はじめに
Cephはスケーラブルで高パフォーマンスな分散ストレージシステムです。分散ストレージなので、ファイルやデータを複数のストレージ(HDDやSSD等)にまたがって保存します。
より特徴的なのが、ファイルが一つのストレージにまとまって保存されるのではなく、分割されて複数のストレージに分散して保存される点です。この手法は「ストライピング(RAID0)」と呼ばれます。
ストライピングにより、データの読み書きが並列処理で行われるため、I/Oパフォーマンスの向上が見込めます。例えば、あるファイルがHDD1台に格納されている場合と、HDD3台に分割して保存されている場合を比較すると、後者の方が各HDDにかかる負荷が分散されます。その結果、ストレージ全体でのスループットやIOPSが向上することが期待されます。
Cephのストライピングの仕組みについては、以下の記事が参考になります
https://docs.ceph.com/en/mimic/architecture/#data-striping
今回は「Cephが本当に分散ストレージなのか?」を検証するために、大容量のファイルを作成し、そのデータが複数のストレージに分散して格納される様子を確かめてみました。
Cephクラスターの概要
Cephクラスターは、Kubernetes上でRook Cephを使って作成します。
スペックおよび利用するツール
AWSのEC2インスタンスに作成したKubernetesを使います。以下のようなスペックです。
- Control Plane(1台)
- EC2インスタンス
- OS : Ubuntu 22.04
- インスタンスタイプ : t3a.small(2vCPU, 2GiBメモリ)
- EC2インスタンス
- Worker Node(3台)
- EC2インスタンス
- OS : Ubuntu 22.04
- インスタンスタイプ : t3a.small(2vCPU, 2GiBメモリ)
- EBSボリューム(OSD用)
- タイプ : gp3
- サイズ : 5GiB
- スループット : 125(デフォルト)
- IOPS : 3000(デフォルト)
- EC2インスタンス
図で表すと、以下のような状態になります。AWSリソースを黒色、k8sのコンポーネントを青色で書いています。
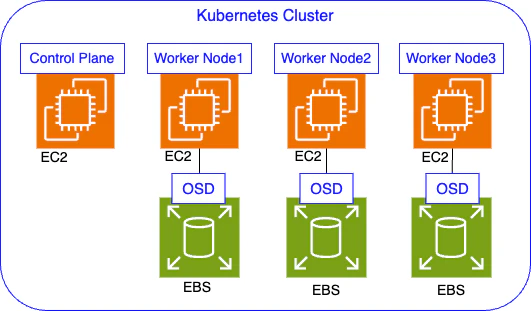
Cephクラスターの構成
Cephクラスター上に、RADOS Block Device(RBD)用のプールを作ります。ファイルやデータを読み書きするCephのクライアントから見ると、RBDは外付けHDDのように認識されます。
クライアントがファイルを作成すると、クライアント側では一つのファイルとして認識されますが、実際のデータはストライピングによって3つのストレージデバイス(=EBS)に分割されて保存されます。以下がその様子を表したものです。
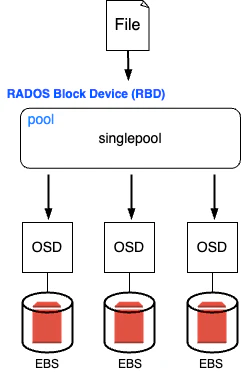
Cephクラスターの構築
筆者記事になりますが、以下のQiitaを参考にしてCephクラスターを作ります。
大きくは、以下の3つの手順に分かれます。
- AWSリソース(EC2やEBS等)の作成
- KubernetesクラスターおよびCNIの構築
- Rook Cephをインストールして、Cephクラスターを構築
今回利用したCeph関連ツールのバージョンは以下です。
- Rook Ceph:v1.16.1
- Ceph:v19.2.0
RBDの作成
CephBlockPool の作成
外付けHDDに相当するRBDを作成します。
Kubernetesでは、CephBlockPool というカスタムリソースを使ってRBD用のプールを作成します。以下がそのマニフェストです。
apiVersion: ceph.rook.io/v1
kind: CephBlockPool
metadata:
name: singlepool
namespace: rook-ceph
spec:
replicated:
size: 1
レプリカ数を1にしている理由
データのレプリカ数(=spec.replicated.size)は、今回はデータがストライピングにより分散されることを検証したいため、1にしています。
本来はレプリカ数は3以上に設定するのが推奨です。しかし、レプリカ数を増やすと、データの分散がストライピングだけでなくレプリケーションによっても発生します。その結果、データの分散がストライピングによるものかレプリケーションによるものかの判別が必要となります。今回はストライピングによるデータの分散のみを確認したいので、レプリカ数は1(レプリカ無し)にしています。
以下のコマンドで、リソースを作成します。
kubectl apply -f cephblockpool.yaml
リソースが作成されたことを確認します。
$ kubectl get cephblockpool -n rook-ceph
NAME PHASE TYPE FAILUREDOMAIN AGE
singlepool Ready Replicated host 38h
CephのCLIから、singlepoolというプールが生成されたことも確認できます。
$ kubectl exec -it -n rook-ceph deploy/rook-ceph-tools -- ceph osd pool ls
.mgr
singlepool
StorageClass の作成
RBDのプールをKubernetes経由で利用可能にするため、StorageClass を作成します。
YAMLが長いので、折りたたみでマニフェストを載せます。
rook-ceph-block.storageclass.yaml(折りたたみ)
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: rook-ceph-block
provisioner: rook-ceph.rbd.csi.ceph.com # csi-provisioner-name
parameters:
# clusterID is the namespace where the rook cluster is running
# If you change this namespace, also change the namespace below where the secret namespaces are defined
clusterID: rook-ceph # namespace:cluster
# If you want to use erasure coded pool with RBD, you need to create
# two pools. one erasure coded and one replicated.
# You need to specify the replicated pool here in the `pool` parameter, it is
# used for the metadata of the images.
# The erasure coded pool must be set as the `dataPool` parameter below.
#dataPool: ec-data-pool
pool: singlepool
# (optional) mapOptions is a comma-separated list of map options.
# For krbd options refer
# https://docs.ceph.com/docs/master/man/8/rbd/#kernel-rbd-krbd-options
# For nbd options refer
# https://docs.ceph.com/docs/master/man/8/rbd-nbd/#options
# mapOptions: lock_on_read,queue_depth=1024
# (optional) unmapOptions is a comma-separated list of unmap options.
# For krbd options refer
# https://docs.ceph.com/docs/master/man/8/rbd/#kernel-rbd-krbd-options
# For nbd options refer
# https://docs.ceph.com/docs/master/man/8/rbd-nbd/#options
# unmapOptions: force
# (optional) Set it to true to encrypt each volume with encryption keys
# from a key management system (KMS)
# encrypted: "true"
# (optional) Use external key management system (KMS) for encryption key by
# specifying a unique ID matching a KMS ConfigMap. The ID is only used for
# correlation to configmap entry.
# encryptionKMSID: <kms-config-id>
# RBD image format. Defaults to "2".
imageFormat: "2"
# RBD image features
# Available for imageFormat: "2". Older releases of CSI RBD
# support only the `layering` feature. The Linux kernel (KRBD) supports the
# full complement of features as of 5.4
# `layering` alone corresponds to Ceph's bitfield value of "2" ;
# `layering` + `fast-diff` + `object-map` + `deep-flatten` + `exclusive-lock` together
# correspond to Ceph's OR'd bitfield value of "63". Here we use
# a symbolic, comma-separated format:
# For 5.4 or later kernels:
#imageFeatures: layering,fast-diff,object-map,deep-flatten,exclusive-lock
# For 5.3 or earlier kernels:
imageFeatures: layering
# The secrets contain Ceph admin credentials. These are generated automatically by the operator
# in the same namespace as the cluster.
csi.storage.k8s.io/provisioner-secret-name: rook-csi-rbd-provisioner
csi.storage.k8s.io/provisioner-secret-namespace: rook-ceph # namespace:cluster
csi.storage.k8s.io/controller-expand-secret-name: rook-csi-rbd-provisioner
csi.storage.k8s.io/controller-expand-secret-namespace: rook-ceph # namespace:cluster
csi.storage.k8s.io/node-stage-secret-name: rook-csi-rbd-node
csi.storage.k8s.io/node-stage-secret-namespace: rook-ceph # namespace:cluster
# Specify the filesystem type of the volume. If not specified, csi-provisioner
# will set default as `ext4`. Note that `xfs` is not recommended due to potential deadlock
# in hyperconverged settings where the volume is mounted on the same node as the osds.
csi.storage.k8s.io/fstype: ext4
# uncomment the following to use rbd-nbd as mounter on supported nodes
# **IMPORTANT**: CephCSI v3.4.0 onwards a volume healer functionality is added to reattach
# the PVC to application pod if nodeplugin pod restart.
# Its still in Alpha support. Therefore, this option is not recommended for production use.
#mounter: rbd-nbd
allowVolumeExpansion: true
reclaimPolicy: Delete
同じマニフェストは、以下のGitHubリポジトリにも格納しています。
上記のマニフェストを使って、次のコマンドでStorageClassを作成します。
kubectl apply -f rook-ceph-block.storageclass.yaml
StorageClassが作成されたことを確認します。
$ kubectl get storageclass
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
rook-ceph-block rook-ceph.rbd.csi.ceph.com Delete Immediate true 43h
※ CephBlockPoolとStorageClassのマニフェストは、こちらのサンプルをもとにして作っています。
ボリューム(PVC)の作成
RBDのStorageClassを使って、クライアントからマウント可能なボリュームを作成します。
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: rook-ceph-block-pvc
namespace: default
spec:
storageClassName: rook-ceph-block
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Gi
次のコマンドでPVCリソースを作成します。
kubectl apply -f rook-ceph-block.pvc.yaml
PVCが作られたのを確認します。
$ kubectl get pvc -n default
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS VOLUMEATTRIBUTESCLASS AGE
rook-ceph-block-pvc Bound pvc-0be27c77-4311-4711-a0dd-9749ed58b84d 10Gi RWO rook-ceph-block <unset> 43h
(参考)PVCとRBDイメージの対応
上記でPVCの情報を出力した際、3列目のVOLUMEに、pvc-0be27c77-4311-4711-a0dd-9749ed58b84dと書かれています。これは、PVC作成時に動的プロビジョニングによってPVも同時に作られた事を意味します。
このPVのマニフェストを覗いてみると、volumeHandleにrook-cephというワードが含まれたボリュームIDが書かれているのを確認できます。
$ kubectl get pv pvc-0be27c77-4311-4711-a0dd-9749ed58b84d -oyaml | grep volumeHandle
volumeHandle: 0001-0009-rook-ceph-0000000000000002-9c911d92-3168-4920-b12d-1730f8f7d948
このPVCに対応するRBDのイメージは、Ceph CLIで以下のコマンドで確認できます。
$ kubectl exec -it -n rook-ceph deploy/rook-ceph-tools -- rbd ls singlepool
csi-vol-9c911d92-3168-4920-b12d-1730f8f7d948
後半の 9c911d92-3168-4920-b12d-1730f8f7d948 がPVのvolumeHandleとRBDイメージで共通しており、Kubernetesで作成したリソースがCephとしっかり連動している事がわかります。
データが分散して格納されることの確認
ようやく準備が整いました。
ここからは、Ceph(RBD)のクライアントが作成した大容量のファイルが、それぞれのストレージ(≒OSD)に分散して格納されることを確認していきます。
ディスク利用状況の確認(ファイル作成前)
まずは、現在の各OSDの利用状況をCephのCLIで確認します。
$ kubectl exec -it -n rook-ceph deploy/rook-ceph-tools -- ceph osd df
ID CLASS WEIGHT REWEIGHT SIZE RAW USE DATA OMAP META AVAIL %USE VAR PGS STATUS
1 ssd 0.00490 1.00000 5 GiB 30 MiB 1.2 MiB 10 KiB 28 MiB 5.0 GiB 0.58 1.00 11 up
0 ssd 0.00490 1.00000 5 GiB 29 MiB 1.2 MiB 11 KiB 28 MiB 5.0 GiB 0.58 1.00 9 up
2 ssd 0.00490 1.00000 5 GiB 29 MiB 1.2 MiB 12 KiB 28 MiB 5.0 GiB 0.58 1.00 15 up
TOTAL 15 GiB 89 MiB 3.7 MiB 34 KiB 85 MiB 15 GiB 0.58
MIN/MAX VAR: 1.00/1.00 STDDEV: 0
DATAの列を見ると、それぞれのOSDで合計1.2MiBのデータが格納されていることがわかります。
RBDをマウントするPodの作成
RBDイメージにファイルを作成するためのPodを、以下のマニフェストでデプロイします。
apiVersion: v1
kind: Pod
metadata:
name: mnt-rbd
namespace: default
spec:
containers:
- name: mnt-rbd
image: busybox
command:
- tail
- -f
- /dev/null
volumeMounts:
- name: rbd-volume
mountPath: /data
volumes:
- name: rbd-volume
persistentVolumeClaim:
claimName: rook-ceph-block-pvc
Pod作成コマンドは以下です。
kubectl apply -f mnt-rbd.pod.yaml
程なくして、RBDをマウントしたPodが作成されます。
$ kubectl get po -n default
NAME READY STATUS RESTARTS AGE
mnt-rbd 1/1 Running 0 19s
Pod内の/dataディレクトリが、RBDでマウントされていることを確認できます。
$ kubectl exec -it -n default mnt-rbd -- df -h | grep /data
/dev/rbd0 9.7G 24.0K 9.7G 0% /data
ファイル作成 → 分散されていることの確認
mnt-rbdのPod上で3GiBの大容量ファイルを作成します。
kubectl exec -it -n default mnt-rbd -- sh
(Pod内で実行)
/ # dd if=/dev/zero of=/data/test_file bs=1M count=3072
/dataディレクトリに、確かに3GiBのファイルが作成されたのが確認できます。
(Pod内で実行)
/ # ls -l /data
total 3145748
drwx------ 2 root root 16384 Jan 5 04:08 lost+found
-rw-r--r-- 1 root root 3221225472 Jan 5 04:18 test_file
続いて、CephのCLIでOSDの利用状況を確認してみます。
$ kubectl exec -it -n rook-ceph deploy/rook-ceph-tools -- ceph osd df
ID CLASS WEIGHT REWEIGHT SIZE RAW USE DATA OMAP META AVAIL %USE VAR PGS STATUS
1 ssd 0.00490 1.00000 5 GiB 1006 MiB 973 MiB 10 KiB 32 MiB 4.0 GiB 19.64 0.95 11 up
0 ssd 0.00490 1.00000 5 GiB 758 MiB 730 MiB 11 KiB 28 MiB 4.3 GiB 14.80 0.72 9 up
2 ssd 0.00490 1.00000 5 GiB 1.4 GiB 1.3 GiB 12 KiB 32 MiB 3.6 GiB 27.53 1.33 15 up
TOTAL 15 GiB 3.1 GiB 3.0 GiB 34 KiB 93 MiB 12 GiB 20.66
MIN/MAX VAR: 0.72/1.33 STDDEV: 5.25
DATAの列を見ると、各OSDの値が1.2MiBから1GiB程度に増えて、3GiBのファイルが分散されて格納されていることを確認できました。
おわりに
「Cephのデータが一つのファイルでも複数ストレージに分散されている」ことを何となくは理解していたのですが、今回の検証を行うことで、より理解を深められました。