AviUtlでスクリプトを作っているときに、こんな問題にぶち当たりました。
string.gsubとは
string.gsub(str, pattern, repl [, n])
Luaの標準ライブラリで追加される関数です。
strにあるpatternを検索して、replで置換します。
nで置換する回数を指定できます(指定しない場合は1回)。
patternは正規表現パターンとして認識します。
やりたいこと
つまり、
steak = string.gsub("ステーキソース", "ー", "ェ", 2)
debug_print(steak) --"ステェキソェス"と表示されるはず
ということができるはずです。
しかし
AviUtlのスクリプト上から呼び出してみると、このようなエラーコードを吐き、スクリプトが止まりました。
:5: malformed pattern (missing ']')
このmalformed patternというのをGoogle翻訳に掛けると、不正なパターン__という意味でした。
その後のmissing ']'ですが、]が見つかりません__という意味です。
つまり、「このコードには]が無いですよ!」と教えてくれているのです。
……ですが、このスクリプト上では[や]は一切使用していません。
どういうことだってばよ!
ネットで検索してみると、似たような症状になっている方のブログを発見しました。
string.find()は、パターン内に「ー」が命令に入ってるとエラーになります。
つまり、「ー」を含む単語は命令語にできません。
(中略)
malformed pattern (missing `]')
「ー」の中に「[」と解釈できる文字が含まれていて、パターンを閉じる「]」が伴わないとエラーになってるっぽい?Stella Maris 「CCLバグ。」 2007年09月20日
全く同じ症状です。
気になるのは、「ー」の中に「[」と解釈できる文字が含まれていてという部分です。
Shift JISの罠
AviUtlの易しい使い方「Aviutlで使える文字コードの話」によると、AviUtlは__Windows-31J__(MS932)という文字セットで動作しているようです。
これは、Shift JIS(CP932)から派生した文字セットです。
Windows-31JとShift JISは、一部の文字で互換性がありませんが、__ほとんど同じ__です。
ただ、Shift JISのほうが馴染み深いかと思いますので、この記事ではShift JISと呼称して記述します。
ダメ文字
更にネットを検索すると、このようなページが見つかりました。
Shift_JIS(SJIS, cp932) の文字コードで、2byte目が0x5c の \ になっているものの俗称(だめ文字、駄目文字)
0x5cの \ は使用するフォントやロケールによりバックスラッシュまたは¥記号で表示されます。
ダメ文字を含む文字列やパス、ファイル名を処理する場合には文字化け、検索不可など様々な不具合が起きることがあります。
ダメ文字には ー ソ 十 表 など、使用頻度の高いものもあるので cp932を扱う場合には注意が必要です。fudist「Shift_JISのダメ文字」
どうやら、ーは2バイトで表現されているようです。
そして偶然にも、その2バイト目が0x5b ――つまり、[を表すコードになっているようです。
Shift JIS環境下だと、string.gsubやstring.findなどの関数は、1バイトずつ走査していきます。
そのため、文字の中に[のようなシステム文字が存在すると、場合によってはバグって停止します。
今回例に出したstring.gsubですが、前述の通り第2引数のpatternを正規表現パターンとして認識しています。
[はLua正規表現の記号の1つであったがために、malformed patternと表示されてしまったのです。
| ダメ文字の例 | 含む文字 |
|---|---|
| 「―」「ソ」「十」「表」など | 0x5c \ |
| 「ー」「ゼ」「充」「深」など | 0x5b [ |
| 「+」「ボ」「倍」「本」など | 0x7b { |
このように「ー」のような記号や「ソ」のようなカタカナまで含まれているので、非常に厄介です。
そして、この問題はどちらかというとShift JIS系特有の問題なので、Luaではどうしようもないというのが現状です。
その他の問題点
string.reverse関数を例に挙げます。
この関数は、string.reverse("abcdef")を"fedcba"のように逆順に変換します。
しかし、この処理は1バイトごとに行われます。
例えば、string.reverse("こんにちは")とすると、返り値は"ヘちにんこ・"となり見事にバグります。
また、@Phroneris様の投稿によると、table = {十=10}のように記述すると、スクリプトがバグるといったことも報告されていました。
解決方法
かなり強引な手法ですが、解決したのでここに記します。
ワイド文字列を使う
そもそも、Shift JIS環境下のソースコードで日本語を使うというのは、そこそこ__危険な行為__だったりします。
つまり言い換えれば、__Shift JISを使わなければ何の問題もない__ということです。
この方法には、外部DLLを使用する必要があります。
これはLuaからC/C++の関数を呼び出して、使用することが出来る機能です。
(DLLの作り方に関してはここで解説しているのでよろしければどうぞ)
マルチバイト文字・ワイド文字
マルチバイト文字は、Shift JISのように1バイト以上で表される文字のことです。
文字によって、長さが異なること(可変長)が特徴です。
一方ワイド文字は、Unicodeのように常に2バイト(もしくは4バイト)の長さで表される文字のことです。
ワイド文字は、どれも長さが同じこと(固定長)が特徴です。
参考 マルチバイト文字とワイド文字(Microsoft Docs)
MultiByteToWideChar関数
C/C++では、Windows API(windows.h)を用いることで、マルチバイト文字とワイド文字の相互変換が可能です。
ちなみに、C++で通常の文字列はstd::stringという型ですが、ワイド文字列はstd::wstringという型で表します。
ということで、マルチバイト文字列とワイド文字列とを相互に変換する関数をつくりました。
参考 wstringをstringへ変換する(わびさびサンプルソース)
参考 stringをwstringへ変換する(わびさびサンプルソース)
# include <stdio.h>
# include <tchar.h>
# include <locale.h>
# include <iostream>
# include <string>
# include <windows.h>
std::string WstrToStr(std::wstring str) { //ワイド文字列 -> マルチバイト文字列
int iBufferSize = WideCharToMultiByte(CP_OEMCP, 0, str.c_str(), -1, (char*)NULL, 0, NULL, NULL);
CHAR* cpMultiByte = new CHAR[iBufferSize];
WideCharToMultiByte(CP_OEMCP, 0, str.c_str(), -1, cpMultiByte, iBufferSize, NULL, NULL);
std::string ret(cpMultiByte, cpMultiByte + iBufferSize - 1);
delete[] cpMultiByte;
return(ret);
}
std::wstring StrToWstr(std::string str) { //マルチバイト文字列 -> ワイド文字列
int iBufferSize = MultiByteToWideChar(CP_ACP, 0, str.c_str(), -1, (wchar_t*)NULL, 0);
wchar_t* cpUCS2 = new wchar_t[iBufferSize];
MultiByteToWideChar(CP_ACP, 0, str.c_str(), -1, cpUCS2, iBufferSize);
std::wstring ret(cpUCS2, cpUCS2 + iBufferSize - 1);
delete[] cpUCS2;
return(ret);
}
LuaからDLLを呼び出す
Lua側からDLLの関数を呼び出せるようにしておきます。
今回、プラグインの名前はtextmoduleとしてみました。
# include <lua.hpp>
static luaL_Reg functions[] = {
{ nullptr, nullptr }
};
extern "C" {
__declspec(dllexport) int luaopen_textmodule(lua_State* L) {
luaL_register(L, "textmodule", functions);
return 1;
}
}
gsubの実装
C++上でLuaのstring.gsubを再現してみます。
int gsub(lua_State* L) {
//Luaから引数を取得
std::wstring text = StrToWstr(lua_tostring(L, 1));
std::wstring pattern = StrToWstr(lua_tostring(L, 2));
std::wstring repl = StrToWstr(lua_tostring(L, 3));
int num = lua_tointeger(L, 4);
for (int i = 0; i < num; i++) //num回繰り返す
{
std::wsmatch results;
bool l = std::regex_search(text, results, std::wregex(pattern)); //正規表現でtextを検索
if (l) {
int s = results.position(); //patternの現れる位置
int l = results.length(); //patternの長さ
text = text.replace(s, l, repl); //textのpatternをreplで置換
}
else {
break; //text中にpatternがなくなったらfor文を抜ける
}
lua_pushstring(L, WstrToStr(text).c_str()); //Luaに渡す返り値を設定
}
return 1; //返り値の数を指定
}
std::regex_search(std::wstring, std:wsmatch, std::wregex(std::wstring))で検索します。
std::wsmatchに検索結果が渡されるので、.position()と.length()で置換する範囲を取得します。
最後に.replace(int, int, std::wstring)で指定した場所を置換します。
これをnum回繰り返せば完成です。
完成品
最終的に完成したものがこちらです。
# include <lua.hpp>
# include <iostream>
# include <regex>
# include <stdio.h>
# include <tchar.h>
# include <locale.h>
# include <string>
# include <windows.h>
std::string WstrToStr(std::wstring str) {
int iBufferSize = WideCharToMultiByte(CP_OEMCP, 0, str.c_str(), -1, (char*)NULL, 0, NULL, NULL);
CHAR* cpMultiByte = new CHAR[iBufferSize];
WideCharToMultiByte(CP_OEMCP, 0, str.c_str(), -1, cpMultiByte, iBufferSize, NULL, NULL);
std::string oRet(cpMultiByte, cpMultiByte + iBufferSize - 1);
delete[] cpMultiByte;
return(oRet);
}
std::wstring StrToWstr(std::string str) {
int iBufferSize = MultiByteToWideChar(CP_ACP, 0, str.c_str(), -1, (wchar_t*)NULL, 0);
wchar_t* cpUCS2 = new wchar_t[iBufferSize];
MultiByteToWideChar(CP_ACP, 0, str.c_str(), -1, cpUCS2, iBufferSize);
std::wstring oRet(cpUCS2, cpUCS2 + iBufferSize - 1);
delete[] cpUCS2;
return(oRet);
}
int gsub(lua_State* L) {
if (lua_type(L, 1) != LUA_TSTRING) {
return 0;
}
if (lua_type(L, 2) != LUA_TSTRING) {
return 0;
}
if (lua_type(L, 3) != LUA_TSTRING) {
return 0;
}
std::wstring text = StrToWstr(lua_tostring(L, 1));
std::wstring pattern = StrToWstr(lua_tostring(L, 2));
std::wstring repl = StrToWstr(lua_tostring(L, 3));
int num;
if (lua_type(L, 4) == LUA_TNUMBER) {
num = lua_tointeger(L, 4);
}
else if (lua_type(L, 4) == LUA_TNIL) {
num = 1;
}
else {
return 0;
}
for (int i = 0; i < num; i++)
{
std::wsmatch results;
bool l = std::regex_search(text, results, std::wregex(pattern));
if (l) {
int s = results.position();
int l = results.length();
text = text.replace(s, l, repl);
}
else {
break;
}
lua_pushstring(L, WstrToStr(text).c_str());
}
return 1;
}
static luaL_Reg functions[] = {
{"gsub", gsub},
{ nullptr, nullptr }
};
extern "C" {
__declspec(dllexport) int luaopen_textmodule(lua_State* L) {
luaL_register(L, "textmodule", functions);
return 1;
}
}
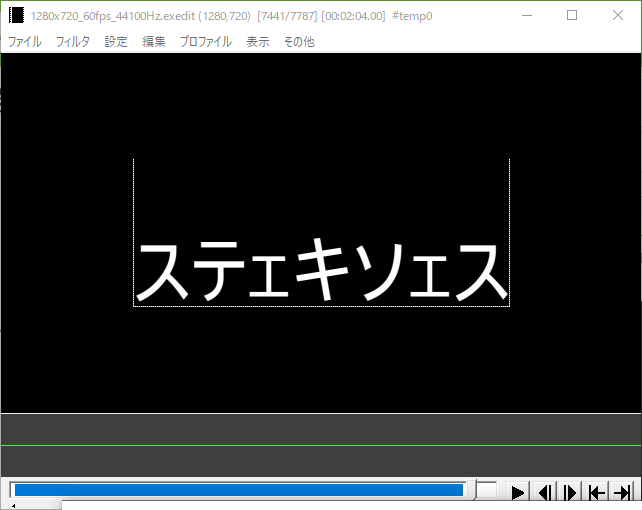
これをAviUtlで呼び出してみると……?
require("textmodule") --DLL呼び出し
steak = textmodule.gsub("ステーキソース", "ー", "ェ", 2)
debug_print(steak) --debug出力する
--画面にテキストとして描画する
obj.load("text", steak)
obj.draw()
このように、無事表示することができました!
最後に
今回つくったtextmoduleですが、
find sub gsub len reverse upper lower matchなどの
他の標準関数も再現してみました(ここで公開しています)。
ワイド文字列で処理を行うと、直感的に文字列を操作できるのでとても便利です。
特に、文字列の長さを取得するlen関数は、実際に表示されている文字数を返してくれるので、とてもわかりやすいです。
(Lua標準のstring.lenはバイト長を返す)
もしAviUtlで日本語の文字列操作を行いたいときは、このようにワイド文字に変換する方法を試してみてください。
追記
ePi様のScrapboxで本記事を取り上げていただいたようです。
LuaのPatternとダメ文字(ePi様、コメントで教えていただいた@yumetodo様、ありがとうございます)
正規表現パターンに[や]が含まれていると、エスケープしてくれるスクリプトです。
コードを__引用__させていただきます(ちょっと改変してます)。
local function safe_pattern(s)
return string.gsub(s, "([\x81-\x9f\xe0-\xfc])([%[%]])","%1%%%2")
end
debug_print( string.gsub("ステーキソース", safe_pattern("ー"), "ェ", 2) ) --ステェキソェス
-- こちらでは AviUtl1.10、exedit0.92、LuaJIT2.0.5にて動作確認しました
-- LuaJIT非使用の環境下では、malformed patternが出て使えないみたいです。
これで動作するようです。
LuaJITなしバージョン
さらに、LuaJIT非使用下でも動作するスクリプトも書いてくださってます(これも少し改変してます)。
local function safe_pattern(str)
local ret = ""
local i , n = 1, #str
while(i<=n)do
ret = ret..string.sub(str, i, i) --処理のできた文字を格納
local byte = string.byte(str, i) --文字コードを取得
if( (0x81<=byte and byte<=0x9f) or (0xe0<=byte and byte<=0xfc) )then --2バイト文字かどうか
i = i + 1
local c = string.sub(str, i, i) --2バイト目の文字を取得
byte = string.byte(c, 1)
if ( byte==0x5b or byte==0x5d ) then -- "["、"]"かどうか
ret = ret.."%" --エスケープ記号を追加
end
ret = ret..c
end
i = i + 1
end
return ret
end
debug_print( string.gsub("ステーキソース", safe_pattern("ー"), "ェ", 2) ) --ステェキソェス
string.byteで1バイトずつ文字コードを取得し、2バイト文字かどうかを判別しています。
Windows-31Jでは、第1バイトが「0x81~0x9F」または「0xE0~0xFC」の場合は2バイト文字です。
Shift JISではまた範囲が異なるので、注意が必要です。
2バイト文字のビット範囲
| Shift JIS | Windows-31J | |
|---|---|---|
| 第1ビット | 0x81~0x9F 0xE0~0xEF |
0x81~0x9F 0xE0~0xFC |
| 第2ビット | 0x40~0x7E 0x80~0xFC |
0x40~0x7E 0x80~0xFC |
上記プログラムでは、2バイト目が"[" "]"(0x5B 0x5D)だったときに、前に%を入れてエスケープさせています。
参考 正規表現(Lua Memo)
この方法は、他の関数や別のダメ文字にも応用できますので、ぜひご参考までに。
参考ページ
Shift_JIS(Wikipedia)
Shift_JISのダメ文字(fudist)
Luaスクリプト「a={八=8}」 AviUtl「よし通れ」 Luaスクリプト「a={九=9}」 AviUtl「通れ」(@Phroneris)
wstringをstringへ変換する(わびさびサンプルソース)
stringをwstringへ変換する(わびさびサンプルソース)
LuaのPatternとダメ文字(ePi)