概要
DevOpsでは、モニタリングできる仕組みを組み込み、開発サイクルを回しながらモニタリングした情報やユーザーのフィードバックをもとに次のアイデアを検討し、実装リリースしていくという流れがあります。
モニタリングやフィードバックから得られる情報がサービス開発の様々な面において指針となるため、とても重要な要素と考えられます。
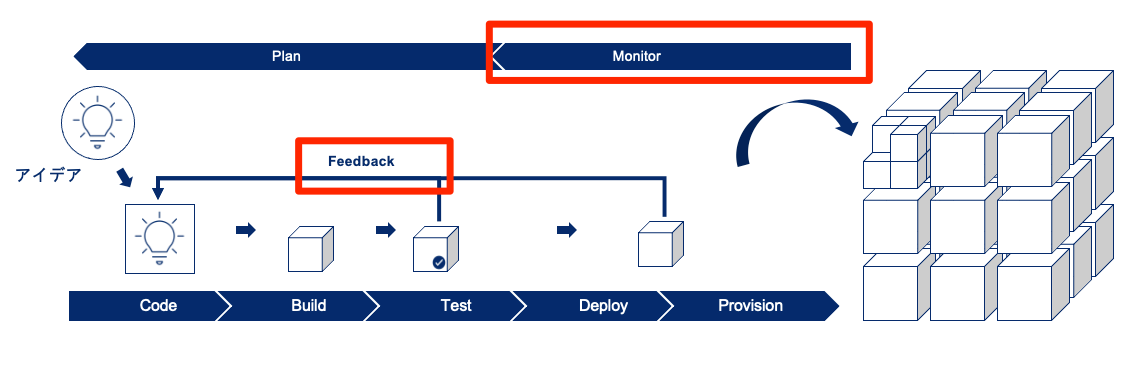
今回はこの「モニタリング」と「フィードバック」に着目し、一例として私の実際に担当している社内システムを例に、行っている取り組みをまとめてみました。
まだ試行錯誤しているところが多いですが。何かの参考になれば幸いです。
背景
社内システムを開発している弊チームでは、開発だけでなく運用や仕様の決定も担当しています。
対象システムは社内で使われますが、業務は常に変化しており、システムの使われ方や立ち位置、必要とされる機能も変わっていきます。
そういったなかで、やはり「継続的モニタリング」「継続的フィードバック」それらを基にした開発サイクルを回すことが重要と実感しています。
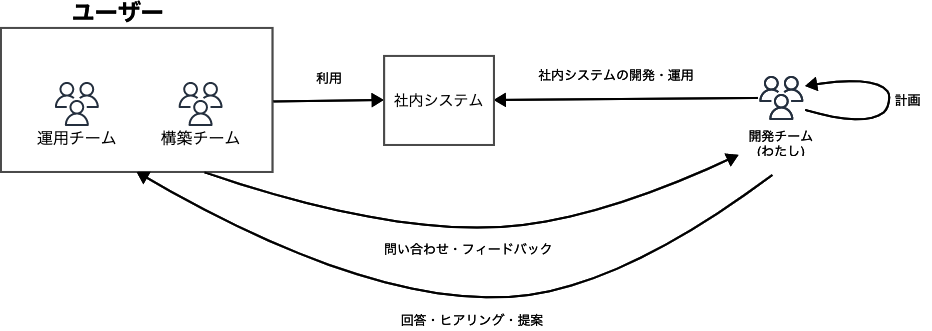
システムのモニター、効果測定、ユーザーからのフィードバックの取得や集積はツールやマネージドサービスを活用し、自動化できるところは自動化を進めています。それらの情報からアイディアや解決策を見出す部分は定例ミーティングを開きチームでディスカッションすることが多いです。
AWSやSaaSの活用
この社内システム自身やモニタリングの仕組みにはAWSや各種SaaSを利用しています。
自らサーバーをホストし実装やフレームワークのインストールをせずとも、基本的なマイクロサービスの構成要素はサービス化されており、即時、必要なぶんだけ調達することができます。
今回の例では「モニタリングと収集」の部分でLambdaが収集した情報をS3に保管し、保管された情報をAthena&Glueでクエリによる分析を可能としています。
これらAWSサービス間のやりとりは、AWSで用意されているAPIやイベントを利用しています。またSaaSへのアクセスも提供されているAPIをつかって行います。

対象システム
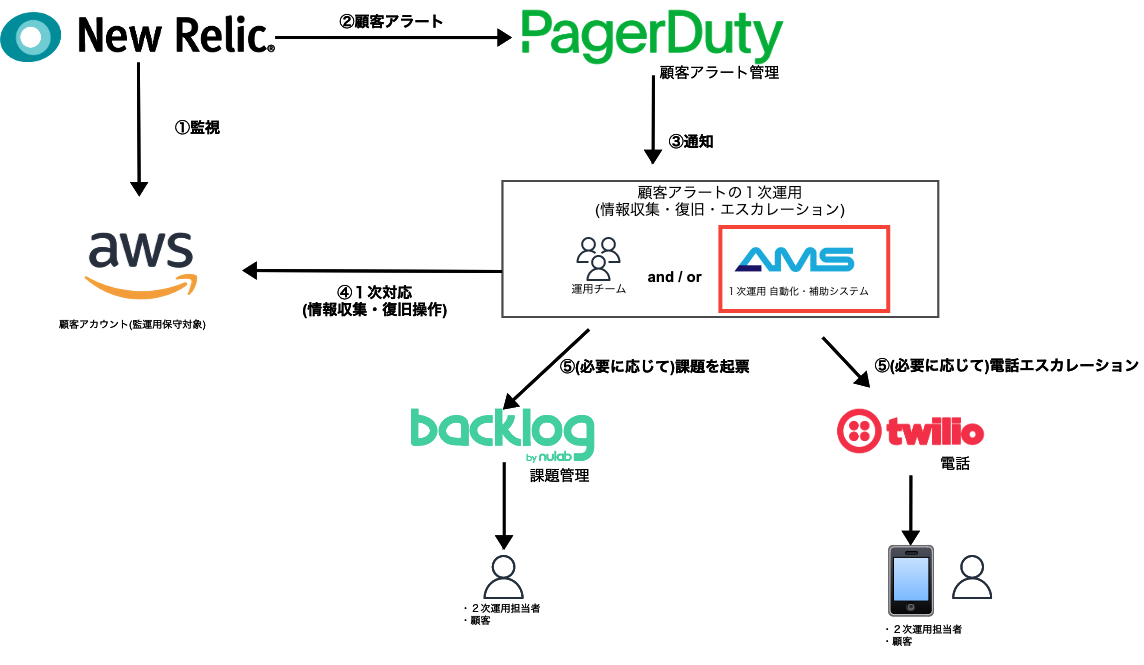
今回、例として出すのは図中の赤枠で囲んでいる「1次運用 自動化・補助システム」です。
運用保守契約いただいている顧客のアカウントに、アラート(=顧客アラート)が発生したときに「情報収集」「復旧操作」「エスカレーション」を自動で行うシステムです。
これは人間の「一次運用チーム」と協調して動き、情報収集までをシステムで行い、続きを運用チームに委譲したり、登録した自動化シナリオの想定外の事態が発生した場合も運用チームに続きを委譲したりもします。
モニタリングしたい情報
OKR
このサービスの目的は以下です。
- 顧客アラート対応を迅速・正確に行う
- 人間の一次運用チームの負担を減らし、単純作業はシステムで行い、柔軟な対応が必要なところは人間が行うほうに寄せる
以下のような情報をOKR測定の要素として収集する必要があります。
- 顧客アラートの対応速度
- 顧客アラートのシステム対率
SLI/SLO
正常に処理したリクエストの割合※をSLIとし、一定の基準(SLO)をみたいしているか確認できる必要があります。
※正常に処理したリクエスト数 / 総リクエスト数
システム・インフラ、アプリケーション
システムの構成は別の記事参照
利用しているAWSサービスのメトリクスやログを収集し、常に確認できる必要があります。
モニタリングと収集
モニタリングしたい情報は、以下の図のように集積しています。
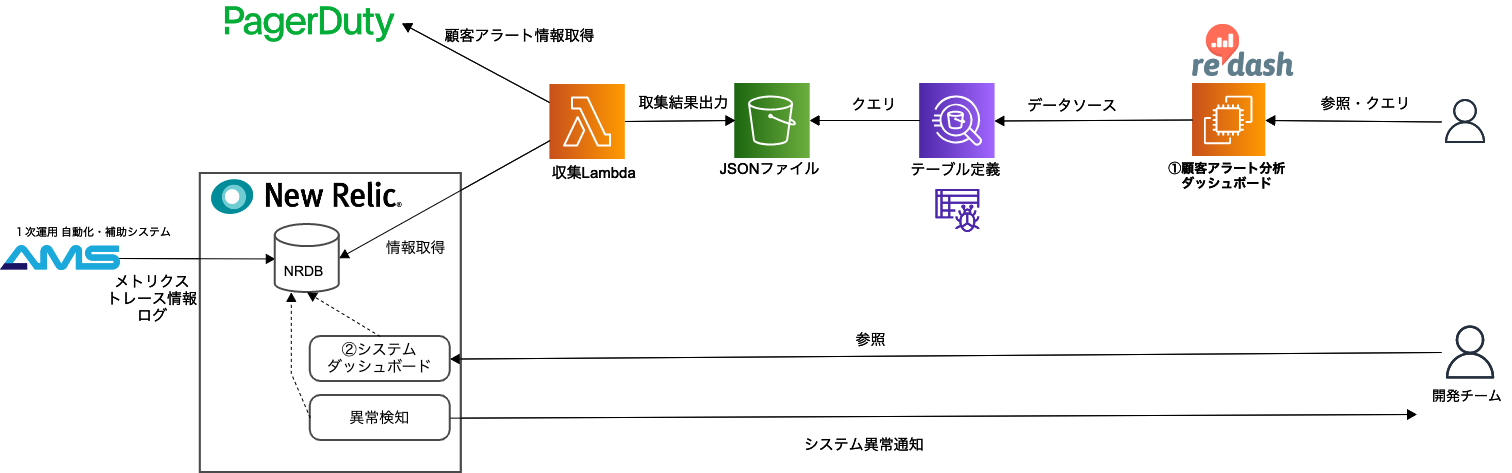
情報のソースとして顧客アラート情報はPagerDuty、システムに関する情報はNewRelic内のデータベース(NRDB)に集積しています。
① 顧客アラート分析ダッシュボード
主にOKRや顧客アラート全体の傾向を分析するためにのダッシュボード

情報収集用のLambdaを定期実行し、情報を統合してJSONファイルとして格納。それをAthena&Glueでテーブルとして定義し、EC2上に構築したRe:dash(ダッシュボードツール)から参考・クエリの発行を行っています。
自動化システムの効果確認だけでなく、顧客ごとの傾向の分析にも利用し、負担の大きい顧客アラートが頻発している場は運用手順や監視設定、監視対象のシステムのチューニングなどを見直す改善アクションをとります。
② システムダッシュボード
システムの状況を確認するためのダッシュボード
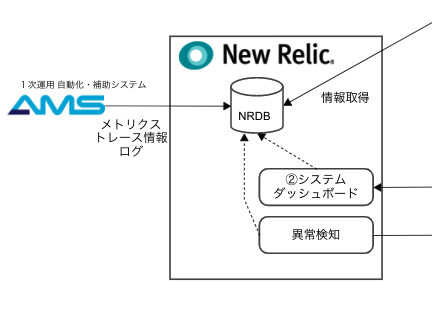
New Relic にメトリクス、アプリケーションのトレース情報、ログを集約し、ダッシュボードを作成しています。
それぞれLambdaのInvocations/Errors、顧客アラートの処理開始・終了時刻・実行結果、エラーログなどをモニタリングしています。
エラー発生やキャパシティ逼迫などの異常時は開発チームに通知がいくようにしています。
継続的フィードバック
システムからユーザーから得た情報をフィードバックとして次のアクションの検討・計画に反映させます。
ダッシュボードは各自意識してみるようにしていますが、チームの定例なども活用して状況共有・検討する場を設けています。
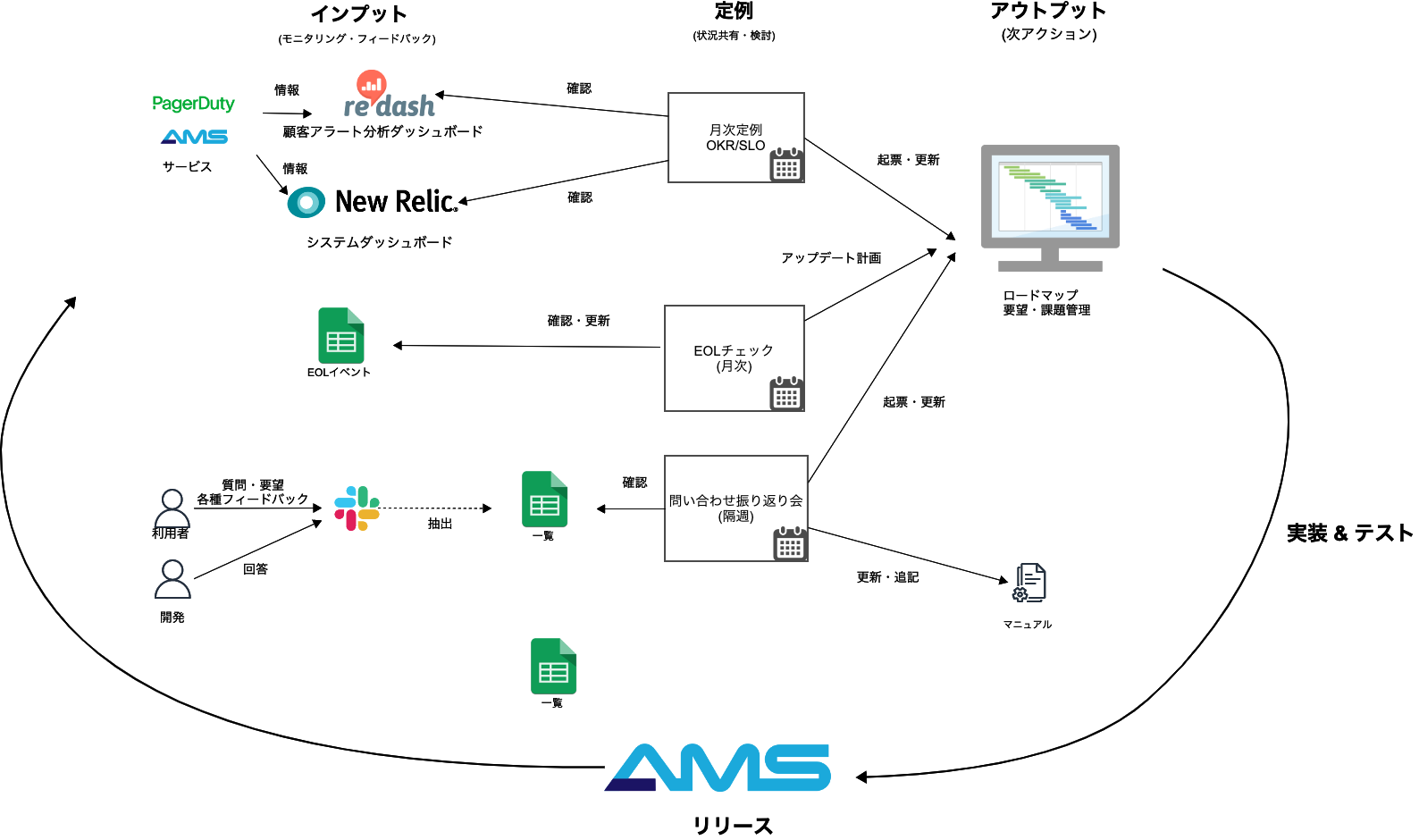
月次定例 OKR/SLO
-
OKRが期の目標に対してどの位置に今あるか確認し、必要に応じて原因分析や対策を検討
-
SLOを確認
- SLOの基準の自体の妥当性の確認
- リリース計画を立てるときにエラーバジェットがどの程度溜まっているか参考にする
-
システムダッシュボードの確認
- 閾値は超えていないが増加傾向にあり将来的に逼迫しそうなメトリクスがないかなど、ざっと確認
- 大規模なリージョン障害の影響など振り返り
-
リポジトリのリリースタグ、CloudFormationスタックの更新履歴でリリース頻度を確認
EOLチェック(月次)
月1回、担当者でサービスで使用しているランタイムや言語、ライブラリ、OSなどについてEOL情報を収集・更新する
EOLの時期を確認しアップデートや乗り換えの計画を建てる。
収集する情報例
- Lambda::ランタイムサポートポリシー
- Beanstalk::リタイアが予定されているプラットフォームバージョン
- Python::Status of Python branches
- Node.js::Releases
- 各種EOLを載せているサイト
問い合わせ振り返り会(隔週)
利用者からの質問や要望・フィードバックはSlackを中心に随時受け付け回答しているが、2週間に1回、それらをスプレッドシートに一覧出力し振り返り会を実施。
以下のような会話し、必要に応じてアクションに起こす。情報共有の意味もあるので、できるだけチーム全員が参加。
- この問い合わせはなぜ発生したか?
- マニュアルの更新・追記
- UIなどの改善課題
- 要望と費用対効果
- 問い合わせへ適切な内容と速度で回答できたか?
- スキトラ
- マニュアルや仕様の整理
- 問い合わせ対応により必要以上に開発者に負荷がかかっていないか?
- 緊急度の設定基準見直し
- 問い合わせに対する対応のアサイン方法見直し
そのほかの取り組みや工夫していること
- 半年に1回、匿名アンケートを取りNPS(ネットプロモータースコア)を算出
- Slackで問い合わせを受ける際にワークフロー機能を使って「問題の特定に必要な情報」「緊急度」を必須入力項目にする。
終わりに
開発チーム内にて実装したい機能がある場合、フィードバックへの対応や取り込みは時間がかかるためあとに回されてしまうこともあるかもしれません。しかし、実際に利用されるかわからない機能をリリースするよりも、実際にユーザーが求めている機能をリリースしたほうが効率がよいと考えています。
また要望やフィードバックをそのまま受け取るだけでなく背景の把握やヒアリング、対処方法の検討や実験する時間を定期的に確保することも効果があると実感しています。