本記事はBrainPad Advent Calendar 2020 https://qiita.com/advent-calendar/2020/brainpad の記事です。
音声認識や話者認識にニューラルネットワークが用いられるようになって早数年[1]。
ニューラルネットワークはとっても複雑なモデリングが可能ですが、そのためには大量のデータが必要です。
音声認識分野で有名な大規模コーパスといえばLibriSpeechがあります。しかし音声は言語の壁があるので、画像のようにアメリカで作られたデータセットをそのまま日本で使うことができません。さらに話者依存性や話し方などのタスク依存も大きいです。
余談:話し言葉になると音響的にも言語的にも変化するので話し言葉もコーパスが欲しくなるけれども・・・・・日本語話し言葉コーパス(CSJ)[2]みたいな大規模コーパス作るのはとても大変です
先ほど画像について少し触れましたが、画像認識でもニューラルネットワークはとても使われているのでデータ量はとても重要です。データセットも色々準備されています。画像は言語依存のようなものが少ないので、アメリカで整備された画像データセットを使って、日本で使うための画像認識モデルを作ることも良く行われています。
とはいえ、大規模データセットはだれでも作れるわけではありません。大規模データセットで学習した画像認識モデルを、手元の画像識別タスク向けに利用したい考えは多く、転移学習やファインチューニングといった技術がよく使われています。
音声認識や話者認識のニューラルネットワークでは畳み込みニューラルネットワーク(以下、CNN)を使ったものが出てきています。これは周波数特性としてスペクトラムを用い、スペクトラムを画像とみなすことでCNNを周波数分析として利用しています。では、画像で学習したCNNを音声認識の周波数分析パートに使えないでしょうか。
話者認識の分野では画像で学習したモデルから転移学習する試みが行われています。VoxCeleb2という動画と音声のデータセット(インタビューや講演などが多い)を用いた話者認識[3]では、最初に顔画像データセットを用いてベースモデルを学習します。次に動画と音声をリンクさせたCNNに拡張してからインタビュー動画を用いて学習し、音声部分を切り出して話者認識モデルを作成しています。
画像は時系列データではないので、音声認識のように系列シンボル列を求めるタスクよりも話者認識のように単一シンボルを予測するタスクの方が画像認識モデルからの転移学習しやすそうです。音声から単一シンボル予測を行うタスクとして、今年ならではなものとして「発話音声を用いてマスクを着用しているか否かを予測する」タスクがあります[4]。
このタスクに、画像で事前学習したモデルを利用する論文[5]もありましたので紹介します。
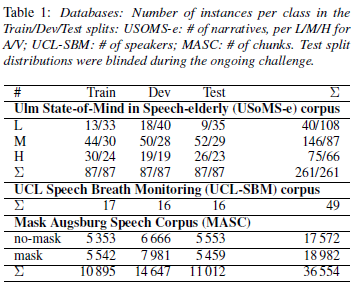
この論文はInterspeech2020で開催されたパラ言語情報に関するコンペ「ComParE 2020」のタスクであるマスク部門に参加されたものです。このタスクでは、短時間の音声からマスクを着用しているか否かを判定するものです。MASC(Mask Ausburg Speech Corpus)という1発話1秒程度の音声コーパスを用います。発話数は36554で、話者数は32です。マスク有りと無しの発話が半々くらい(少しマスク有りが多め)となっています。(下記の表はコンペの説明論文[4]のTable 1より引用)また、データはTrain(学習用)、Dev(学習の検証用)、Test(評価用)に分かれています。
音響特徴量には短時間FFTによるスペクトログラムを用いていますが、時間解像度と周波数解像度を両方高くすることはできません(トレードオフの関係にあります)。そこで窓幅を3種類用意し、それぞれをチャンネル(カラー画像のRGBに相当)とすることで複数の解像度を1つのデータにまとめています。論文のFig.1では、窓幅(ws)の例として5ms,15ms,50msの3種類を用意し、各窓幅のスペクトログラムをチャンネルに割り当てて、3チャンネルスペクトログラムとしています。最後に320×320ピクセルにリサイズしています。データ拡張も行っており、回転(最大3度)、拡大(最大140%)、輝度変化(最大30%)を行っています。

次に分類を行うニューラルネットワークモデルを用意します。320×320ピクセルの3チャンネルデータを用いて、マスクの着用有無という2択問題を求めるモデルですので、よくある画像分類モデルの構造が使えそうです。この論文ではVGG、ResNert、DenseNetが使われています。全てImageNetを用いた学習済モデルを初期モデルとし、最後の出力層を2ユニットに差し替えて2択問題対応モデルとしています。
また、モデルのアンサンブルも行っています。ここでは出力層のソフトマックス関数の出力を分類クラスの所属確率とみなし、複数モデルの出力層から得られた所属確率の平均を用いるアンサンブル手法と最大値を用いるサンサンブル手法を採用しています。
実験結果として、最初にTrainデータで学習したモデルをDevデータで評価した結果を示します。
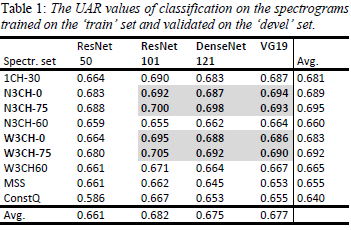
N3CH-0(窓長8ms、15ms、30ms)の3チャンネルスペクトログラムと、N3CH-75(N3CH-0を-75dBでカットオフしたもの)。W3CH-0(窓長5ms、15ms、50ms)の3チャンネルスペクトログラムとW3CH-75(W3CH-0を-75dBでカットオフしたもの)の計4種類の性能が高かったことが分かります。MSS(メルスケールのスペクトログラム)やConstQ(コンスタントQ変換)よりも周波数軸に変換を加えない*3CH-*の方が概ね良い結果となっています。
次に、Train+Devデータで学習してTestデータで評価を行います。使用するスペクトログラムは最初の実験で性能が高かった4種類(N3CH-0、N3CH-75、W3CH-0、W3CH-75)です。
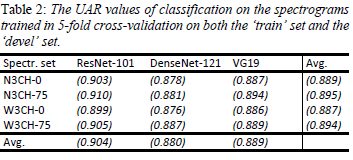
Trainだけで学習した結果と比べると性能が非常に良くなっていますが、Train+Devを用いて学習している効果なのでしょうか。確かにデータ量は約2倍になっていますが。学習に用いるデータ量を確認したいなら、Trainで学習してTestで評価したものとTrain+Devで学習してTestで評価のように、評価用データを同一にすればとも思いました。
最後に、マスク着用の有無を判別する際にどこを重要視しているのか確認しています。この論文では画像認識でもよく用いられるCAM[6]を用いています。CAMを用いてマスクありとクリア(マスクなし)のスペクトログラムの重要度を色付けした結果が以下の図です。ランダムに4発話を抽出しています。
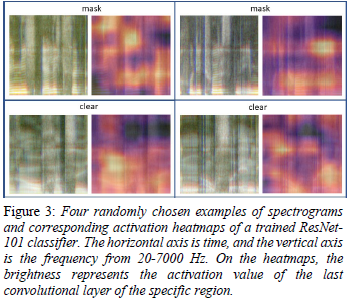
次にマスクあり音声の重要度を、周波数毎に平均をとったグラフが以下の図です。
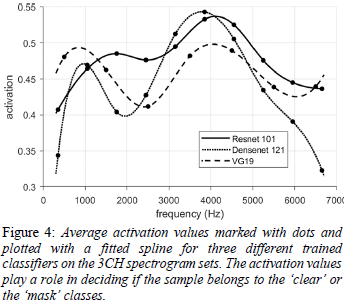
マスクありの音声を見つけるには3kHzから5kHzが重要という事が分かります。音声認識のような音韻の識別にはあまり重要視されない周波数帯ですね。このことは、高周波数帯を重要視しないメルスケールや対数周波数を用いたモデルの方が、マスク着用の判別性能が高くなかった結果とも一致します。
以上で論文の紹介を終わります。普段は音声認識に触れることが多いので、メルスケール周波数よりも周波数変換なしの方が良い結果になることが新鮮でした。パラ言語情報は音韻とは違う軸に重要な情報がある事を思い出しました。
文献
[1]Alex Graves, Abdel-rahman Mohamed and Geoffrey Hinton,”SPEECH RECOGNITION WITH DEEP RECURRENT NEURAL NETWORKS”,http://www.cs.toronto.edu/~hinton/absps/DRNN_speech.pdf ,2011.
[2]日本語話し言葉コーパス,https://pj.ninjal.ac.jp/corpus_center/csj/
[3]Joon Son Chungy, Arsha Nagraniy, Andrew Zisserman, “VoxCeleb2: Deep Speaker Recognition”, https://arxiv.org/abs/1806.05622, 2018.
[4]Björn W. Schuller, Anton Batliner, et al., “The INTERSPEECH 2020 Computational Paralinguistics Challenge:Elderly Emotion, Breathing & Masks”, http://www.compare.openaudio.eu/compare2020/, 2020.
[5]Jeno Szep, Salim Hariri, “Paralinguistic Classification of Mask Wearing by Image Classifiers and Fusion”, https://isca-speech.org/archive/Interspeech_2020/pdfs/2857.pdf, 2020.
[6]Bolei Zhou, Aditya Khosla, Agata Lapedriza, Aude Oliva, Antonio Torralba, “Learning Deep Features for Discriminative Localization”, https://arxiv.org/abs/1512.04150, 2015.