本記事について
乱数に関する理解を深め、乱数を使うプログラムにおいて、再現性の有無をコントロールできるようになることを目標とする。
特にデータサイエンス・数値計算系の分野で乱数を使う方を想定読者としているが、乱数に関する説明は事前知識なく読むことができる。
実務における乱数
DS系の実務において乱数を用いるシーンは非常に多い:
- 機械学習
- 学習データ/テストデータをランダムに分割する
- 学習に用いるミニバッチをランダムに選択する
- シミュレーション
- 離散イベントシミュレーションにおいてランダムな時間間隔でイベントを発生させる
- 人流シミュレーションにおいてランダムに目的地を選択する
- 交通シミュレーションにおいて経路選択をランダムに行う
- 数理最適化
- 初期解をランダムな解に設定する
- 近傍探索アルゴリズムにおいて解の遷移先をランダムに選択する
場合によっては自分で実装していない部分(ライブラリの内部)で使われていることもあるため、乱数がどこで使われているのかよく注意して把握しておく必要がある。
疑似乱数と乱数シード
計算機において真のランダムな数の系列をとることは難しい。そのため実際には所定のアルゴリズムに従ってランダムに見える系列をとることになる(疑似乱数)。
アルゴリズムとしてはメルセンヌ・ツイスタ、PCG など多数あるが、実用上は信頼できるライブラリが提供している実装を使えば良い。疑似乱数には備えるべき望ましい性質(再現性を担保する仕組みがある、周期が長い、等)があるが、広く使われているライブラリであればそれらを備えていることが多いためである1。
実務で疑似乱数を使う際には、再現性を確保したい/確保したくないのいずれであるかを意識することが重要である。
例えば以下のようなケースでは再現性を確保し、実行のたびに同じ結果が得られるようにする必要がある:
- モデル学習/評価を再現するために、同一の学習データ/テストデータ分割を行いたい
- シミュレーション設定を変えてもイベントの発生の仕方は変わらないようにしたい
- 同じ最適化問題に対し、異なる計算環境で同一の最適化結果を得たい
一方で、以下のようなケースでは再現性は必要なく、実行のたびに異なる結果が得られるようにしたい:
- 学習データ/テストデータの分割を何通りも試して学習と評価を繰り返し行い、汎化誤差の程度を見積もりたい
- 複数回のシミュレーションを行い、ランダムな挙動によるばらつきの大きさを評価したい
- 複数のランダムな初期解から最適化を行い、より良い解を探したい
疑似乱数の実装において、再現性の有無は乱数シードを指定するかどうかで制御することができる。
疑似乱数生成器(=疑似乱数を生み出す、内部状態をもったオブジェクト)を初期化する際に乱数シードを指定することで、同じ乱数系列を返す生成器が得られる。
乱数シードを指定しない場合の挙動はライブラリの実装によるが、現在時刻など再現性の少ない値が使われ、異なる乱数系列を返す生成器が得られる。
「乱数が固定される」ことがイメージできない人がしばしばいる (e.g.「ランダムなのに決まっているってどういうこと?」) が、次のように考える(or 説明する)とよいだろう:
- 乱数が固定されていない場合、サイコロを毎回振るイメージ
- 乱数が固定されている場合、あらかじめサイコロを振った結果を記載した表があり、その表を上から順に読んでいくイメージ
- 乱数シードの値ごとに表が準備されており、乱数シードを指定するとどの表を使うかが決定される
- 乱数生成器を初期化しなおすと読み込む場所が表の先頭に戻る
乱数生成器の扱い方
どのプログラミング言語でも疑似乱数の利用方法はおおまかには以下のような流れになる:
- 疑似乱数生成器 (
rngと称する) の初期化- ここで引数として乱数シードを与えることができる
- ランダム値関数にパラメータとして
rngを与えて所望の乱数を得る- ランダム値関数は、一様分布からのサンプリング、ガウス分布からのサンプリング、のようにライブラリによって提供されている
- 言語によっては
rngのメソッドとして実装されていることもある
ライブラリによってはグローバルな乱数系列およびその乱数シードを固定する関数が用意されていることも多い(Python であれば、random モジュールの random.seed() など)。
この場合、モジュールレベルで上記の rng に相当する乱数生成器が定義されており、乱数シードを固定する関数を呼ぶとその乱数生成器がシード付きで初期化されることになる。
グローバルな乱数系列を用いる場合、再現性の担保が難しくなるため要注意。グローバルな乱数を用いる箇所を1つでも変更すると、全体の系列がずれてしまうのである。
例えば乱数を使用する2つの処理 A,B を順に実行する場合を考える。
プログラムの最初にグローバルな乱数シードを固定する実装の場合、A→B をこの順に実行している限りは毎回同じ結果が得られる。しかし、処理の順序を逆にしたり (B→A)、間にグローバルな乱数を使用する他の処理を挟む (A→C→B) と個々の処理の結果が変化してしまう2。
このようなことを避けるためには以下のような習慣に従うのが好ましい:
- 処理単位ごとに乱数生成器を用意し、処理単位の中ではその乱数生成器のみを用いる
「処理単位」の部分はクラス単位、あるいはクラスのインスタンス単位のほうが好ましいケースもあるかもしれない。
重要なのは、ある部分で乱数を使ったことの影響がプログラム中の他の処理に影響しないように設計することである。
自己完結的なプログラム(他のプログラムから呼び出されることがない)であって、まるっとプログラム全体で再現性が取れれば良い、という場合はグローバルな乱数系列を用いるのでも良いだろう。
実装例
以下、Pytyon の利用を想定する。
Python で乱数を利用には、標準ライブラリの random モジュールを用いるか、numpy.random モジュールを用いる。
乱数を大量に使用する場合(大きなサイズのランダム配列が必要、など)
グローバルな乱数系列を用いる例
random モジュールを用いた例を示す。
import random
SEED = 0
print("set seed", SEED)
random.seed(SEED)
print(random.random())
print(random.random())
print(random.random())
random.seed(SEED)
print("set seed", SEED)
print(random.random())
print(random.random())
print(random.random())
SEED = 1
random.seed(SEED)
print("set seed", SEED)
print(random.random())
print(random.random())
print(random.random())
実行結果
set seed 0
0.8444218515250481
0.7579544029403025
0.420571580830845
set seed 0
0.8444218515250481
0.7579544029403025
0.420571580830845
set seed 1
0.13436424411240122
0.8474337369372327
0.763774618976614
random.seed(SEED) 文で random モジュールのグローバルなシードを固定したのち、random.random() 関数によってグローバルな乱数生成器から [0,1) 区間の一様乱数を取得している。
以下のことがわかる:
- シードを固定しなおすと同じ乱数が得られる
- 異なるシードを指定すると異なる乱数が得られる
random モジュールには一様乱数以外にも様々な分布から乱数を得る方法が提供されている。詳しくは公式ドキュメントを参照。
乱数生成器を個別に取得する例
numpy.random モジュールを利用する例を示す。
import numpy as np
class Hoge:
def __init__(self, seed, name):
self.seed = seed
self.name = name
self.reset_rng()
def reset_rng(self):
self.rng = np.random.default_rng(self.seed)
def action(self):
print(f"{self.name} outputs {self.rng.random()}")
hoge0 = Hoge(0, name="hoge0")
hoge1 = Hoge(0, name="hoge1")
hoge0.action()
hoge1.action()
hoge0.reset_rng()
hoge0.action()
hoge1.action()
実行結果
hoge0 outputs 0.6369616873214543
hoge1 outputs 0.6369616873214543
hoge0 outputs 0.6369616873214543
hoge1 outputs 0.2697867137638703
この例では Hoge クラスのインスタンスごとに乱数生成器を保持させて、乱数を使う処理 action() では自身の乱数生成器を使うように実装している。
処理の流れは以下のようになっている:
- インスタンスの初期化時に
numpy.random.default_rng()関数によって乱数生成器を取得-
hoge0,hoge1ともに同じシード値を指定している
-
-
action()メソッドを1回ずつ呼び出す。両者は異なる乱数生成器を持つがシード値が同じのため、同じ値が得られる -
hoge0のみ乱数生成器を再取得する -
action()メソッドを1回ずつ呼び出す。hoge1は初回と異なる値が得られる一方、乱数生成器を再取得したhoge0は初回と同じ値が得られる。
2つのインスタンス間で影響が及ばないようになっていることが確認できる。
補足: 計算時間について
乱数を生成する処理は(四則演算などと比べると)1回あたりの処理時間が大きい:
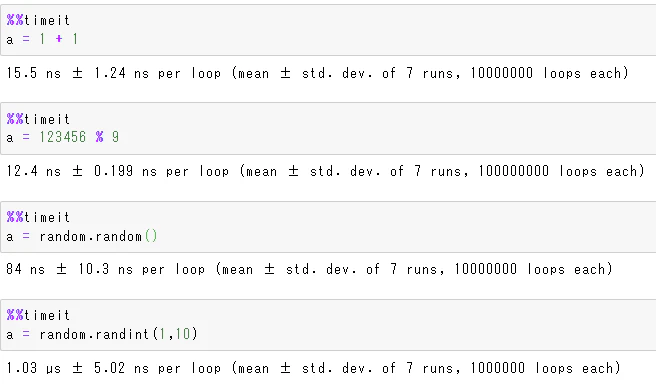
そのため、大量に乱数を使うプログラムを作る際は以下のような注意が必要:
- 極力
numpy.randomモジュールを利用し乱数を用いる処理を配列演算で一括で行うようにする - (それでも遅い場合) 乱数は(10万個など)ある程度の個数を先に計算してリストに保持おき、リストの要素を順繰りに用いるような実装にする
- そもそも、乱数を使う頻度を減らせないか検討する
以下に numpy による乱数取得の例を載せる。
numpy.random の関数の引数の説明や、他にどのような乱数生成ができるかについては公式ドキュメントを参照。

↑ N 個の乱数列を取得するために、Python の for 文を使う代わりに numpy で配列で取得することで 10 倍程度高速化している。
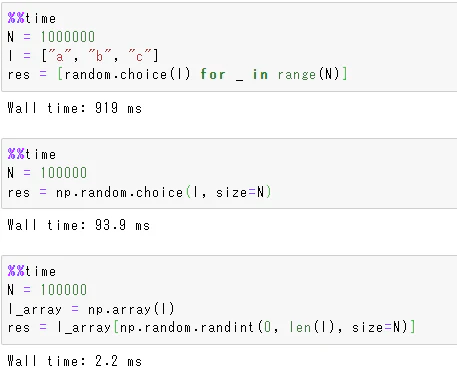
↑ リストから N 回ランダムサンプリングする場合も、numpy で配列で取得することで 10 倍程度高速化する(上段, 中段)。リストの要素ではなく配列の添字をランダムサンプリングし、配列アクセスを行うことでさらに 50 倍ほど高速化する (下段)。
大きな for 文の代わりに numpy の配列演算を使うのは乱数に限らず高速な Python プログラムを作るために重要である。