目的
SpotifyのAPIを使って、世界各国で聞かれているトラックのTop200を比較して
各国に音楽傾向があるのか調べる。
Spotifyとは
Spotify(スポティファイ)は、スウェーデンの企業スポティファイ・テクノロジーによって運営されている音楽ストリーミングサービス。2021年現在、3億5,600万人(うち有料会員数1億5,800万人)のユーザーを抱えており、音楽配信サービスとしては世界最大手である。パソコン・スマートフォン・タブレット型端末・ゲーム機などの電子端末に対応している。日本では2016年9月にサービスが開始された。
※wikipediaより
環境
python3.6
surface laptop(windows10)
Microsoft Edge
Jupyter Notebook
データ
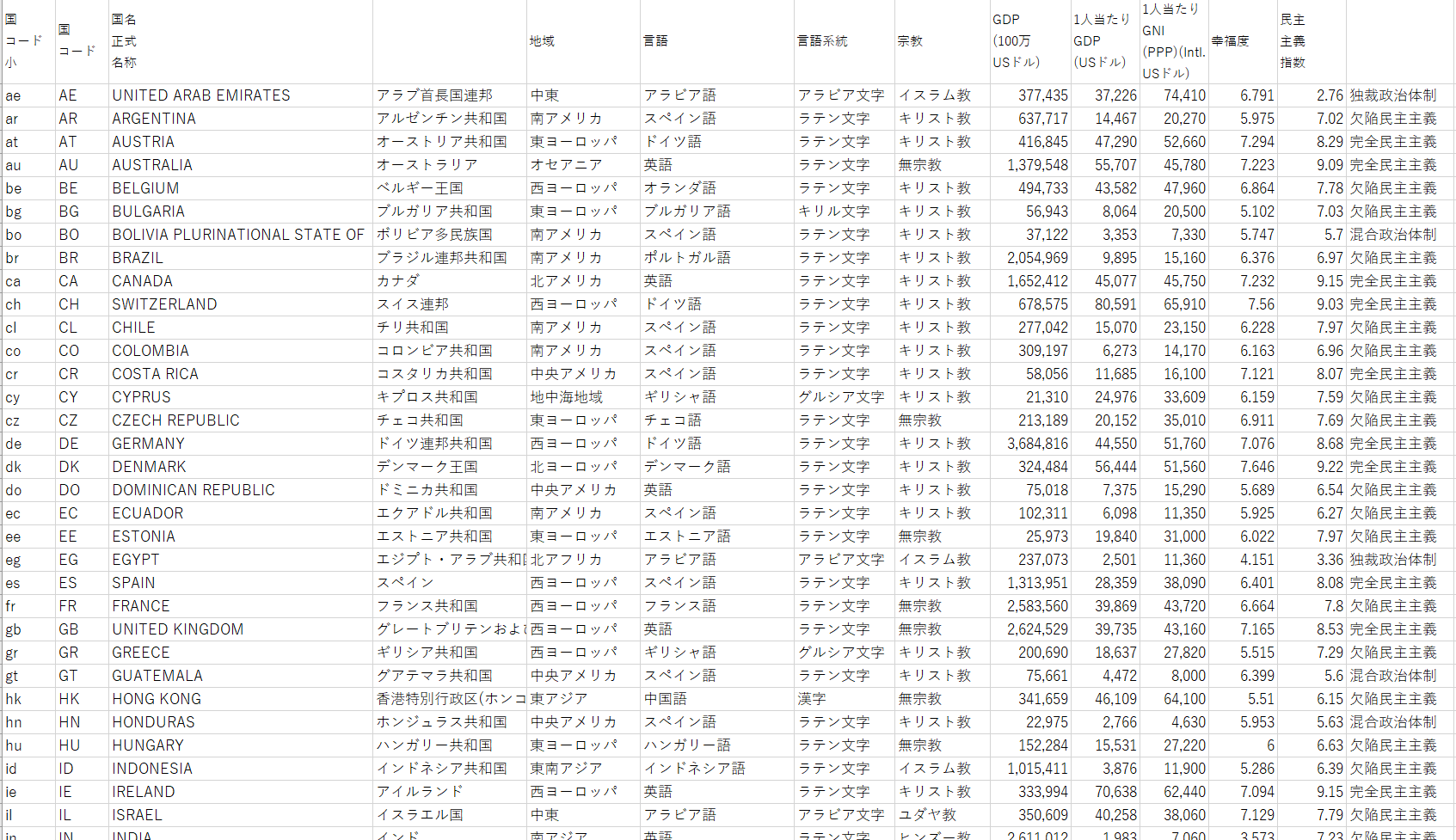
①国の特徴を収集
国別に
・地域(北アメリカ、東ヨーロッパ、アジア等)
・言語
・主な宗教
・GDP
・GNI
・幸福度
・民主主義指数
を64ヵ国集めました。
※主にwikipediaから手作業です。
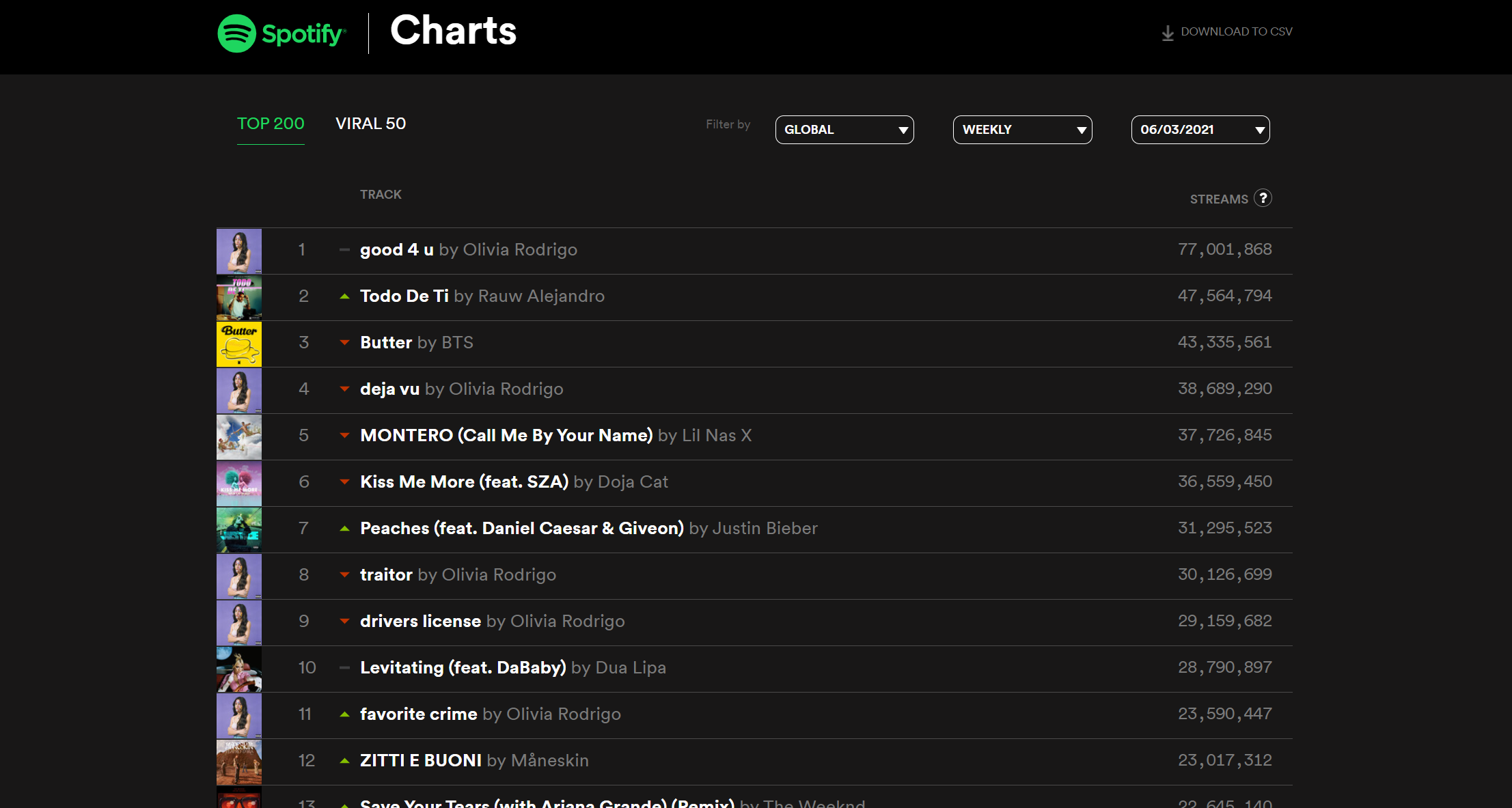
②トラックの特徴を収集
Spotify chartから、国別の週間トラックトップ200を取得、CSVで保存
import pandas as pd
import spotipy
from tqdm import tqdm
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn import preprocessing
from sklearn.cluster import KMeans
from sklearn.ensemble import RandomForestClassifier
from sklearn.decomposition import PCA
pd.set_option('display.max_rows',100)
pd.set_option('display.max_columns',100)
国の特徴①を読み込んでDataFrameにする
SpotiryAPIを使うためにIDの認証を行う
df_country=pd.read_csv('country_data.csv')
df_country=df_country.dropna(how='any',axis=1)
client_id = 'client_id'
client_secret = 'client_secret'
client_credentials_manager = spotipy.oauth2.SpotifyClientCredentials(client_id, client_secret)
spotify = spotipy.Spotify(client_credentials_manager=client_credentials_manager)
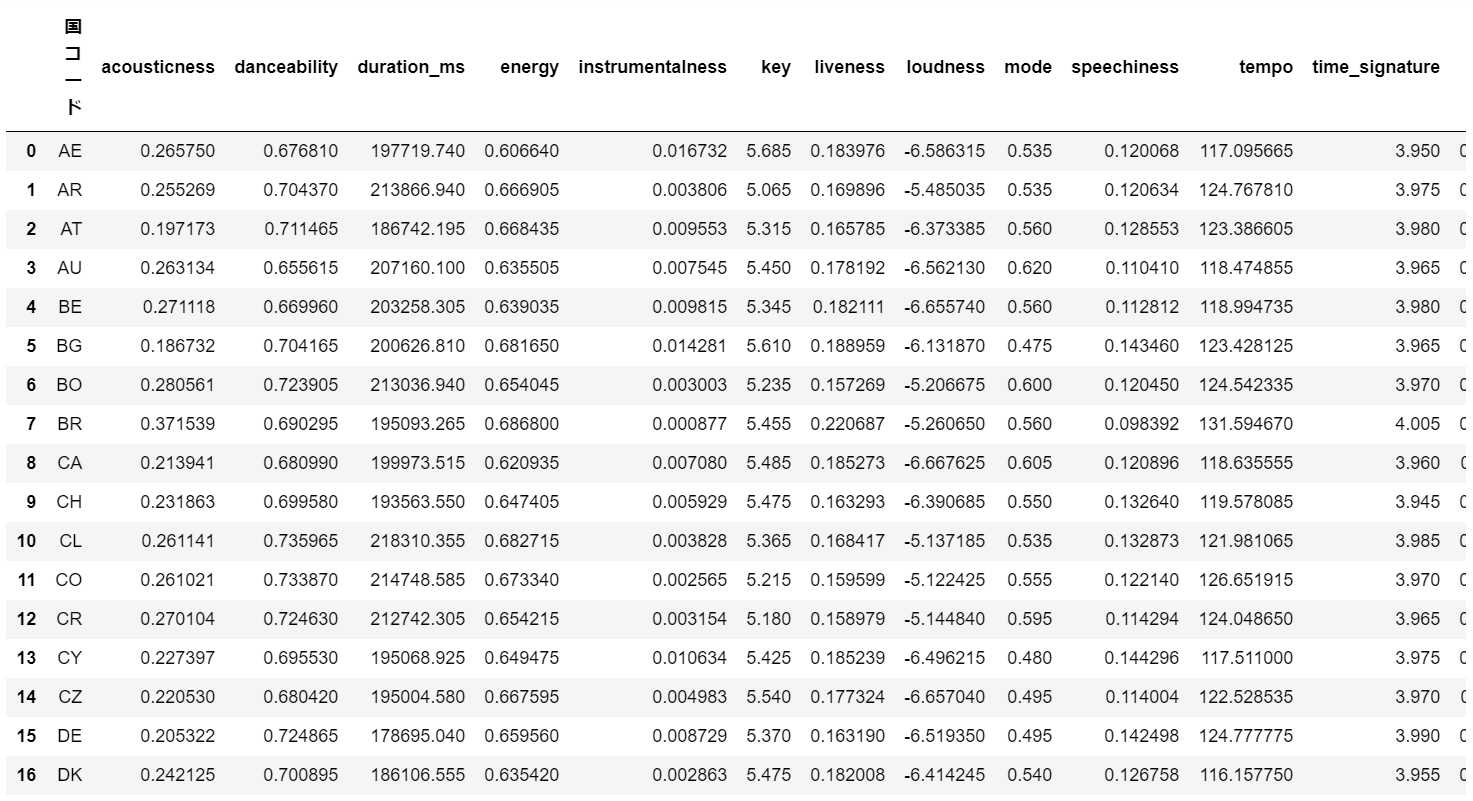
データを扱っていきます。
まずは各国のトラックトップ200の特徴量を平均したDataFrameをつくります。
(2021/5/20集計データ)
df_compare=pd.DataFrame(columns=['国コード','acousticness','danceability', 'duration_ms', 'energy',
'instrumentalness', 'key', 'liveness', 'loudness', 'mode',
'speechiness', 'tempo', 'time_signature', 'valence'])
#forループでCSVのトラックリストを取り出す
for country_lower in tqdm(df_country['国コード小']):
df_features=pd.DataFrame(columns=['acousticness','danceability', 'duration_ms', 'energy',
'instrumentalness', 'key', 'liveness', 'loudness', 'mode',
'speechiness', 'tempo', 'time_signature', 'valence'])
df_artist = pd.read_csv('./regional-' + str(country_lower) + '-weekly-latest.csv',header=1)
#トラックをループして1か国に対し200曲のDataFrameにする
for url in tqdm(df_artist['URL'].values.tolist()):
track_id = url[31:]
result =spotify.audio_features(track_id)[0]
features_list=[result['acousticness'], result['danceability'], result['duration_ms'], result['energy'],
result['instrumentalness'], result['key'], result['liveness'], result['loudness'],
result['mode'], result['speechiness'], result['tempo'], result['time_signature'], result['valence']]
s=pd.Series(features_list,index=df_features.columns)
df_features=df_features.append(s,ignore_index=True)
#特徴量を平均して1か国ずつの特徴量にする
mean_series=df_features.mean()
mean_series['国コード']=country_lower.upper()
df_compare=df_compare.append(mean_series,ignore_index=True)
df_compareを見てみると…
各国の特徴量の平均が出ました。
特に大差はないですね…
この特徴量を元にKMeansでクラスタリングして可視化してみます。
X=df_compare[['acousticness','danceability', 'duration_ms', 'energy',
'instrumentalness', 'key', 'liveness', 'loudness', 'mode',
'speechiness', 'tempo', 'time_signature', 'valence']]
#標準化して各特徴量のスケールを合わせる
sc=preprocessing.StandardScaler()
sc.fit(X)
X_norm=sc.transform(X)
#クラスタリング
model = KMeans(n_clusters=4,random_state=0)
model.fit(X_norm)
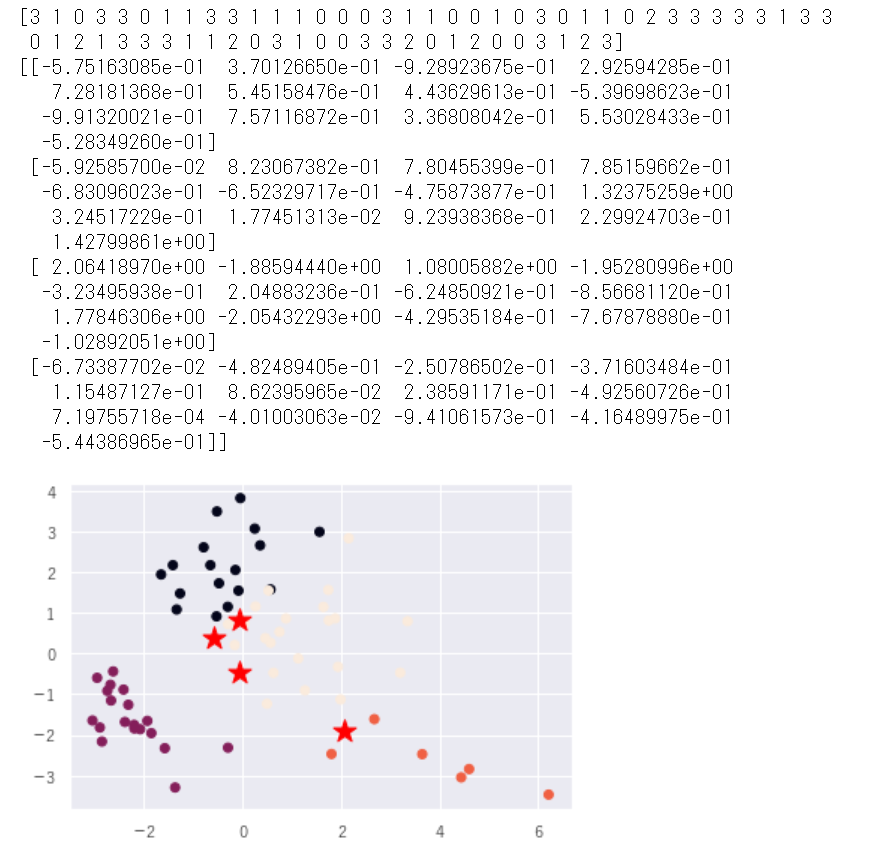
print(model.labels_)
print(model.cluster_centers_)
#可視化のために二次元へ次元削減(主成分分析)
pca = PCA(n_components=2)
pca.fit(X_norm)
pca_X = pca.transform(X_norm)
plt.scatter(pca_X[:,0],pca_X[:,1], c=model.labels_)
plt.scatter(model.cluster_centers_[:,0],model.cluster_centers_[:,1],s=250, marker='*',c='red')
plt.show()
クラスター数は
5個だとラベル4が1個だったので
4個にしておきます。
クラスタリングにおいてどの特徴量が影響しているのか調べるために
目的変数yに分類されたラベルを指定して
ランダムフォレストにてモデルを作成、
feature_importances_を使って
クラスタリング時の特徴量の重要度を出してみます。
y=model.labels_
model_2 = RandomForestClassifier(n_estimators=30,random_state=0)
model_2.fit(X, y)
importances = model_2.feature_importances_
feature_importance_df= pd.DataFrame({'feature':X.columns, 'importance':importances})
feature_importance_df=feature_importance_df.sort_values('importance',ascending=False)
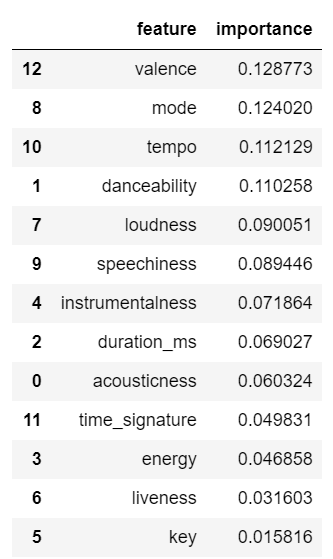
※特徴量説明
Spotifyの76,000曲の属性データを分析した結果、J-RockはRockというよりむしろPunkだったより
| キー | 意味 |
|---|---|
| valence | 曲が伝える音楽のポジティブ性を表す0.0から1.0の尺度。この指数の高い値の曲はより陽性(幸せ、陽気、陶酔など)であり、低い指数の曲はより陰性となります(悲しい、落ち込んだ、怒るなど)。 |
| mode | スケール。メジャーが1でマイナーが0。 |
| tempo | 曲の全体的な推定テンポ。1分あたりのビート(BPM)。音楽用語では、テンポは、ある曲のスピードまたはペースであり、平均ビート期間から導出されます。 |
| danceability | テンポ、リズムの安定性、ビートの強さ、全体的な規則性などの音楽要素の組み合わせに基づいて、ダンスのための曲であるかを示します。 0.0の値は、最も踊りずらいことを、1.0は、最も踊りやすいことを示します。 |
| loudness | 曲の全体的な音量をデシベル(dB)で表したものです。 |
| speechiness | スピーチは、曲の中で話された単語の存在を検出します。録音(例えば、トークショー、オーディオブック、詩)のように、音声が占める割合が大きくなるほど、値は1.0に近くなります。 |
| instrumentalness | 曲にボーカルがないかどうかを予測します。この指標では、 “オー(Ooh)”とか “アー(aah)”の音は楽器の出した音として扱われます。ラップや話し言葉はボーカルとして扱われます。インストゥルメンタルネスの値が1.0に近いほど、曲にはボーカル・コンテンツが含まれていない可能性が高くなります。 |
| duration_ms | 楽曲の時間をなんとミリ秒でお届け。 |
| acousticness | アコースティックかどうかを示す0.0から1.0の指標です。 |
| time_signature | 曲全体の拍子。 |
| energy | 0.0から1.0の指標で、強度およびアクティブ度を表します。一般的には、エネルギッシュなトラックは、速く、音が大きく、騒々しい感じがします。 |
| liveness | 録音中に聴衆が存在したかを検出します。この値が高いほど、曲がライブで実行された可能性が高くなります。 |
| key | 曲のキー。0 = C, 1 = C♯/D♭, 2 = D,...のように対応づけられた値が入ります。 |
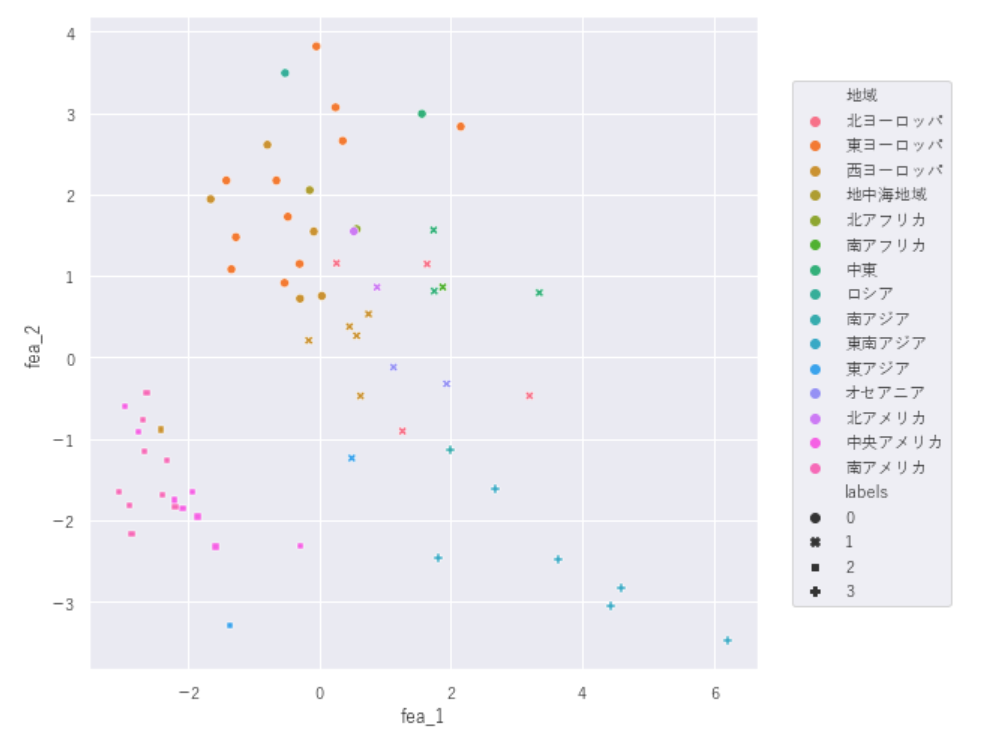
国の特徴①に圧縮した特徴量とラベルを合わせて可視化してみます。
df_country_data=df_country
df_country_data['fea_1']=pca_X[:,0]
df_country_data['fea_2']=pca_X[:,1]
df_country_data['labels']=model.labels_
sns.set(font='Yu Gothic')
#地域×ラベル
plt.figure(figsize=(8,8))
df_country_data=df_country_data.sort_values('rea_num',ascending=True)
graph=sns.scatterplot(data=df_country_data, x='fea_1', y='fea_2', hue='地域',style='labels')
graph.legend(loc='right',bbox_to_anchor=(1.3,0.5))
【地域×ラベル】
#主な言語の文字系統
plt.figure(figsize=(8,8))
df_country_data=df_country_data.sort_values('lan_num',ascending=True)
graph2=sns.scatterplot(data=df_country_data, x='fea_1', y='fea_2', hue='言語系統',style='labels')
graph2.legend(loc='right',bbox_to_anchor=(1.3,0.5))
【言語系統×ラベル】
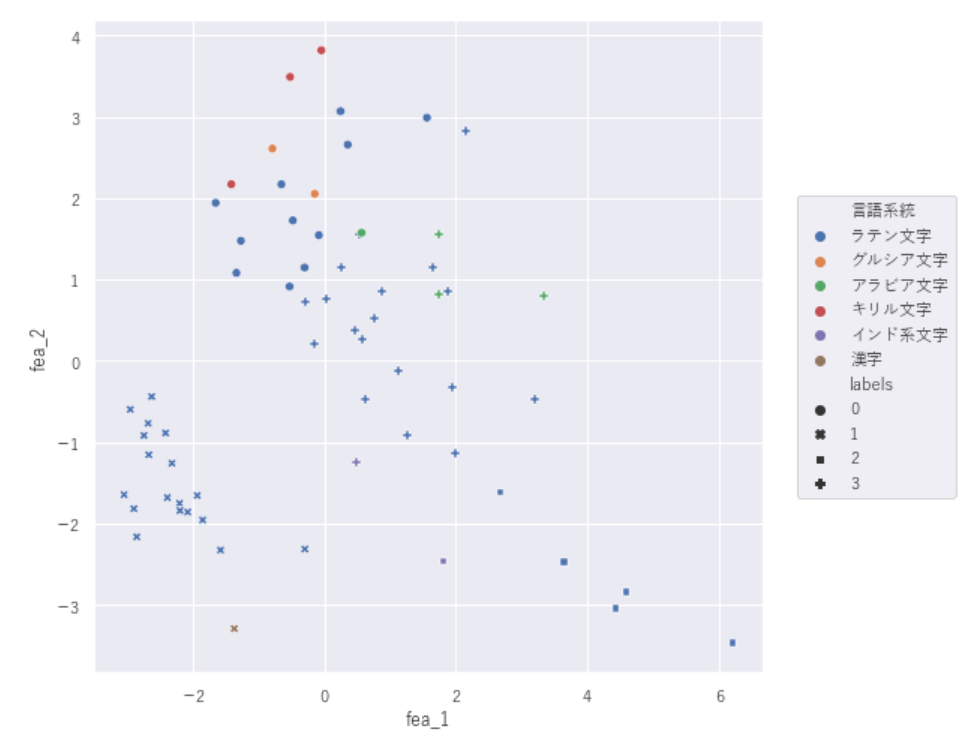
言語(英語、日本語等)だと
国に対して分類が細かすぎたので、
文字系統にまとめてみたのですが
文字系統だと分類が荒すぎるようです…
#主な宗教
plt.figure(figsize=(8,8))
df_country_data=df_country_data.sort_values('rel_num',ascending=True)
graph3=sns.scatterplot(data=df_country_data, x='fea_1', y='fea_2', hue='宗教',style='labels')
graph3.legend(loc='right',bbox_to_anchor=(1.25,0.5))
【主な宗教×ラベル】
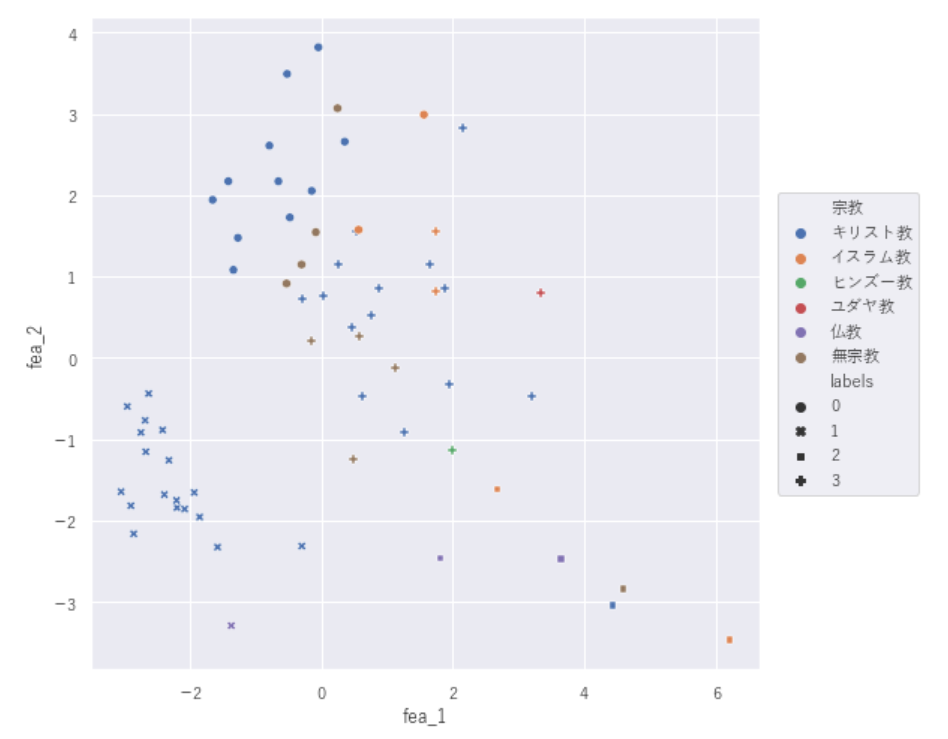
こちらももう少し細かく宗教の分類をする必要がありそうです。
#GDP(100万USドル)順位
plt.figure(figsize=(8,8))
graph4=sns.scatterplot(data=df_country_data, x='fea_1', y='fea_2', size='順位',hue='labels')
graph4.legend(loc='right',bbox_to_anchor=(1.2,0.5))
【GDP(100万USドル)順位×ラベル】
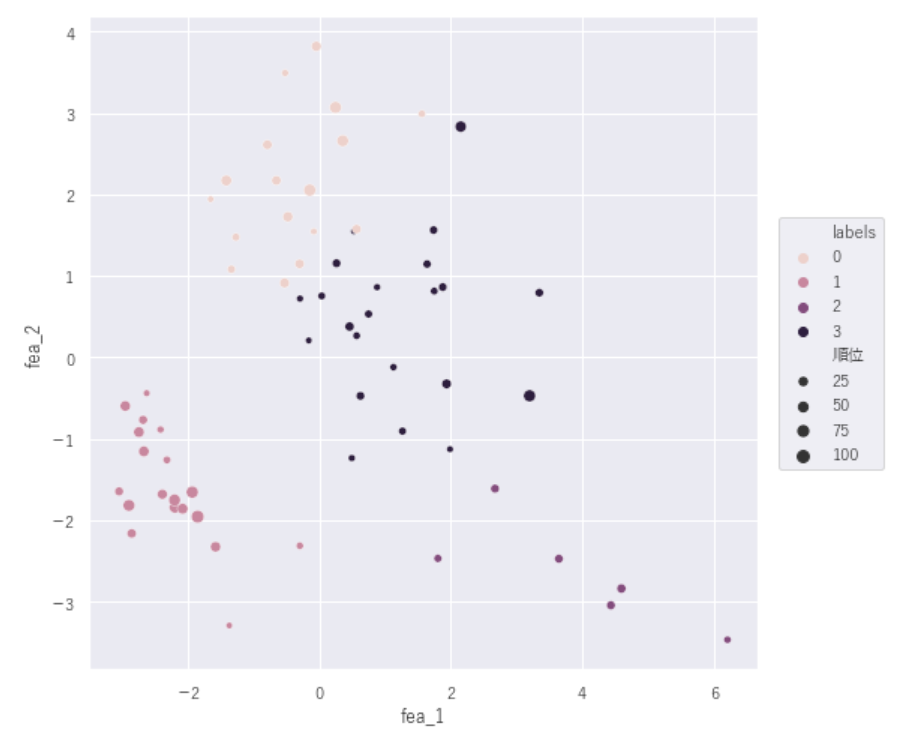
#1人当たりGDP(USドル)順位
plt.figure(figsize=(8,8))
graph5=sns.scatterplot(data=df_country_data, x='fea_1', y='fea_2', size='順位.1',hue='labels')
graph5.legend(loc='right',bbox_to_anchor=(1.2,0.5))
【1人当たりGDP(USドル)順位×ラベル】
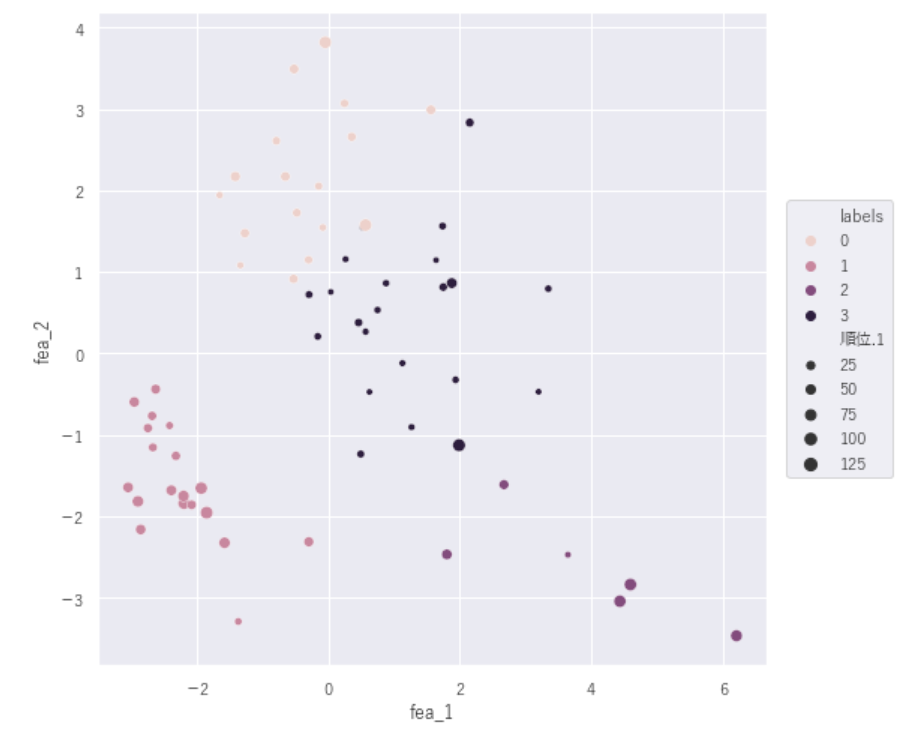
#1人当たりGNI(PPP)(Intl.USドル)順位
plt.figure(figsize=(8,8))
graph6=sns.scatterplot(data=df_country_data, x='fea_1', y='fea_2', size='順位.2',hue='labels')
graph6.legend(loc='right',bbox_to_anchor=(1.2,0.5))
【1人当たりGNI(PPP)(Intl.USドル)順位×ラベル】
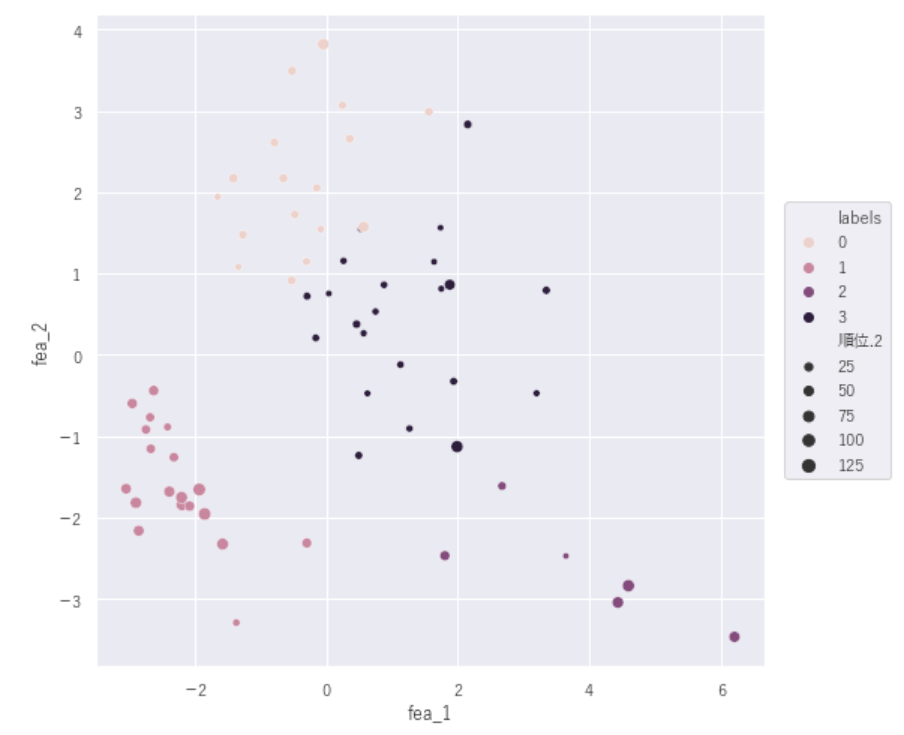
#幸福度順位
plt.figure(figsize=(8,8))
graph7=sns.scatterplot(data=df_country_data, x='fea_1', y='fea_2', size='順位.3',hue='labels')
graph7.legend(loc='right',bbox_to_anchor=(1.2,0.5))
【幸福度順位×ラベル】
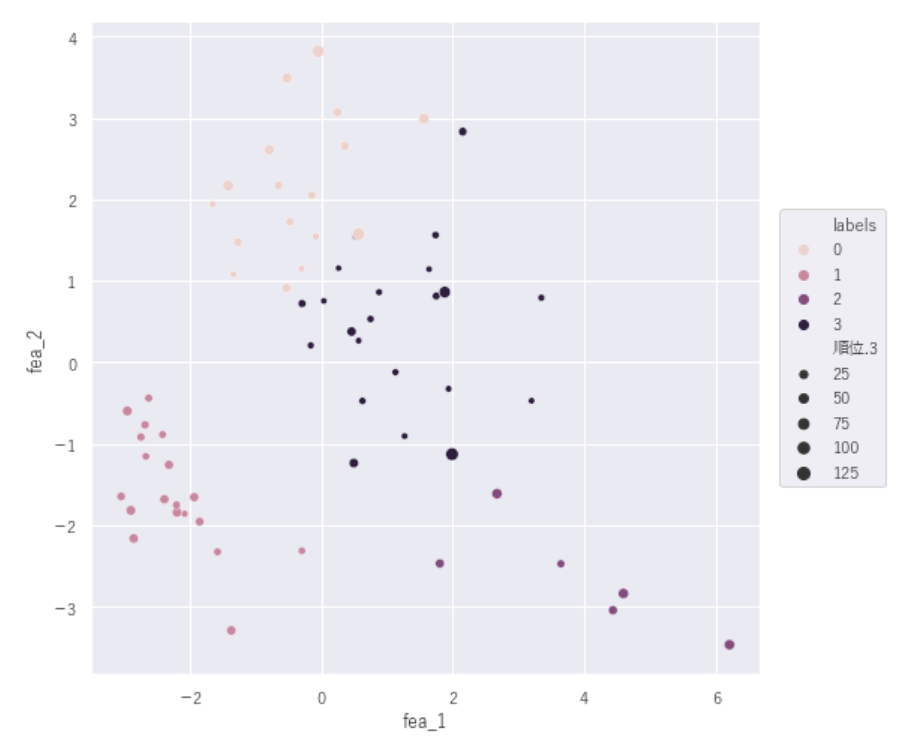
#民主主義指数順位
plt.figure(figsize=(8,8))
graph8=sns.scatterplot(data=df_country_data, x='fea_1', y='fea_2', size='順位.4',hue='labels')
graph8.legend(loc='right',bbox_to_anchor=(1.2,0.5))
【民主主義指数順位×ラベル】
※指数が大きい方が1位(完全民主主義→欠陥民主主義→独裁政治体制)小さい方が低位
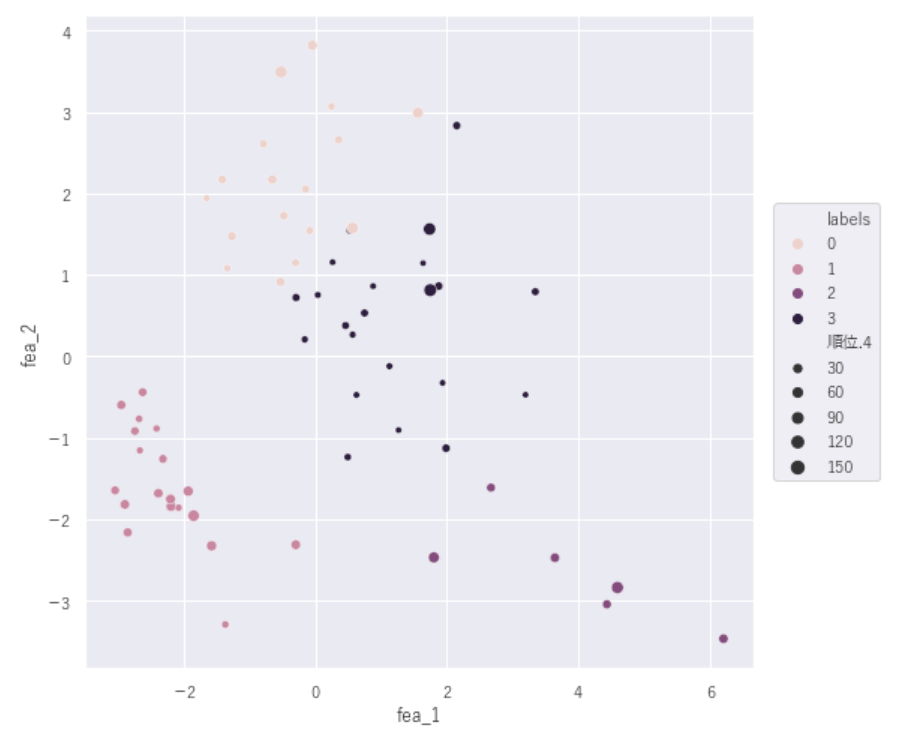
後半はあまり関係がなさそうなデータでした…
どうやら地域が関係していそうなので
国名、地域、ラベルの一覧を出してみます。
label_df=df_country_data.loc[:, ['Unnamed: 3','地域','labels']]
label_df.sort_values(['labels','地域'])
| 国名 | 地域 | ラベル |
|---|---|---|
| ロシア連邦 | ロシア | 0 |
| トルコ共和国 | 中東 | 0 |
| エジプト・アラブ共和国 | 北アフリカ | 0 |
| キプロス共和国 | 地中海地域 | 0 |
| オーストリア共和国 | 東ヨーロッパ | 0 |
| ブルガリア共和国 | 東ヨーロッパ | 0 |
| チェコ共和国 | 東ヨーロッパ | 0 |
| エストニア共和国 | 東ヨーロッパ | 0 |
| ハンガリー共和国 | 東ヨーロッパ | 0 |
| ラトビア共和国 | 東ヨーロッパ | 0 |
| ポーランド共和国 | 東ヨーロッパ | 0 |
| ルーマニア | 東ヨーロッパ | 0 |
| スロバキア共和国 | 東ヨーロッパ | 0 |
| ウクライナ | 東ヨーロッパ | 0 |
| ドイツ連邦共和国 | 西ヨーロッパ | 0 |
| フランス共和国 | 西ヨーロッパ | 0 |
| ギリシア共和国 | 西ヨーロッパ | 0 |
| コスタリカ共和国 | 中央アメリカ | 1 |
| ドミニカ共和国 | 中央アメリカ | 1 |
| グアテマラ共和国 | 中央アメリカ | 1 |
| ホンジュラス共和国 | 中央アメリカ | 1 |
| メキシコ合衆国 | 中央アメリカ | 1 |
| ニカラグア共和国 | 中央アメリカ | 1 |
| パナマ共和国 | 中央アメリカ | 1 |
| エルサルバドル共和国 | 中央アメリカ | 1 |
| アルゼンチン共和国 | 南アメリカ | 1 |
| ボリビア多民族国 | 南アメリカ | 1 |
| ブラジル連邦共和国 | 南アメリカ | 1 |
| チリ共和国 | 南アメリカ | 1 |
| コロンビア共和国 | 南アメリカ | 1 |
| エクアドル共和国 | 南アメリカ | 1 |
| ペルー共和国 | 南アメリカ | 1 |
| パラグアイ共和国 | 南アメリカ | 1 |
| ウルグアイ東方共和国 | 南アメリカ | 1 |
| 日本国 | 東アジア | 1 |
| スペイン | 西ヨーロッパ | 1 |
| インドネシア共和国 | 東南アジア | 2 |
| マレーシア | 東南アジア | 2 |
| フィリピン共和国 | 東南アジア | 2 |
| シンガポール共和国 | 東南アジア | 2 |
| タイ王国 | 東南アジア | 2 |
| ベトナム社会主義共和国 | 東南アジア | 2 |
| オーストラリア | オセアニア | 3 |
| ニュージーランド | オセアニア | 3 |
| アラブ首長国連邦 | 中東 | 3 |
| イスラエル国 | 中東 | 3 |
| サウジアラビア王国 | 中東 | 3 |
| カナダ | 北アメリカ | 3 |
| アメリカ合衆国(米国) | 北アメリカ | 3 |
| 南アフリカ共和国 | 南アフリカ | 3 |
| 大韓民国 | 東アジア | 3 |
| インド | 南アジア | 3 |
| リトアニア共和国 | 東ヨーロッパ | 3 |
| ベルギー王国 | 西ヨーロッパ | 3 |
| スイス連邦 | 西ヨーロッパ | 3 |
| グレートブリテンおよび北部アイルランド連合王国(英国) | 西ヨーロッパ | 3 |
| アイルランド | 西ヨーロッパ | 3 |
| イタリア共和国 | 西ヨーロッパ | 3 |
| オランダ王国 | 西ヨーロッパ | 3 |
| ポルトガル共和国 | 西ヨーロッパ | 3 |
| デンマーク王国 | 北ヨーロッパ | 3 |
| アイスランド共和国 | 北ヨーロッパ | 3 |
| ノルウェー王国 | 北ヨーロッパ | 3 |
| スウェーデン王国 | 北ヨーロッパ | 3 |
おわりに
各国2021/5/20の週間チャートを使用したところ、
| 分類ラベル | 地域 |
|---|---|
| ラベル0 | 東ヨーロッパ |
| ラベル1 | 中央、南アメリカ |
| ラベル2 | 東南アジア |
| ラベル3 | オセアニア、中東、北アメリカ、北ヨーロッパ |
という結果になりました。
東、南アジアやアフリカはバラつきがありますが
国のデータが少なかったので集めて分析進めたいですね!
南北のアメリカや西ヨーロッパが分かれてしまいました…
地域・言語系統以外に
大きくラベルに関係してそうな特徴(言語系統、GDPなど)は
見られなかったです。
文化や言語が隣接地域へ連鎖して波紋上に広がっていくように
音楽も広がってきたのでしょう
インターネットやSNS、
それこそSpotifyのようなストリーミングサービスが普及した現在
波紋のように伝わってきた音楽も、
電脳的な網の目の中で交差しながら広がるエコーのようなものに進化しているのではないでしょうか
ストリーミングで世界に広がるものが今後はもっと増えていくと思います。
今後の分析結果も面白くなりそうです。
分析結果が体感とリンクするのか実際の曲を聴き比べてみたいです^^
データの分類不足も改善しつつ、
バラつきがある地域や分かれてしまった地域にどんな理由が隠れているのか
今後はデータリテラシーの勉強も増やして
また、もっとデータを集めて今後の分析に期待します!!