この記事はBrainPad Advent Calendar11日目の記事です
音声認識において、ニューラルネットワークを用いたモデルが高い性能を出して業界が騒然となった2010年から2012年。あれから約10年が経ったということで、音声認識におけるニューラルネットワークについてまとめてみました。
改めて音声認識について
音声認識とは「音声に含まれる意味内容に関する情報(言語情報)を、コンピュータによって抽出し、判定すること」1です。音声認識は人間で例えると耳と脳の処理の一部に相当します。具体的には、空気中の圧力変化である音を入力して、日本語や英語などの自然言語情報+感情表現情報を認識します。ちなみに、声を発声する時には頭の中で自然言語を考えて、肺や声帯などの調音機構を絶妙な調整を行って音として出力します。これらの処理の連鎖であるSpeech chainの様子を下図に示します(2から引用)。
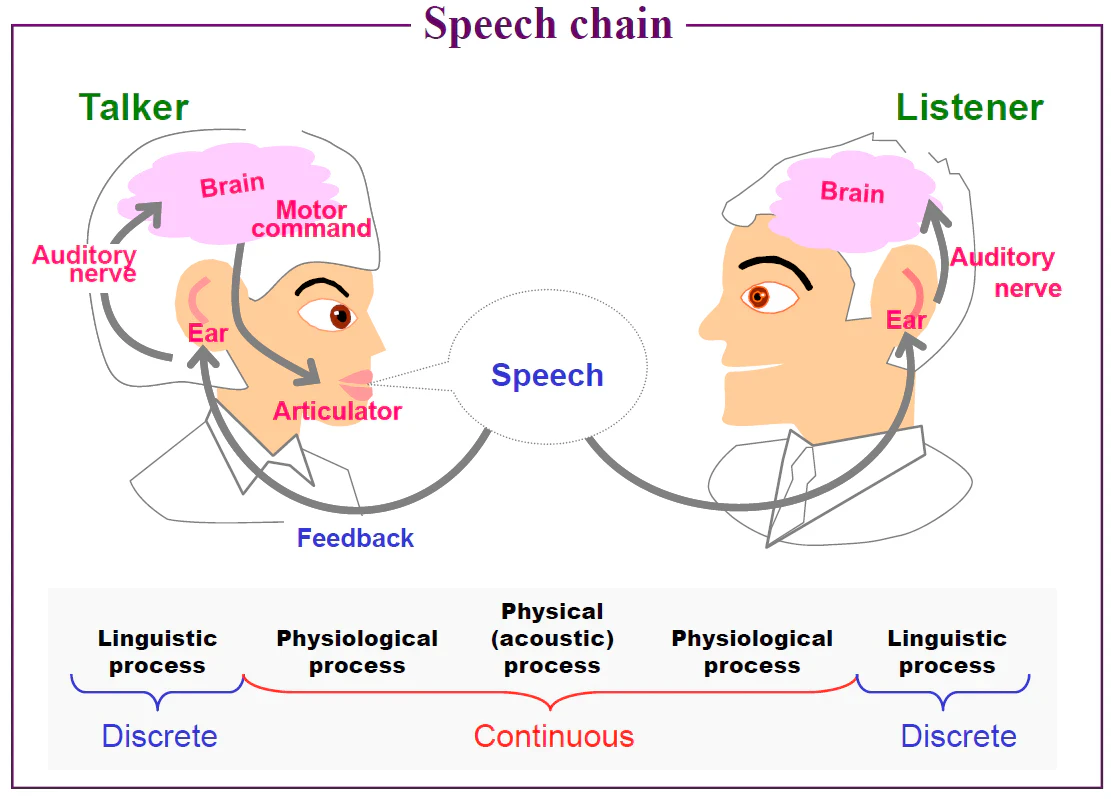
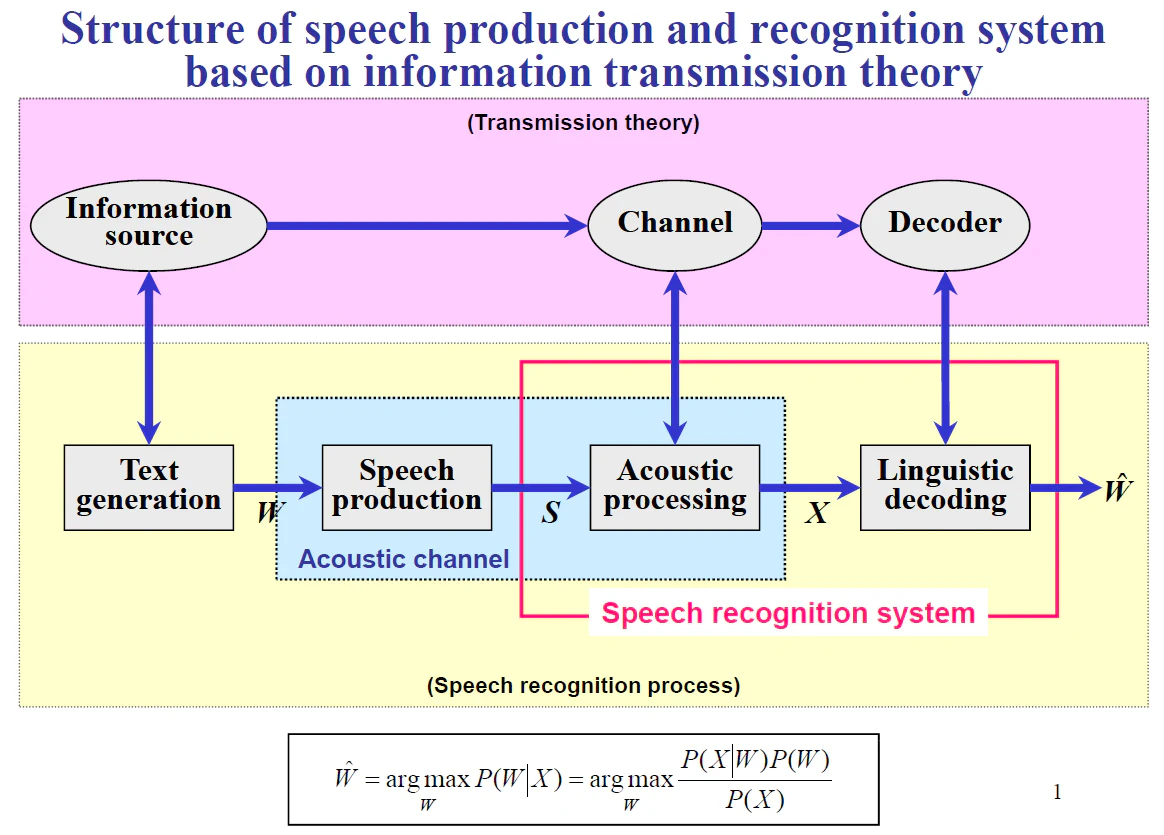
音声生成は頭の中で考えたテキストを音声に変換するプロセスです。そのため、音声認識は音声からテキストを推定するので、音声生成の逆問題と考えることもできます。テキストを情報源として音声波形に変換されたものが入力となり、音声波形に埋め込まれているテキストを逆問題として推測します。音声波形から音素シンボル(発音記号のようなもの)を推定し、音素シンボル列から自然言語のテキスト列を推定する2段階構造が多いです。前者の音声波形Xから音素シンボルを推定するモデルを音響モデル、後者の自然言語テキストWを推定するモデルを言語モデルと呼びます。この流れを下図に示します(2から引用)。 基本的にはP(W|X)が最大となるWを探す探索問題として定式化され、モデルの学習を行います。最近はモデルを2つに分けずに1つのモデルで音声波形Xから単語列Wを推定するend-to-endモデルも増えてきましたが、さらに大量の学習データが必要となります。
「こんにちは」というテキストを2秒で話した場合、音声波形を0.1秒刻みでデータ化すると20個の入力データ系列になります。音声認識はこの20個の入力データ系列を「こんにちは」という文字に当てはめることです。このため、音声波形Xから音素シンボルを推定するモデルを音響モデルは、長いデータ系列を短いデータ系列に当てはめる必要がある上に、音声波形は多少の伸び縮みも生じます(早口だったり一部の文字だけ長くなったり等など)。音声認識研究の初期ではDPマッチングを用いたテンプレートマッチングを基本とした手法が多かったです。とはいえ、話者の違いなどを全てテンプレートにすることは困難なので、音声分野でも確率的なモデルの導入が始まりました。1990年代から2010年頃まで支配的だったのはDPマッチングを拡張した隠れマルコフモデル(HMM)です。HMMの各隠れ状態は音響信号(正確には波形そのものではなく音響特徴量)のパターンを示しています。このパターンを混合正規分布(GMM)でモデル化していました。このGMMとHMMを組み合わせたGMM-HMMモデルは2010年頃までの主流です。
音響モデルへのニューラルネットワークの適用
音声認識にニューラルネットワークを用いることは1990年代2000年代から研究されていました(私の学生時代の先輩もニューラルネットワークを用いていましたが性能不足と過学習に苦しんでいた印象です)。ニューラルネットワークの導入対象ですが、広く用いられているのはHMMの出力確率 $P(X|S)$ を求めるために使われています($X$は音響特徴量、$S$はHMMの隠れ状態)。2000年代までは計算コストや学習手法の問題からネットワークの規模が小さく性能も不足していたましたが、2010年頃からGMM-HMMに匹敵する性能が報告され始め345、ニューラルネットワークの発展にともない音声認識分野でも広く採用されていきました。GMMとニューラルネットワークの違いを図に示します(6の図3より引用)
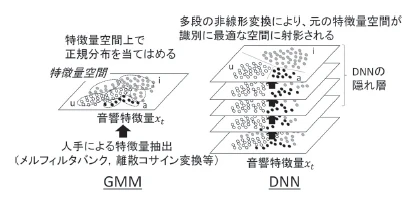
GMMでは音響特徴量に複数の正規分布を当てはめることで領域の分割を行っていましたが、ニューラルネットワーク(上図のDNN)ではDNNの複数の層+線形変換+非線形変換によって領域の分割をおこなっています。
また、音声波形から音響特徴量を求める手法としてニューラルネットワークを用いることもあります。これまではメルフィルタバンクの出力に離散コサイン変換をかけて、その低次の係数だけを音響モデルの入力として使っていました。この特徴量変換をニューラルネットワークに置き換えることで、特徴量抽出器として用いることができます。
言語モデルへのニューラルネットワークの適用
従来の言語モデルはN-gramを用いていました。自然言語処理の分野でのニューラルネットワークの適用と同じく、音声認識の言語モデルとしても
- RNN
- LSTM
- Transfomer
- BERT
と発展が続いています。この分野の説明は本記事では触れませんので自然言語処理の解説や書籍など参照願います。
End-to-Endモデル
ここまで紹介したモデルは、音響特徴量⇒音響モデル⇒言語モデル⇒認識結果 という多数の処理を順番に行っています。音響モデルにDNN-HMMを用い、言語モデルにLSTMを用いる。といった流れです。ここで、HMMをニューラルネットワークに置き換えることができれば、入力から出力までを全てニューラルネットワークに置き換えることができます。音声認識では入力信号は音響特徴量の系列、出力信号は文字や単語の記号列なので入力と出力の長さが異なります。このような長さの異なる系列信号を変換するニューラルネットワークをEnd-to-Endモデルのニューラルネットワークと呼びます。音声認識におけるEnd-to-Endモデルを幾つか紹介します。
CTC:Connectionist Temporal Classification
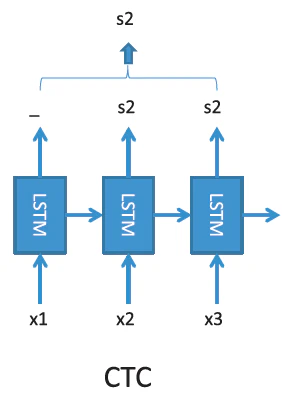
CTCはHMMを用いずに時系列信号を分類しようとしたモデルです7。通常、音素(発音記号に近いものと思ってください)や文字単位のLSTMを用います。これだけだと無音区間の表現ができないので、どの音素・文字でもない記号(ブランク記号)も用意し、各音素・文字の間に挿入します。出力系列を計算するときはブランク記号を削除することで、入力信号系列よりも短い出力信号系列を得ることができます。これらの処理の流れを以下の図に示します(8の図3より引用)。入力x1x2x3を与えたとき、x1はブランク記号、x2は音素s2、x3は音素s2に割り当てられ、入力x1x2x3全体としては音素s2という出力が得られています。
注意機構付きエンコーダーデコーダーモデル
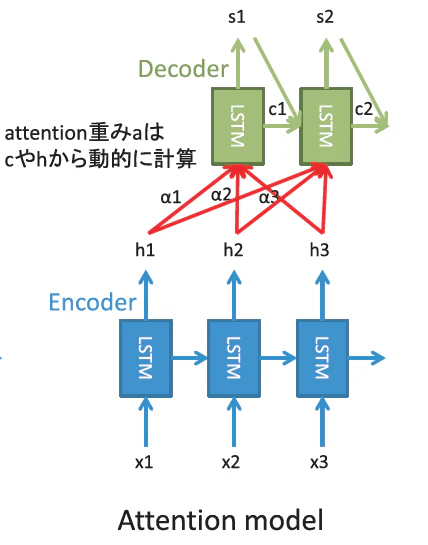
エンコーダーデコーダーモデルは、入力⇒エンコーダー⇒中間表現⇒デコーダー⇒出力 という流れで処理を行います。注意機構付きエンコーダーデコーダーモデルのエンコーダーでは入力信号をLSTMに入れます。入力をLSTMに入れるところはCTCに似ていますが、LSTMの出力は音素などではなく分散表現(数値ベクトル)を求めます。デコーダーでは、分散表現を入力として音素・文字の系列を出力します。その際、最初の音素・文字は最初の方の音響特徴量を重要視した方が良いので、重みを付けます。これが注意機構(Attension)と呼ばれる仕組みで、この重みもニューラルネットワークの学習対象となります。この処理の流れを以下の図に示します(8の図3より引用)。
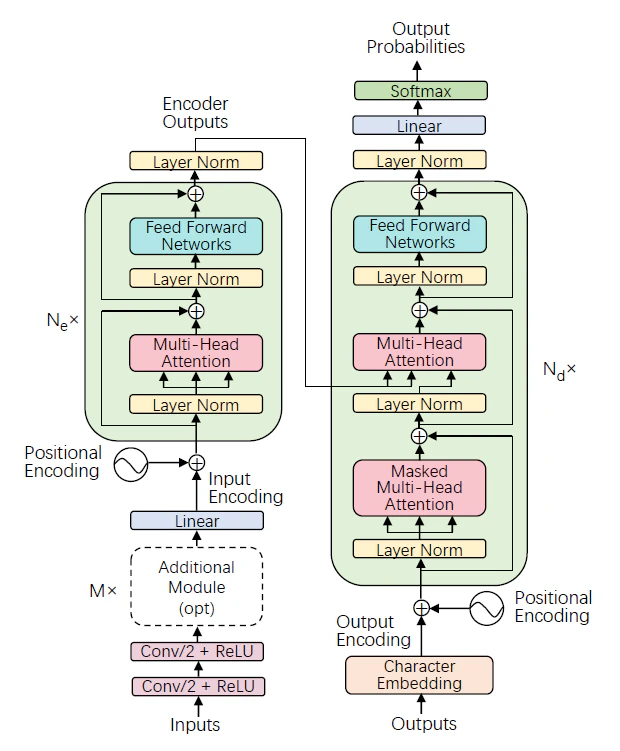
Transfomerを用いたモデル
自然言語処理と同様に、RNNやLSTMをTransfomerに置き換える動きは音声認識でも行われています。2018年に提案されたTransfomerを用いた音声認識End-to-Endモデル[9]では、注意機構付きエンコーダーデコーダーモデルで使われていたLSTMの代わりに、multi-head self-attention を用いています。この処理の流れを以下の図(9のFig2より引用)に示します。
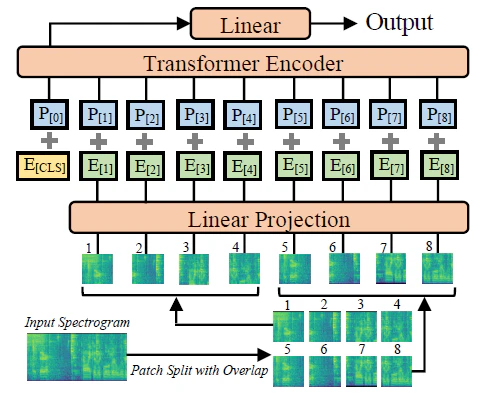
2018年提案モデル9では入力信号に音声信号のスペクトログラムを用い、畳み込み層を通していました。今年提案されたモデル10ではCNNを用いずにLinear Prediction(線形予測)を用いています。処理の流れを以下の図に示します(10のFigure 1より引用)。畳み込み層はスペクトルの直前直後(100ミリ秒単位)の関係性や、スペクトルを画像とみなしての形状情報を得るので、この辺りが聴覚の認識機構とずれているのかもしれない・・・などと考えていますが、まだ不明な点も多いところです。
まとめ
本記事では音声認識分野でのニューラルネットワークの導入について、最近までの流れをまとめてみました。2000年頃でもニューラルネットワークを音声認識を取り入れてみようという動きはありましたが、画像認識と同様に隠れ層を増やしても学習がうまくいかなかったり過学習がひどかったりして、GMM-HMM+N-gramモデルが主流でした。2006年以降は層を増やしたニューラルネットワークの学習法が徐々に出始めて、2010年前後からは画像認識などと同様に大きく導入が進んでいきました。(2011年頃は研究から少し離れていたので、2012年に「ついにHMMの次のモデルが表われそうだ」という話を聞いた時は驚きました)
最後に音声認識分野の勉強を始めてみたい方向けの参考情報を以下に示します。まずは気軽に調べてみたい方は、以下の記事が参考になります(本記事もかなり参考にしています)。
・私のブックマーク「音声認識システム」, 人工知能学会, https://www.ai-gakkai.or.jp/resource/my-bookmark/my-bookmark_vol35-no3/ , 2020.
書籍で本格的に勉強されたい方は以下がお勧めです。
(音声認識を全体的に学び始める方向け)
・荒木雅弘, 「イラストで学ぶ 音声認識」, 講談社, 2015.
(音声認識をHTK、Juliusなどで作ってみたい方向け)
・荒木雅弘, 「フリーソフトでつくる音声認識システム(第2版)」, 森北出版, 2017.
(音声認識の理論面をがっつり勉強したい方向け)
・篠田浩一, 「音声認識」, 講談社, 2017.
参考文献
-
古井貞煕,「音声情報処理」,森北出版,1998. ↩
-
Sadaoki Furui, "Speech Information Processing", Tokyo Tech OCW, http://www.ocw.titech.ac.jp/index.php?module=Archive&action=KougiInfo&GakubuCD=226&GakkaCD=226716&KougiCD=76027&Nendo=2010&Gakki=2&lang=EN&vid=05&tab=7, 2010. ↩ ↩2
-
D. Yu et al., “Roles of pre-training and finetuning in context-dependent DBN-HMMs for realworld speech recognition,” Proc. NIPS Workshop on Deep Learning and Unsupervised Feature Learning , 2010. ↩
-
F. Seide et al., “Conversational speech transcription using context-dependent deep neural networks,” Proc. Interspeech, pp. 437–440, 2011. ↩
-
G. Dahl et al., “Context-dependent pre-trained deep neural networks for large-vocabulary speech recognition,” IEEE Trans. Speech Audio Process., 20, 30–42 , 2012. ↩
-
神田直之, 「音声認識における深層学習に基づく音響モデル」,日本音響学会誌, 2017. ↩
-
A. Graves and N. Jaitly, “Towards End-to-End speech recognition with recurrent neural networks,” Proc. ICML (2014). ↩
-
河原達也, 「音声認識技術の変遷と最先端 ─深層学習によるEnd-to-End モデル─」,日本音響学会誌, 2018. ↩ ↩2
-
Dong, L., et al."Speech-Transformer: A no-recurrence sequence-to-sequence model for speech recognition", ICASSP 2018, 2018. ↩ ↩2
-
Yuan Gong, Yu-An Chung, James Glass, "AST: Audio Spectrogram Transformer",https://arxiv.org/abs/2104.01778, 2021. ↩ ↩2