この記事は、 2016年 eeicアドベントカレンダー その1 の一日目の記事です。
東京大学工学部電子情報工学科( eeic )の学生実験として、情報可視化実験というものがあります。d3.js を用いて情報可視化システムを2人組で開発していく実験で、主眼は Javascript と D3.js におかれる(参考: もう1人のTAによるC 言語しか触ったことない人向け JavaScript 入門)のですが、チーム開発をするために git 及び GitHub の習熟も求められます。
私は今この実験の TA をしているのですが、どうしても git ・ GitHub についての解説に時間が割けないのが現状です。また、この実験の採点対象はありがちなレポートではなく、GitHub 上に push されたコミット であるという特徴があります。しかしeeicでの講義は2人組などで開発をする課題も多いにも拘らず、一括して git を教える機会もないため、結果として初めて git を触る人も多いのが実情です。その状況での commit はやや見づらい/読みづらいものが多く、採点が少し難航しました。
そこで本記事では、授業や今後の研究生活/バイト/インターンなどで困らない程度の git ・ GitHub についての解説を行い、授業の不足分を補おうと思います。もちろん先生の書いた説明もわかりやすいのですが、ここではより汎用的な説明を行うつもりです。
もちろん、対象読者は eeic の人だけに限らず、より一般的な人に読んでもらえればなと思ってます。というわけで、やや表向きなまえがきからこの記事を始めます。
まえがき
学生の皆さん、 git 使ってますか?
「 git 」という名前を知っている人でも、「強い人は使ってるみたいだけど難しそうでよくわからない」とか「 git はチーム開発のためのものなので個人開発しかしない自分には関係ない」とか思う人は多いのではないでしょうか。
そういった git へ心理的障壁の原因は世間の git 入門記事にあると僕は思っています。というのも、世間で実際に git を使っている人は IT 企業の社会人が多く、チーム開発のためのものとして導入されがちだからです。
そこで本記事では、学生が直面しやすい状況をユースケースとして想定して git ・ GitHub の使い方を説明してみようと思います。そのため、普通の git 入門とは解説の順番が違っていたり、内容を省いていたりします。
もちろん対象読者は学生にかぎらず、他の git 入門記事でよくわからなかったという人にも馴染めばいいなと思っています。「なぜ git が使いたいのか」を説明しようとする一方で、「git のこの機能は何なのか」については説明をあえてぼかしているところもあり、git について詳しい人からすると詰めが甘い記事かもしれません。訂正や批判など有りましたらコメントなどをして戴けるとありがたいです。
本編
レポート・ノートのためのバージョン管理
すこし意外かもしれませんが、この記事では最初に個人利用目的で git を使ってみることをオススメします。
もちろん git はチーム開発専用のツールではないので、個人で使うだけでも十分なメリットはありますし、何より誰にも迷惑をかけない良い練習になります。
肩慣らしとしてテキスト主体のファイルについてのバージョン管理について見ていきましょう。
別ファイルでの管理とその問題点
情報系の学生であっても、 PC で作成する文書としてレポートは一般的なものでしょう。レポートを作成するときに全体の構成を変えるなどの大きな変更をすると、あとから戻ろうと思っても戻りづらいという問題があります。そういった場合に備えてファイル名に「レポート_v1.doc, レポート_v2.doc, ……」とか「レポート_20161201.tex, レポート_20161202.tex, ……」といった別のファイル名での保存のような有りがちな対処をしたことがある人も多いのではないでしょうか。
こういった別ファイルとしての保存による管理はたしかに便利なのですが、いくつかの問題が有ります。例えば、
- ファイルが多くなってくると戻りたいときにどれが目的のバージョンなのかわからない。
- 各ファイルごとの違いがわかりづらい
- 重要なのは各ファイルごとの違いなのに、ファイル全体を保存するので容量を食う。
といったものです。
バージョン = commit
これらの問題を解決するためのツールが「バージョン管理システム」と呼ばれるもので、 git もその一つです。「バージョン」とは上記のレポートの例で言うところの名前付きファイルそれぞれに相当し、ある時点でのフォルダ全体の状態を保存できます。git ではこのバージョンを「 commit (コミット)」という名前で管理します。
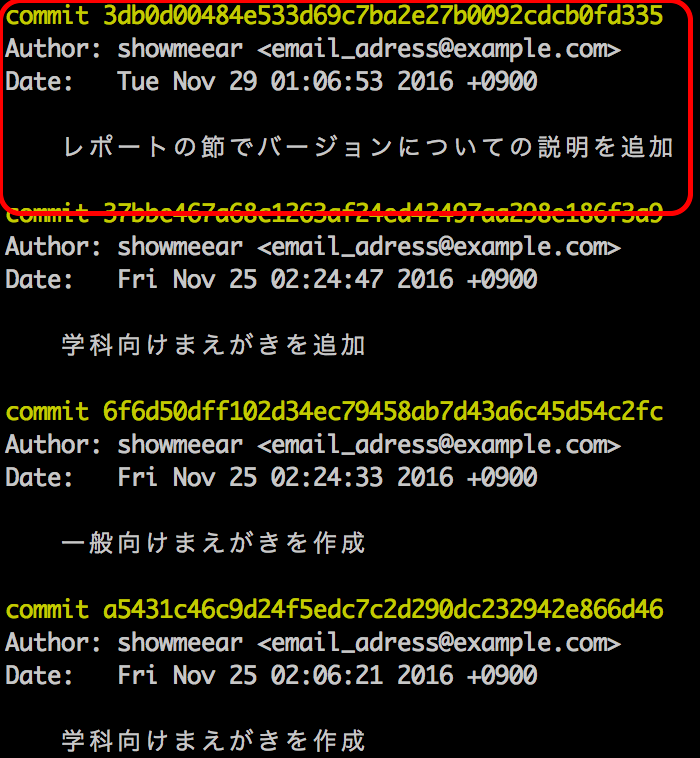
イメージがつかめないかもしれないので、詳しい使い方を説明する前に git で管理している状態をとりあえず実際に見てみます。図は私がこの記事を markdown ファイルで書いている際の過去の commit (バージョン)です。
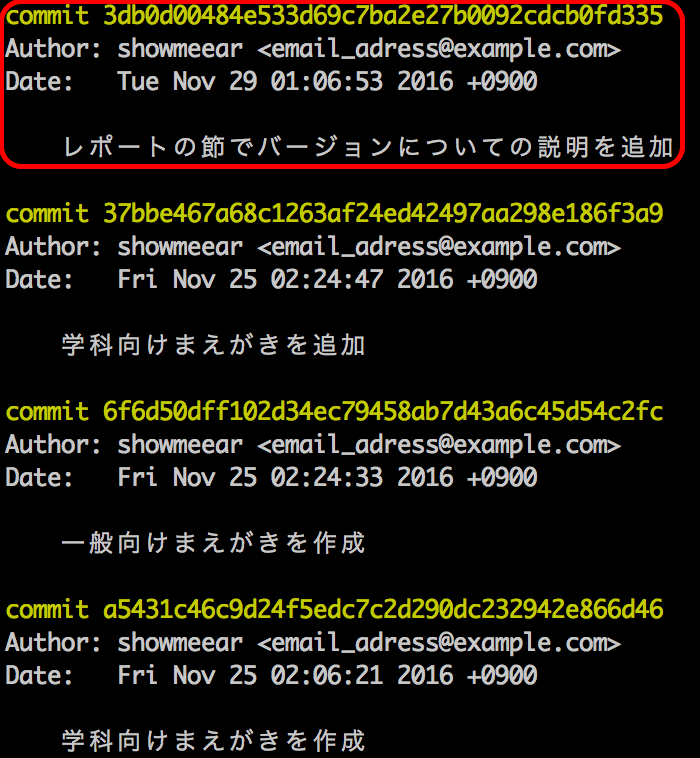
上の方ほど新しいバージョン、下の方ほど古いバージョンになっています。ここでは、四角で囲った commit について見てみます。
最初の commit 1716172bee0c291529e0bfbfce8728e419effd64 というのは、その commit を一意に特定するための名前のようなもので、commit IDといいます。ファイル名での保存の例でのファイル名に相当します。その下には Author として誰がその commit を作成したのか、つまりその変更を行った人が表示されています。更にその下には Date、つまりその変更が保存された日時が表示されています。
そして、 git を使う上で一番重要になるのが一行開けて下にある「レポートの節で……」という一文です。これは commit を保存する際に記入することができるコメントのようなもので、"commit message"と呼ばれています。ここにその commit での変更内容を記述しておくことで、先述した問題点の1つめ、どれが目的のバージョンかわかりづらいという問題を解決することができます。
commit の保存と困ったときの $ git status
では、実際に commit を保存してみます。この節をここまで追記した状態で、現状確認のためのコマンド $ git statusをしてみましょう。すると、以下の図のようなことを言われます。
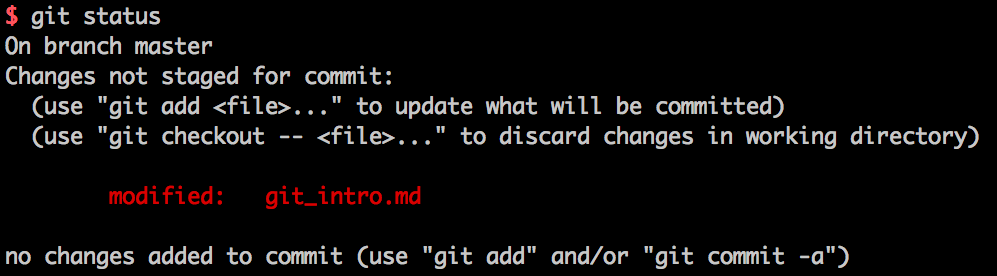
ここでは commit を作成したいので、「(use "git add ..." to update what will be committed)」というお言葉に従います。そこで、 $ git add git_intro.md としてもよいですし、フォルダ全体の commit を作成すると捉えて $ git add . などとしても良いです。この add というのは「ステージング」ということをしているのですが、詳細については次節のチーム開発のところで説明します。今はとりあえず commit のための準備だと捉えておいてください。
$ git add した後で、再度$ git statusをしてみると、以下のような状態になります。
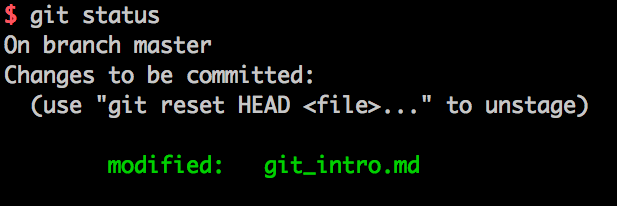
「Changes to be committed: ……」 と言われているので、僕のgit_intro.mdは commit として保存できる状態になっています。commitを作成するためのコマンドは $ git commit -m <コミットメッセージ>です。例えば $ git commit "commitについての説明を追加"といった感じです。
大事なことなのでもう一度まとめます。commitを保存するには
$ git add <ファイル名>$ git commit -m コミットメッセージ
とします。gitは親切なので、困った場合は$ git statusをすることでどうすればよいかの教えてくれることが多いです。
ただし、$ git add や $ git status をする際に fatal: Not a git repository …… などと怒られることがあります。これは、そのフォルダが git で管理するよう設定されていないということなので、$ git initとすれば解決します。
過去を振り返る $ git log
先程提示した、過去の commit 一覧は $ git log というコマンドで見ることができます。
さらに、重要な情報だけを見やすくしたいときには$ git log --oneline --decorate --graph というコマンドを使うことで、下図のようなスッキリとした見た目で見ることができます。
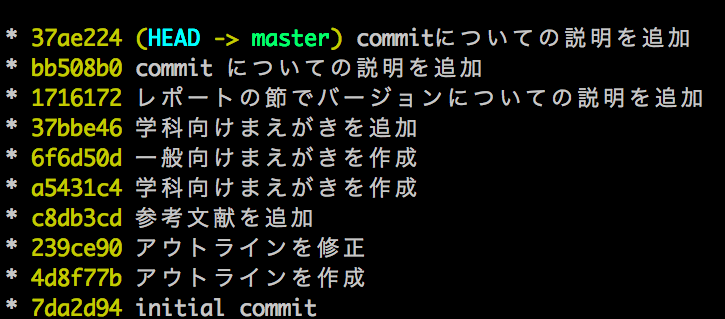
HEADというのは、今自分がいる場所を示す目印だと思っていてください。「 master 」については後で説明します。
ちなみに、僕はこの長ったらしいコマンドをよく使うので、$ glog とすると $ git log --oneline --decorate --graph となるようにエイリアス(コマンドのショートカットみたいなもの)を設定しています。git は alias を使うとより便利になるので、いちいち長いコマンドを打ちたくないという人は gitで便利なエイリアス達 - Qiita などを参考に設定してみると良いでしょう。
commit ごとの違いを知るための $ git diff
次に、「バージョン管理をしていたことで進捗が救われる」という事例を紹介します。
さきほどの $ git log についての節ですが、実は一度削除してしまっていました。しかし、あとからやはり書く必要があろうと思い直したのですが、削除しているためまた一から書き直す必要があります。
……といって一から書き直すのは時間の無駄なのですが、git で管理しているおかげで削除してしまった文章も用意に復元することができます。現状の commit の履歴を見てみます。($ git log --oneline --decorate --graph)

commit message から分かる通り、 「42577d5」という commit で該当部分を削除してしまいました。なので、その削除内容を知るために、その1つ前の commit (89b8d22)と比較してみます。コマンドとしては $ git diff 89b8d22 42577d5 です。すると、以下のような結果が表示されました。
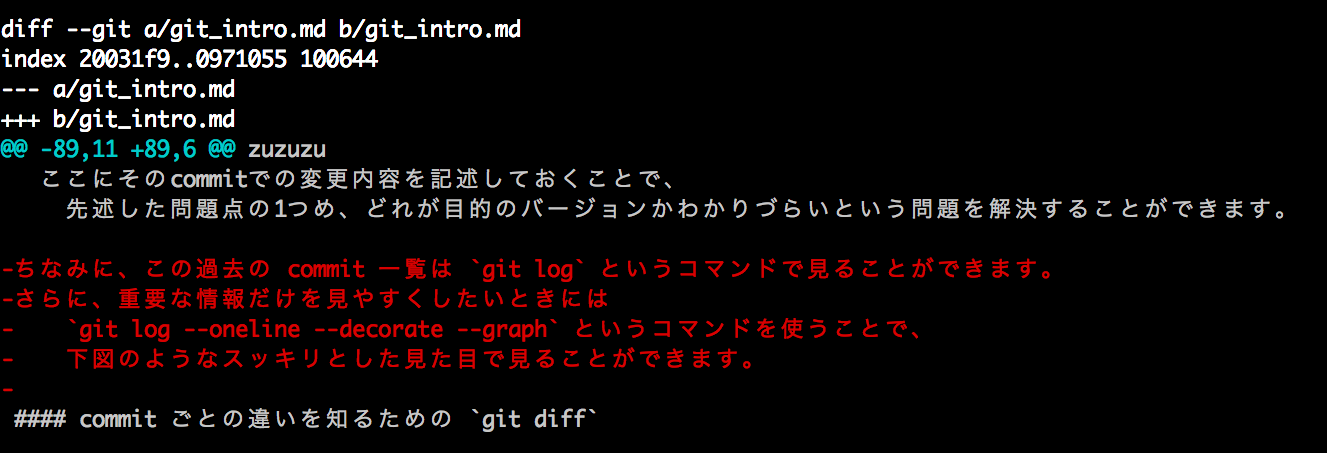
行頭に"-"があり、赤くなっているところがその commit で削除した部分です。この部分をコピペすることで、削除してしまった部分を復元することができました。
この $ git diff は他にも、 commit を保存する前に今の状態を確かめるときにもよく使います。(詳細は省略)
タイムマシーン $ git checkout
git は画像や動画などのバイナリファイルの管理が苦手です。というのも、$ git diff をしても画像の変更については何が変わったのかがわかりづらいためです。そこで、ここではさらに「誤った図を修正前の時点まで戻って元の図をサルベージする」といういわば過去遡行をしてみます。そのためのコマンドは $ git checkout というもので、commit を指定するとフォルダの状態がその時点までまるっと戻ります。
例えば、最初にお見せした図を過って以下のように四角の一部が文字にかぶせてしまったとします。
画像から四角を消すのは難しいため、編集前の図を再度編集する必要がありますが、編集前のファイルが残っていなかったらどうしようもありません。しかし、編集前のファイルがある状態で commit が保存されていれば、どうにかなります。commitの履歴が以下のようになっていれば、

$ git checkout 4c6bff9 とすることで、図を修正する前のフォルダの状態に戻ることができます。その過去の図を一旦他のフォルダにコピーするなどして、$ git checkout master (master というのはとりあえず最新版のことだと思ってください) とすれば、図の編集後の状態に戻りつつ元の図をサルベージすることができました。
この checkout は、今は大したことができないように見えますが、後のbranchの説明のところで重要になってくるので心に留めておいてください。
プログラミング課題のためのbranch
プログラミング特有の問題
前節ではレポートのバージョン管理について説明しましたが、この節ではプログラミングの際のバージョン管理について述べます。git といえばプログラミングに用いるものという認識は一般的でしょうから、この節以降がメインと言ってもかまわないのですが、実は前節に説明した内容だけでも十分に git を使えます。
しかしながら、プログラミングの課題にはレポート(のようなテキスト主体のファイル)になかった以下のような困りごとが有ります。
- とりあえず動く提出できる状態のものと、開発途中のものを分けたい。
- 1つの機能を追加するために複数の commit が必要になるので、 commit だけでは粒度が小さすぎる
こういった問題を解決するための git の主要な機能として branch というものを用います。
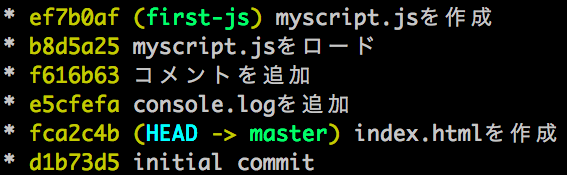
ここでも、 branch の使い方について説明する前に実際に branch を使うとどうなるのか見てみましょう。以下は、ドットインストールの JavaScript 入門 を #02 までやってみたときのgit logです。
![merge後のgit log][branch-merge-log.png]
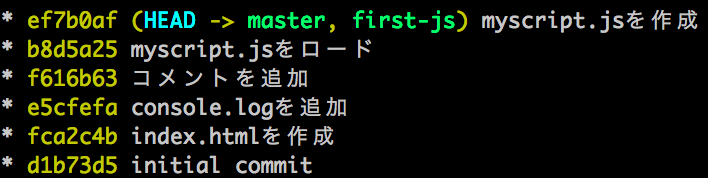
今まで一直線だったグラフが枝分かれしているのがひと目見てわかると思います。この「枝」分かれこそがその名の通り branch に相当します。この branch があることで、ドットインストール JavaScript 入門#02 での変更がe5cfefaからef7b0afまでだというのが容易にわかります。
この節では、このようなわかりやすい git log を残すためにどうするのかを説明します。
branchの作成
まず、ドットインストールの第一回分が終わった状態にいるとします。この時の git log は以下のようになっています。

この状態で $ git branch first-js としてみます。このコマンドは "first-js" という名前のブランチを作成するというコマンドで、この状態でgit logを見てみると以下のようになっています。

緑の文字のfirst-jsが追加されたのがわかると思います。
表示されている場所と文字色から勘の良い方は気づくと思いますが、今まで無視してきたmasterというのも実は branch です。git の初期設定のブランチがこの master であり、「完成物」と呼べるものに対して使われるのが一般的です。つまり、授業の課題などを開発している際には、提出できるものを master としてとっておき、新しい機能を追加したりするときに別のブランチを作成するのが良いでしょう。
新しい branch での開発の進め方
$ git log のところでHEADについて説明したのを覚えているでしょうか?確認しておくと、HEADとは現在の自分の居場所のことでした。上記の log を見ると分かる通り、HEADはmasterを指しており、さきほど作成したfirst-jsには移れていない状況です。
自分がいるブランチを切り替えるコマンドは、前節でコミットの移動の際に用いた checkout です。前節でも、最新版(master)に戻るために$ git checkoutで移動したのはこれと同じ仕組みです。
実際に $ git checkout first-jsを行うと、git log は以下のようになり、first-js に移ったのがわかるでしょう。ちなみに、 branch を作成しつつ checkout も同時に行う $ git checkout -b first-js というコマンドもあり、こちらを使うのが普通だと思います。

ここで、少し寄り道して branch の誤解を解いておきます。branch (枝)という名前から、「 branch とは commit が連続した枝」と思ってしまいがちです。しかし実際には branch は「コミットに対する目印」と言ったほうが近いです。C言語を使ったことがある人には、「 C 言語での配列が実は連続した要素の先頭のポインタ」という状況が想起されるかもしれません。(余計わかりづらいでしょうか?)
branch が commit を指すものであるからこそ、 checkout ができるわけです。また、今後 branch を使用する merge なども、実は branch でなくcommit IDを指定してもコマンドを実行することができたりします。この「 branch は所詮 commit の目印でしかない」という事実は最初のうちは馴染みづらいかもしれないですが、branch を気軽に使用する上では必須の知識といっても過言でないので認識しておいてください。
では、 branch を切り替えた状態で commit してみます。結果 git log は以下のようになります。

master は元の位置のまま、first-js という目印が移動しています。
このあと commit を何度か重ねてみても、 master は元の位置のままです。
分岐を合流させる merge
first-js での開発が終了したら、 master にその変更を反映させる必要があります。しかし、先程も説明したとおり master は元の位置のままなので、master という"分岐"と first-js という"分岐"を合流させなければなりません。そこで用いるコマンドが $ git merge というものです。
ブランチどうし(すなわち、 commit どうし)の merge をするには、まず変更をとりこみたいブランチに移動します。すなわちここでは、$ git checkout master を行います。
ここで、 $ git merge first-js --no-ff とすると、 git のテキストエディタが開きます。
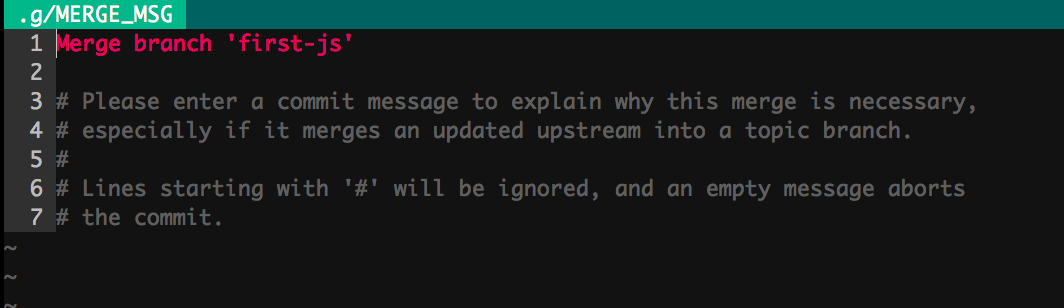
なにやら色々書いてあって怖いですが、これは単に commit message を記述するためのものに過ぎません。デフォルトで Merge branch 'first-js' と書いてあるもので十分なので、このまま保存して終了します。( vi や vim なら :wq )
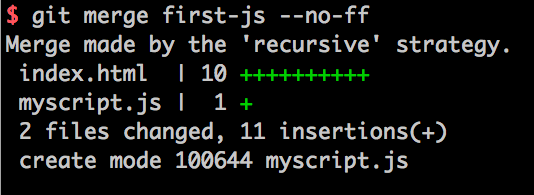
すると、上記のように master が first-js を merge することでどのような変更が起こったのかが表示されます。
こうして、ブランチの状態が以下のようになるわけです。
![merge後のgit log][branch-merge-log.png]
こわくない conflict
次のようなありがちなケースを考えてみましょう。
master から checkout した branch topic1 の途中で行き詰まり、一旦 master から別のbranch topic2 を checkout し、その branch での開発終了して merge しました。そのあとで、再度 topic1 を開発したところ開発が終了したので master に merge したいです。
つまり、 log は以下のような状態になっています。(簡単のために各 branch では1つしかコミットしてないものとします。)
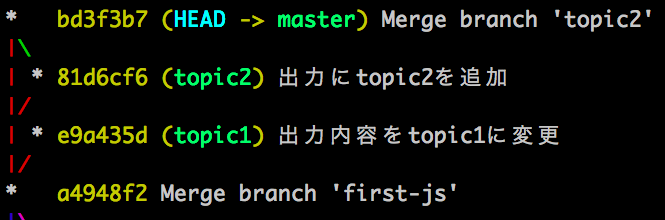
つまり、先程の場合と違い master と topic1 が直接つながっていない(親子関係にない)という状態です。
ここで、 master に対して $ git merge topic1 をしようとするとどうなるでしょうか?
世間の git 入門記事では問題なく merge できるものとして細書に説明をすることが多いですが、実際は結構な確率で merge できません。このとき、 git は "conflict" (競合) を起こしていると言います。
ここでは conflict の解決方法について簡単に説明します。
最初の状態では log.js の1行目に console.log("hello world!"); とあったとします。
topic1では出力の内容を変更するため、1行目を console.log("topic1"); としました。
topic2でも出力の内容を変更するため、1行目を console.log("topic2"); としました。
このとき、 merge したあとのファイルはどうなるのが正しいでしょうか?
最近ファイルを編集したほうを採用しますか?それとも、最近 commit したほうが良いですか?あとから merge するほう?もしくは両方残して2行にしますか?
開発者にとっては、編集には意図があるのでどちらを採用すべきか、それとも両方残すべきかは判断がつきますが、さすがにその判断を git が下すことはできません。もし git が勝手に判断してくれたとして、それが間違っていたらせっかくの編集が消えてしまうことになり大変なので、開発者が自分で選択することが必要となります。
とりあえず、現状の log の状態を $ git log --graph --oneline --decorate --graph -p --all で確認してみます。
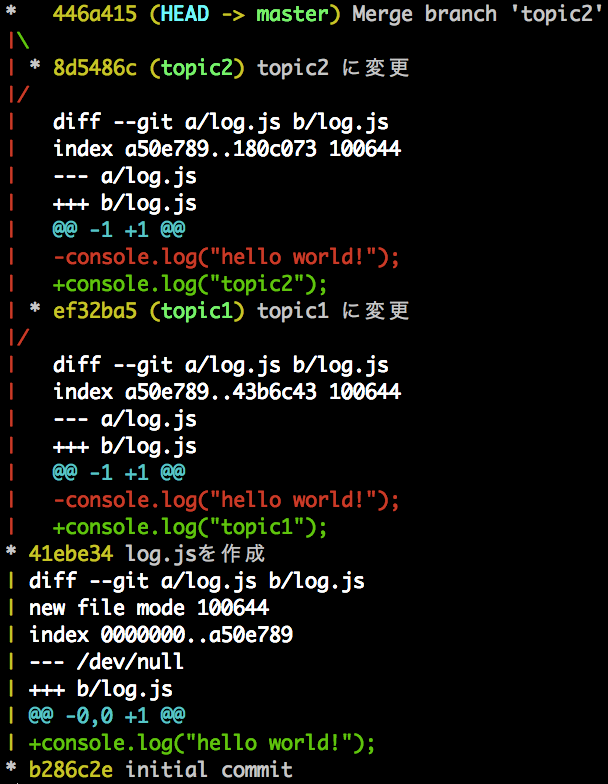
この状態で、 $ git merge topic1 をしてみます。
$ git merge topic1
Auto-merging log.js
CONFLICT (content): Merge conflict in log.js
Automatic merge failed; fix conflicts and then commit the result.
"fix conflicts and then commit the result." と怒られてしましました。とりあえず status を確認してみます。
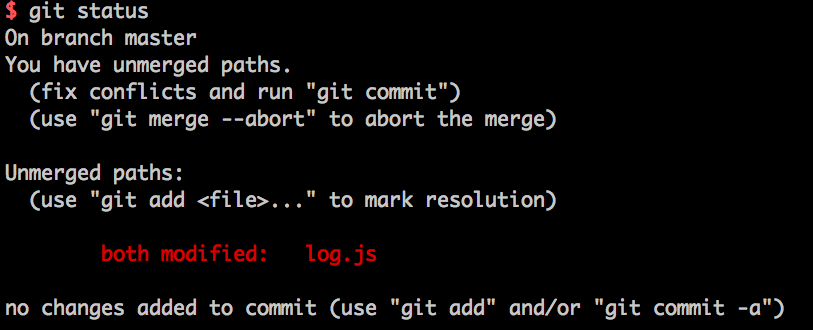
このときの log.js は以下のようになっています。
<<<<<<< HEAD
console.log("topic2");
=======
console.log("topic1");
>>>>>>> topic1
見た目がいかついので少しビビりがちですが、なんのことはなく、
最初の <<<<<<< HEAD の行から ======= の行までが merge 先の変更
======= の行から >>>>>>> topic1 の行までが merge 元の変更
というだけです。
これを普通にテキストファイルで修正して
console.log("topic1");
console.log("topic2");
などとすれば解決です。先程の status でも言われていたとおり、解決したらまた $ git add log.js して $ git commit すれば、いつもどおりの merge ができます。
一応確認しておくと、 merge 後の log は以下のようになります。
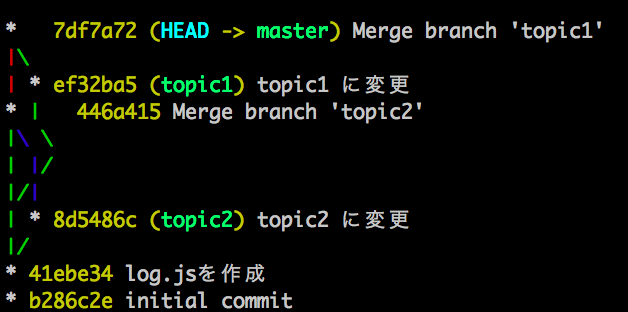
今回は順序を変えつつ両方残しましたが、もちろん片方だけ残すなどでも大丈夫です。結局 merge というのは新しい commit を作る行為の一種なので、大して恐れる必要はないわけです。
ただし、大して恐れる必要がないとはいえ、修正はめんどくさいです。今回は一行ずつの取捨選択で住みましたが、これが何十、何百行もあったら取捨選択が大変になるわけです。なので、 conflict を起こさないための tips は数多く有ります。ここでは詳細は説明しないので、気になる人は 安全な Merge を行う開発フロー | Developers.IO を参照ください。
合併の方法いろいろ
上記の説明の中で、 merge を行う際にひっそり --no-ff というオプションを付けました。このオプションを付けないデフォルトの状態では、merge 後の git log の形としては以下のようになります。
これを Fast Forwad Merge (早送りマージ) といい、マージする2つのブランチが直接つながってるときにマージ先のブランチが移動するだけになります。せっかく分岐させたのにどのような分岐があったのかという情報が失われてしまい、あとから見たときにわかりづらいので、私は --no-ff オプションを常に付けることをおすすめします。
合併の仕方には他にも、 log をキレイにする $ git rebase などがあるので、興味のある方は調べてみてください。ただ、僕は後で紹介する Pull Request でも用いられる No Fast Forwad Merge が良いという宗教観を持っているので、このオプションを布教しておきます。
gitで管理したくないものを除く .gitignore
これは今までの branch の話とは全く違うのですが、 .gitignore と言うものを紹介しておきます。TA をしているときに余分なファイルの差分を見る必要があってめんどくさかったので、ちゃんと設定するようにしましょう。
「余分なファイル」とは何か、という話になると思いますが、たとえば .DS_Store や hoge.txt~ などのバックアップファイルはどう考えてもいらないですよね。また、言語によっては node_modules フォルダは不要だとかもありそうです。
いちいち考えるのがめんどくさいという人は、 github/gitignore: A collection of useful .gitignore templatesから自分の今のフォルダに適した .gitignore ファイルをダウンロードするだけでも良いと思います。
円滑なチーム開発のためのリモートリポジトリと GitHub Flow
ようやくチーム開発まで来ました。例によって、チーム開発でも今までのところがわかっていればあとは大したことありません。共有するためにアップロードとダウンロードする必要があるだけ、といっても過言ではないです。
ただし、チーム開発で重要になるのは git ・ GitHub の些細な使い方ではなく、円滑なコミュニケーションを促す方法です。円滑なコミュニケーションとは、担当わけや新緑管理、コードや git log を見やすくすることなどなどです。
というわけで、この章では代表的な GitHub の使い方を簡単に説明した上で、今まで説明できなかった git ・ GitHub の tips を紹介したいと思います。
GitHub から ダウンロードして変更してアップロードする
まず、そもそもなぜチーム開発する際に GitHub が必要になるのでしょうか?答えは簡単で、チームでコードを共有するためにはチームメンバーがアクセス可能な場所にコードを置く必要があるからです。インターネット上にある git 管理されたコード置き場のことをリモートリポジトリといいます。また、 GitHub や GitLab などはそういったリモートリポジトリを置かせてくれる ホスティングサービスです。
では、実際に使ってみましょう。GitHub のアカウント作成やレポジトリ作成は、普通の web サービスを使う感覚でできるので解説しません。万が一わからなくてもググれば出ます。
既存のプロジェクトであれ新規のプロジェクトであれ、基本は "Clone or download" というボタンから始まります。ここに https://github.com/mazamachi/InfovisGithubHandson.git や、 git@github.com:mazamachi/InfovisGithubHandson.git のようなリンクが表示されています。
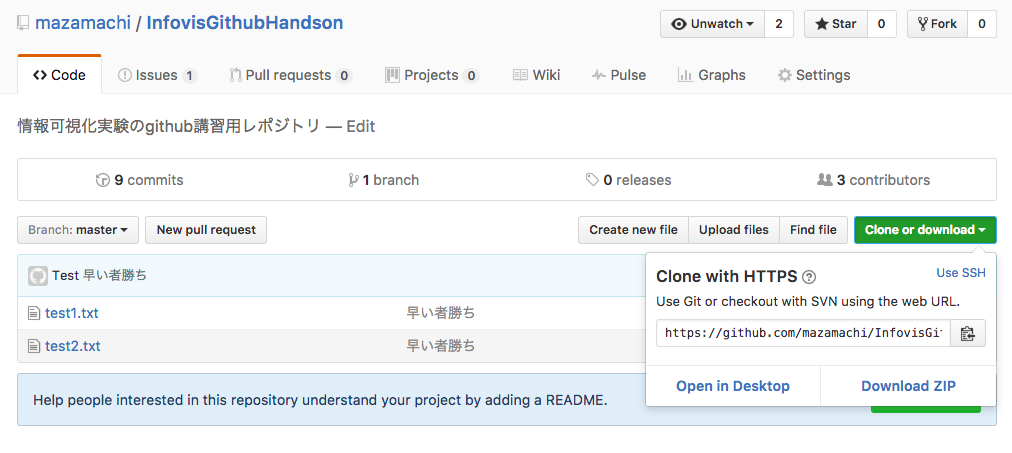
このリンクをコピーして、ターミナルから $ git clone https://github.com/mazamachi/InfovisGithubHandson.git などとします。すると、リポジトリ名の名前のフォルダが作成されました。実際にその中身を見てみると、ファイル内容も git log もリモートリポジトリとそっくりおなじになっていることが見て取れると思います。つまり、その名の通りリモートリポジトリの"クローン"をダウンロードするコマンドが $ git clone <link> なわけです。
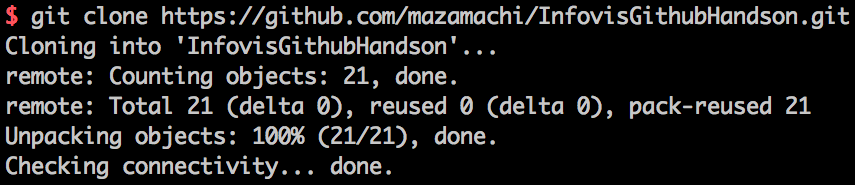
その後、幾つか開発を進めたか、チームの誰かがリモートリポジトリに対して変更を行ったとします。その時、ローカル(自分のPC上の)リポジトリとリモートリポジトリには差異が生じるので、いずれも最新版に更新することが望まれます。
リモートリポジトリに変更があったときは、基本的に $ git pull <branch> とすれば良いです。この "pull"は、ローカルからダウンロードして注目している branch を最新版にすることだと思ってください。ただし、より正確にはダウンロードしたブランチをローカルのブランチに merge することなので、強豪が発生したら解決する必要があります。
一方、自分が branch に変更を加えたらそれを今度はアップロードする必要があります。そのコマンドは $ git push origin <branch> です。origin というのはリモートリポジトリのブランチを示すタグのようなものです。ここでも、リモートリポジトリで競合が発生しないように注意する必要がありますが、競合が発生していたらそもそも基本的に push できないので、一旦 pull してリモートリポジトリの変更を自分のリポジトリに取り込んでから push するだけで良いです。あんまり競合すると大変ですが、それは一人でやっていたときと変わらないのであまり気構える必要はありません。
ただ、わからなかったり間違えて迷惑をかけたりしたときにはチームの人にきちんと質問や謝罪をすることが大事です。これができない人はそもそもチーム開発できません。自分のコミュ力のなさを git に責任転嫁するのはやめましょう。(突然の怒り)
branch と Pull Request で円滑な merge を
先程、開発が終わったら push するだけで良いと言いました。これはもちろん、 branch の基本どおり master ではなくその機能ごとに branch を分けているという前提のものです。もしチーム全員が master に push していたら、 push しようとするたびに conflict を解消する必要がありますが、
1人1 branch しか触っていなければ、他の人のコードが影響するのは maseter に merge するときだけになり、シンプルです。
このように、 master を直接いじることは conflict が頻繁に起こる原因になりやすいので、GitHub を使う際にはリモートリポジトリで merge 作業するのが一般的です。今まではローカルで merge していましたが、どうすればよいのでしょうか?
答えは GitHub の Pull Request という機能を用います。今、 master から add_js ブランチが伸びていたとします。これを push したとき、 GitHub 上に "Compare & pull request" というボタンが現れます。
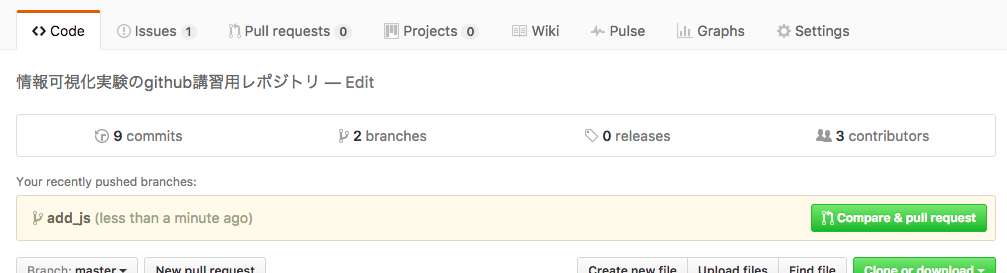
そのボタンを押すと Pull Request が作成でき、Pull Request のタイトルと説明を記述することができます。すなわち、自分がその branch でどんな変更を行ったのかを記述することができるわけです。merge できる状態だったらこのページから mergeを行います。
また、この Pull Request のページは掲示板のスレッドのように利用することもできるため、実装する上で必要なことの記述や他のメンバーとの議論、コードレビューなどをすることができます。
さらに便利なことに、この Pull Request は当然ながらその branch がまだ完成していなくても作成することができます。
というわけで、僕のおすすめとしては
- 作る機能を決定
- その機能向けのbranch を作成
- 空の commit (
$ git commit -m 'first commit' --allow-emptyなどでできます)をしてpush - Pull Request を作成し、その Pull Request でやることを明確にする
- あとは通常通り開発・ commit をしつつ適宜 push する。
という流れを繰り返すのが良いでしょう。
より詳しく知りたい人は GitHub FlowでPull Requestベースな開発フローの進め方 - Qiita を参照してください。
また、上の記事でも触れられていますが、 GitHub には Issue というものもあります。Pull Request に似ているのですが、これは branch と紐付いていません。なので、主に議論をする場所として用いられます。Pull Request はすでに実装することが決まっている機能が主体ですが、Issue では「こんな機能が欲しい」とか「こんなバグが有った」などを話すのが一般的なようです。機能を追加する前に、 Issue で十分に議論を重ねてから Pull Request を作るのが良いでしょう。
さらに、実は commit message に Issue の番号 (#1など) を入れると、 Issue と commit を紐付けることができ、一連の commit の最終的な目標が明確になります。
これらの Issue と Pull Request を効率的に用いて、チームメンバーやTAにわかりやすい開発を心がけましょう。
チームメンバーのためにあなたができること
PR や Issue ほどメジャーではないですが、潤滑なチーム開発をするための git のおもてなしをご紹介します。
細かい add、細めな commit
ある commit について理解したいとき、人はその commit と直前の commit の diff を見ることで、その commit で何が行われたのかを確認します。その際、 diff があまりにも大きいと、commit message でいくら説明していても把握が難しいので、commit は細かいほうが良いです。
ただ、今まで git add コマンドを $ git add <file> として説明していましたが、これではファイルに対して行った変更が大きいとき、そのファイル全体が commit に含まれてしまいます。もしその中の一部が重要な場合はそこだけ抽出して commit にしたほうがわかりやすいです。
その際に用いるのが $ git add -p というパッチオプションです。これは、1つのファイル内での変更を適宜分割したり一部を選びながら add することができるコマンドです。実際に実行すると以下のような画面になります。
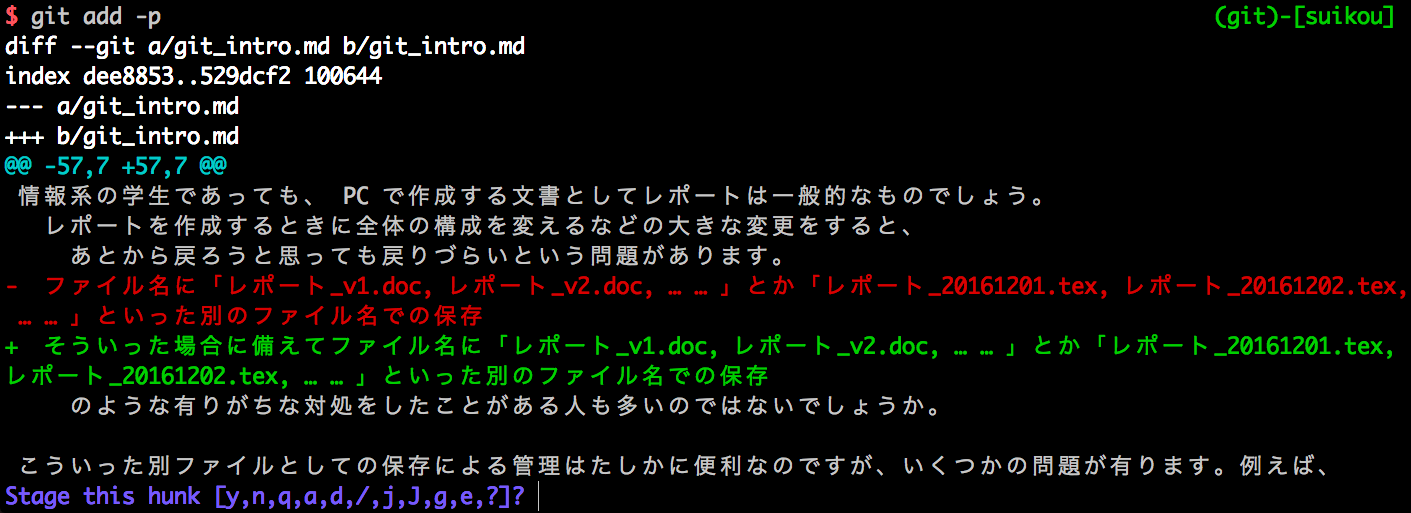
y を押すと add できたり、 ? を押すとヘルプを表示できたりします。詳細は 横着で神経質な私とあなたに贈るgit add -p - Qiita が詳しいです。
ただし、新規作成したファイルはファイル全体を add するしかないようなので、気をつけてください。
[2017/12/05 追記]
嘘です。git add -N file とすると、ファイルの存在だけステージングすることができ、その後ならgit add -p を行うことができます。
僕は最近だと git add -N だけで一旦コミットして、その後 git add -p することが多いです。
直前の commit の修正
git を使っていると、「機能的にはさっきの commit に含めるべきだったのに忘れてた」とか「commit message 間違えた」とかのケアレスミスがしょっちゅう起きます。特に気にする必要はないのですが、そういうときには追加したい変更を add した上で $ git commit --amend とすると、直前の commit を修正できます。いつもの vi の画面が開くので、 commit message を書き換えることなども可能です。
ただし、**このような過去の書き換えは、pushしたあとには絶対に行わないでください。**というのも、pushしたあとで過去を書き換えてしまうとリモートリポジトリにとっては時間軸が2つあってどちらが正しいのかわからない状態になってしまうわけです。無理やりpushできたとしても、それを修正するためにはチームメンバー全員が煩雑な作業を行う必要があるわけです。
ちなみに、僕が昨年度実験で git のソースコードをいじったときの内容はこの辺に関連するので、よかったら見てみてください。gitに新機能を追加してgit masterを目指す(応用編) - クフでダローバルな日記
危険性もある一方で「git では過去の書き換えができる」というのはなかなか面白く、個人で使う分にはかなり便利なのでこの事実は頭の片隅に入れといておきましょう。
おわりに
どうでしたでしょうか、git はいいぞという宗教観はうまく伝わっているでしょうか。
gitはどうしても実際に使ってみないことにはなれないので、この記事だけ読んでもつかえるようになるのは難しいかもしれません。ただ、git を使うとうれしいことが多そうだとか、今度レポートを書くときには一人で git をつかってみようか、といった気持ちにさせることができていたら幸いです。
明日のeeic advent calendar は D_plius さんの「自己評価が低い人のための乱数で決める人生」です。
ところで……クリスマスが近いですね? サンタさん待ってます!!
参考文献
-
こわくない Git
- とても分かりやすく説明も必要十分な感じがします。スライドとしてもとてもきれいなのでご一読をおすすめします。
-
本当の初心者向け! Git 入門のための概念から基本用語まで | Git編:一歩踏み出すフロントエンド入門
- gitのメリットの説明はとてもわかり易いです。比喩のところはとてもわかりづらい気がするので読まなくて良いです。
-
開発フロー研修 @ Wantedly - Qiita
- 僕は3年の春休みに2月ほど Wantedly でインターンしていたのですが、ここで実際に経験した開発フローが後々もかなり生きているので、少し長いですが読んでみることをおすすめします。