はじめに
データサイエンティスト検定の勉強をしてて個人的につまずいたところをメモ。
現在大学院で統計学を専攻していたこともあってか、データサイエンス以外の問題でつまずく傾向が強いように思えた。
追記(受け終わった感想):かなり実務寄りで、実際にビジネスにデータサイエンティストとして関わった経験あるいは、データの利活用を進めた経験のある人でないと解けないだろという問題が多い印象だった。
原系列
観測されたデータそのもの。主に時系列データの文脈でこう呼ばれている(と感じている)。
時系列データは、時間的順序を追って一定間隔ごとに観察されたデータである。時刻とともに、値が刻々と変化していく性質から、短期的な自己相関の他に、傾向変動、周期変動や不規則変動などの複数の変動要因によって起こると考えられている。
原系列に対して、高速フーリエ変換を実行すると、周波数スペクトルに置き換えることができる。
→ 原系列の周期性を確認できる
・原系列を移動平均系列に変換 : 長期的な傾向を確認できる。
・原系列を差分系列に変換 : 長期的な傾向が取り除かれる。
→ 上昇傾向か下降傾向かトレンド(直近の状況)を知ることができる。
参考
https://stats.biopapyrus.jp/time-series/
情報の種類
| 説明 | 例 | |
|---|---|---|
| 一次情報 | 自身で収集したアンケートやヒアリング結果など、実際に「自分で集めたデータ」 | 実験データ、調査結果 |
| 二次情報 | 他者が執筆した書籍や論文に記載された調査結果など、「公開/販売されているデータ」 | MNIST, RESAS, オープンデータ |
オープンデータとは
基本原則
- 政府自ら積極的に公共データを公開すること
- 機械判読可能で二次利用が容易な形式で公開すること
- 営利目的、非営利目的を問わず活用を促進すること
- 取組可能な公共データから速やかに公開等の具体的な取組みに着手し、成果を確実に蓄積していくこと
例:人口統計や公共のデータ
参考
https://www.kantei.go.jp/jp/singi/titeki2/tyousakai/kensho_hyoka_kikaku/dai9/siryou3.pdf
データベース
テーブルの正規化
データの重複をなくし、テーブルから冗長性を取り除いた状態にすること。
データの追加や更新、削除などの操作がしやすくなり、メンテナンス効率が向上。リレーショナルデータベース(RDB)の設計においては、「正規形」という概念が用いられる。
| 名称 | 状態 | イメージ |
|---|---|---|
| 非正規形 | データの冗長性や不整合がある状態 | |
| 第一正規形 | 下記の不整合が解消された状態 ・同じ列が複数ある ・1つのセルの中に複数の値が入ってる ・結合セルが存在する → 繰り返して横に長いものを解消させる。 |
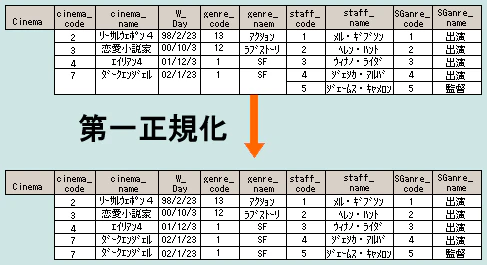 |
| 第二正規形 | 第一正規形を満たし、主キーが決まればテーブルを構成する主キー以外の属性の値が一意に決定する(関数従属関係)。主キーに部分従属している属性は(別テーブルに)分離する。 → 主キーと非キーのテーブル分け |
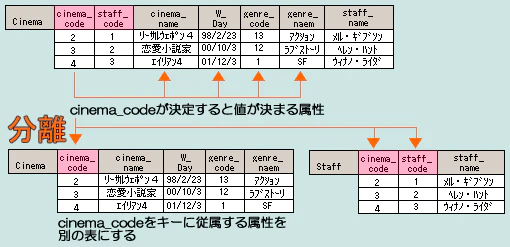 |
| 第三正規形 | 第二正規形を満たし、主キー以外の項目に従属する関係(推移従属関係)を別テーブルに分離する。 → 非キーと非キーのテーブル分け |
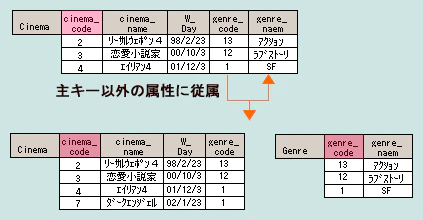 |
参考
http://ext-web.edu.sgu.ac.jp/HIKO/Prog03/SenpaiKyozai/shiohara/formalize.html
データ基盤
| 名称 | 特徴 |
|---|---|
| データレイク | 収集されたデータをそのままの状態で蓄積する場所(生データ) ・各ストレージの生データを一箇所に統合するための蓄積環境 ・通常は、データの構造に依存しないストレージシステムで構築 |
| データウェアハウス | 分析しやすい形に整形されたデータを蓄積する場所 ・集計・加工されたデータの蓄積環境 ・データウェアハウスは、SQLやPythonなどと連携できることが望ましい |
| データマート | 特定の利用目的のために抽出されたデータを蓄積する場所 ・データウェアハウスから利用目的ごとにデータを抽出した蓄積環境 ・データ取得処理の負荷分散が可能 |
イメージ図

参考
https://www.tableau.com/ja-jp/learn/articles/data-mart
分散処理
処理速度の向上を目的に1つの処理を分散して、プロセッサ内のいくつかのコアに割り当てること。ここでは、Hadoop (MapReduce)とApache sparkの特徴を簡単に説明する。
| 名称 | データの保管場所 | 処理速度 | コスト | 適した処理方式 | スケーラビリティ |
|---|---|---|---|---|---|
| Hadoop | ディスク | 遅い(ディスクに書き込むから) | 安い | バッチ処理 | 42000ノードくらい |
| Apache spark | RAM(ランダムアクセスメモリ) | 速い(RAMだから) | 高い | リアルタイム処理 | 8000ノード程度が限度 |
参考
https://zenn.dev/caterpillar/articles/a62abf4fe74505
画像フォーマット
| 形式 | カラー | データ容量 | 圧縮画像 |
|---|---|---|---|
| PNG | フルカラー(1677万色) | 大きい | 可逆(画像が劣化しない) |
| JPEG | フルカラー(1677万色) | 小さい | 不可逆(画像が劣化する) |
| GIF | 256色 | かなり小さい | 可逆(画像が劣化しない) |
プロトコル
FTP(ファイル転送プロトコル)の仕組み
インターネット初期から存在しており、プロトコルの原点。ほとんどのデータは、FTPを活用して、アップロード・ダウンロードされている。
かつては主流であったが、現在ではリスクが高い認識。FTPはデータの通信経路が暗号化されておらず、ユーザ名やパスワードなどの認証情報もなかったため。
様々なプロトコル
| 名称 | 説明 |
|---|---|
| FTPS | FTPに「SSL/TLS」を導入することで、FTPになかったデータの暗号化によってセキュリティを高めた。 |
| SCP | ネットワーク上の通信が暗号化される「SSH(Secure Shell)」と呼ばれるプロトコルを導入することで、より安全性を高めた。転送が中断された場合に途中から再開できない。 |
| HTTP | webサーバとクライアント間で通信を行うためのプロトコル。HTMLで記載されたテキストなどの転送に用いられる。通信は暗号化されない。 |
| HTTPS | 通信が暗号化されたHTTP。盗聴や改ざん、なりすましを防止できる通信プロトコル。 |
| SFTP | SCPと同じくSSHを使って暗号化するプロトコル。SCPとは異なり、途中で転送が中断された場合でも中間箇所から再開する。「Linux」にデフォルトでインストールされている。 |
| SMB | Microsoft社が開発した共有プロトコルで、「Server Message Block」の略称。Windowsネットワークの根幹にあたるプロトコルで、ローカル上のWindowsやサーバーの共有フォルダへデータを送信する機能がある。 |
参考文献
https://www.itscom.co.jp/forbiz/column/cloud/3624/
マルウェア
| 名称 | 説明 |
|---|---|
| ウイルス | プログラムの一部を書き換え、自己増殖していくマルウェア。 単体では存在することができず、プログラムの一部を改ざんして入り込み、分身を作って増殖していく。 |
| ワーム | 自身を複製して感染させていく形態はウイルスと同じ。 しかし、ウイルスのように他のプログラムを必要とせず、単独で存在することが可能なマルウェア。 |
| トロイの木馬 | 一見しただけでは問題のない画像や文書などのファイル、スマートフォンのアプリなどの偽装して、デバイスの内部へと侵入する。そして外部からの指令によって、そのデバイスを操るマルウェア。 |
| スパイウェア | 本人も気づかないうちにPCなどのデバイスにインストールされ、ユーザの個人情報やアクセス履歴などを収集するマルウェア。 |
マルウェア感染経路
・メールの添付ファイル
・ネットワーク経由で侵入
・不正サイトや悪意のあるサイトへのアクセス
・不正なソフトウェアやアプリのインストール
・ソフトウェアの脆弱性を突いて侵入
マルウェア感染で起こる被害
・個人情報を抜き取られたり、情報が流出したりする
・デバイスに保存されているファイルが改ざんされる
・デバイスを勝手にロックされて持ち主でも操作ができなくなる
・外部と勝手に通信を行う
・デバイスを乗っ取られ、サイバー攻撃の「踏み台」として使われる
予防方法
・ウイルス対策ソフトを導入し、常に最新バージョンにアップデートしておく
・PCの場合には、インストールしているOSを最新版に保っておく
・怪しいURLはクリックしない
・不審なメールや不審な添付ファイルは開かない
・重要なファイルは漏洩しても、開けないように暗号化しておく
・機密情報を保存してあるサーバーは、許可のないデバイスから隔離しておく
暗号化技術の種類
| 名称 | 特徴 | アルゴリズム | メリット | デメリット |
|---|---|---|---|---|
| 共通鍵 | 暗号化と復号ともに共通鍵を使用する ・暗号化:共通鍵 ・復号 :共通鍵 |
DES・AES | 暗号化が高速 | 鍵の管理が面倒 |
| 公開鍵 | 暗号化と復号に異なる鍵を使用する ・暗号化:受信者の公開鍵 ・復号 :受信者の秘密鍵 |
RSA | 鍵の管理が容易 | 暗号化が低速 |
電子署名
公開鍵暗号やハッシュ関数を使い、データに電子的に署名すること。ハッシュ関数によって改ざんを検知できるので、送信者が正しいことと伝送経路上でデータが改ざんされていないことを保証できる。
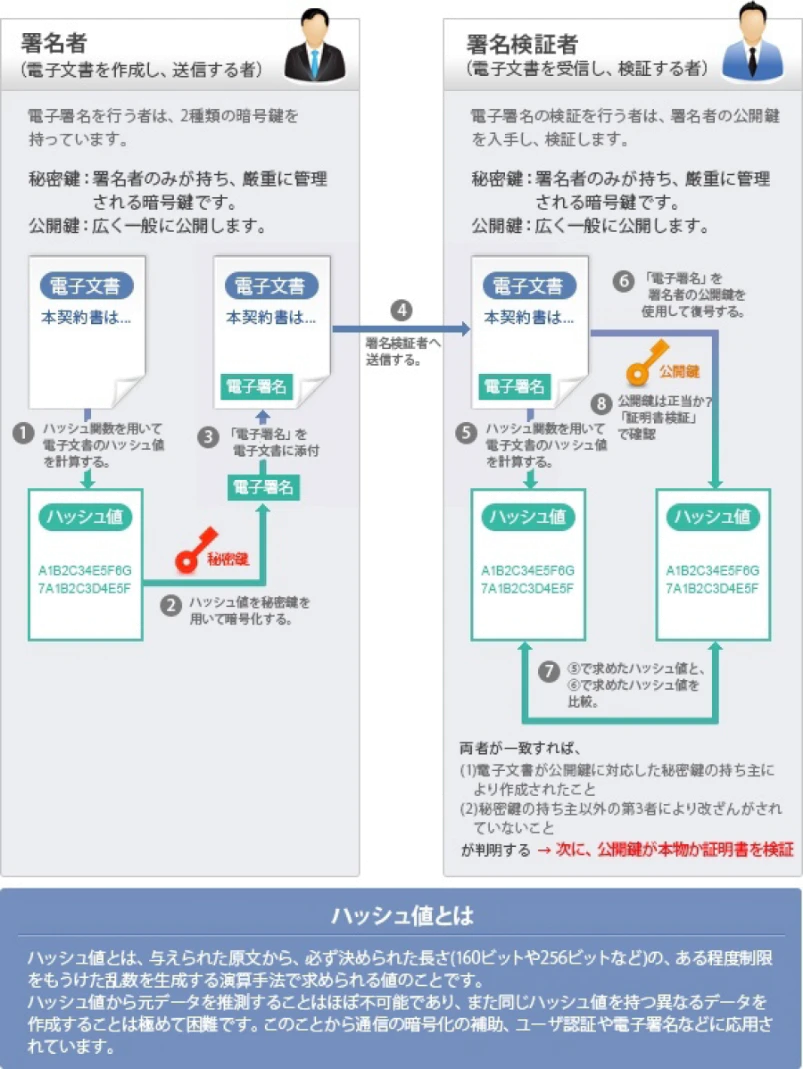
参考
https://www.c-a-c.jp/about/knowledge.html
AutoML
AutoML(Automated Machine Learning)とは、機械学習モデルの設計や構築を自動化すること、またはそのための手法全般を指す。
機械学習プロセス
問題や仮説の定義 → データ収集 → データ加工 → 特徴量設計 → 機械学習モデルの生成 → モデルの運用
の各ステップのうち、データ加工からモデル設計までを自動化を行うことができる技術。プログラミングが不要。
ツール例
-
AutoML Table(Google)
- GoogleのAutoML Tableは、AutoMLの中で最も知名度が高いものでしょう。データの自動処理を主な機能として持ち、具体的には数値や文字列などのデータを自動的に整形し、問題があれば抽出することを自動化できます。
-
DataRobot
- DataRobotは100社以上の企業で導入されていて、アコム、ANA、Calbee、といった有名企業にも導入されています。最近では、自動特徴量探索機能が進化していたり、データの異常を察知して想定外のイベントの根本原因を把握することができるようになっています。
-
dotData
- データ収集・加工からモデル設計、可視化、運用までのプロセスを数ヶ月から数日に短縮できます。