はじめに
皆様、こんにちは! VMware by Broadcom で Lead Enterprise Architect をしている鈴木章太郎です。このブログエントリは、TUNA-JP Advent Calender 2023 第17日目です。VMware Tanzu Application Platform / Greenplum データベースと React のサンプルアプリについて、ご紹介したいと思います。
サンプルアプリの前提
このアプリは、弊社の基幹イベントである VMware Explorer 2023 (11/14-11/15)での Greenplum データベースブースでご紹介したアプリケーションです。Tanzu Application Platform と VMware Greenplum ベクターデータベースを使った RAG(Retrieval Augmented Generation、後ほど説明)構築というのが、このブースでこのアプリをご紹介した趣旨ですね。
生成 AI の課題
何度も言われていることですが、もう一度簡単にまとめておきますね。
・学習時点までの知識 : 最新の状況がインプットされていない。
・Hallucination (ハルシネーション) : アウトプットの真偽が定かでない。
上記の理由から、あらかじめ学習させたドメインに限定しない質問に対して正しく答えられない場合がある。
プライベート AI/LLM に対する VMware のポジション
プライベート AI についての VMware の考え方については、こちらに詳しくまとまっています。ここでは下記の点を強調しておきます。
オンプレミス / マルチクラウド で、プライベートデータを使用して追加トレーニングをすることができれば、最新の情報への問い合わせにも応えることができます。
また、今回は扱いませんが、特定の目的に適した言語モデルへのファインチューニングも可能となります。
いわゆる、RAG(Retrieval Augmented Generation) による最新事実に基づくテキスト生成ですね。
RAG(Retrieval Augmented Generation)とは何か
それでは改めて RAG とは何でしょうか?ということになります。
RAG(Retrieval Augmented Generation)とは、大規模言語モデル (LLM) と外部のデータベースや情報源を結びつけるための新しい技術のことを示します。
外部のデータベースや情報源から事実を検索して、最新の正確な情報に基づいて大規模言語モデル(LLM)に回答を生成させることで、より 回答精度を向上させることが可能となります。
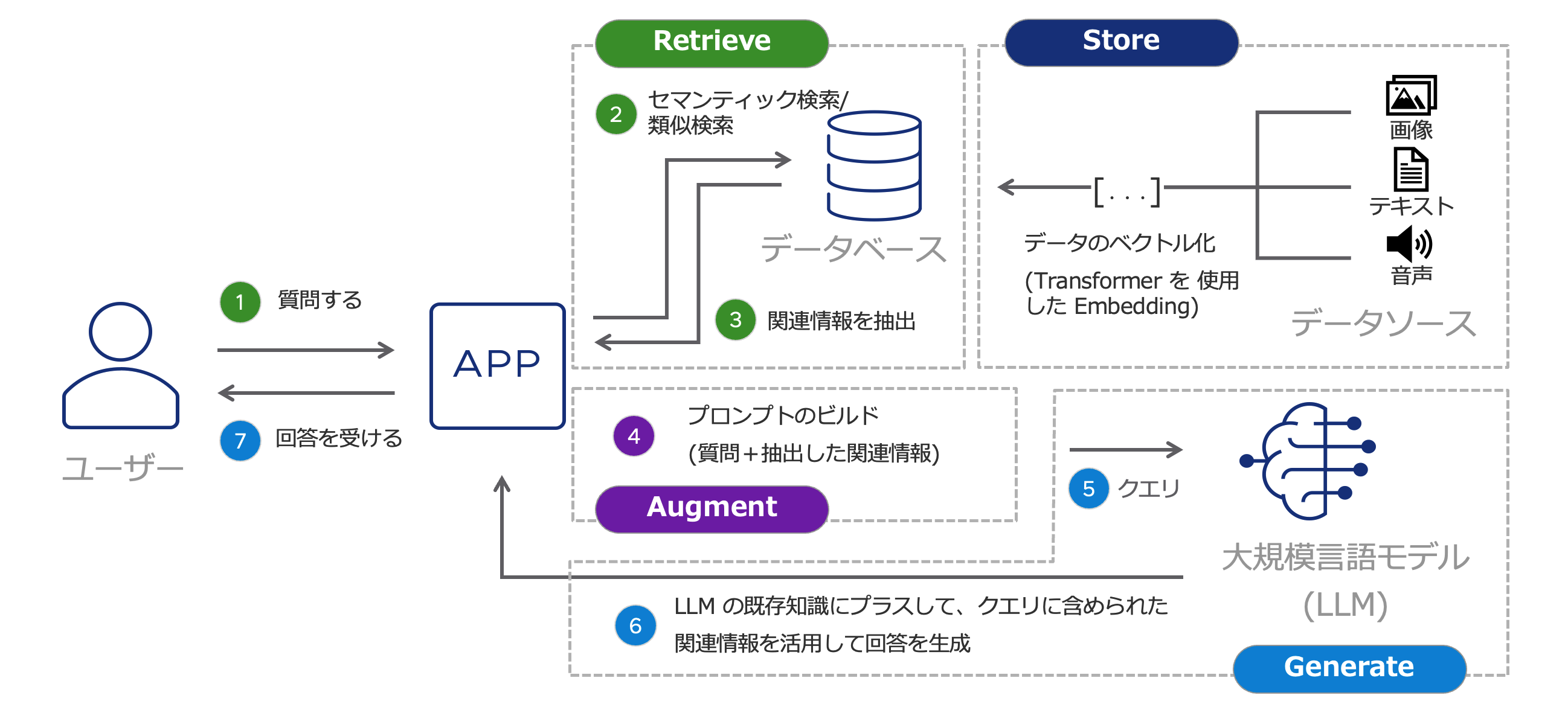
補足)セマンティック検索 とは
セマンティック検索とは、「データの持つ意味を理解させて検索する技術」を表す (一般的に、テキストの検索を「セマンティック検索」、画像や音声などの検索を「類似検索」と呼ぶ)。表現の揺らぎに対応 (類義語や活用形は同等の意味として扱う ことが可能 例:飲食店・レストラン など)。
ベクトル化されたデータからセマンティック検索することで、通常のテキスト検索に比べ関連性の高い結果が得られることや検索の高速化 などのメリットが得られる。
ファインチューニング vs RAG(検索・拡張・生成)
ここで簡単な比較をしてみます。
ファインチューニング
・データサイエンスの知識要
・高い処理能力(e.g. GPU) が必要
・大量の事前データの用意が必要
RAG (検索・拡張・生成)
・シンプルに始められる軽量なタスク
・データサイエンスの知識低
・求められる処理能力はある程度限定的
・ベクトルデータベースの活用
簡単な比較をしてみますと、上記のようになるかと思います(ReAct とかもありますが取り急ぎ)。
そこで、RAG から始めることを色々なベンダーもお薦めしていますよね。
またこの要素の一つとして、ベクトルデータベースの活用というのが、現実的に出てくるわけですね。
ベクトルデータベースの興隆
今年後半にかけて、クラウドベンダーおよびテクノロジーベンダー各社において、ベクトルデータベース提供の発表が増えています。Microsoft Azure OpenAI Service はもちろん、MongoDB、Databricks、AWS RDS/Aurora、Oracle、Google Cloud...と、もはやベクトル検索を提供していないデータ基盤を見つける方が難しい状況です。ベクトル検索に特化したデータベースを提供するスタートアップも登場してきていますよね。PostgreSQL をベースに、OSS である pgvector の実装を組み合わせたものが多く、データベースそれ自体でベクトル化機能を持っているか否か、等々、若干の機能の違いがあります。
その中で、VMware におけるベクトルデータベースの実装が、PostgreSQL + pgvector ベースの Greenplum ということになります。これが今回のサンプルにどうつかわれているか、早速、サンプルアプリのシナリオと構成について、次でご紹介しましょう。
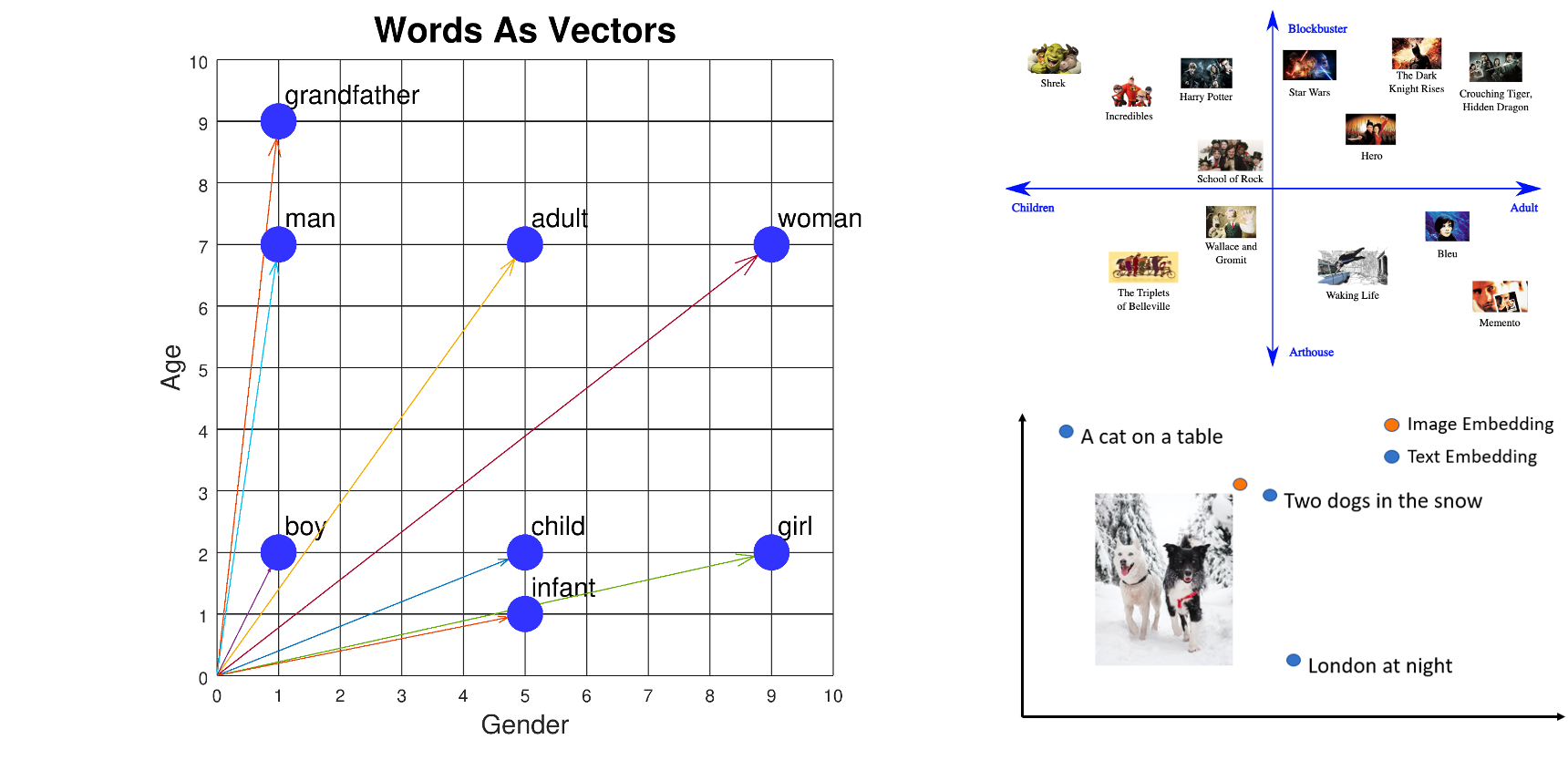
ベクトルデータベースとは
ベクトルデータベースは、データをベクトルとして表現し、高速で効率的に検索や比較が行えるデータベースの一種です。通常のデータベースではテキストや数値などの形式でデータを格納しますが、ベクトルデータベースではデータをベクトルとして表現するため、類似性の高いデータを素早く見つけることができます。ベクトルデータベースは生成 AI アプリケーションや検索エンジンなど、多くの分野で活用されており、その重要性がますます高まっています。
例えば、猫と犬は座標軸的にかなり異なりますが、猫とトラはもう少し近くの座標になる、そんなイメージですね。
参考 : ベクトルデータベースにおけるテキスト/画像検索 - Semantic Similarity Search
サンプルアプリの概要と構成
データ
このアプリのデータベースは、英語のテキストがベクトル化されて大量に格納されたものです。中身は、こちらの VMware Explore U.S. の全360超のセッションの、ID、タイトル、概要、スピーカー情報など、を格納したものと、それぞれのセッションの全文文字起こしが格納されているものになります。
VMware Explore US セッションを日本語で検索・サマリーするアプリ
全体像
このアプリは、この英語のデータベースに対して、"日本語で検索・サマリーする"ところがポイントです。このデータベースは、先ほどご紹介したベクトルデータベースですので、英語だろうと日本語だろうとフランス語だろうと、あるいは他のアジアや中東や欧州等の言語だろうと、同じような結果を期待することができるわけです。
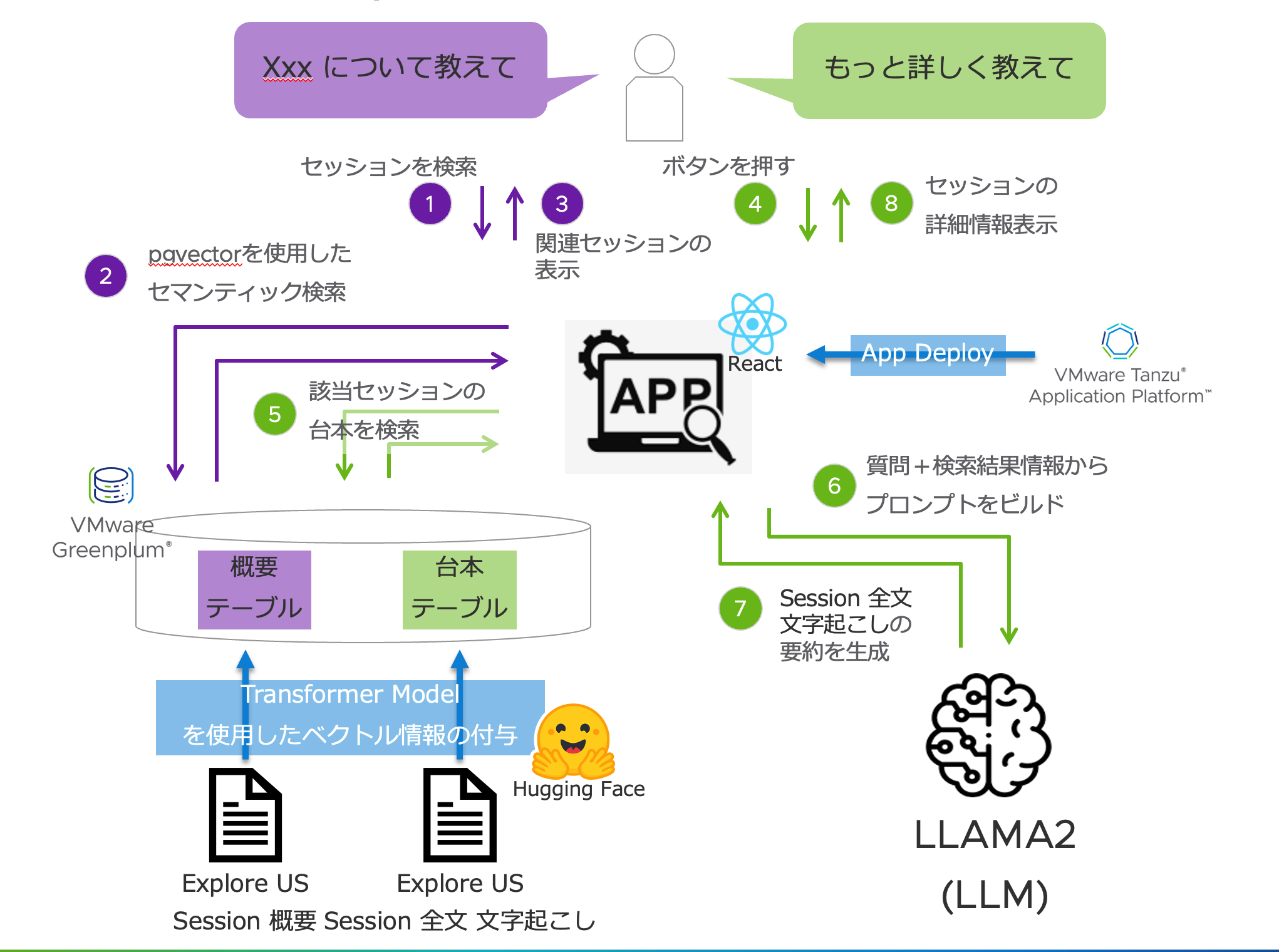
アプリのワークフローは以下の通りです。
- ユーザーが UI を通じて知りたいワードを検索
- pgvector にてクエリと概要のベクトルを比較し、関連セッションを検索
- UI に関連セッション一覧を表示
- 詳しく知りたいセッションの「もっと詳しくリンク」を押す
- 該当セッションの全文文字起こしを検索
- Greenplum DB より取得された全文文字起こしから LLM へのプロンプトを生成し、LLM へクエリ
- セッション全文文字起こしの要約を生成
- UI にセッションの要約を(徐々に... → ここがポイントです。ソースコードを参照)表示
実際のアプリの実行画面
それでは、実際のアプリの実行画面をお見せしましょう。先ほどの図にある通り、このアプリのバックエンドは、Tanzu Application Platform 上にデプロイされた API アプリのコンテナで、このバックに、ベクトルデータベースとしてのVMware Greenplum があります。
そしてこのアプリのフロントエンド側は(ブラウザーでデモをする関係で)React で作ってあります。
今回は、iOS シミュレーターの Safari で実行しています。
- ユーザーが UI を通じて知りたいワードを検索

- pgvector にてクエリと概要のベクトルを比較し、関連セッションを検索 (※1 : 下記参照)

- UI に関連セッション一覧を表示(※2 : 20件に設定してあります)
- 詳しく知りたいセッションの「もっと詳しく」リンクを押す

- 該当セッションの全文文字起こしを検索
- Greenplum DB より取得された全文文字起こしから LLM へのプロンプトを生成し、LLM へクエリ
- セッション全文文字起こしの要約を生成
- UI にセッションの要約を徐々に表示

以上です。いかがでしょうか?
色々な業種・業態に応用が可能なアプリだと思います。
ベクトルデータベースに格納されている多次元のベクトル同士の比較(上記フローの2.※部分の補足)
ここでちょっとだけ補足させてください。上記の全体像の図にもある通り、検索実行時に、このアプリは、pgvector にてクエリと概要のベクトルを比較し、関連セッションを検索しています。これはモデルをその都度ダウンロードしてくることになります。そこでされている処理は、まさにベクトルデータベースに格納されている多次元のベクトル同士の比較です。
たとえば、Hello World! というテキストがどのようなベクトルで格納されているかといえば、このようなイメージになります。


ソースコード
このアプリは、@hmachi さんと僕とで実稼働20時間くらいで開発しています。
- Tanzu Application Platform にデプロイする API アプリケーション(@hmachi さんのリポジトリ)
https://github.com/mhoshi-vm/explore-api - React のフロントエンド側アプリケーションは僕(@shosuz のリポジトリ)
https://github.com/shosuz-evangelist/react-ai-explore
にあります。ご興味のある方はぜひご参照ください!
Tanzu Application Platform による迅速な開発とデプロイ
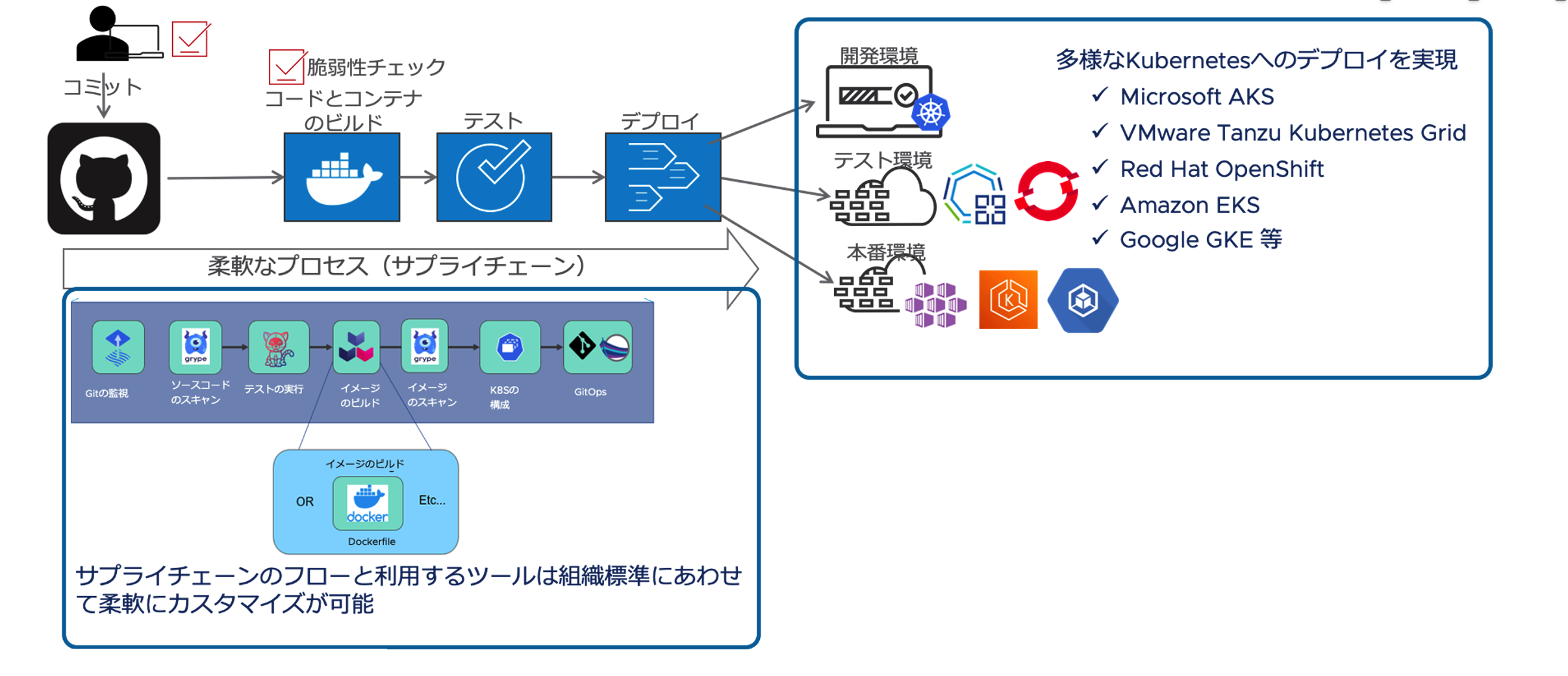
今回はアプリのご紹介等中心にご説明しましたのであまり書けなかったのですが、この両者を Tanzu Application Platform でモニタリングできますし、CI/CD も簡単に実施できます。コンテナを作る必要はなく、コマンドラインで実行するだけで、コンテナ(API、React Web アプリ)のいずれもデプロイされて立ち上がります。例えば 2. のコードの UI を実際にイベント終了後に、修正して GitHub にコミットしてプッシュしました。3−4分で新しいコンテナが立ち上がって新しい UI で立ち上がります。またソースコードやコンテナの脆弱性のチェック設定、ツール選択なども全て可能です。この辺りまたの機会に書かせて戴きますね。
まとめと次回の予告
以上で、VMware Tanzu Application Platform / Greenplum データベースと React のサンプルアプリご紹介は終わりです。いかがでしたでしょうか?
次回21日のブログエントリでは、今年の11/11にJJUG 2023 ででご紹介した GitHub Copilot/Copilot Chat を使った Spring Boot アプリ開発について、ご紹介できればと思います。お楽しみに!