この記事はミクシィグループ Advent Calendar 2019 の15日目の記事です。
Blenderを知っていますか?
みなさんはBlenderを知っていますか?
BlenderはOSSの3DCG統合ソフトですが、最近はVTuberやVRChatの流行により、エンジニアでも知っている人は多いのではないでしょうか。
Blenderはかなり歴史が古く、最初にリリースされたのは1994年です(つまりJavaが世に出るより前からBlenderはありました)
現在も活発に開発が続いており、つい先日の11/21には最新版の2.81がリリースされたばかりです。
そんなBlenderは最初期から標準の保存形式として.blendという独自形式のファイルフォーマットを採用してきました。
.blendは生物がもつDNAのような仕組みを取り入れることで、強烈な後方互換性を持っていることでも有名で、なんと25年前のBlender1.00で作られた.blendファイルが最新版の2.81でも問題なく開くことができます。
Blenderをインストールしている人は、実際にBlender1.00で作られた.blendファイルを開いてみてください。どのバージョンであっても普通に開けるはずです。
ここまで読めば.blendファイルの仕組みが気になって仕方がないと思うので、今日は.blendのファイルフォーマットの話をします。
.blendの特徴
.blendは、他の多くのバイナリフォーマットとは違ういくつかの特徴を持っています。
- Blenderは実行中のメモリの状態を、ほぼそのままメモリダンプする形で.blendファイルにします。
- ヘッダを付け加えるだけで、他の操作を必要としないため、複雑なプロジェクトであっても保存が非常に高速です。
- ファイルヘッダにエンディアンやポインタレジスタのサイズまで書き込むため、一般的なバイナリフォーマットでは重要なエンディアン変換すら必要ありません。
- .blendはDNAと呼ばれる構造を持っており、BlenderはこのDNAを最初に読み込み、.blendファイルを開こうとしているBlenderのバージョンとBlenderが動いているコンピュータの環境に合わせてどのようにデータを処理すればよいかを決めた後で、実際にデータを処理します。
- DNAというのは、要するにデータがどのような形式なのかを表しており、.blend単体で保存したいデータ自体とデータがどのような形で保存されているかの両方の情報を持っているということです。
- このような自己言及的なファイルフォーマットはかなり先進的で、最近ではGoでencoding/gobとして採用されていたりもします。
.blendの全体観
.blendは大まかに、ファイルヘッダとファイルブロックの2つのセクションで構成されています。

はじめにファイルヘッダがあり、その後ブロックヘッダとブロックデータを持つファイルブロックと呼ばれる構造がいくつも続き、最後にDNA1ファイルブロックとENDBファイルブロックが入り、ファイルが終了します。
ファイルブロックヘッダにブロックデータの種類を表すコードが入っており、コードに合わせてブロックデータの処理を変える必要があります。
DNA1もENDBもコードの一種で、必ず最後のファイルブロックになるというルール以外は普通のファイルブロックと同じです。
ここからは具体的に各セクションのフォーマットを見ていきます。
ファイルヘッダ
ファイルヘッダは.blendファイルを処理するうえで、全般的に必要な情報が格納されています。
サイズは必ず12バイトで、次のように構成されています。
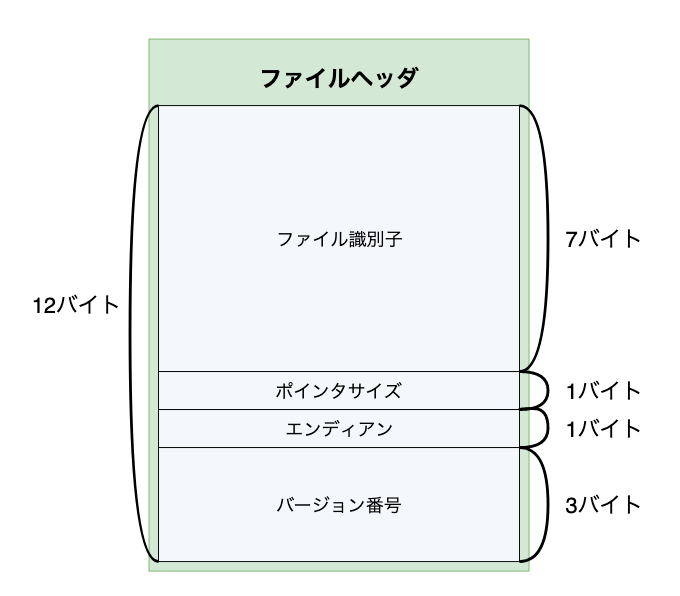
| フィールド | サイズと型 | 概要 |
|---|---|---|
| ファイル識別子 | 7バイト文字列 | 必ず"BLENDER"が入ります。 |
| ポインタサイズ | 1バイト文字 |
_のとき32ビットポインタ、-のとき64ビットポインタを使用した環境で保存されたファイルであることが分かります。 |
| エンディアン | 1バイト文字 |
vのときリトルエンディアン、Vのときビッグエンディアンでデータが配置されています。 |
| バージョン番号 | 3バイト文字列 | バージョン番号から"."を抜いたものが入っています。 Blender2.81で保存された.blendファイルであれば、ここには 281が入っています。また、数値としてのバージョン番号ではなくASCIIであることに注意してください。(2.81の場合は 50,56,49と並んでいます。) |
ここで指定されたエンディアンとポインタサイズに基づいて、続くファイルブロックを読み取っていきます。
ファイルブロック
ファイルブロックには、前述の通り、ブロックヘッダとブロックデータの2つから成ります。
ブロックデータは、ブロックヘッダによって大きく構造が異なるため、ここではひとまず、ブロックヘッダの解説をします。
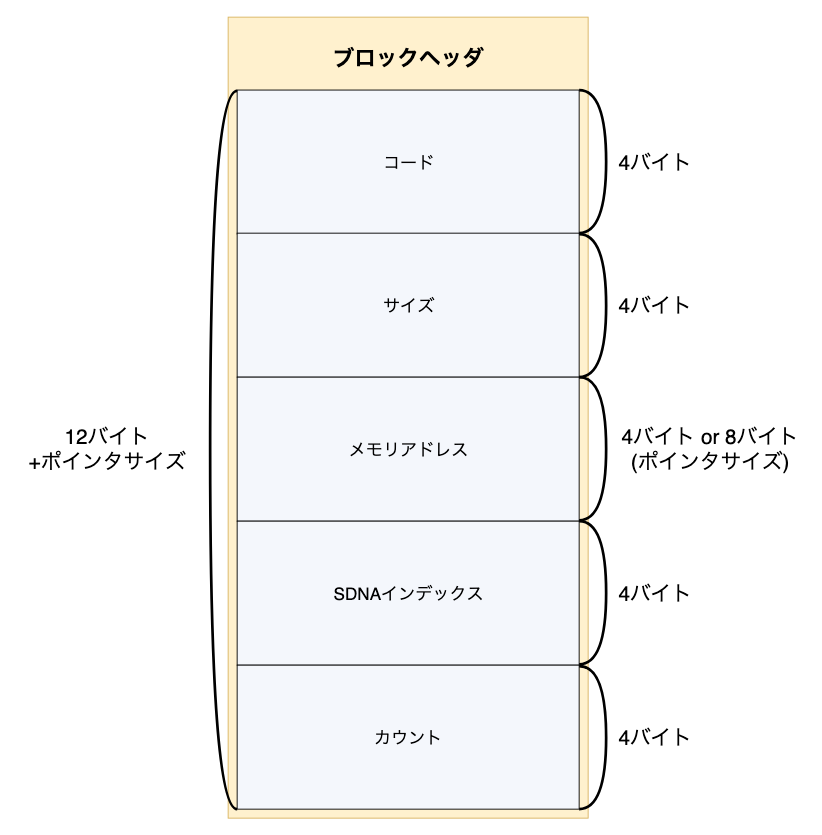
ブロックヘッダは12+ポインタサイズの可変長データです。
ファイルヘッダで指定されたポインタサイズが32ビットの場合16バイト、64ビットの場合20バイトがブロックヘッダのサイズになります。
| フィールド | サイズと型 | 概要 |
|---|---|---|
| コード | 4バイト文字列 | ファイルブロックの識別子の役割をしています。 |
| サイズ | 32ビット整数 | ブロックデータのサイズを表しています。 |
| メモリアドレス | ポインタサイズの整数 | この.blendファイルが保存されたとき、どこのメモリアドレスにこのブロックが保存されていたかが入っています。 |
| SDNAインデックス | 32ビット整数 | 後述のDNA1ブロックのデータから構築されるSDNAのインデックスで、ブロックデータのデータ構造を決定するために使います。 |
| カウント | 32ビット整数 | SDNAによって決定したデータ構造がブロックデータにいくつ含まれるかを表しています。(つまり暗黙的に全てのブロックデータは要素数 == カウントの配列として処理されます。) |
冒頭で紹介した.blendが持つDNAと関係する、SDNAインデックスというフィールドが出てきました。
DNAは、この.blendに含まれる様々な構造体の定義の集まりです。SDNAインデックスを指定することで、インデックスに対応した構造体を検索することができます。
続くブロックデータは、ここで検索した構造体がカウント分だけ連続して並んでいます。
つまり、あとはDNA1ブロックさえ読めれば、自由に.blendファイルを操作できるようになります。
ファイルブロック(ENDB)
DNA1ブロックの話に移る前に、ENDBブロックをやっつけておきます。
このファイルブロックは必ず最後のファイルブロックになっており、ファイルの終端であることを表しているだけで、特にデータ自体に影響を与えるものではない特殊なファイルブロックです。
ブロックヘッダは次のようになります。
| フィールド | 値 |
|---|---|
| コード | ENDB |
| サイズ | 0 |
| メモリアドレス | 0x00000000 |
| SDNAインデックス | 0 |
| カウント | 0 |
サイズに0が入っているため、ENDBブロックはブロックデータを持ちません。
ファイルブロック(DNA1)
ついにやってきましたDNA1ブロックです。
冒頭の図をもう一度貼りますが、DNA1ブロックは必ず最後から2番目のファイルブロックにあります。
DNA1ブロックもファイルブロックの1種なので、ブロックヘッダとブロックデータからなります。
ブロックヘッダの構造は他のファイルブロックと同じなため割愛しますが、ブロックデータは次のようになっています。
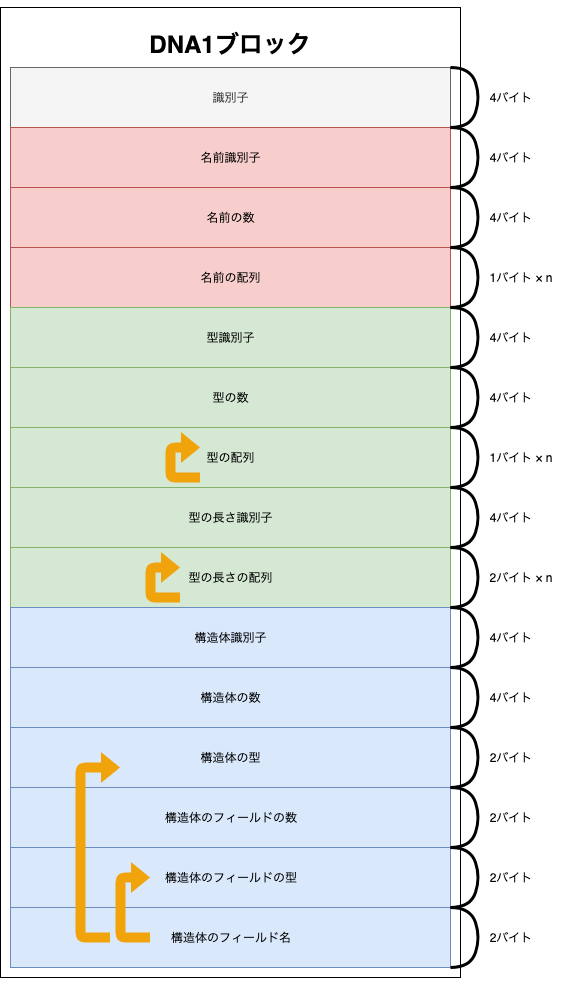
なんとなくわかると思いますが、図のオレンジの矢印の部分はループで処理します。
それぞれのフィールドの役割は次の通りです。
| フィールド | サイズと型 | 概要 |
|---|---|---|
| 識別子 | 4バイト文字列 | 必ず"SDNA" |
| 名前識別子 | 4バイト文字列 | 必ず"NAME" |
| 名前の数 | 32ビット整数 | 名前の配列の要素数 |
| 名前の配列 | ヌル終端文字列の配列 | フィールド名を表現するのに使う配列 |
| 型識別子 | 4バイト文字列 | 必ず"TYPE"。4バイト単位にアライメントを整えてから読む必要があります。 |
| 型の数 | 32ビット整数 | 型の配列の要素数 |
| 型の配列 | ヌル終端文字列の配列 | 型名を表現するのに使う配列 |
| 型の長さ識別子 | 4バイト文字列 | 必ず"TLEN"。4バイト単位にアライメントを整えてから読む必要があります。 |
| 型の長さの配列 | 16ビット整数の配列 | sizeof(型[i]) == 型の長さ[i] |
| 構造体識別子 | 4バイト文字列 | 必ず"STRC"。4バイト単位にアライメントを整えてから読む必要があります。 |
| 構造体の数 | 32ビット整数 | 構造体の配列の要素数 |
| 構造体の型 | 16ビット整数 | 型[構造体の型] == この構造体の型名 |
| 構造体のフィールドの数 | 16ビット整数 | この構造体が持つフィールドの数 |
| 構造体のフィールドの型 | 16ビット整数 | 型[構造体のフィールドの型] == この構造体のこのフィールドの型名 |
| 構造体のフィールド名 | 16ビット整数 | 名前[構造体のフィールド名] == この構造体のこのフィールドの名前 |
これでDNAの準備が整ったので、あとは好きなファイルブロックのSDNAインデックスに対応する型をバリバリ構築して抜き出していくだけです。
簡単ですね。
さいごに
.blendのDNAをパースし、各ファイルブロックのデータ構造を導くまでのサンプルをGo言語で作りました。
かなり殴り書きのプログラムなので、お世辞にもよいプログラムではないですが、もし.blendファイルをガチャガチャしたくなったときは参考にしてみてください。
github.com/shumon84/blend-reader
.blendは圧縮オプションもなくて、必要な予備知識も少ないうえに、バージョン問題も上手に回避されているため、かなり扱いやすくていいですね。
みなさんもよかったら、身の回りにある、ありふれたバイナリファイルをパースしてみてください。
それぞれいろんな思想の元に作られていて、なかなか面白いですよ。
明日は @halhorn さんです。