この本の第6章をまとめたものです
Pipelineクラス
- scikit-learnの変換器と推定器を結合して、関数呼び出しをすっきりとさせる
- 変換器:StandardScaler(標準化), PCA(次元削減)
- .fit() --> データの統計的性質を取得してメモリに保存
- .transform() --> それをもとにデータの値をいじくる
- 推定器:LogisticRegression(回帰)
- .fit() --> トレーニングデータを学習してモデルをfitさせる
- .predict() --> テストデータをpredict
モデルの選択
-
ハイパーパラメータの最適化
- トレーニングの前に決めておく値
- 例えばADALINEのコスト関数を最小化するための勾配降下法で登場した学習率$ \gamma $(36ページ)
ホールドアウト法
- モデル同士の優劣を決めるには、トレーニングデータのみならずテストデータも用いて正解率を出すことにより評価する必要がある
- ただこの方法だと、特定のテストデータに適したモデルが選択されることになるので、過学習を防ぐため最終的な性能評価にはまた別のテストデータが必要となる
- そこでトレーニングデータセットの一部を、モデル選択時のテストに用いることにし、これを検出データセットと呼ぶ
- ただしここでの分け方によって性能の評価が変わってくるかもしれない。そこで...
k分割交差検証
- トレーニングデータセットをk分割し、そのうち一つを非復元抽出(取ったあとツボに戻さない方)で選んで検出データセットとする、というのをk回繰り返し、k回の正解率(or誤り率)の平均を性能の評価とする
- 納得のいく正解率をだすハイパーパラメータを見つけたら、トレーニングデータセット全体で改めて学習し直す
- 層化k分割交差検証
- k分割したデータセットそれぞれでクラスの偏りができないような分割をすることでほんのり改善
バイアスとバリアンスの診断
復習(3章)
- バイアスが高い=学習不足
- モデルの複雑さがデータのパターンを捕捉するには不十分
- パラメータをもっと増やすと良い
- バリアンスが高い=過学習
- 逆にデータに対してモデルが複雑すぎる
- パラメータを減らすか、トレーニングデータを増やしてみる
学習曲線

検証曲線
- バイアス、バリアンスの判定基準は学習曲線と同じで、横軸をモデルのハイパーパラメータとしたものである
- ここではロジスティック回帰の正則化パラメータC(74ページ)
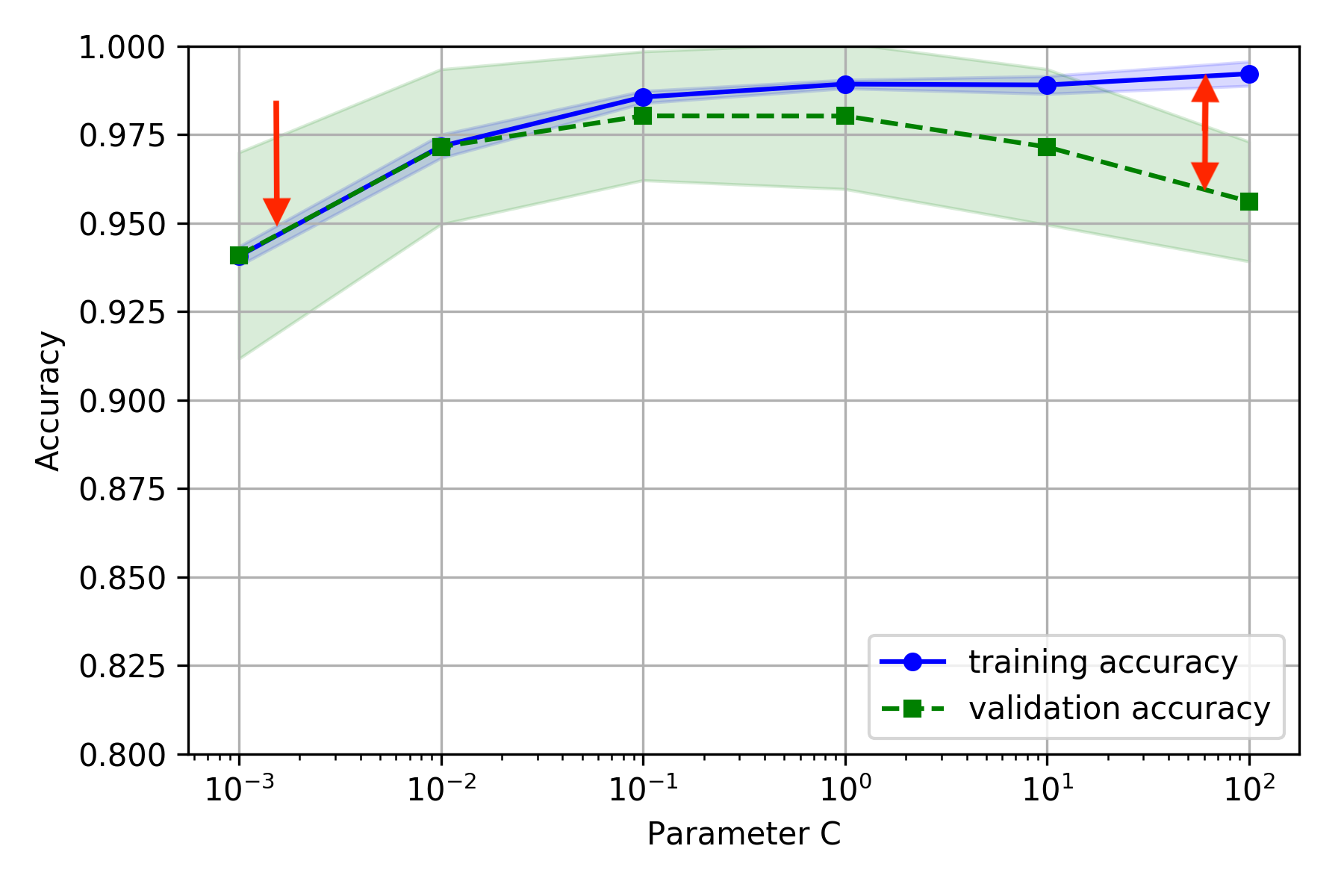
- ここではロジスティック回帰の正則化パラメータC(74ページ)
グリッドサーチ
ハイパーパラメータが複数ある場合などに、様々な値の組合せを愚直に調べて最適な組合せを探す方法だが、考えられるすべての組合せを調べようとすると計算コストがすごいことになる
入れ子式の交差検証
- まずデータセット全体をk1分割する
- そのうち1つをテストデータセットとし、残りのデータをトレーニングデータセットとする
- k2分割交差検証を行う(トレーニングデータセットをk2等分して1つを検証データセットとする×k2回)
- 1~3をk1回繰り返す
- 複数のアルゴリズム同士の比較の際に推奨されるらしい
様々な性能評価指標
混同行列
 これらの四則演算により様々な性能評価指標が求まる(適合率、再現率、F1スコア等)(全部scikit-learnにあるよ)
これらの四則演算により様々な性能評価指標が求まる(適合率、再現率、F1スコア等)(全部scikit-learnにあるよ)
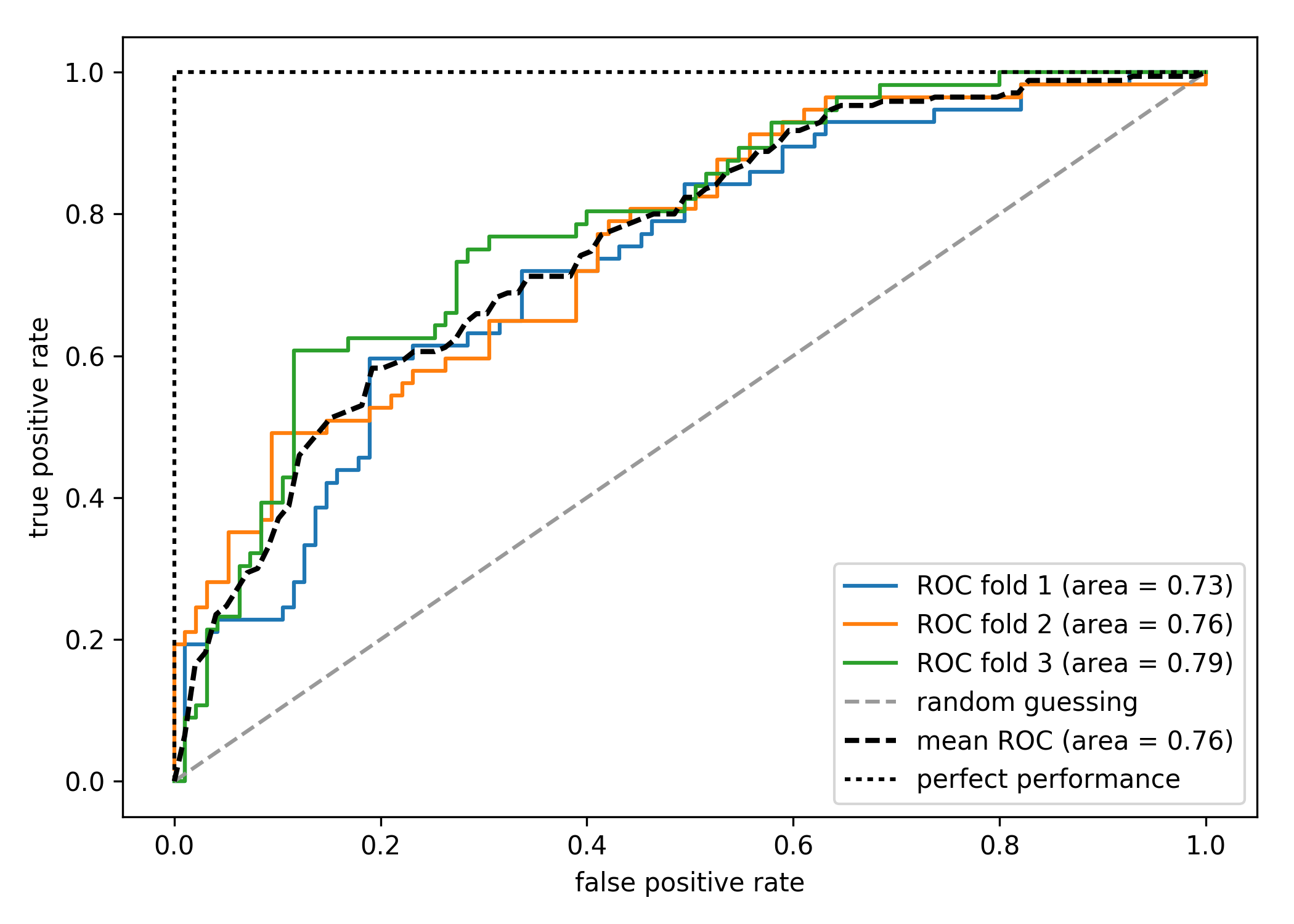
ROC曲線
- 陽性か陰性かの判断に用いるしきい値を0から1まで変化させた時の真陽性率と偽陽性率の変化をプロットしたもの
- 真陽性率は正解が陽性だった時に陽性と判定する条件付き確率
- 偽陽性率は正解が陰性だった時に陽性と判定する条件付き確率
- 偽陽性率に対して真陽性率が高ければ高いほどいいので、グラフが対角線より上に来て、左や上の辺に張り付くほどいいモデルだと言える
- よって曲線下面積AUCは性能の指標となる
- この手法はおなじみの一体全の考え方により多クラス問題にも拡張可能らしい
クラスに偏りがある場合
- 正解率は万能ではない
- 機械の故障の点検では、故障なしのデータの割合が圧倒的に多いので、必ず正常と答えるモデルはものすごい正解率を叩き出してしまう
- だからこそ色々な性能評価指標が提案されている
- アルゴリズムによってはコスト関数や報酬を各トレーニングサンプルに対する合計値としているが、これだと偏りがある場合に多数決になってしまう
- 少数ラベルへの誤った予測には大きなペナルティを課す、などの工夫が必要
- scikit-learnでclass_weight='balanced'とするだけでいいそうで
- 色々方法はあるが、万能な解決策はないっぽい
- その都度頑張る