ACCESS Advent Calendar 2020 の18日目の記事となります!
やっはろー!みなさま、良い年末を過ごされてますかー!!
※テンションが高いのは、深夜帯に記事を書いているからですね笑
ML関連の仕事したり、プログラム組んだりを趣味でやってたりするので、
今回の記事もML関連のお話となります。
概要
日本語版BERTを利用した要約モデル(要約マンと作者は記載してる)を、SageMaker上で動かしてみた話になります。
※結構前に作ったので、だいぶ内容忘れてるので、思い出しながら、、笑
実装したコード類については、下記にあります。
https://github.com/kurama554101/YouyakuMan
推論エンドポイントの構築手順などは、README.mdに書いたつもりですが、不足や不明点・誤りなどありましたら、
リポジトリへのissue登録か、この記事でコメント頂けると幸いです。
参考資料
元となった要約マンの話は下記を参考にしています。
要約マンとは?
日本語版BERTを利用した要約モデルで、BERTSumがベースとなっています。
簡単な処理の流れは以下のようなイメージです。
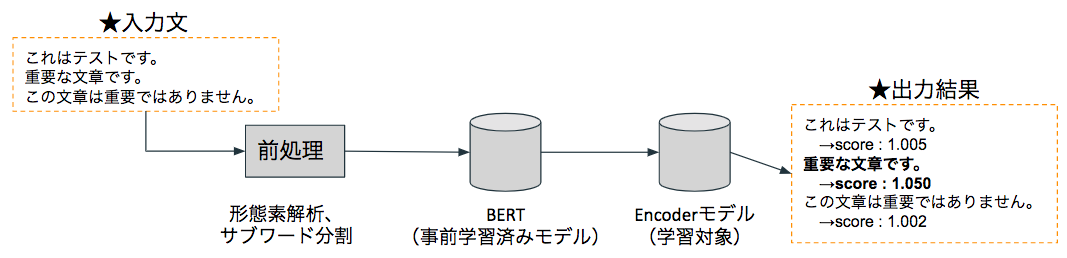
つまり、BERTSumはBERT(事前学習済みモデル)+Encoder(ここは学習対応が必要)の構成となっているわけです。
要約マンの詳細な紹介については、参考資料をご確認していただければと思います。
BERTとは?
自然言語処理で最近よく用いられる事前学習済みモデルの一種がBERTとなります。
TransformerのEncoder部分を利用しているのと、学習方法(MLMとNSP)が特徴的なモデルとなっています。
詳細は、様々な記事やBERT論文で触れられているので、割愛します。
Encoderとは?
Encoder部分は、どのような構造になっているのでしょうか。
要約マン・BERTSumでは、BERTの出力(文章全体の特徴量)をEncoderの入力とし、Encoderの出力としては、どの文章が重要か?をスコアとして出しています。
ここはBERTSumの論文でも触れられていますが、下記をEncoderとして試しています。
- シンプルなClassifier
- Transformer
- LSTM(RNNの一種)
結果としては、Transformerが最も精度が良かったため、要約マンでもTransformerをEncoderとして採用しています。
※ちなみに、BERTSumの論文だと、Encoder部分をSummarization Layersと言っていたりします。
ちなみに、BERT部分は事前学習モデルとなっており、再学習は実施しないですが、
Encoder部分は学習対象となります。
SageMakerとは?
SageMakaerは、AWSで提供されている機械学習モデルを利用するためのマネージドサービスとなります。
機械学習モデルをサービスに組み込むためには、様々な課題を解決する必要があります。
例えば、、
- 学習するための環境をどのように構築するか
- 学習時のデータをどこに格納するか
- 学習したモデルをどこに格納するか、バージョニングをどうするか
- モデルの推論するためのAPIをどのように提供するか
- 推論前後の前処理・後処理をどこでどのように実行するか
- 再学習の仕組みをどのように構築するか
- モデルのモニタリングをどのように行うか
などなどです。
以下の図が分かりやすく、MLモデルをサービス化する際に、モデルコード部分が如何に締めてる割合として少ないかを示しています。
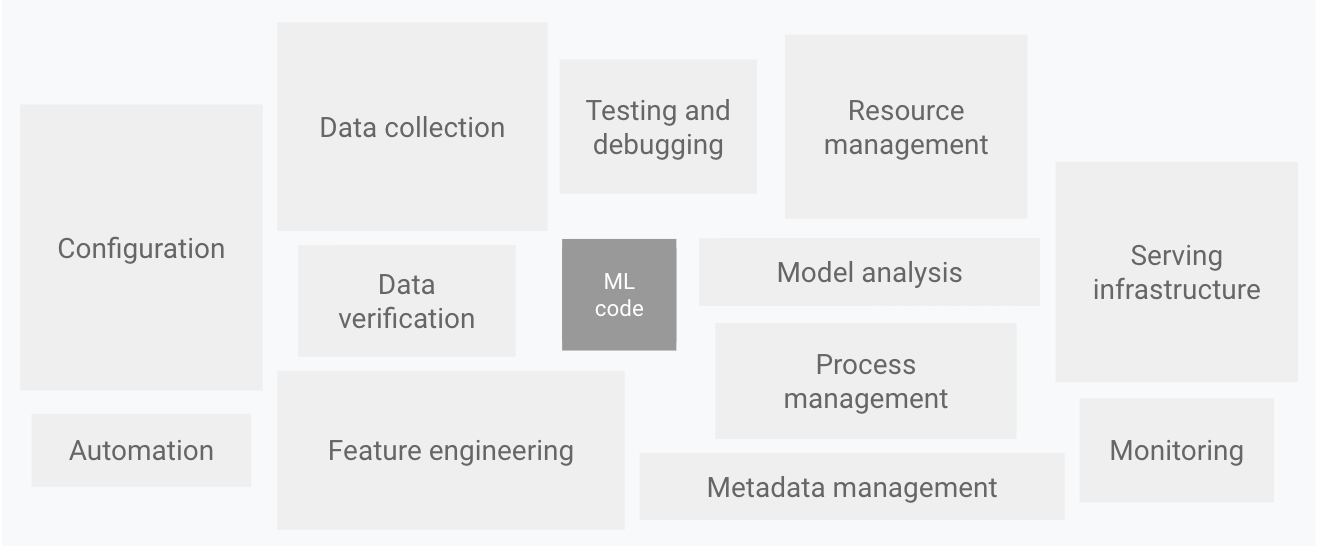
※上図はこちらの記事から抜粋。
要約とは?
要約はそのままの意味ですが、「文章について、要点・重要な内容をおさえて、短くまとめたもの」となります。
自然言語処理で要約のタスクは難しい課題とされており、とりわけ、日本語での要約は今だに難題とされています。
要約は一般的に以下の二種類の手法をとられます。
- Extractive
- 要約結果を、要約対象となる文章から抽出して、出力する
- Abstractive
- 要約結果を、要約対象となる文章に含まれない単語・文も用いて、出力する
Abstractiveの方が難度が高いですが、より自然な要約文章を出力するケースが多いです。
※ちなみに、今回の要約マンでは、Extractiveな要約手法となっています。
要約に関する詳細手法について
論文をチェックしたりするのが良いですが、NLP-Progressで、最近の自然言語処理タスクで精度の高いとされる手法がまとまっています。
要約(Summarization)を見ると、BERTSum(の発展系)もランキングに乗っていたりします。
※また余談ですが、自然言語処理のベンチマークで有名なGLUE(Super GLUE含む)のリーダーボードとかを見ると、最近のモデル事情が分かったりします。
学習するためのデータセットについて
今回、要約マンを学習させるためのデータセット検討が一番悩みました・・。(要約系のデータセットって、中々ないんですよね・・)
要約マンの作成者はクローリングをしているっぽいですが、ちと面倒だったので、下記のlivedoorニュースコーパスを利用しました。
※本文を入力文、タイトルを要約文として扱っています。
SageMakerで要約マンを動かすまでの道のり
要約マンをSageMaker上で動作させるために、以下のような対応を実施しました。
- 学習用、推論エンドポイント用のDockerイメージの作成
- 要約マン内部で、Jumanを使っており、C++のライブラリをSageMakerのPytorchイメージに追加する必要がある
- データセットの整形+アップロード対応
- SageMakerでyouyakumanの学習が出来るように修正
- SageMakerでyouyakumanの推論処理が出来るように修正
- notebookインスタンスで実行するコードの作成
はまったこと
SageMakerのカスタムイメージを作る際に、学習用と推論用の両方イメージ作成が必要というのに、最初気付かなかった点
これは利用するSageMakerのベースイメージ次第ではありますが、最近のPytorch・TFなどのDockerイメージを見ると、
基本的に学習用・推論用でイメージが別れています。(CPU・GPUは勿論別れてますね)
今回はPytorchのイメージをベースに、Dockerイメージを作り直しています。
また、使用できるSageMaker用のDockerイメージは下記を参照すれば、どのようなバージョンが利用できるか、が確認出来ます。
https://github.com/aws/deep-learning-containers/blob/master/available_images.md
Jumanがなぜかコンテナ上で動作しない問題が勃発・・涙
これが一番はまった問題で、、最初は全く意味がわからない問題でしたね・・。
結論からすると、「SageMakerのコンテナ動作開始時に出ているwarningがJumanへの入力になってしまっていて、Jumanの実行が正常に動作しなかった」となります。
これは、JumanをPython経由で使う際にpyknpを使うのですが、
pyknpの実装を追っていくと、Jumanの実行結果を標準出力から取得するような処理となっていることがわかります。
https://github.com/ku-nlp/pyknp/blob/bc13c9a06c8e0fb5b14a186a63bb67f9bba1c1bb/pyknp/juman/juman.py#L49-L71
※subprocessを利用して、jumanを実行し、標準出力の結果を取得してるんですね。
実際の問題自体は、下記のhinsi_id部分に数字以外(intで変換できない)が入ったのが例外発火の原因となっていました。
https://github.com/ku-nlp/pyknp/blob/master/pyknp/juman/morpheme.py#L137-L150
精度検証など
すいません、、まだ精度検証とかはちゃんと出来ておらず、別途実施しようかと思っています。
まとめ
色々とハマりはしましたが、無事要約を行うモデル(要約マン)が、SageMaker上で動作したのはよかったです。
Encoder部分を置き換えれば、Abstractiveな要約も可能だと思うので、次はEncoder部分を差し替えて、Abstractiveな要約も試したいと思います。
明日は、@ikeyasuさんの投稿になります!乞うご期待!