これは何か
2020年3月に筆者が参加したkaggleコンペGoogle Cloud & NCAA® ML Competition 2020-NCAAWにてmlflowのtracking機能を導入してみた結果、使い勝手が良かったので、備忘録ついでに投稿する。記載内容は主にmlflowのtracking機能導入方法と自身が導入時に躓いた点について記載していく。
mlflowとは
mlflowとは、機械学習のライフサイクル(前処理→学習→デプロイ)を管理するオープンソースなプラットフォームであり、主に3つの機能を有している。
- Tracking: ロギング
- Projects: パッケージング
- Models: デプロイ支援
今回は主にTracking導入方法について触れていく。Projects, Modelsの詳細についてはこちらを参考にしてほしい。
Trackingとは
Trackingは機械学習モデルの構築時における各パラメータや評価指標と結果、出力ファイルなどをロギングする機能である。なお、gitにprojectを置いておけばコードバージョンの管理も可能であるが、それも紹介するとなるとprojectsの方にまで話が膨らんでしまうと思ったので、今回は割愛する(次回、projectsについて触れた時に扱いたいと考えている)。
mlfrowの導入
mlflowのinstall
mlflowはpipでインストールができる。
pip install mlflow
*本記事執筆当時のmlflowのversionは1.5.0である。
URIの設定
ロギングする際のURIを設定する(デフォルトでは実行時のフォルダ直下に作成される)。
URIにはローカルディレクトリはもちろん、データベースやHTTPサーバなども指定できる。
ロギング先のディレクトリ名は mlruns にする必要がある(理由は後述する)。
import mlflow
mlflow.set_tracking_uri('./hoge/mlruns/')
*今回はローカル上での管理を行う。
experimentの作成
experimentは機械学習プロジェクトにおける各タスクごとに分析者が任意で作成していく(例えば、特徴量、機械学習手法、パラメータの比較など)。
# experimentが存在しなければ作成される。
mlflow.set_experiment('compare_max_depth')
実行
実際にロギングを行ってみる。
with mlflow.start_run():
mlflow.log_param('param1', 1) # パラメータ
mlflow.log_metric('metric1', 0.1) # スコア
mlflow.log_artifact('./model.pickle') # その他、モデルやデータなど
mlflow.search_runs() # experiment内のロギング内容を取得できる
パラメータやスコア、モデルなどをロギングしている。各関数の詳細な仕様などについては公式ドキュメントを参照してほしい。
ローカルサーバの起動
URIで設定したディレクトリまで移動する。この時、 mlruns ディレクトリが配下になるようにする( mlruns ディレクトリが存在しない場合、 mlruns ディレクトリが作成される)。
mlflow ui でローカルサーバが起動する。
$ cd ./hoge/
$ ls
mlruns
$ mlflow ui
ブラウザ上で http://127.0.0.1:5000 を開くと下記画面が表示される。
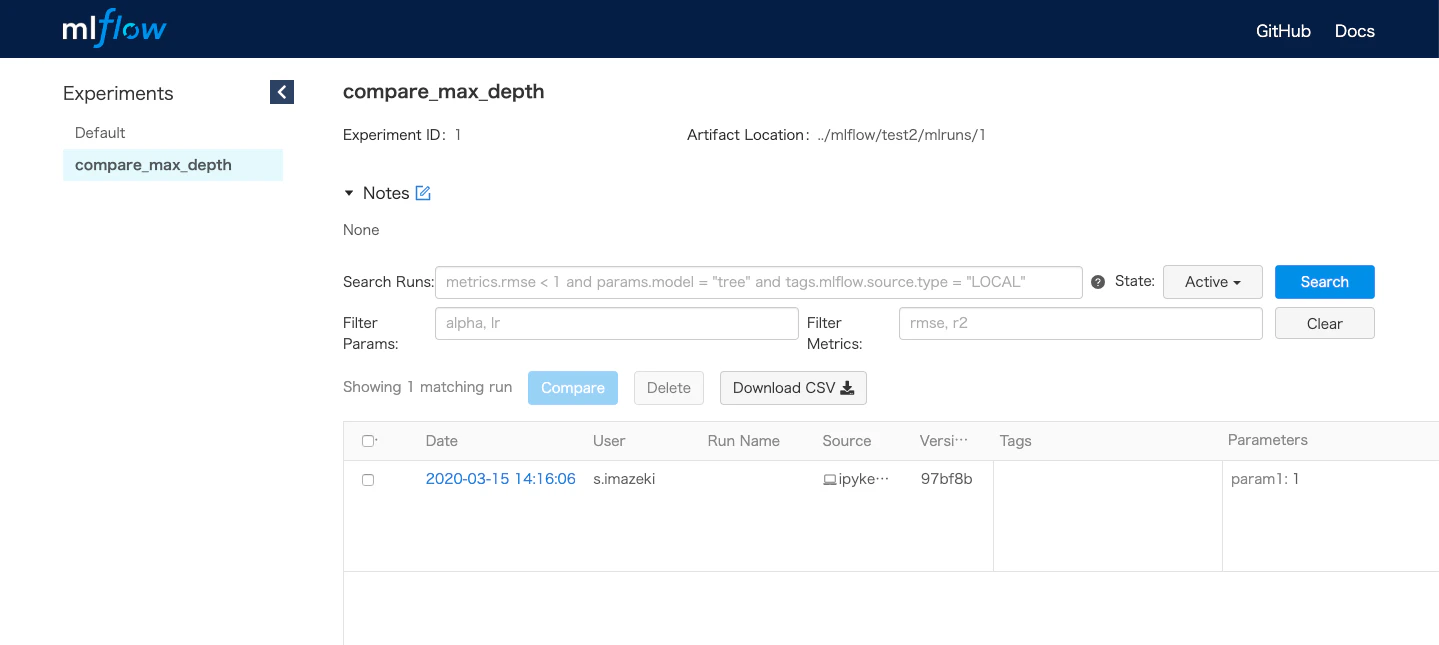
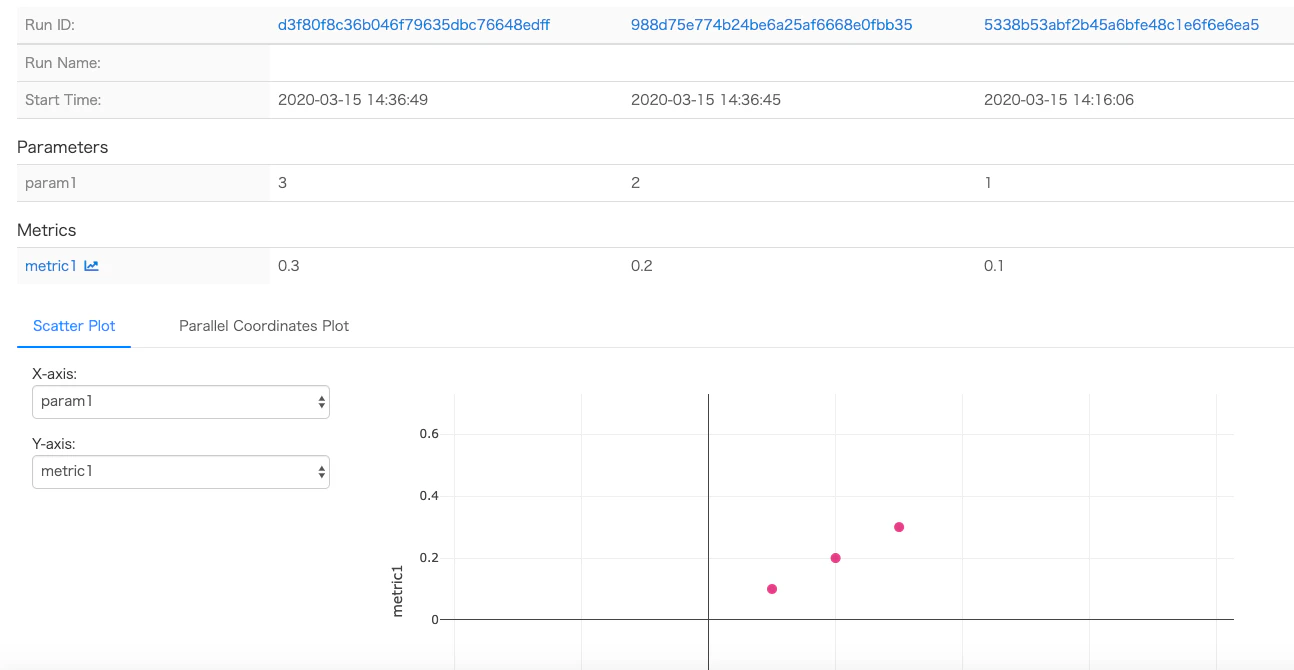
パラメータごとの比較も可能になっている。
Tips
experiment idの取得
tracking = mlflow.tracking.MlflowClient()
experiment = tracking.get_experiment_by_name('hoge')
print(experiment.experiment_id)
experiment名の取得
# 方法1: experiment listの取得
tracking.list_experiments()
# 方法2:
tracking = mlflow.tracking.MlflowClient()
experimet = tracking.get_experiment('1') # experiment idを渡す
print(experimet.name)
experimentの削除
tracking = mlflow.tracking.MlflowClient()
tracking.delete_experiment('1')
run idの取得
with mlflow.start_run():
run_id = mlflow.active_run().info.run_id
start_run() のパラメータに取得したrun_idを渡すと、対象のrun_idのログが上書きされる。
runの削除
tracking = mlflow.tracking.MlflowClient()
tracking.delete_run(run_id)
dictを用いたロギング
# 複数のパラメータを同時にロギングしたい時はdictで渡す。
params = {
'test1': 1,
'test2': 2
}
metrics = {
'metric1': 0.1,
'metric2': 0.2
}
with mlflow.start_run():
mlflow.log_params(params)
mlflow.log_metrics(metrics)
download artifacts
tracking = mlflow.tracking.MlflowClient()
print(tracking.list_artifacts(run_id=run_id)) # artifactsのリストを取得
[<FileInfo: file_size=23, is_dir=False, path='model.pickle'>]
tracking.download_artifacts(run_id=run_id, path='model.pickle', dst_path='./')