はじめに
三体Ⅲが発売されましたが、皆さんもう読みましたか?
僕は発売日当日にKindleで購入したものの、全然読めていません。
このままだと永遠に読み終わらない危機感を感じまして、
読む時間がないならせめて「ながら聴き」したいと思いました。
しかしAudibleはまだ販売されておらず、
販売されたとしても上下合わせてで9,000円とかなり高額です。
また、スマホの設定でも読み上げることは可能ですが、
スマホが使いづらくなるので不採用です。
そこで、お金をかけずにPC上でKindleを読み上げる方法を実現したので紹介します。

特記
途中でKindleのスクリーンショットを行いますが、
スクリーンショット自体の違法性は無いようです。
ただし、あくまでも所有者本人のみが利用することに限る話であり、
アップロードしたり他人に渡したりするのは違法となりますのでご注意ください。
環境
環境は以下になりますが、Windowsでも同じような方法で実現できると思います。
- macOS 10.15.7(19H1217)
- Google Colaboratory(以降、Colab)
- Google Drive(以降、Drive)
パイプライン
自分でモデル作るなども面白い取り組みですが、
その時間で三体Ⅲを読了できてしまいそうなので、
ネットに転がっている物を使いました。
パイプラインは下記になります。
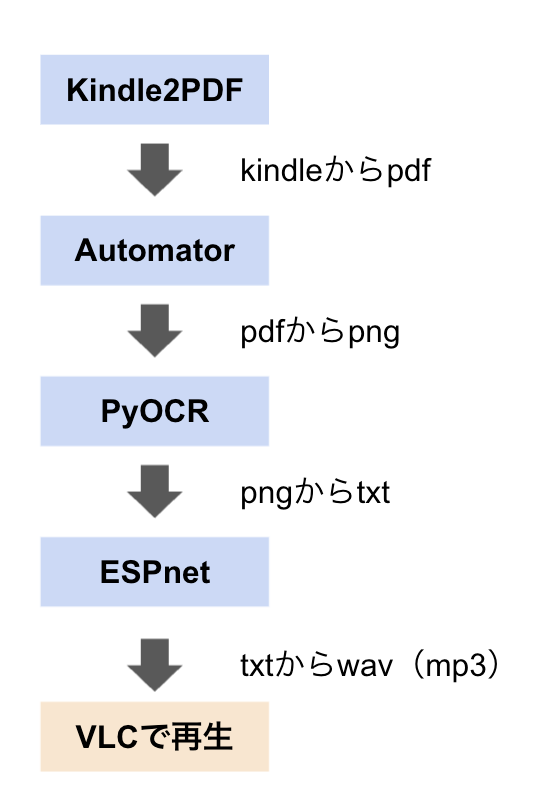
パイプラインなんてかっこつけた言葉を使ってしまいましたが、がっつり人の手が入ります。
Kindle2PDF
まずは、Kindle2PDFを使って、KindleをPDF化を作成します。
使い方はREADME.mdを読めばわかると思います。
なお、Kindle2PDFはあくまでキャプチャ画像をPDFにするだけであって、OCRは行いません。
OCRについては後段の処理で行います。
また、ソースの一部(この辺)を改修して直接PNGを出力することで、後段のAutomatorを省略することができます。
# 別プロセスで画像の保存とページめくりを行うので,
# ちゃんと前のキャプチャが保存されるかを確認する
if self.previous_timestamp is not None:
if self.previous_timestamp == cap.get_current_timestamp():
time.sleep(3.0)
# キャプチャ画像を取得
crop_img = cap.crop_capture()
# 前ページと同じかどうかチェック
# 同じ場合は終了
if i > 0 and is_same_img(current_img, crop_img):
print("Done because of same image.")
break
Automator
PDFからpng画像を出力します。
その他フリーソフトでも同様のことができると思いますが、今回はAutomatorにて行いました。
参考にしたサイトは下記になります。
とても丁寧に書かれているので、記事のまま設定すれば迷うことは無いと思います。
PyOCR
各png画像に対して文字認識を行います。
ここからはDrive上にpng画像を格納して、Colab上で実行します。
入出力は以下のようになります。
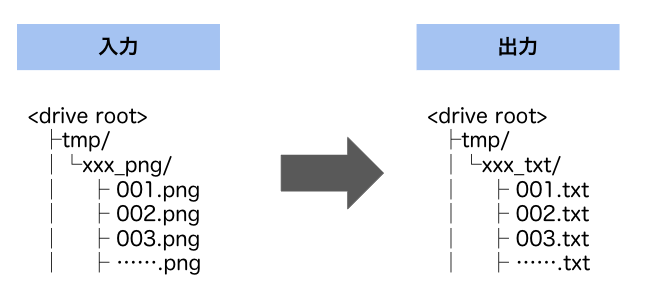
実際はDrive上の任意場所で構いませんが、
今回作成したColabでは上記構成を前提に実装しています。
OCRにはPyOCRを利用しており、内部でTesseractを実行しています。
なお、三体(含む、多くの小説)は縦書きですが、縦書きの場合は、
予め縦書き用のモデルである「jpn_vert」をダウンロードする必要があるのがポイントです。
Colabは以下に置いています。
ESPnet
各文字認識結果に対して音声合成を行います。
前段で出力したDrive上のtxtから、mp3を作成します。
入出力は以下のようになります。
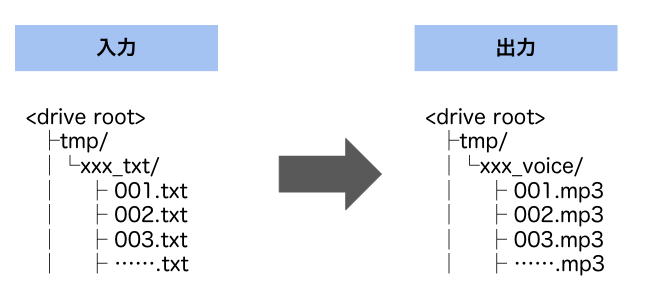
音声合成には、ESPnetを利用しました。
https://github.com/espnet/espnet
さらにpydubを利用して、句点の際に無音を入れて間を開けることで、
多少自然な読み上げになるようにしました。
ついでに容量圧縮のためにmp3形式で保存もしています。
colabは下記です。
VLCで再生
mp3プレイヤーはなんでもよいのですがすでに持っていたVLCを利用して再生しました。
とりあえずVLCに作成したmp3をドロップして、順番に再生するだけです。
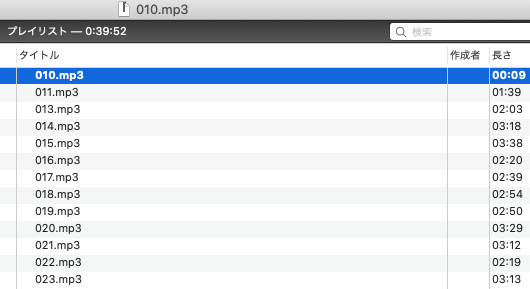
スクショを撮ったページごとに、mp3ファイルを分けて再生することで、
どこまで再生したかがわかりやすくなります。
通勤通学中に聴いた続きから、Kindleで読むということもしやすくなるとおもいます。
感想
実際にK2Sにて三体Ⅲを聴いてみましたが、以下の問題点がありました。
- 人物名がおかしい(面白い)
- ふりがな部分がおかしい
- ながら聴きできるような易しい小説じゃない
だいたい予想していたとおりではありますが、
読むとなると多分ずっと読み終えることができなかったはずなので、良かったのかなあ。。。という感じです。
その他、図や数式が含まれている書籍はうまく行かないなど、利用にはいろいろ制限がありますが、
小説などの読み物系について、ながら聴きで空気感を味わうには使えると判断しました。
おわりに
こうして無事三体Ⅲをながら聴きすることができました。
他の小説をながら聴きする際も同じ手順を行う必要があり多少面倒なので、
できれば人の手が入らない方法を実現したいのですが、
音声合成の際に、処理速度的にGPUが必要なので、我が家では実現できておりません。
高スペックなGPUマシンをお持ちの方はぜひ、一気通貫した方法を実現してみてください。