はじめに
丁度 1 か月前くらいに OCI Data Flow1 で Spark Oracle Datasource というものがリリースされました。本記事では簡単なサンプルプログラムを交えながら機能の概要を見ていきたいと思います。
Spark Oracle Datasource とは?
通常、Spark アプリケーションから Database(DB2/MariaDB/MS Sql/Oracle/PostgreSQL) へアクセスする際は、JDBC Driver をドライバのクラスパスに含めてこんなお作法で実行します。
// Note: JDBC loading and saving can be achieved via either the load/save or jdbc methods
// Loading data from a JDBC source
Dataset<Row> jdbcDF = spark.read()
.format("jdbc")
.option("url", "jdbc:postgresql:dbserver")
.option("dbtable", "schema.tablename")
.option("user", "username")
.option("password", "password")
.load();
Properties connectionProperties = new Properties();
connectionProperties.put("user", "username");
connectionProperties.put("password", "password");
Dataset<Row> jdbcDF2 = spark.read()
.jdbc("jdbc:postgresql:dbserver", "schema.tablename", connectionProperties);
// Saving data to a JDBC source
jdbcDF.write()
.format("jdbc")
.option("url", "jdbc:postgresql:dbserver")
.option("dbtable", "schema.tablename")
.option("user", "username")
.option("password", "password")
.save();
jdbcDF2.write()
.jdbc("jdbc:postgresql:dbserver", "schema.tablename", connectionProperties);
// Specifying create table column data types on write
jdbcDF.write()
.option("createTableColumnTypes", "name CHAR(64), comments VARCHAR(1024)")
.jdbc("jdbc:postgresql:dbserver", "schema.tablename", connectionProperties);
※引用: https://spark.apache.org/docs/latest/sql-data-sources-jdbc.html
これに加えて、Oracle Database への接続に Wallet が必要な場合は、プログラム中で実行時にダウンロードするコードを追加する or Object Storage や OCI Vault にダウンロード済みの Wallet を置いておき実行時に取得する、等の対応が必要でした。この辺りの処理は、ある種お決まりのパターンなので、”Oracle として JDBC Datasource を拡張して Data Flow ユーザーの Oracle Database への接続周りをもっと楽にしよう!”というコンセプトのもと生まれた機能だと思われます。(※個人の推測です)
手順
こんな環境を作ってみます。非常にシンプルですが、load/save のパターンを網羅しておけば後は好きにできると思います。
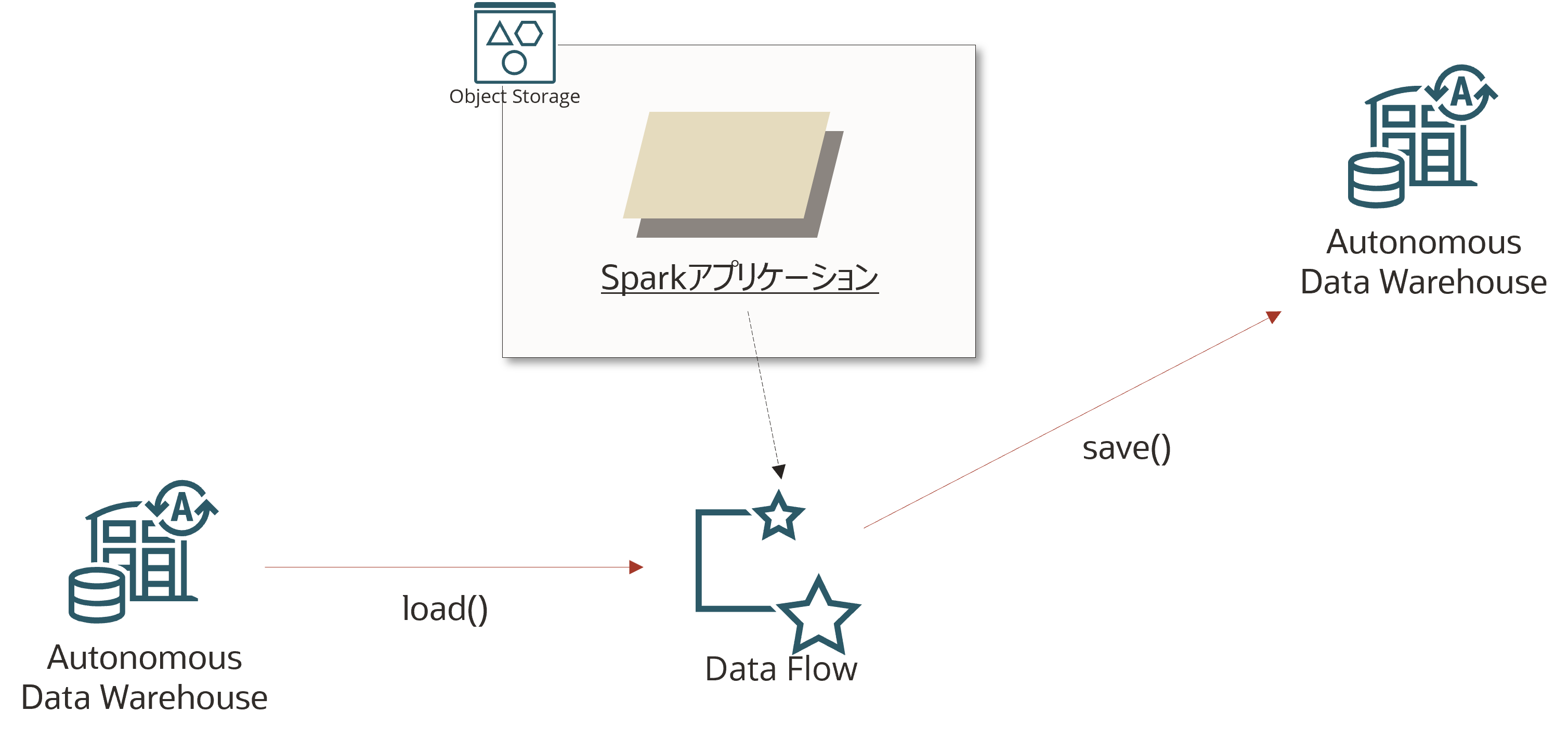
前提
- Autonomous Database(ADW/ATP)が作成済みであること
- Data Flow を使うための事前セットアップが完了していること
サンプルアプリケーションの取得
事前にサンプルアプリケーションを作っておいたので、こちらを使います。
git clone https://github.com/shukawam/oracle-dataflow-examples.git
クローンすると、以下のようになっています。
tree -d -L 1
.
├── spark-etl-java
├── spark-oracle-datasource
└── structured_streaming_kafka_word_count
今回のこの中から、spark-oracle-datasource を使います。src/main/java/me/shukawam/Main.java が Spark アプリケーションの本体となっているのでこちらの解説をします。コードは以下の通り。
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;
import java.util.*;
public class Main {
public static void main(String... args) { // ... 1
SparkSession spark = SparkSession.builder().appName("spark-oracle-datasource").getOrCreate();
Map<String, String> properties = getProperties(args); // ... 2
readWriteAdw(spark, properties); // ... 3
spark.stop();
}
// ... 2
private static Map<String, String> getProperties(String... args) {
Map<String, String> properties = new HashMap<>();
properties.put("adbId", args[0]);
properties.put("username", args[1]);
properties.put("password", args[2]);
properties.put("schema", args[3]);
properties.put("fromTable", args[4]);
properties.put("toTable", args[5]);
return properties;
}
// ... 3
private static void readWriteAdw(SparkSession spark, Map<String, String> properties) {
Map<String, String> defaultOptions = new HashMap<>();
defaultOptions.put("adbId", properties.get("adbId")); // ... 4
defaultOptions.put("user", properties.get("username")); // ... 4
defaultOptions.put("password", properties.get("password")); // ... 4
Dataset<Row> dataset = spark.read()
.format("oracle")
.options(defaultOptions)
.option("dbtable", String.format("%s.%s", properties.get("schema"), properties.get("fromTable")))
.load(); // ... 5
dataset.show();
dataset.write()
.format("oracle")
.options(defaultOptions)
.option("dbtable", String.format("%s.%s", properties.get("schema"), properties.get("toTable")))
.save(); // ... 6
}
}
- Spark アプリケーションのエントリーポイント
- 実行時引数を取得しています。バリデーション処理などは一切含まれていないので参考にする際は適当な処理を追加してください
- ADW からのデータの読み込み、書き込みの処理が実装されています
- Spark Oracle Datasource として共通的に必要なパラメータを定義しています
- adbId: Autonomous Database の OCID を指定します
- username: ADB へ接続する際のユーザー名を指定します
- password: ADB へ接続する際のパスワードを指定します
- 4 で定義したパラメータに加えて、読み込む先のテーブル名を指定し、データをロードします
- 4 で定義したパラメータに加えて、書き込む先のテーブル名を指定し、データを書き込みます
Data Flow アプリケーション2の作成
Data Flow アプリケーションを作成します。以下、OCI CLI で作成しますが、OCI コンソールでも問題なく実施可能です。
まずは、Spark アプリケーションをビルドします。
cd spark-oracle-datasource
./mvnw package
target/spark-oracle-datasource-1.0-SNAPSHOT.jar が存在することを確認します。
ls target/ | grep -i spark-oracle
spark-oracle-datasource-1.0-SNAPSHOT.jar
Data Flow はアプリケーションアーカイブを Object Storage から読み込むため、これを任意のバケットにアップロードします。
oci os object put \
--bucket-name <your-bucket> \
--file target/spark-oracle-datasource-1.0-SNAPSHOT.jar
確認します。
oci os object list \
--bucket-name <your-bucket> \
--query 'data[?name==`spark-oracle-datasource-1.0-SNAPSHOT.jar`]'
以下のような結果が返ってくれば OK です。
[
{
"archival-state": null,
"etag": "08e98a4d-fffb-41b3-a49b-ea463af4cdc0",
"md5": "/QQbEecE24UkmMwCJRbGCw==",
"name": "spark-oracle-datasource-1.0-SNAPSHOT.jar",
"size": 3325,
"storage-tier": "Standard",
"time-created": "2022-04-22T06:08:04.034000+00:00",
"time-modified": "2022-04-22T06:08:04.034000+00:00"
}
]
次に、Data Flow アプリケーションを作成します。(--configuration spark.oracle.datasource.enabled=true を含めないと、Oracle JDBC Driver や Wallet をダウンロードするために必要な依存関係が追加されないので、処理に失敗します)
oci data-flow application create \
--compartment-id $COMPARTMENT_ID \
--display-name "Spark Oracle Datasoruce example" \
--driver-shape VM.Standard2.1 \
--executor-shape VM.Standard2.1 \
--file-uri oci://<your-bucket>@<object-storage-namespace>/spark-oracle-datasource-1.0-SNAPSHOT.jar \
--language JAVA \
--num-executors 1 \
--spark-version 3.0.2 \
--class-name me.shukawam.Main \
--configuration spark.oracle.datasource.enabled=true
--arguments "<adbId> <username> <password> <schema> <fromTable> <toTable>"
実行すると以下のような結果が返ってきます。(一部情報をマスクしています)
{
"data": {
"archive-uri": "",
"arguments": [
"<adbId>",
"<username>",
"<password>",
"<schema>",
"<fromTable>",
"<toTable>"
],
"class-name": "me.shukawam.Main",
"compartment-id": "ocid1.compartment.oc1...",
"configuration": {
"spark.oracle.datasource.enabled": "true"
},
"defined-tags": {},
"description": null,
"display-name": "Spark Oracle Datasoruce example",
"driver-shape": "VM.Standard2.1",
"execute": null,
"executor-shape": "VM.Standard2.1",
"file-uri": "oci://<your-bucket>@<object-storage-namespace>/spark-oracle-datasource-1.0-SNAPSHOT.jar",
"freeform-tags": {},
"id": "ocid1.dataflowapplication.oc1.ap-tokyo-1...",
"language": "JAVA",
"lifecycle-state": "ACTIVE",
"logs-bucket-uri": "oci://dataflow-logs@<object-storage-namespace>/",
"metastore-id": null,
"num-executors": 1,
"owner-principal-id": "ocid1.user.oc1...",
"owner-user-name": "oracleidentitycloudservice/...",
"parameters": null,
"private-endpoint-id": "",
"spark-version": "3.0.2",
"time-created": "2022-04-22T06:49:32.917000+00:00",
"time-updated": "2022-04-22T06:49:32.917000+00:00",
"type": "BATCH",
"warehouse-bucket-uri": null
}
}
作成したアプリケーションを実行します。
oci data-flow run create \
--application-id ocid1.dataflowapplication.oc1.ap-tokyo-1... \
--display-name "Spark Oracle Datasource" \
--compartment-id $COMPARTMENT_ID
以下のような結果が返ってきます。
{
"data": {
"application-id": "ocid1.dataflowapplication.oc1.ap-tokyo-1...",
"archive-uri": "",
"arguments": [
"<adbId>",
"<username>",
"<password>",
"<schema>",
"<fromTable>",
"<toTable>"
],
"class-name": "me.shukawam.Main",
"compartment-id": "ocid1.compartment.oc1...",
"configuration": {
"spark.oracle.datasource.enabled": "true"
},
"data-read-in-bytes": 0,
"data-written-in-bytes": 0,
"defined-tags": {},
"display-name": "Spark Oracle Datasource",
"driver-shape": "VM.Standard2.1",
"execute": "",
"executor-shape": "VM.Standard2.1",
"file-uri": "oci://<your-bucket>@<object-storage-namespace>/spark-oracle-datasource-1.0-SNAPSHOT.jar",
"freeform-tags": {},
"id": "ocid1.dataflowrun.oc1.ap-tokyo-1...",
"language": "JAVA",
"lifecycle-details": null,
"lifecycle-state": "ACCEPTED",
"logs-bucket-uri": "oci://dataflow-logs@<object-storage-namespace>/",
"metastore-id": null,
"num-executors": 1,
"opc-request-id": "53A91AF5B456458184FC2CF15F50F78F/E46BEC96C00E400DEFB16F469723D794",
"owner-principal-id": "ocid1.user.oc1...",
"owner-user-name": "oracleidentitycloudservice/...",
"parameters": null,
"private-endpoint-dns-zones": null,
"private-endpoint-id": null,
"private-endpoint-max-host-count": null,
"private-endpoint-nsg-ids": null,
"private-endpoint-subnet-id": null,
"run-duration-in-milliseconds": 0,
"spark-version": "3.0.2",
"time-created": "2022-04-22T06:58:56.293000+00:00",
"time-updated": "2022-04-22T06:58:56.293000+00:00",
"total-o-cpu": 2,
"type": "BATCH",
"warehouse-bucket-uri": ""
}
}
コンソールを確認し、実行が完了したら、toTable で指定したテーブル内のデータを参照し、fromTable と同様のものが出力されれば OK です!
参考
- Release Note - Data Flow Adds Spark Oracle Datasource Functionality
- OCI Document - Spark Oracle Datasource