麦わら海賊団のメンバーのだれにどのくらい似ているのか調べるアプリを作ってみた
今回は機械学習の画像認識を使ったアプリを作りました。
題名にある通り、自分の顔がワンピースの麦わら海賊団のメンバーのだれにどのくらい似ているのかを調べることができます。
GitHubはこちら
↓↓↓
https://github.com/Sho-cmyk/shiny-winner
まずは完成形を見てください。
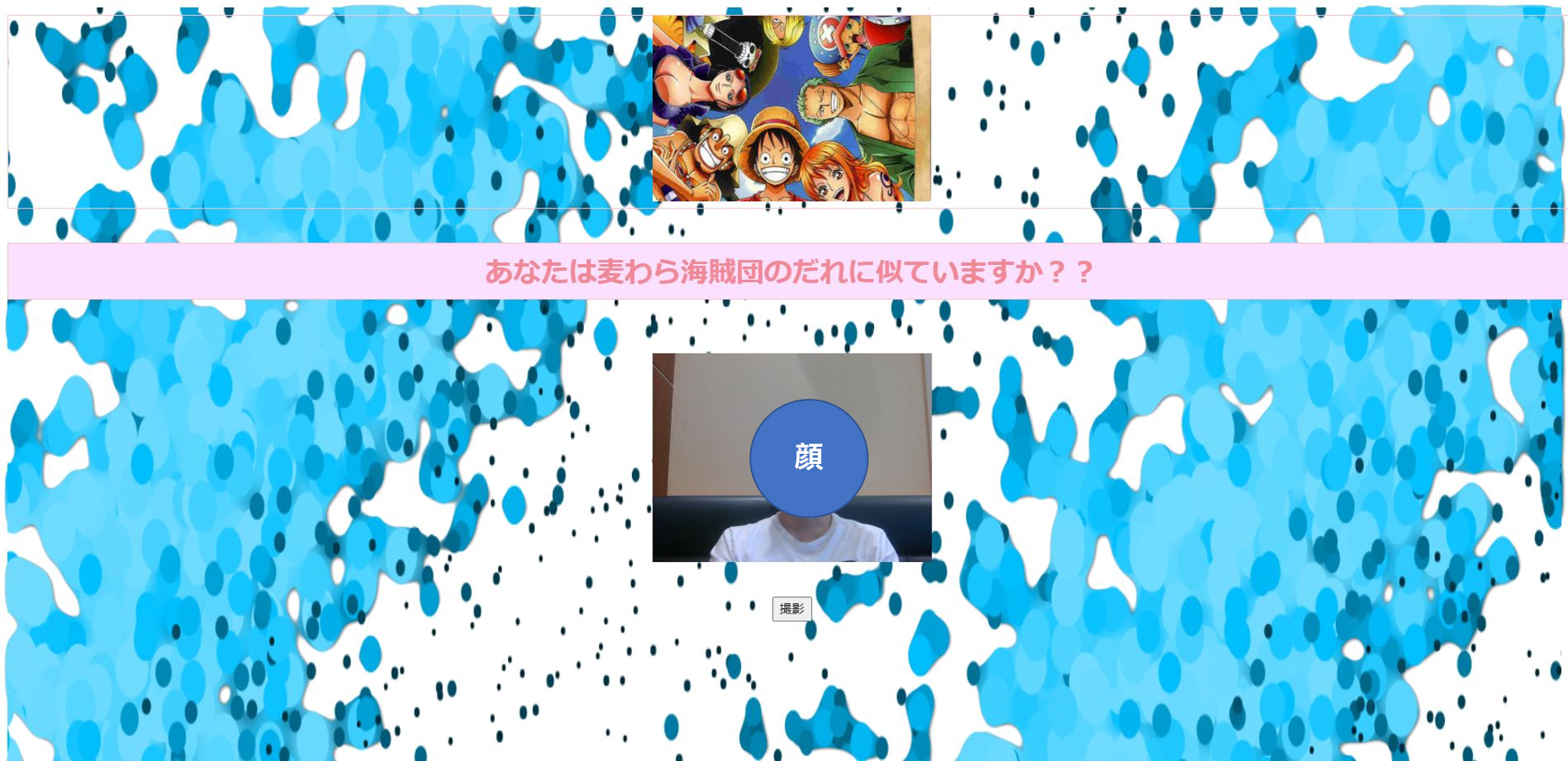
撮影ボタンを押すと、、
自分の顔が麦わら海賊団のメンバーのだれにどのくらい似ているのかを示してくれます。
似ているキャラクター上位2つが表示されます。

私はジンベエに76%ブルックに13%似ていることがわかりました。
アプリが気になる方はこちらのURLから試してみてください。
↓↓↓
https://one-piece-camera.herokuapp.com/
アプリを作る手順
次にアプリを作る手順を紹介していきます。
手順は大きく分けて以下の通りです。
- ファイル構成(flask)
- 学習用の画像を集める
- 画像の前処理
- 学習
- 推定
- html/css/jsで出力画面を整える
- おまけ(特徴抽出)
1. Flaskでのファイル構成
flask_app
├ one-piece_cnn_aug.h5 ---重みを保存
├ static --- 静的ファイル置き場所
│ ├ img
│ └ webcam.js
│ └ image.js
│ └ stylesheet.css
├ templates --- テンプレート
│ └ index.html
├ main.py --- アプリ実行用スクリプト(アプリの入り口)
├ requirements.txt
└ runtime.txt
└ Profile
└ README.md
2.学習用の画像を集める
私はYahooの画像検索で、麦わら海賊団のメンバーそれぞれの画像をスクレイピングします。
それぞれ200枚スクレイピングしました。
詳しいスクレイピング方法は、以下を参照しました。
引用:https://www.youtube.com/watch?v=BrCaYYJtC4w
3.画像の前処理
次に使える画像だけを残していきます。
目的のキャラクターが単体で移っていない写真は消していきます。
その結果、それぞれの写真の枚数が以下の通りになりました。
ウソップ:82枚
サンジ:74枚
ジンベエ:57枚
ゾロ:85枚
チョッパー:90枚
ナミ:51枚
ビビ:58枚
フランキー:78枚
ブルック:78枚
ルフィ:83枚
ロビン:58枚
そしてそれぞれのキャラクターごとの正確さを確認すると以下の通りになりました。
ウソップ
Epoch 100/100
50/50 [==============================] - 1s 11ms/step - loss: 1.1921e-07 - acc: 1.0000
32/32 [==============================] - 0s 5ms/step
Test Loss: 1.192093321833454e-07
Test Accuracy: 1.0
その画像を今度は訓練データとテストデータに分けます。訓練データはImageDataGeneratorを使って水増しします。
from PIL import Image
import os
import glob
import numpy as np
from sklearn.model_selection import train_test_split
from keras.preprocessing.image import ImageDataGenerator
classes = ["ウソップ", "サンジ", "ジンベエ", "ゾロ", "チョッパー",
"ナミ", "ビビ", "フランキー", "ブルック", "ルフィ", "ロビン"]
num_classes = len(classes)
image_size = 50
num_testdata = 30
# 画像の読み込み
X_train = []
X_test = []
Y_train = []
Y_test = []
for index, classlabel in enumerate(classes):
photos_dir = "./"+classlabel
files = glob.glob(photos_dir+"/*.jpg")
for i, file in enumerate(files):
if i >= 200:
break
image = Image.open(file)
image = image.convert("RGB")
image = image.resize((image_size, image_size))
data = np.asarray(image)
X_train.append(data) # リストの最後尾に追加する
Y_train.append(index) # ラベルを追加する
datagen = ImageDataGenerator(
samplewise_center=True, samplewise_std_normalization=True)
g = datagen.flow(X_train, Y_train, shuffle=False)
X_batch, y_batch = g.next()
X_batch *= 127.0/max(abs(X_batch.min()), X_batch.max())
X_batch += 127.0
X_batch = X_batch.astype('unit8')
# 配列にしてテストとトレーニングデータに分けて入れる
X_train = np.array(X_train)
X_test = np.array(X_test)
y_train = np.array(Y_train)
y_test = np.array(Y_test)
# X_train,X_test,y_train,y_test=train_test_split(X,Y)
xy = (X_train, X_test, y_train, y_test)
np.save("./one-piece_aug.npy", xy) # コードを保存
4.学習
学習モデルはCNNを利用します。
コードは以下のとおりです。
from keras.models import Sequential
from keras.layers import Conv2D, MaxPooling2D
from keras.layers import Activation, Dropout, Flatten, Dense
from keras.utils import np_utils
import keras
import numpy as np
from tensorflow.keras.optimizers import RMSprop
classes = ["ウソップ", "サンジ", "ジンベエ", "ゾロ", "チョッパー",
"ナミ", "ビビ", "フランキー", "ブルック", "ルフィ", "ロビン"]
num_classes = len(classes)
image_size = 50
# メインの関数を定義する
def main():
X_train, X_test, y_train, y_test = np.load(
"./one-piece_aug.npy", allow_pickle=True)
X_train = X_train.astype("float")/256
X_test = X_test.astype("float")/256
y_train = np_utils.to_categorical(y_train, num_classes)
y_test = np_utils.to_categorical(y_test, num_classes)
model = model_train(X_train, y_train)
# model_eval(model,X_test,y_test)
model_predict(model, X_test, y_test)
def model_train(X, y):
model = Sequential()
model.add(Conv2D(32, (3, 3), padding='same', input_shape=X.shape[1:]))
model.add(Activation('relu'))
model.add(Conv2D(32, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(64, (3, 3), padding='same'))
model.add(Activation('relu'))
model.add(Conv2D(64, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(512))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(11))
model.add(Activation('softmax'))
# opt=RMSprop(lr=0.0001,decay=1e-6)
opt = keras.optimizers.adam()
model.compile(loss='categorical_crossentropy',
optimizer=opt, metrics=['accuracy'])
model.fit(X, y, batch_size=32, epochs=100)
# モデルの保存
model.save('./one-piece_cnn_aug.h5')
return model
def model_predict(model, X, y):
scores = model.predict(X, verbose=1)
for i in range(X.shape[0]):
print('正解値:', y[i].argmax())
if __name__ == "__main__":
main()
学習結果は以下のようになりました。
Epoch 100/100
7888/7888 [==============================] - 69s 9ms/step - loss: 0.0130 - acc: 0.9962
330/330 [==============================] - 1s 3ms/step
Test Loss: 5.885516380541253
Test Accuracy: 0.4727272728175828
Test Accuracyがとても低いです。
考えられる原因は前処理後のデータが少なかったと思われます。
そこで、画像の枚数を以下のように増やしました。
ウソップ:82枚→341枚
サンジ:74枚→206枚
ジンベエ:57枚→374枚
ゾロ:85枚→357枚
チョッパー:90枚→260枚
ナミ:51枚→251枚
ビビ:58枚→339枚
フランキー:78枚→416枚
ブルック:78枚→279枚
ルフィ:83枚→482枚
ロビン:58枚→263枚
画像はtwitter、google、microsoft edgeでスクレイピングして前処理しました。
その結果11%精度が向上しました。
Epoch 100/100
17600/17600 [==============================] - 127s 7ms/step - loss: 0.0407 - acc: 0.9917
1100/1100 [==============================] - 2s 2ms/step
Test Loss: 4.337944065440785
Test Accuracy: 0.5881818179650741
恐らく画像の枚数を増やすと精度は更に向上すると思われます。
5.推定
いよいよ推定です。
撮影された写真が学習済みモデルに当てはめられて、どのキャラにどのくらい似ているのかという情報を得ることができます。
そして、その得た情報を出力するためにhtmlに送ります。
import PIL
import io
import base64
import re
from io import StringIO
from PIL import Image
import os
from flask import Flask, request, redirect, url_for, render_template, flash, jsonify
from werkzeug.utils import secure_filename
from keras.models import Sequential, load_model
from keras.preprocessing import image
import tensorflow as tf
import numpy as np
from datetime import datetime
classes = ["ウソップ", "サンジ", "ジンベエ", "ゾロ", "チョッパー",
"ナミ", "ビビ", "フランキー", "ブルック", "ルフィ", "ロビン"]
classes_img = ["static/img/usoppu.jpg", "static/img/sanji.jpg", "static/img/jinbe.jpg", "static/img/zoro.jpg", "static/img/chopper.jpg",
"static/img/nami.jpg", "static/img/bibi.jpg", "static/img/franky.jpg", "static/img/bruck.jpg", "static/img/rufi.jpg", "static/img/robin.jpg"]
num_classes = len(classes)
image_size = 50
UPLOAD_FOLDER = "./static/image/"
ALLOWED_EXTENSIONS = set(['png', 'jpg', 'jpeg', 'gif'])
app = Flask(__name__)
def allowed_file(filename):
return '.' in filename and filename.rsplit('.', 1)[1].lower() in ALLOWED_EXTENSIONS
model = load_model('./one-piece_cnn_aug.h5') # 学習済みモデルをロードする
graph = tf.get_default_graph()
app = Flask(__name__)
@app.route('/', methods=['GET', 'POST'])
def upload_file():
global graph
with graph.as_default():
if request.method == 'POST':
myfile = request.form['snapShot'].split(',')
imgdata = base64.b64decode(myfile[1])
image = Image.open(io.BytesIO(imgdata))
# 保存
basename = datetime.now().strftime("%Y%m%d-%H%M%S")
image.save(os.path.join(UPLOAD_FOLDER, basename+".png"))
filepath = os.path.join(UPLOAD_FOLDER, basename+".png")
image = image.convert('RGB')
image = image.resize((image_size, image_size))
data = np.asarray(image)
X = []
X.append(data)
X = np.array(X).astype('float32')
X /= 256
result = model.predict([X])[0]
result_proba = model.predict_proba(X, verbose=1)[0]
percentage = (result_proba*100).astype(float)
array_sort = sorted(
list(zip(percentage, classes, classes_img)), reverse=True)
percentage, array_class, array_img = zip(*array_sort)
pred_answer1 = "ラベル:" + \
str(array_class[0]) + ",確率:"+str(percentage[0])+"%"
pred_answer2 = "ラベル:" + \
str(array_class[1]) + ",確率:"+str(percentage[1])+"%"
pred_answer3 = "ラベル:" + \
str(array_class[2]) + ",確率:"+str(percentage[2])+"%"
img_src1 = array_img[0]
img_src2 = array_img[1]
img_src3 = array_img[2]
basename = datetime.now().strftime("%Y%m%d-%H%M%S")
filepath3 = UPLOAD_FOLDER + basename+".png"
return render_template("index.html", answer1=pred_answer1, img_data1=img_src1, answer2=pred_answer2, img_data2=img_src2, answer3=pred_answer3, img_data3=img_src3)
return render_template("index.html", answer="")
if __name__ == '__main__':
port = int(os.environ.get('PORT', 8080))
app.run(host='0.0.0.0', port=port)
#app.run(debug = True)
6.出力画面を整える
あとはhtml/css/jsで出力画面を整えるだけです。
webcam.jsは以下の引用です。
https://github.com/jhuckaby/webcamjs
背景のhtml/jsは以下の引用です。
https://codepen.io/stefanweck/pen/YNPdRR
7.おまけ(特徴抽出)
今回ワンピースの麦わら海賊団のメンバーを分類器にかけましたが、どの特徴をもって分類しているのかをopenCVを使って検証してみました。
例えば、ルフィの写真を特徴抽出したものがこちらです。

主に目の周り、髪型の特徴を抽出していることが見受けられます。
まとめ
今回学習画像枚数を増やすことで47%から58%まで精度を向上させることができました。
58%という確率は決して高いとは言えません。
これから更に精度を向上させるためには以下の2つの方法が考えることができます。
1.学習画像データを更に増やす
2.vgg,resnetなど他の学習モデルを試す