はじめに
LLM を用いたアプリケーション開発や運用時には、生成途中のプロンプトが期待通りになっているのか?、複数提供しているツールから正しいツールを使えているのか?、一連の処理の中でどの処理に時間を要しているのか?、一連の処理を実行するのに一体いくらコストがかかっているのか?、LLM が生成した回答をユーザーはどのように評価しているのか?など、ということが知りたくなります。
LLM アプリケーションでオブザーバビリティを確保するために必要となる機能群を提供するプラットフォームとして Langfuse というものがありますので、本記事では OCI Generative AI Service と LangChain(LangGraph) と Langfuse を組み合わせて LLM アプリケーションのトレースを確認してみます。
Langfuse はなにものなのか?
前述した通り、LLM アプリケーション運用の営みで必要となる機能群を提供するプラットフォームです。具体的には以下のような機能が提供されています。
| 機能 | 概要 | Self-hosted | Managed |
|---|---|---|---|
| オブザーバビリティ | LLM アプリケーションの計装 + トレース情報の連携 | ○ | ○ |
| プロンプト管理 | プロンプトのバージョン管理、デプロイ | ○ | ○ |
| プロンプトエンジニアリング | プロンプトのテストが可能 | × | ○ |
| 分析 | LLM の推論実行にかかったコスト、レイテンシ等がダッシュボードから確認可能 | ○ | ○ |
| 評価 | LLM が生成した回答に対するスコアの収集と評価が可能 | △(評価は非対応) | ○ |
| テスト | データセット(入力と期待される回答)に対してベンチマークが可能 | ○ | ○ |
これらの機能をアプリケーションに組み込むために専用の SDK(Python, JavaScript/TypeScript)や LangChain, LlamaIndex との統合機能などが提供されています。今回は、LangChain から OCI Generative AI Service を使い、トレース情報を取得してみます。
Langfuse のインストール
で記されている通り、Docker で簡単に起動することができます。
docker container run --name langfuse \
-e DATABASE_URL=postgresql://hello \
-e NEXTAUTH_URL=http://localhost:3000 \
-e NEXTAUTH_SECRET=mysecret \
-e SALT=mysalt \
-p 3000:3000 \
-a STDOUT \
langfuse/langfuse
また、ドキュメントには記載がありませんが コミュニティメンテナンスされている Helm Chart がありますので、Kubernetes 上でも簡単に動作させることができます。
helm repo add langfuse https://langfuse.github.io/langfuse-k8s
helm repo update
helm install langfuse langfuse/langfuse
実際に試してみる
前提
本記事で試す環境は、以下の前提で動作確認をしています。
- Python: 3.11.7
- OCI SDK for Python 2.133.0
- LangChain: 0.2.16
- Langfuse: 2.36.0
トレースを取得する全体の処理イメージ
以下のような Agent を作成します。LLM(OCI Generative AI Service - cohere.command-r-plus)には、ツールとして、自然言語を SQL に変換し、その変換された SQL を持って実際に Autonomous Database にクエリを発行し、その結果を返すようなツール(いわゆる、Text-to-SQL)をバインドしています。
+-----------+
| __start__ |
+-----------+
*
*
*
+-------+
| agent |
+-------+
* .
** ..
* .
+-------+ +---------+
| tools | | __end__ |
+-------+ +---------+
Agent 部分の実装
ポイントをかいつまんで紹介するため、ノートブック全体は以下をご参照ください。
今回は以下の様な従業員テーブルとサンプルデータを事前に用意し、そちらを使用します。
import oracledb
with oracledb.connect(
dsn=dsn,
user=username,
password=password,
config_dir=config_dir,
wallet_location=wallet_dir,
wallet_password=wallet_password
) as connection:
with connection.cursor() as cursor:
create_table_statement = """
CREATE TABLE IF NOT EXISTS EMPLOYEE (
EMPLOYEE_ID NUMBER PRIMARY KEY, -- 社員番号
NAME VARCHAR2(100), -- 従業員名
GENDER VARCHAR2(10), -- 性別
DEPARTMENT VARCHAR2(50), -- 部署
POSITION VARCHAR2(50), -- 役職
DETAILS VARCHAR2(255) -- 詳細情報
)
"""
# テーブル作成
cursor.execute(
statement=create_table_statement
)
# ダミーデータの用意
sample_data = [
(1, "佐藤 太郎", "男性", "営業", "マネージャー", "経験豊富な営業マネージャー"),
(2, "鈴木 次郎", "男性", "開発", "エンジニア", "AI開発に従事"),
(3, "田中 花子", "女性", "人事", "リーダー", "採用業務を担当"),
(4, "山田 太一", "男性", "マーケティング", "スペシャリスト", "デジタルマーケティング担当"),
(5, "高橋 美咲", "女性", "開発", "エンジニア", "クラウドインフラのスペシャリスト"),
(6, "井上 一郎", "男性", "営業", "チームリーダー", "営業部のチームリーダーで、大手企業向けの営業を担当"),
(7, "小林 明美", "女性", "開発", "シニアエンジニア", "ソフトウェアアーキテクチャ設計の経験豊富"),
(8, "森田 健太", "男性", "サポート", "カスタマーサポート", "製品サポートの専門家"),
(9, "中村 優子", "女性", "経理", "経理担当", "会社全体の経理業務を担当"),
(10, "藤田 一華", "女性", "営業", "アシスタント", "営業部のサポート業務を担当"),
(11, "山本 翔太", "男性", "開発", "ジュニアエンジニア", "新卒エンジニアで、AIプロジェクトに参画中"),
(12, "加藤 美和", "女性", "人事", "人事アシスタント", "人事データの管理や、採用サポートを担当"),
(13, "佐々木 健", "男性", "マーケティング", "マーケティングアナリスト", "市場調査とデータ分析を担当"),
(14, "斎藤 美紀", "女性", "営業", "フィールドセールス", "顧客訪問やプレゼンテーションを担当"),
(15, "大野 智", "男性", "開発", "データサイエンティスト", "ビッグデータ分析と機械学習モデルの構築を担当"),
]
# データ挿入
cursor.executemany(
statement=insert_sample_data_statement,
parameters=sample_data
)
まずは、LLM に使用させるツールを以下の様に実装します。なお、今回は自然言語から SQL への変換に Autonomous Database の機能である SELECT AI を活用しています。セットアップ手順については、以下ドキュメントや有志によるブログ記事が参考になりました。
from langchain_core.tools import tool, Tool
@tool
def nl_to_sql(query: str) -> list:
"""自然言語をSQLに変換(SELECT AI使用)し、そのSQLを実行し結果を返します"""
with oracledb.connect(
dsn=dsn,
user=username,
password=password,
config_dir=config_dir,
wallet_location=wallet_dir,
wallet_password=wallet_password
) as connection:
with connection.cursor() as cursor:
set_ai_profile_statement = """
BEGIN
DBMS_CLOUD_AI.SET_PROFILE(
profile_name => 'OCI_GENERATIVE_AI'
);
END;
"""
cursor.execute(
statement=set_ai_profile_statement
)
statement = f"SELECT AI RUN {query}"
cursor.execute(statement=statement)
result = cursor.fetchall()
return result
tools = [
Tool(
name="nl_to_sql",
func=nl_to_sql,
description="""
従業員テーブルに対する自然言語の問い合わせをSQLに変換したのち、そのSQLの実行結果を返します。
特定の条件に当てはまる従業員を検索する際や、数の集計時に役にたつツールです。
"""
)
]
作成したツールをバインドするように ChatModel を定義します。
from langchain_community.chat_models.oci_generative_ai import ChatOCIGenAI
chat = ChatOCIGenAI(
auth_type="INSTANCE_PRINCIPAL",
service_endpoint="https://inference.generativeai.us-chicago-1.oci.oraclecloud.com",
compartment_id=<compartment_id>,
model_id="cohere.command-r-plus",
is_stream=True,
model_kwargs={
"temperature": 0,
"max_tokens": 2500,
"top_p": 0.75,
"top_k": 0,
"frequency_penalty": 0,
"presence_penalty": 0
}
).bind_tools(tools=tools)
Agent のグラフ構造を定義します。
# ツールノード
tool_node = ToolNode(
tools=tools,
name="demo-tools",
tags=["text-to-sql"]
)
from typing import Literal, List
from langgraph.checkpoint.memory import MemorySaver
from langgraph.graph import END, StateGraph, MessagesState
# Agentノードの定義
def should_continue(state: MessagesState) -> Literal["tools", END]:
messages = state["messages"]
last_message = messages[-1]
if last_message.tool_calls:
return "tools"
return END
def call_model(state: MessagesState):
messages = state["messages"]
response = chat.invoke(messages)
return {"messages": [response]}
# StateGraphの定義
workflow = StateGraph(MessagesState)
workflow.add_node("agent", call_model)
workflow.add_node("tools", tool_node)
workflow.set_entry_point("agent")
workflow.add_conditional_edges("agent", should_continue)
workflow.add_edge("tools", "agent")
checkpointer = MemorySaver()
app = workflow.compile(checkpointer=checkpointer)
この Agent を実行してみると、期待通り 15 人という数字が出力されました。
import uuid
from langchain_core.prompt_values import HumanMessage
session_id = str(uuid.uuid4())
result = app.invoke(
input={
"messages": [
HumanMessage(content="従業員は何人いますか?")
]
},
config={
"configurable": {
"thread_id": session_id
}
}
)
print(result["messages"][-1].content) # >> 15人です。
Langfuse を用いたトレース情報の取得
前述した Agent は非常にシンプルな実装だったのと質問も単純だったため、期待通りのテキストを生成してくれました。しかし、これが Agent にバインドしているツールが多数あり、複雑な質問をした場合かつ期待通りのテキストが返却されなかった場合を考えてみましょう。この場合は、テキストが最終的に生成されるまでのどのフェーズが期待通りでなかったのか?という情報を頼りに改善アプローチを実施するでしょう。また、期待通りのテキストが返却されたとしても回答が生成されるまでに非常に時間がかかっている場合は、同様にどこの処理が支配的なのか?という情報を参照し、それを解決するための手段を検討する、ということを行うのではないでしょうか?このような活動を行うために必要な情報をある程度自動で収集してくれる + 可視化してくれるのが Langfuse ってわけです。
LangChain から使う場合は、LangChain の Callback システムに Langfuse の実装を渡してあげるだけで、(チェーンや)Agent の実行ステップに対してトレース情報を取得してくれます。
from langfuse.callback import CallbackHandler
# LangChainのCallbackシステム用のLangfuse実装
langfuse_handler = CallbackHandler(
secret_key=secret_key,
public_key=public_key,
host=langfuse_host,
sample_rate=1.0 # for demo
)
session_id = str(uuid.uuid4())
result = app.invoke(
input={
"messages": [
HumanMessage(content="従業員は何人いますか?")
]
},
config={
"configurable": {
"thread_id": session_id
},
"callbacks": [langfuse_handler] # LangChainのCallbackシステムにLangfuseの実装を渡してあげるだけ
}
)
print(result["messages"][-1].content) # >> 15人です。
Langfuse のコンソールではどのような情報が参照可能なのか
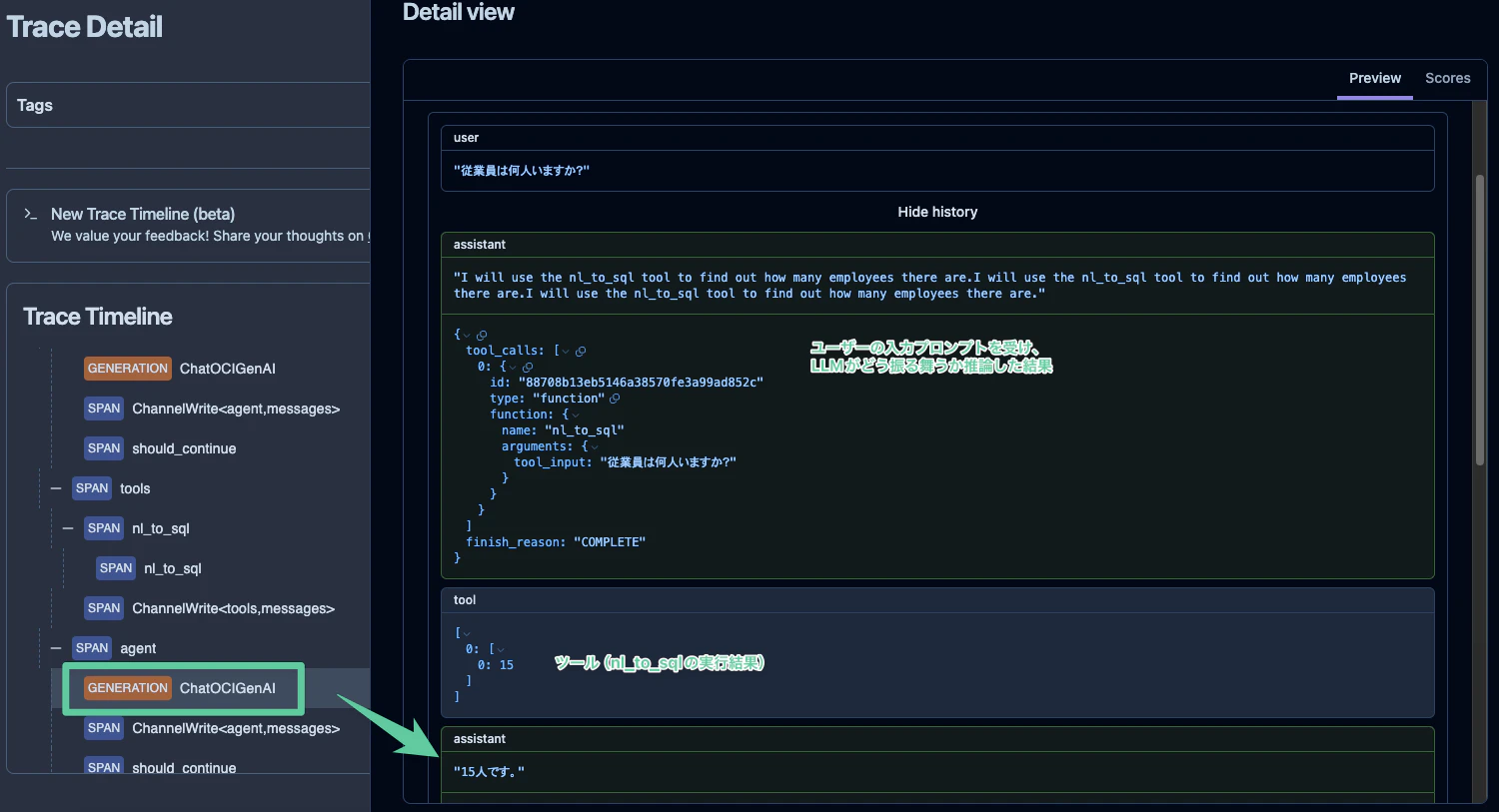
先ほどの Agent に対して、「従業員は何人いますか?」と問い合わせた時どのような処理が行われていたのか確認してみると、単純そうに見えて実は色々な処理がされていたことがわかります。

簡単に解説すると、最初の GENERATION(LLM の生成タスク用の特別なスパン)では、ユーザーが入力した「従業員は何人いますか?」という問いに対して、どう振る舞うべきかを推論しています。

中身を確認すると、「I will use the nl_to_sql tool to find out how many employees there are.」と生成されており、ユーザーの入力プロンプトに対して、nl_to_sql というツールを 従業員は何人いますか? というパラメータを与えて実行すれば良いと推論しています。これに対して、LLM の推論結果に tool_calls というパラメータが含まれていますので、ツールノードに処理が移譲されます。
実際に nl_to_sql が実行されると、15 という結果が返ってきていることがわかります。

最後にもう一度、LLM の推論が実行されます。この時には、ツールの実行結果が LLM にきちんと連携された上でテキスト生成が行われていることが確認できます。
終わりに
今回は、LLM オブザーバビリティの中でもトレース情報を Langfuse を使って収集してみました。収集するべき情報はまだまだたくさんありますので、その辺りは別記事などで触れられればと思います。
参考