本記事はこちらのブログの抄訳です
このブログでは、MLOps の重要性の高まりと、Walgreens Boots Alliance (WBA) と Databricks が共同開発した MLOpsアクセラレータについて紹介します。MLOpsアクセラレータは、MLプラクティスを標準化し、MLモデルを生産する時間を短縮し、データ サイエンティストと MLエンジニア間のコラボレーションを促進し、ビジネス価値と AIへの投資収益を生み出すように設計されています。この投稿全体を通して、Databricks Lakehouse PlatformでのMLOpsのアプリケーション、WBAがMLOpsを自動化および標準化する方法、およびそれらの成功を再現する方法について説明します。
MLOpsとは?なぜ必要なのか?
MLOpsとは、DevOps+DataOps+ModelOpsによって構成され、組織がコード、データ、およびモデルを管理するのに役立つ一連のプロセスと自動化のことを指します。

しかし、MLOps を実践するには課題が伴います。機械学習 (ML) システムでは、モデル、コード、データはすべて時間の経過とともに進化し、更新スケジュールと MLパイプラインに摩擦が生じる可能性があります。一方、モデルの再トレーニングが必要になるデータドリフトにより、モデルのパフォーマンスは時間の経過とともに低下する可能性があります。さらに、データ サイエンティストがデータセットを調査し続け、モデルを改善するためにさまざまなアプローチを適用すると、より適切に機能する新しい特徴量や他のモデルファミリーが見つかる可能性があります。そして、コードを更新して再デプロイします。
成熟した MLOps システムには、ML パイプラインをテストおよびデプロイする堅牢で自動化された継続的インテグレーション/継続的デプロイ (CI/CD) システムと、継続的トレーニング (CT) および継続的モニタリング (CM) が必要です。モニタリング パイプラインは、モデルのパフォーマンスの低下を特定し、自動再トレーニングをトリガーできます。
MLOps のベスト プラクティスにより、データ サイエンティストは、特徴量エンジニアリング、モデル アーキテクチャ、ハイパーパラメータに関する新しいアイデアを迅速に調査して実装し、新しいパイプラインを自動的に構築、テストして、運用環境にデプロイできます。堅牢で自動化された MLOps システムは、アイデアからビジネス価値の向上まで、組織の AI イニシアチブを強化し、データと ML への投資収益を生み出します。
WBA が Lakehouse で ML と分析を加速した方法
最大規模の小売薬局の 1 つであり、健康と福祉の大手企業である Walgreens は、ML と分析のニーズが高まるにつれて、レイクハウスアーキテクチャに移行しました。Azure Databricks は最適なデータ プラットフォームになりましたが、Delta Lake は、ML、分析、およびレポートのユースケースに使用される精選されたデータとセマンティックデータの両方のソースです。
テクノロジーに加えて、イノベーションを実現するための方法論も変化しています。変革前は、各ビジネス ユニットが ML と分析を個別に担当していました。変革の一環として、Walgreens Boots Alliance (WBA) は IT 組織の下に、ML や分析などのデータの活性化を一元化する組織を設立しました。このプラットフォームはビジネスニーズを本番化する手助けをし、発見を実行可能な生産ツールへ変化させるのを加速させます。
ウォルグリーン社内では、レイクハウスがMLとアナリティクスの力を引き出した多くの事例があります。例えば、RxAnalyticsは、個々の医薬品カテゴリーと店舗の在庫レベルと返品を予測するのに役立ちます。これは、コスト削減と顧客需要のバランスをとるために、どちらも重要です。また、小売業界においても、Retail Working Capitalのようなプロジェクトで同様のMLアプリケーションが提供されています。
WBAのユースケースは、薬局、小売、金融、マーケティング、ロジスティクスなど多岐にわたっています。これらすべてのユースケースの中心にあるのが、Delta LakeとDatabricksです。彼らの成功により、私たちは組織全体でML開発を標準化するためのベストプラクティスを確立したMLOpsアクセラレータを共同で構築し、プロジェクトの初期化から本番稼働までの時間を1年以上からわずか数週間に短縮することに成功しました。次は、WBAのMLOpsアクセラレータのデザイン選択について掘り下げます。
デプロイ コード パターンを理解する
主な MLOps デプロイ パターンには、「モデルのデプロイ」と「コードのデプロイ」の 2 つがあります。モデルのデプロイの場合、モデル アーティファクトは環境間で昇格されます。ただし、これにはいくつかの制限があります、The Big Book of MLOpsで詳細に概要を説明します。対照的に、コードのデプロイは、リソース構成や ML パイプライン コードを含む ML システム全体の唯一の信頼できるソースとしてコードを使用し、環境間でコードを昇格させます。コードのデプロイは、すべての ML パイプライン (つまり、特徴量エンジニアリング、トレーニング、推論、監視) の自動テストと展開を CI/CD に依存しています。これにより、以下の図に示すように、各環境のトレーニング パイプラインを介してモデルが適合されます。要約すると、デプロイ コードは、パイプラインから生成されたモデルの再トレーニングとデプロイを自動化できる ML パイプライン コードをデプロイすることです。
監視パイプラインは、本番環境でのデータとモデルのドリフト、またはオンライン/オフライン データ間のスキューを分析します。データがドリフトしたり、モデルのパフォーマンスが低下したりすると、モデルの再トレーニングがトリガーされます。これは、基本的に、更新されたデータセットを使用して同じコード リポジトリからトレーニング パイプラインを再実行するだけであり、モデルの新しいバージョンが生成されます。モデリング コードまたはデプロイ構成が更新されると、プル リクエストが送信され、CI/CD ワークフローがトリガーされます。
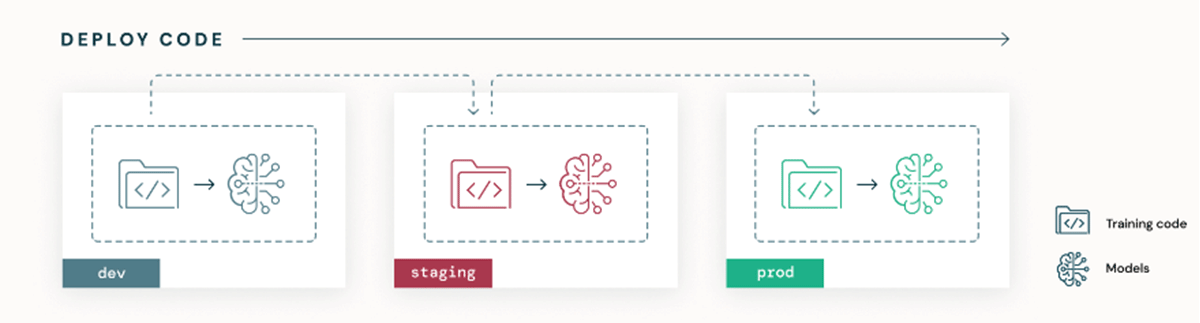
組織が開発環境またはステージング環境から本番データへのデータ サイエンティストのアクセスを制限している場合、コードをデプロイすることで、アクセス制御を尊重しながら本番データのトレーニングが可能になります。データ サイエンティストにとっての学習曲線が急で、リポジトリ構造が比較的複雑であることは欠点ですが、デプロイ コード パターンを長期にわたって採用することで、コラボレーションが促進され、シームレスに自動化された再現可能なプロセスで ML パイプラインを運用できるようになります。
このデプロイ コード パターンとその利点を紹介するために、WBA の MLOps アクセラレータと、インフラストラクチャのデプロイ、CICD ワークフロー、および ML パイプラインの実装について説明します。
WBA MLOps アクセラレータの概要
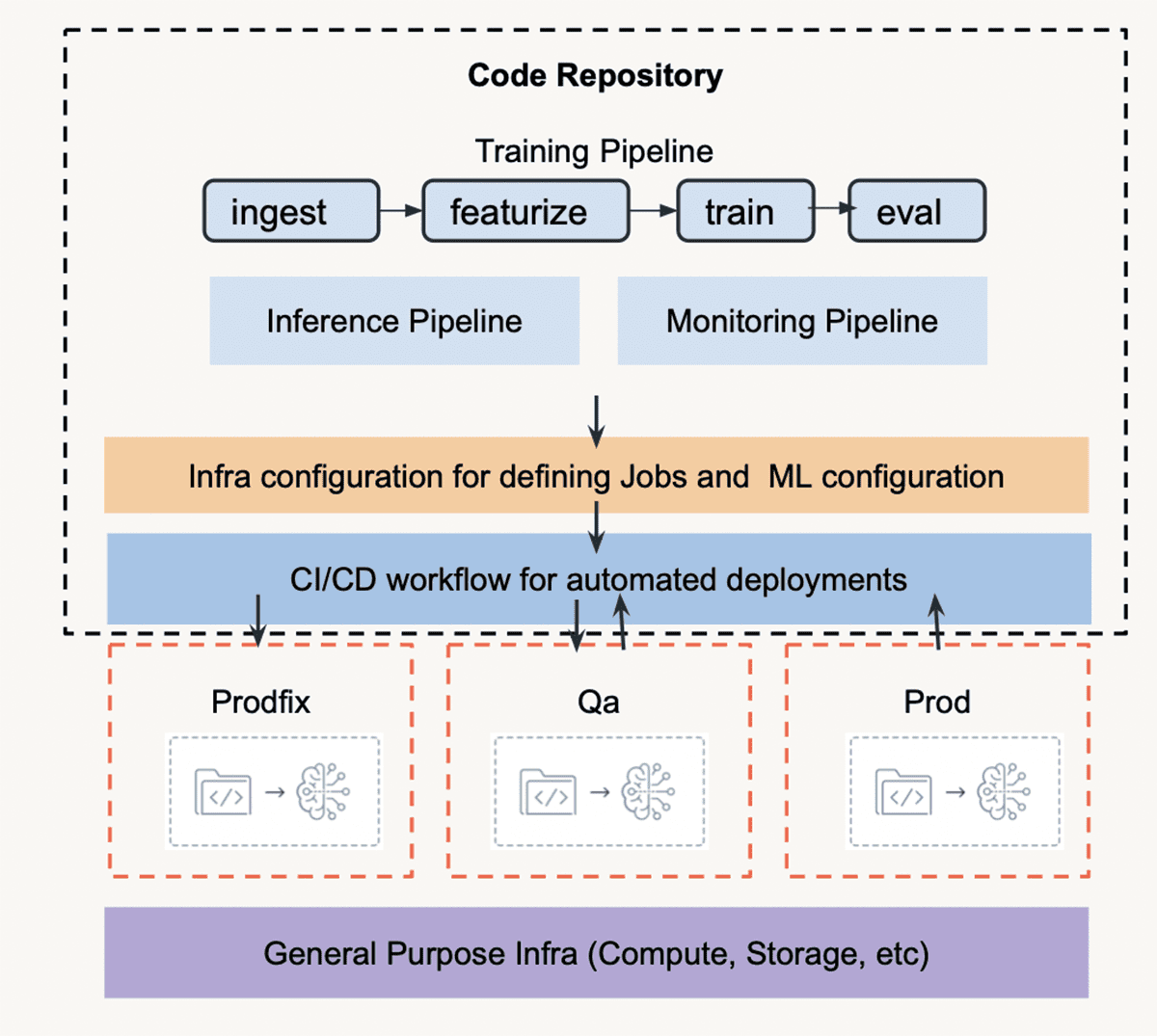
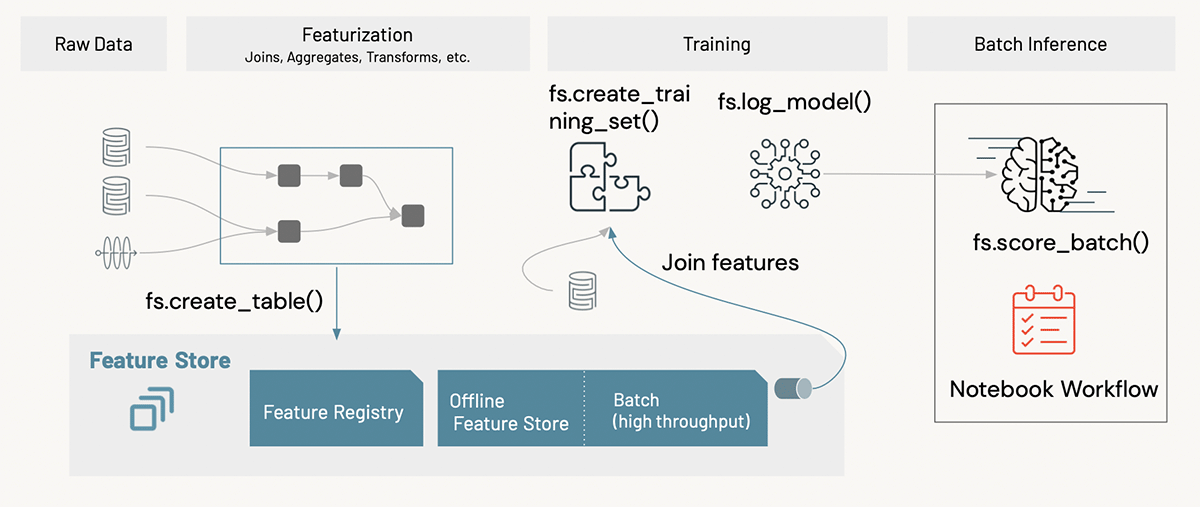
まず、スタックを見てみましょう。WBA は、インフラストラクチャをデプロイし、Databricks ワークスペースを大規模にプロビジョニングするための社内ツールを開発しています。WBA は、CI/CD とバージョン管理にそれぞれ Azure DevOps と Azure Repos を活用しています。Databricks と WBA が共同開発した MLOps アクセラレータは、Databricks ワークスペースとフォークして統合し、ノートブック、ライブラリ、ジョブ、init スクリプトなどをデプロイできるリポジトリです。事前定義された ML ステップ、ML パイプラインを駆動するノートブック、CI/CD 用の事前構築済み Azure パイプラインが提供され、構成ファイルを更新するだけですぐに実行できます。DataOps 側では、Delta Lake と特徴量管理用にDatabricks Feature Storeを使用します。モデリング実験は、MLflow で追跡および管理されます。さらに、本番環境でのデータ ドリフトを監視し、実験プラットフォームに一般化するために、Databricks のプレビュー機能であるモデル監視を採用しました。
以下に示すアクセラレータ リポジトリ構造には、ML パイプライン、構成ファイル、CI/CD ワークフローの 3 つの主要コンポーネントがあります。アクセラレータ リポジトリは、CI/CD ワークフローを使用して、対応する環境の各 Databricks ワークスペースに同期されます。WBA では、開発作業に Prodfix、テストに QA、本番環境に Prod を使用しています。Azure リソースとその他のインフラストラクチャは、WBA の社内ツール一式によってサポートおよび管理されます。
MLOps ユーザー ジャーニー
一般に、ワークフロー全体に関与するチーム/ペルソナには、ML エンジニアとデータ サイエンティストの 2 種類があります。次のセクションでは、それぞれのユーザージャーニーについて説明します。
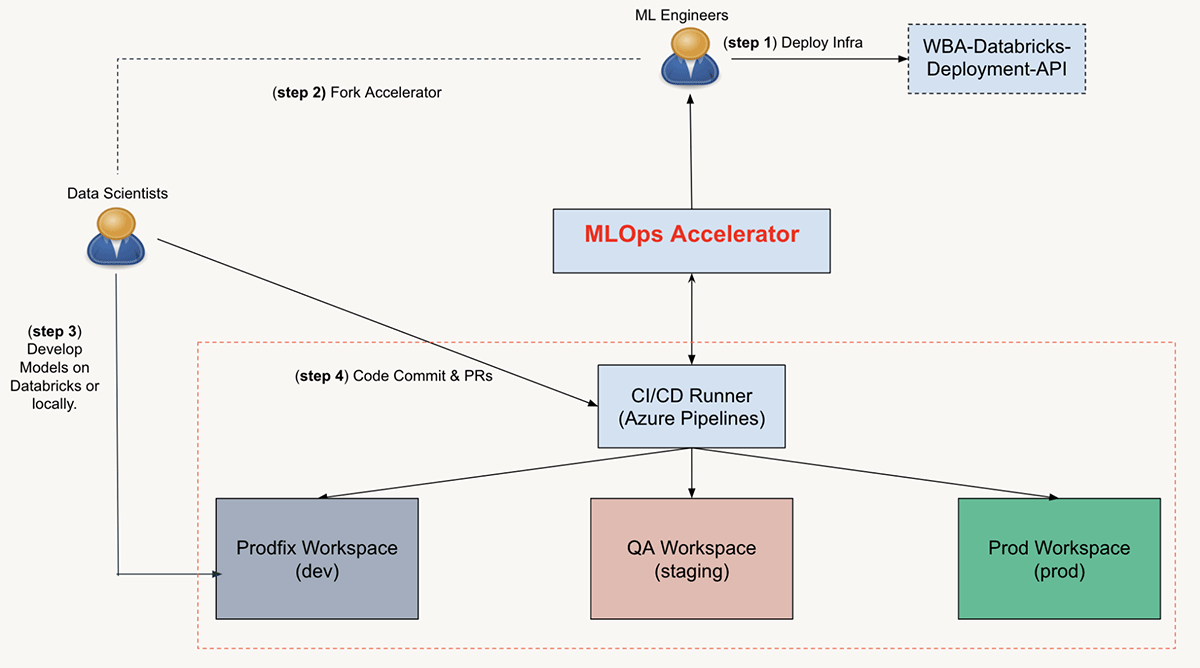
プロジェクトを開始するために、ML エンジニアは、インフラストラクチャ パイプラインをデプロイし、MLOps アクセラレータ リポジトリを ML プロジェクト リポジトリにフォークし、CI/CD 構成を設定し、リポジトリをデータ サイエンス チームと共有することにより、ML プロジェクト リソースとリポジトリを初期化します。 .
プロジェクト リポジトリの準備ができたら、データ サイエンティストはすぐに ML モジュールとノートブックの反復を開始できます。コミットと PR を使用すると、コードのマージによって CI/CD ランナーがトリガーされ、ユニット テストと統合テストが実行され、最終的には展開が実行されます。
ML パイプラインがデプロイされた後、ML エンジニアは、構成ファイルへの変更をコミットし、PR をマージすることにより、バッチ推論ジョブのスケジューリングやクラスター設定などのデプロイ構成を更新できます。コードの変更と同様に、構成ファイルを変更すると、対応する CI/CD ワークフローがトリガーされ、Databricks ワークスペースにアセットが再デプロイされます。
Lakehouse インフラストラクチャの管理
MLOps アクセラレータは、すべての Azure および Databricks リソースを作成、更新、構成するインフラストラクチャ システム上に構築されています。このセクションでは、ユーザー ジャーニーの最初のステップであるプロジェクト リソースの初期化を実行するシステムを紹介します。適切なツールを使用すると、ML プロジェクトごとに Azure および Databricks リソースのプロビジョニングを自動化できます。
Azure リソースのオーケストレーション
WBA では、Azure へのすべてのデプロイは、必要な Azure Resource Management (ARM) テンプレートとパラメーター ファイルを作成する中央のチームによって管理されます。また、このチームはこれらのテンプレートのデプロイ パイプラインへのアクセスを許可し、維持します。
WBA は、環境固有の YAML 構成ファイルを使用して、プロジェクトに必要なすべてのリソースとその構成を 1 か所に収集する、Deployment API と呼ばれる FastAPI マイクロサービスを構築しました。Deployment API は、YAML 構成が変更されたかどうか、そしてそのリソースを更新する必要があるかどうかを追跡します。各リソース タイプは、デプロイ後の構成フックを利用できます。これには、中央のデプロイ パイプラインのアクティビティを強化するための追加の自動化を含めることができます。
Databricks の構成
Deployment API を使用して Databricks ワークスペースをデプロイした後は、白紙の状態になります。Databricks ワークスペースがプロジェクトの要件に従って構成されていることを確認するために、Deployment API はデプロイ後の構成フックを使用します。これにより、Databricks ワークスペースの構成が、更新を適用するマイクロシステムに送信されます。
Databricks ワークスペースを構成する最初の側面は、Databricks の SCIM 統合を介して Databricks にアクセスする必要があるユーザーとグループを同期することです。マイクロシステムは、アクセス権が付与されるように構成されたグループのメンバーシップに基づいてユーザーを追加および削除することにより、SCIM 統合を実行します。これにより、クラスター作成権限や Databricks SQL など、きめ細かいアクセス許可が各グループに付与されます。SCIM の統合とアクセス許可に加えて、マイクロシステムは、既定のクラスター ポリシーの作成、クラスター ポリシーのカスタマイズ、クラスターの作成、および社内の Python ライブラリをインストールするための init スクリプトの定義を行うことができます。
点をつなぐ
Deployment API、Databricks 構成の自動化、MLOps アクセラレータはすべて相互に依存する方法で連携するため、プロジェクトは迅速に反復、テスト、および運用できます。インフラストラクチャがデプロイされると、ML エンジニアがプロジェクト リポジトリ構成ファイルに情報 (ワークスペース URL、ユーザー グループ、ストレージ アカウント名など) を入力します。この情報は、事前定義された CI/CD パイプラインと ML リソース定義によって参照されます。
Azure Pipelines でデプロイを自動化する
以下は、コード昇格プロセスの概要です。git ブランチスタイルと CI/CD ワークフローは独断的ですが、各ユース ケースに合わせて調整できます。WBA のプロジェクトは多様な性質を持っているため、各チームの運営は少しずつ異なる場合があります。目的に最適なアクセラレータのコンポーネントを自由に選択し、アクセラレータから分岐したプロジェクトをカスタマイズできます。
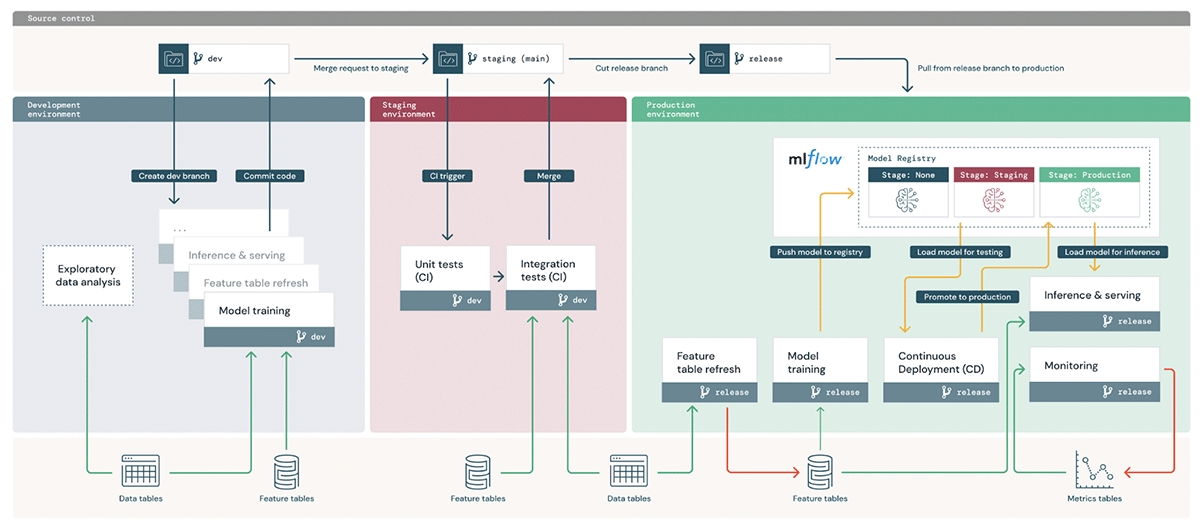
コード昇格ワークフロー
プロジェクトの所有者は、運用ブランチ (サンプル アーキテクチャの「マスター」ブランチ) を定義することから始めます。データ サイエンティストは、Prodfix ワークスペースの非運用ブランチですべての ML 開発を行います。PR を "master" ブランチに送信する前に、データ サイエンティストのコード コミットによって、開発ワークスペースでのテストとバッチ ジョブのデプロイをトリガーできます。コードの運用準備が整うと、PR が作成され、完全なテスト スイートが QA 環境で実行されます。テストに合格し、レビュー担当者が PR を承認すると、デプロイ ワークフローが呼び出されます。Prod ワークスペースでは、トレーニング パイプラインが実行されて最終モデルが登録され、推論パイプラインとモニタリング パイプラインがデプロイされます。各環境のズームインは次のとおりです。
- Prodfix : Exploratory Data Analysis (EDA)、モデル探索、トレーニングおよび推論パイプラインはすべて、Prodfix 環境で開発する必要があります。データ サイエンティストは、Prodfix でモニター構成と分析メトリックを設計する必要もあります。これは、モデルの基盤と、どのメトリックを最適に監視するかを理解しているためです。
- QA : 単体テストと統合テストは QA で実行されます。モニターの作成と分析のパイプラインは、統合テストの一部としてテストする必要があります。統合テスト DAG の例を以下に示します。QA でのトレーニングまたは推論パイプラインのデプロイはオプションです。

- Prod : トレーニング、推論、および監視パイプラインは、CD ワークフローを使用して運用環境にデプロイされます。トレーニングと推論は、ノートブック ワークフローを使用して定期的なジョブとしてスケジュールされます。モニタリング パイプラインは、Delta Live Table (DLT) パイプラインです。
ワークスペース リソースの管理
コードに加えて、MLflow の実験、モデル、ジョブなどの ML リソースは、CI/CD によって構成および促進されます。統合テストはジョブの実行として実行されるため、統合テストごとにジョブ定義を作成する必要があります。これは、過去のテストを整理し、デバッグのためにテスト結果を調査するのにも役立ちます。コード リポジトリでは、DLT パイプラインとジョブ仕様が YAML ファイルとして保存されます。前述のように、アクセラレータは WBA の社内ツールを使用して、ワークスペース リソースのアクセス許可を管理します。DLT、ジョブ、およびテストの仕様は、Databricks API へのペイロードとして提供されますが、カスタム ラッパー ライブラリによって使用されます。アクセス許可の制御は、"CICD/configs" フォルダー内の環境プロファイル YAML ファイルで構成されます。
高レベルのプロジェクト構造を以下に示します。
├── cicd < CICD configurations
│ ├── configs
│ └── main-azure-pipeline.yml < azure pipeline
├── delta_live_tables < DLT specifications, each DLT must have a corresponding YAML file
├── init_scripts < cluster init scripts
├── jobs < job specifications, each job to be deployed must have a corresponding YAML file
├── libraries < custom libraries (wheel files) not included in MLR
├── src < ML pipelines and notebooks
└── tests < test specifications, each test is a job-run-submit in the Databricks workspace
たとえば、以下は "/jobs" フォルダー内の簡略化された "training.yml" ファイルです。これは、トレーニング パイプラインが "training" という名前のノートブック ジョブとしてデプロイされる方法を定義し、11.0 ML ランタイムと 1 つのワーカー ノードを備えたクラスターを使用して、毎日米国中部時間の深夜に "Train" ノートブックを実行します。
<jobs/training.yml>
name: training
email_notifications:
no_alert_for_skipped_runs: false
timeout_seconds: 600
schedule:
quartz_cron_expression: 0 0 0 * * ?
timezone_id: US/Central
pause_status: UNPAUSED
max_concurrent_runs: 1
tasks:
- task_key: training
notebook_task:
notebook_path: '{REPO_PATH}/src/notebooks/Train'
new_cluster:
spark_version: 11.0.x-cpu-ml-scala2.12
node_type_id: 'Standard_D3_v2'
num_workers: 1
timeout_seconds: 600
email_notifications: {}
description: run model training
リポジトリを同期する手順は次のとおりです。
- リポジトリを Databricks ワークスペースにインポートする
- 指定された MLflow Experiment フォルダーを構築し、構成プロファイルに基づいてアクセス許可を付与する
- MLflow モデル レジストリでモデルを作成し、構成プロファイルに基づいてアクセス許可を付与する
- テストを実行する (テストでは MLflow 実験とモデル レジストリを使用するため、手順 1 ~ 3 の後に実行する必要があります。テストは、リソースがデプロイされる前に実行する必要があります。)
- DLT パイプラインを作成する
- すべてのジョブを作成する
- 非推奨のジョブをクリーンアップする
ML パイプラインを標準化する
定義済みの ML パイプラインがあると、データ サイエンティストは再利用可能で再現可能な ML コードを作成できます。一般的な ML ワークフローは、データの取り込み、特徴付け、トレーニング、評価、展開、予測の一連のプロセスです。MLOps アクセラレータ リポジトリでは、これらの手順がモジュール化され、Databricks ノートブックで使用されます。(詳細については、Repos Git Integrationを参照してください )。データ サイエンティストは、ユース ケースに合わせて「ステップ」をカスタマイズできます。ドライバー ノートブックは、パイプライン引数とオーケストレーション ロジックを定義します。アクセラレーターには、トレーニング パイプライン、推論パイプライン、監視パイプラインが含まれています。
├── src
│ ├── datasets
│ ├── notebooks
│ │ ├── Train.py
│ │ ├── Batch-Inference.py
│ │ ├── MonitorAnalysis.py
│ ├── steps < python module
│ │ ├── __init__.py
│ │ ├── utils.py < utility functions
│ │ ├── ingest.py < load raw dataset
│ │ ├── featurize.py < generate features
│ │ ├── create_feature_table.py < write feature tables
│ │ ├── featurelookup.py < lookup features in FS
│ │ ├── train.py < train and log model to MLflow
│ │ ├── evaluate.py < evaluation
│ │ ├── predict.py < predictions
│ │ ├── deploy.py < promote the registered model to Staging/Production
│ │ └── main.py
│ └── tests < unit tests
データとアーティファクトの管理
ML システムではデータとモデルが常に進化しているため、ML パイプラインのデータとアーティファクトの管理について説明します。パイプラインはDeltaと MLflow 中心としています。入力データと出力データを Delta 形式で適用し、MLflow を使用して実験の試行とモデル アーティファクトを記録します。
WBA MLOps アクセラレータでは、Delta と MLflow に基づいて構築された Databricks Feature Store も使用して、モデルの上流系統 (つまり、データ ソースと機能からモデルまで) と下流系統 (つまり、モデルからデプロイ エンドポイントまで) の両方を追跡します。)。事前に計算された特徴は、プロジェクト固有の特徴テーブルに書き込まれ、モデルのトレーニングのためにコンテキスト特徴と共に使用されます。推論プロセスでは、Databricks Feature Store API で利用できるバッチ スコアリング機能を使用します。デプロイでは、特徴テーブルはトレーニング パイプラインのステップとして書き込まれます。このようにして、製品モデルは常に最新バージョンの機能から読み込まれます。
パイプライン オーケストレーション
説明したように、トレーニングと推論はバッチ ジョブですが、モニタリングは DLT パイプラインとしてデプロイされます。トレーニング パイプラインは、最初に ADLS に格納されているデルタ テーブルからデータを読み込み、次に機能を設計してワークスペースの Feature Store に書き込みます。次に、特徴テーブルからトレーニング データセットを生成し、ML モデルをトレーニング データセットに適合させ、Feature Store API を使用してモデルをログに記録します。トレーニング パイプラインの最後のステップは、モデルの検証です。モデルが合格すると、モデルは自動的に対応するステージ (QA 環境の場合は「ステージング」、本番環境の場合は「本番」) に昇格します。
推論パイプラインは「fs.score_batch()」を呼び出して、モデル レジストリからモデルを読み込み、予測を生成します。ユーザーは、データをスコアリングするための完全な機能セットを提供する必要はなく、機能テーブル キーだけを提供する必要があります。Feature Store API は、事前に計算された機能を検索し、それらをコンテキスト機能と結合してスコアリングします。
開発段階では、データ サイエンティストは、モデルのパフォーマンスを評価するためにどのメトリックを追跡する必要があるかなど、モデル モニタリングの構成を決定します (例: すべての列の最小値、最大値、平均値、中央値、集計時間ウィンドウ、モデル品質メトリック、およびドリフト指標)。
本番環境では、推論リクエスト (モデル入力) と対応する予測結果が、監視プロセスに関連付けられた管理対象のデルタ テーブルに記録されます。通常、真のラベルは後で到着し、別の取り込みパイプラインから取得されます。ラベルが利用可能になったら、それらをリクエスト テーブルに追加して、モデル評価分析を推進する必要があります。すべての監視メトリックは、Lakehouse の個別のデルタ テーブルに保存され、Databricks SQL ダッシュボードで視覚化されます。アラートは、選択したドリフト メトリックのしきい値に基づいて設定されます。監視フレームワークは、モデルの A/B テストと、将来のユース ケースの公平性とバイアスの調査も可能にします。
結論
MLOps は、業界の人々がエンドツーエンドの ML サイクルを大規模に自動化するツールを開発している新しい分野です。DevOps とソフトウェア開発のベスト プラクティスを組み込んだ MLOps は、DataOps と ModelOps も展開します。WBA と Databricks は、「コードのデプロイ」パターンに従って MLOps アクセラレータを共同開発しました。プロジェクトが始まった初日から ML 開発を正しい方向に導き、ML パイプラインを本番環境でデプロイするのにかかる時間を数年から数週間に大幅に短縮します。アクセラレーターは、ML ライフサイクル管理のために Delta Lake、Feature Store、MLflow などのツールを使用します。これらのツールは MLOps を直感的にサポートします。インフラストラクチャとリソースの管理については、アクセラレータは WBA の内部スタックに依存しています。Terraform のようなオープンソース プラットフォームも同様の機能を提供します。アクセラレータの複雑さに驚かされないでください。この記事で説明されている運用 ML のベスト プラクティスの採用に関心がある場合は、Databricks で運用可能な MLOps ソリューションを作成するための参照実装を提供します。お願いしますリファレンス実装リポジトリにアクセスするには、このリクエストを送信してください。
このエキサイティングな WBA の旅に参加することに興味がある場合は、Working at WBAをチェックしてください。ピーターはプリンシパル MLOps エンジニアを募集しています!
著者について
Yinxi Zhang は Databricks のシニア データ サイエンティストであり、顧客と協力してエンド ツー エンドの ML システムを大規模に構築しています。Databricks に入社する前、Yinxi はエネルギー業界で 7 年間 ML スペシャリストとして働き、従来の資産と再生可能な資産の生産を最適化しました。彼女は博士号を取得しています。ヒューストン大学で電気工学の博士号を取得しています。Yinxi は元マラソン ランナーで、現在は幸せなヨギです。
Feifei Wang は、Databricks のシニア データ サイエンティストであり、顧客と協力して ML パイプラインの構築、最適化、および運用化を行っています。以前、Feifei はディズニーでシニア デシジョン サイエンティストとして 5 年間勤務していました。彼女はアイオワ州立大学で応用数学とコンピュータ サイエンスの博士号を取得しており、研究の焦点はロボティクスでした。
Peter Halliday は、WBA の機械学習エンジニアリングのディレクターです。彼はシカゴ郊外に住む夫であり、3 人の子供の父親でもあります。彼は 20 年以上にわたって分散コンピューティング システムに携わってきました。彼が Walgreens で働いていないときは、キッチンであらゆる種類の食品を一から作っているのを見つけることができます。彼は出版された詩人であり、不動産投資家でもあります。
Databricksを試す