of_line(team_result, formatted_list):
formatted_list = separate(formatted_list)
if formatted_list.count('') != len(formatted_list):
team_result.append(formatted_list)
return team_result
また、選手名は画像の左半分、キル数ダメージ数は右半分に記載されているので、単語の始点のx座標を元に判定すれば分割できそうです。
さらに、キル数とダメージ数の間には「-」があるので、これを使って分割します。
import re
def add_to_list(img_num, word, coordinates, formatted_list):
if coordinates.x < (img_size[img_num][0] / 2):
for symbol in word.symbols:
formatted_list[0] += symbol.text
return formatted_list
for symbol in word.symbols:
formatted_list[1] += symbol.text
return formatted_list
def separate(formatted_list):
is_first_row = formatted_list[1] == ''
if is_first_row:
formatted_list[0] = re.sub('[^a-zA-Z]', '', formatted_list[0])
return formatted_list
kill_dmg = formatted_list[1].split('-')
for i in range(len(kill_dmg)):
kill_dmg[i] = re.sub('\\D', '', kill_dmg[i]) if len(re.sub('\\D', '', kill_dmg[i])) > 0 else '0'
formatted_list = [formatted_list[0]] + kill_dmg
return formatted_list
分割ついでにキル数とダメージ数は数字だけを残すようにしてみました。
合わせて画像の1行目にある順位、チーム番号、チーム名についてもチーム名だけを抽出しています。
(これは後で利用します。)
結果はこんな感じ。
[['YGR', '', ''], ['YGRRITSUKINTV', '0', '885'], ['YGR_Kanda', '3', '871'], ['YGRsetomiya', '0', '244']]
[['JMY', '', ''], ['MinatoMinami', '0', '880'], ['レオナisガスやねん', '4', '1637'], ['QuSyama', '1', '1241']]
[['BIG', '', ''], ['BIG_REIDSTAR', '7', '2431'], ['BIG_MET_STAR', '7', '752'], ['BIG_URUHA_STAR', '5', '1458']]
[['AQF', '', ''], ['AQF_ExAlbio', '0', '316'], ['AQF_Kuzuha', '2', '924'], ['AQF_FuwaMinato', '0', '447']]
[['MAN', '', ''], ['MAN_BORANUN', '3', '1908'], ['MAN_OHAYAMA', '0', '189'], ['MAN_UGEAND', '4', '1646']]
[['ABP', '', ''], ['ABPtanukin', '3', '1138'], ['ABP_Asahi', '2', '637'], ['ABP_PIROPARU', '0', '529']]
[['NSN', '', ''], ['NsN_rtpetit', '1', '553'], ['NsN_5UAB', '4', '1326'], ['NsN_KawaiiVtuber', '1', '706']]
...
良さげです。あとは選手ごとにまとめてあげれば良いのですが...。
選手名を補正する
先程の結果はチーム名や数字に関しては問題なく読み取れていますが、選手名に関しては完璧とは言えません。
(例: 「NsN_ちひ太郎」→「NsN_5UAB」など)
選手名をキーに各試合の結果を集計したいところですので、ここの表記がブレることは避けたいです。
とはいえ、読み取り精度を100%にするのは難しい...。
ということで、選手名については予め正式表記を用意しておくことにしました。
下記のような結果格納用のCSVファイルを用意して、選手名とチーム名だけ予め記入しておきます。
| Name | Team | 1-KILL | 1-DMG | 1-RANK | 2-KILL | ... | ALL-KILL | ALL-DMG |
|---|---|---|---|---|---|---|---|---|
| BIG_REID_STAR | BIG | 0 | 0 | 0 | 0 | ... | 0 | 0 |
| BIG_MET_STAR | BIG | 0 | 0 | 0 | 0 | ... | 0 | 0 |
| BIG_URUHA_STAR | BIG | 0 | 0 | 0 | 0 | ... | 0 | 0 |
| ... | ||||||||
| OKS_Mirei2434 | OKS | 0 | 0 | 0 | 0 | ... | 0 | 0 |
| OKS_KaminariQpi | OKS | 0 | 0 | 0 | 0 | ... | 0 | 0 |
| OKS_hoshikawa | OKS | 0 | 0 | 0 | 0 | ... | 0 | 0 |
大会中に選手名の表記が変わることは考えにくいため、予め用意した正式表記と読み取った選手名を対応付ける形で選手名を補正します。
対応付けにはdifflibというライブラリのdifflib.SequenceMatcherを用いて類似度を算出し、高い類似度を示した正式表記に読み取った選手名を対応付けます。
また、類似度の高い正式表記が存在しない場合は、他のチームメンバーの対応付けが完了した後に、対応付けられていない正式表記の中で一番類似度の高いものに対応付けることとします。
import difflib
import pandas as pd
def associate_with_name(team_result, canonical_names):
names = {}
for member_num in range(1, len(team_result)):
name = team_result[member_num][0]
for canonical_name in canonical_names:
similarity = difflib.SequenceMatcher(None, name, canonical_name).ratio()
if similarity >= 0.9:
names[name] = canonical_name
continue
if name not in names:
names[name] = None
if None in names.values():
keys = [k for k, v in names.items() if v is None]
names_copy = canonical_names.copy()
for name in names.values():
if name in canonical_names:
names_copy.remove(name)
for key in keys:
max_similarity = -1
for name_copy in names_copy:
similarity = difflib.SequenceMatcher(None, key, name_copy).ratio()
if similarity > max_similarity:
names[key] = name_copy
max_similarity = similarity
return names
if __name__ == '__main__':
df = pd.read_csv(sys.argv[1], index_col=0)
img_file = sys.argv[2]
game_num = sys.argv[3]
cut_image(img_file)
# Instantiates a client
credentials = service_account.Credentials.from_service_account_file(JSON_FILE)
client = vision.ImageAnnotatorClient(credentials=credentials)
results = []
for img_num in range(20):
# The name of the image file to annotate
file_name = os.path.abspath('./game' + str(game_num) + '_rank' + str(img_num + 1) + '.png')
texts = read_image(client, file_name)
team_result = format_to_list(img_num, texts)
team = df[df['Team'].isin([team_result[0][0]])]
canonical_names = list(team.index)
names = associate_with_name(team_result, canonical_names)
print(names)
結果はこちら。
{'YGRRITSUKINTV': 'YGR_RITSUKINTV', 'YGR_Kanda': 'YGR_Kanda', 'YGRsetomiya': 'YGR_setomiya'}
{'MinatoMinami': 'MinatoMinami', 'レオナisガスやねん': 'レオナisガスやねん', 'QuSyama': 'QuSyama'}
{'BIG_REIDSTAR': 'BIG_REID_STAR', 'BIG_MET_STAR': 'BIG_MET_STAR', 'BIG_URUHA_STAR': 'BIG_URUHA_STAR'}
{'AQF_ExAlbio': 'AQF_ExAlbio', 'AQF_Kuzuha': 'AQF_Kuzuha', 'AQF_FuwaMinato': 'AQF_FuwaMinato'}
{'MAN_BORANUN': 'MAN_BORANUN', 'MAN_OHAYAMA': 'MAN_OHAYAMA', 'MAN_UGEAND': 'MAN_UGEAND'}
{'ABPtanukin': 'ABP_tanukin', 'ABP_Asahi': 'ABP_Asahi', 'ABP_PIROPARU': 'ABP_PIROPARU'}
{'NsN_rtpetit': 'NsN_rtpetit', 'NsN_5UAB': 'NsN_ちひ太郎', 'NsN_KawaiiVtuber': 'NsN_KawaiiVtuber'}
...
しっかりと対応付けができました。あとは各選手名の行に結果の数字を書き込んでいくだけです!
いざ、出力
もう悩むことはありません。CSVファイルに書き込みます。
ALL_KILL = 'ALL-KILL'
ALL_DMG = 'ALL-DMG'
def update_data_frame(df, team_result, rank_num):
for index in range(1, len(team_result)):
name = names[team_result[index][0]]
kill = str(game_num) + '-KILL'
dmg = str(game_num) + '-DMG'
rank = str(game_num) + '-RANK'
df.at[name, rank] = rank_num
if len(team_result[index]) < 3:
df.at[name, dmg] = team_result[index][1]
df.at[name, ALL_DMG] = int(df.at[name, ALL_DMG]) + int(team_result[index][1])
continue
df.at[name, kill] = team_result[index][1]
df.at[name, ALL_KILL] = int(df.at[name, ALL_KILL]) + int(team_result[index][1])
df.at[name, dmg] = team_result[index][2]
df.at[name, ALL_DMG] = int(df.at[name, ALL_DMG]) + int(team_result[index][2])
return df
if __name__ == '__main__':
df = pd.read_csv(sys.argv[1], index_col=0)
img_file = sys.argv[2]
game_num = sys.argv[3]
cut_image(img_file)
# Instantiates a client
credentials = service_account.Credentials.from_service_account_file('./my-project-1561277312302-13845f0ebb43.json')
client = vision.ImageAnnotatorClient(credentials=credentials)
results = []
for img_num in range(20):
# The name of the image file to annotate
file_name = os.path.abspath('./game' + str(game_num) + '_rank' + str(img_num + 1) + '.png')
texts = read_image(client, file_name)
team_result = format_to_list(img_num, texts)
team = df[df['Team'].isin([team_result[0][0]])]
canonical_names = list(team.index)
names = associate_with_name(team_result, canonical_names)
df = update_data_frame(df, team_result, img_num + 1)
df.to_csv('./game' + str(game_num) + '.csv')
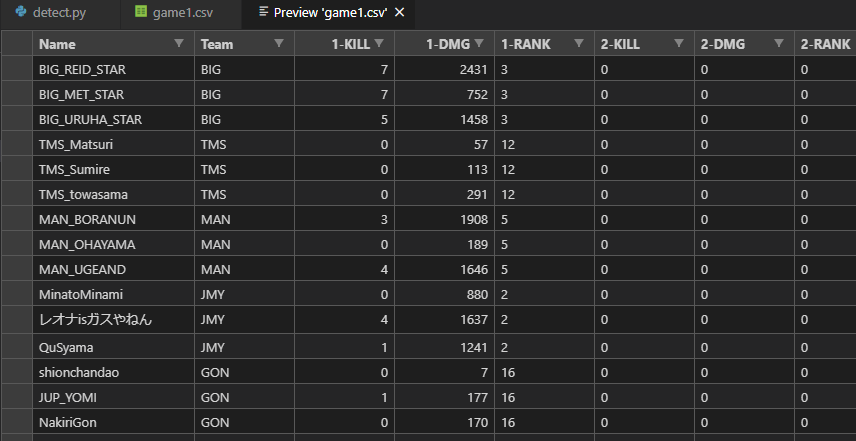
できました!完成です!!
実際の結果と比較してみると、キル数・ダメージ数の記入箇所120箇所(1人2箇所 * 60人)に対し、118箇所で正確に記入できていました。割合にして**約98.3%**です。
思いつきで始めたにしてはかなり精度の高いものができました。大満足です。
課題

人間でも読み取れんものは無理や。