
皆様こんにちは!
Elastic テクニカルプロダクトマーケティングマネージャー/エバンジェリストの鈴木章太郎です。
この記事は、Google Cloud Platform Advent Calendar 2021、12/8のエントリです。
ちょっと前になりますが、10月に GA した Elastic 7.15 (最新版)においては、かなり多くのアップデートがありました。僕自身、Elastic の 当該 Webinar でこの辺りお話ししていますが、1時間でかなりの枚数(100枚超え)のスライドを話しています。そして Google Cloud とのデータ統合機能については、弊社ブログにも分散して書いてあるところ、非常に便利かつ有益なアップデートばかりですので、改めて1個のブログ記事に纏めて皆様にご紹介したいと思います。
Elastic は、10月13日の段階で、Google Cloud との継続的なパートナーシップを通じてリリースされた最新の開発成果について発表しています。その内容と、データのストリーミングや格納、検索、分析に際し、一連の機能を活用する具体的な方法について解説します。
現在、Elastic と Google Cloud 両方のプラットフォームを使って戴いているユーザーで、DevOps や DevSecOps を遂行する組織のユーザーは、追加のソフトウェアをインストールや、YAMLファイルの設定をすることなく、BigQuery、Google Cloud Storage、またはPub/Sub から Elastic にデータをシッピングすることができます(ネイティブ統合機能)。この一連の統合機能を活用すれば、ユーザーは付加的なソフトウェアのインストールや保守、あるいは設定といった運用上のオーバーヘッドを負担する必要がなくなり、重要な業務に集中できるようになります。
また、現在、Elastic と Google Cloud 両方のプラットフォームを使って戴いているアプリ開発領域のユーザーは、Google Cloud Firestore 拡張機能を使って Firestore を使ったアプリに、スムーズに App Search 検索機能を追加可能になりました。すなわち、モバイルアプリや Web アプリに、高速でスケーラブル、関連性の高い、優れた検索機能を追加するために必要な時間や手間を、大幅に短縮可能です。
本ブログ記事では、各統合機能と一般的なユースケース、導入の手順についてご説明します。ユーザーがデータを最大活用できるよう、Google Cloud と Elastic は一連の統合機能の強化に取り組んでいます。各機能の具体的な内容を見てみましょう。
BigQuery による異なるソースのデータ一元化が可能
BigQuery は人気のサーバーレスデータウェアハウスソリューションです。BigQuery を使って、カスタムアプリや各種データベース、Marketo、NetSuite、Salesforce、Web クリックストリーム、Elasticsearch などの異なるソースのデータを一元化できます。ユーザーは BigQuery で異なるソースのデータセットを結合し、SQL クエリをかけてデータを分析できます。BigQuery SQL ジョブのアウトプットは一般的に、BigQuery で別のビューや表を作成するために活用されたり、また組織の関係者やチームと共有するダッシュボードの作成に活用されたりしています。いずれも、Elastic のネイティブなデータ可視化ツール、Kibana で行うことができます。BigQuery と Elastic Stack を組み合わせるもう1つの重要なユースケースに、全文検索があります。すなわち、BigQuery から Elasticsearch にデータをインジェストし、次に各種 Elasticsearch API や Kibana を使ってクエリをかけて検索結果を分析する、といった使い方も可能です。
データインジェストを最適化する
Google Dataflow は、Apache Beam をベースとするサーバーレス非同期メッセージングサービスです。 Google Dataflow をLogstash に代えて使うと、Google Cloud Console からデータを直接インジェストすることができます。そこで Google と Elastic のチームは、BigQuery から Elastic Stack にデータをプッシュする、設定不要の Dataflow テンプレートを共同開発しました。このテンプレートは、従来 Logstash が担っていたデータ形式変換などのデータ処理をサーバーレスな手法で実行します。ユーザーは Logstash をこのテンプレートに置換するにあたり、既存の Elasticsearch インジェストパイプラインに変更を加える必要はありません。
BigQuery と Elastic Stack を併用するユーザーはこれまで、最初に Google Compute Engine 仮想マシン(VM)上に Logstash のようなデータプロセッサー、あるいはカスタムソリューションを個別にインストールし、そのデータプロセッサーなどを使って BigQuery から Elastic Stack にデータを送信する必要がありました。しかしこの方法では、VM のプロビジョニングやデータプロセッサーのインストールに伴ってプロセスや管理の手間が生じます。現在はこの手順を省き、Dataflow のドロップダウンメニューを使って BigQuery から Elastic に直接データをインジェストすることができるようになりました。手間を減らす取り組みは多くのユーザーに役立ちますが、Google Cloud Console を数回クリックするだけでインジェストが完了するとなればなおさらです。
以下に、データインジェストのフローを示します。このインジェストフローは、Elastic Cloud の Elastic Stack から、Google Cloud Marketplace の Elastic Cloud、セルフマネージド環境まで、すべてのユーザーに共通です。
BigQuery Dataflow
使い始める
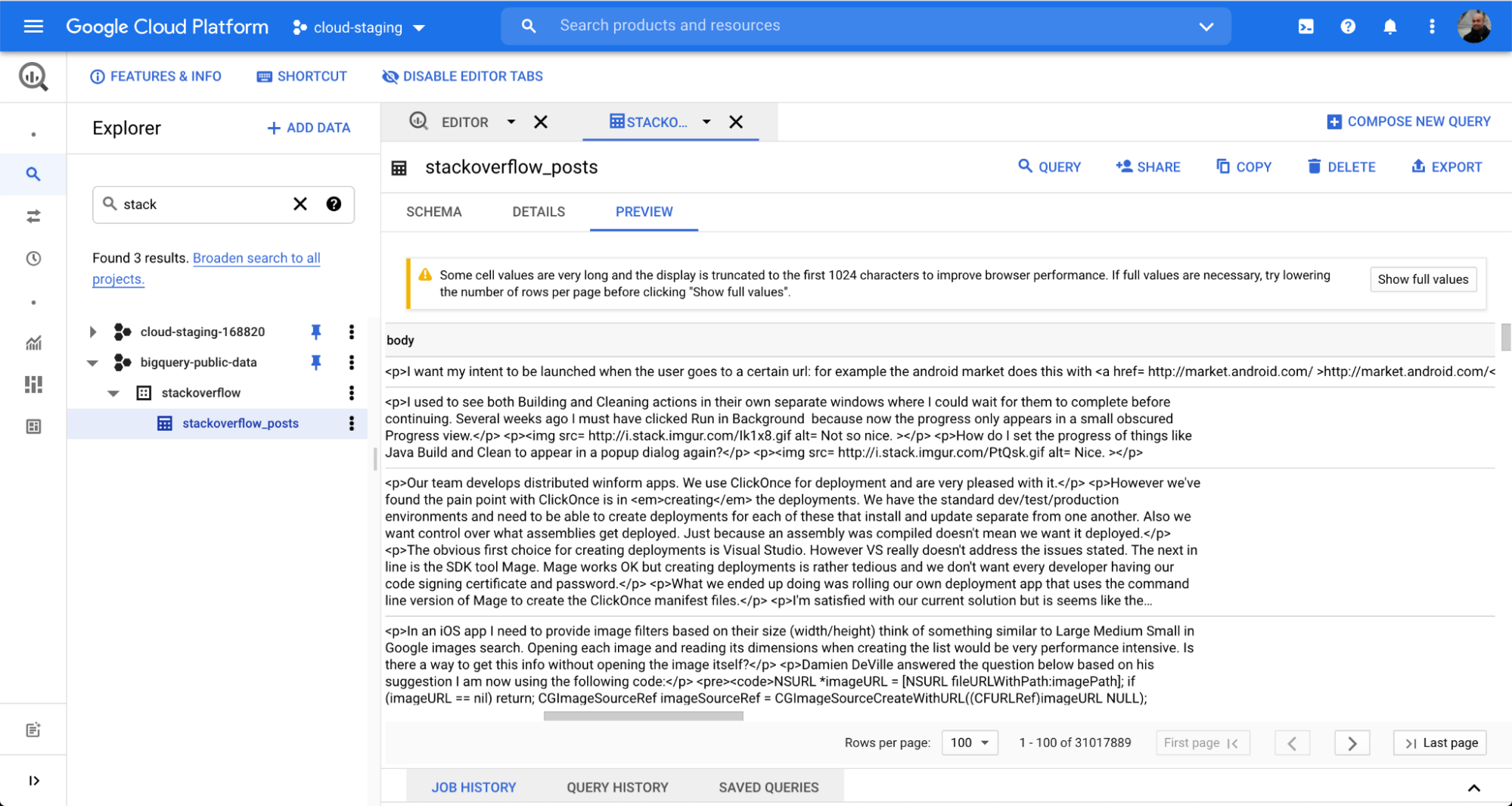
BigQuery から Elasticsearch に簡単にデータをインジェストできることを示すため、今回は人気の Q&A フォーラム、Stack Overflow に公開されているデータセットを使用してみます。Dataflow バッチジョブを経由して数クリックでデータをインジェストし、その後 Kibana で検索や分析を始めることができます。
この例では BigQuery データセット、stackoverflow 以下にある stackoverflow_posts という表を使用します。表には複数の構造化フィールドが post body、title、comment_count などの列形式で存在しており、これらを Elasticsearch に取り込んでフリーテキスト検索やアグリゲーションを行います。
Google Cloud Platform
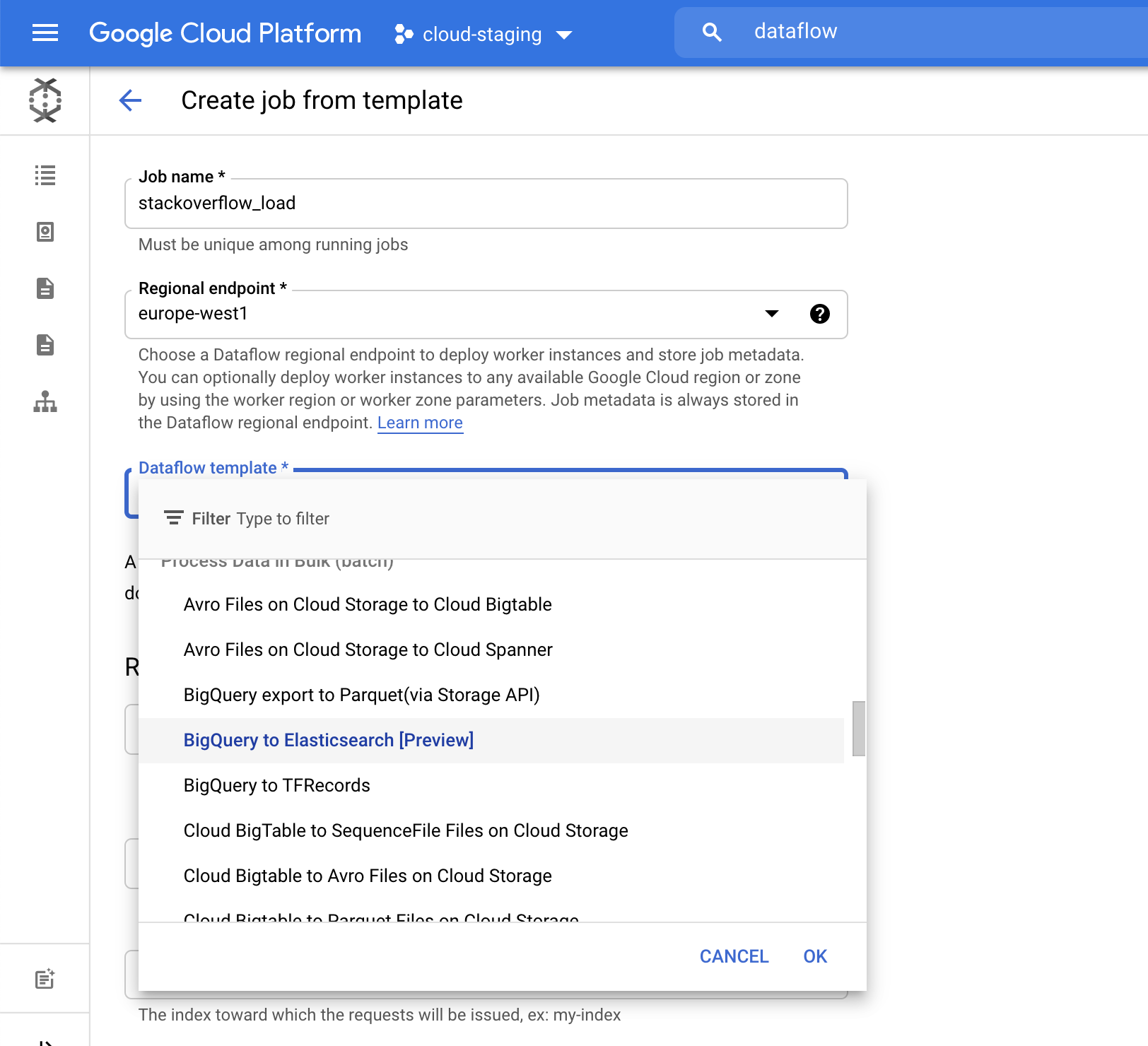
テンプレートから Dataflow ジョブを作成します。Google が提供するテンプレートの1つ、**[BigQuery to Elasticsearch]**テンプレートをドロップダウンメニューで選択します。
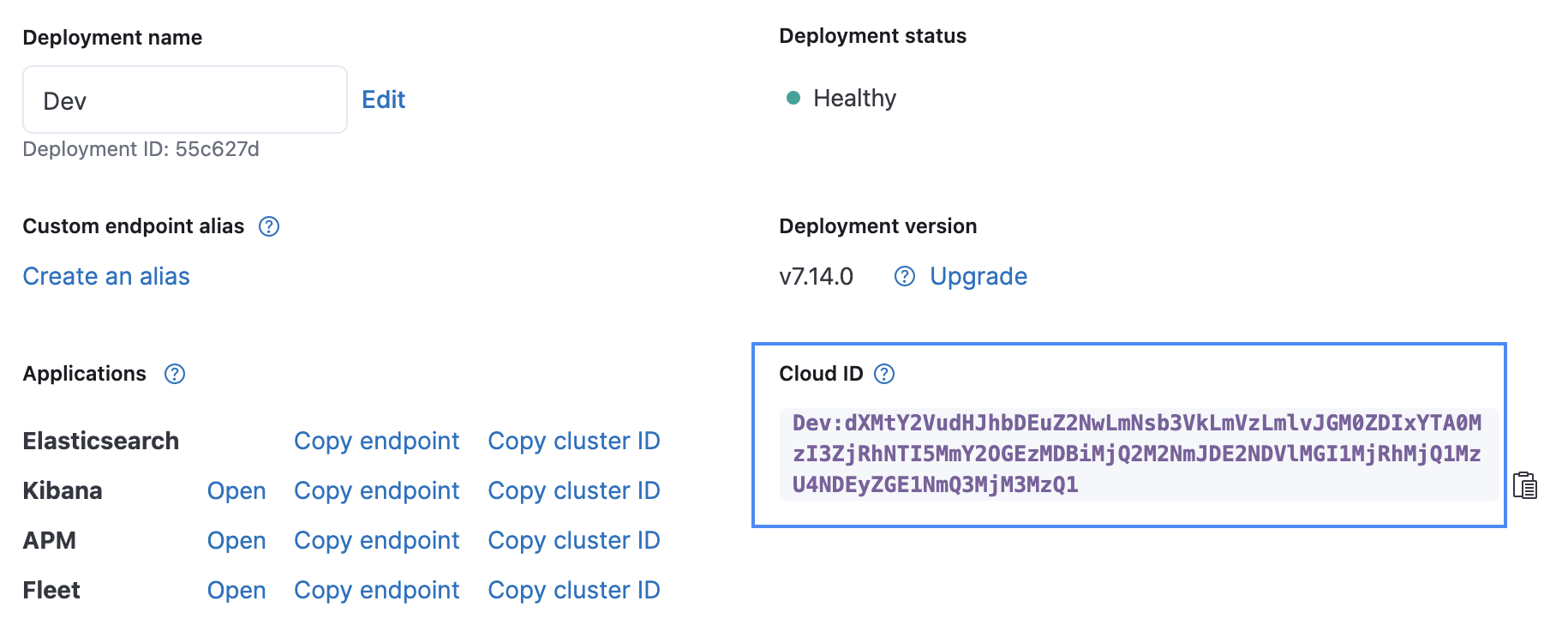
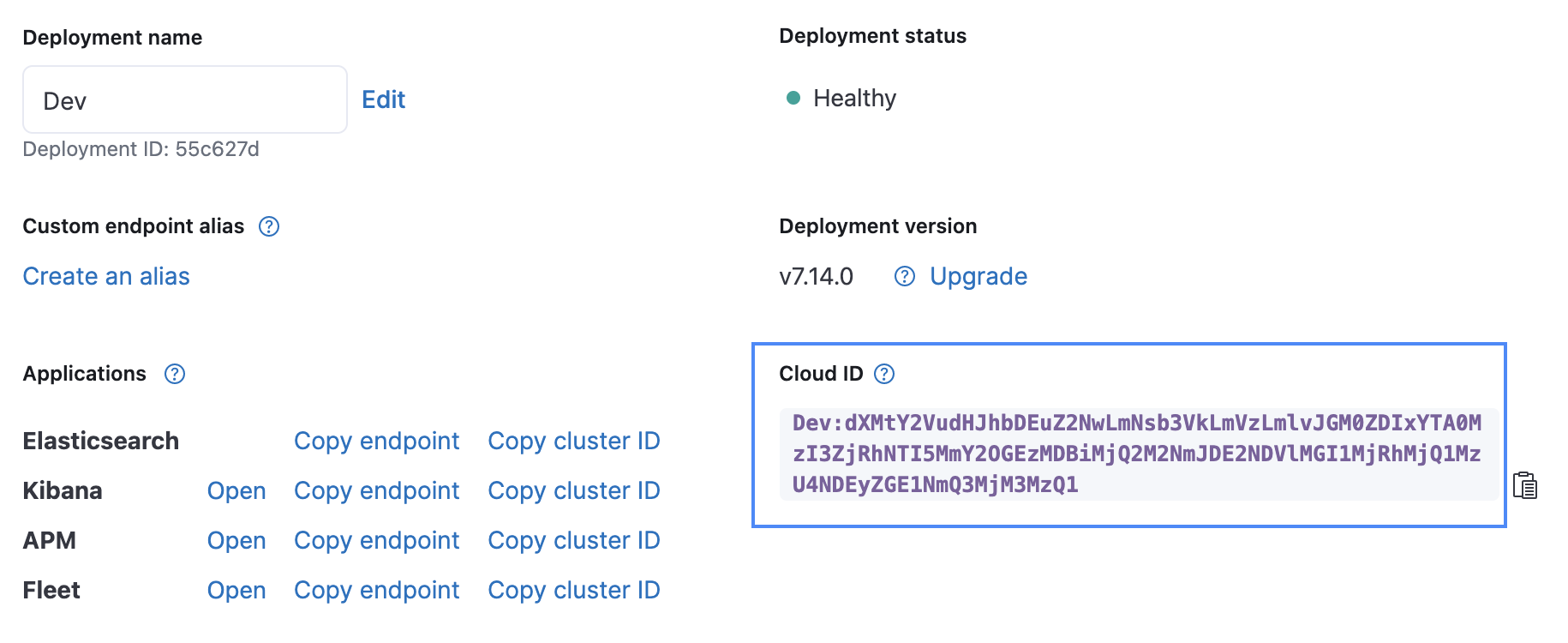
Elasticsearch の Cloud ID や Base64-encoded API Key を含む、必要なパラメーターを入力します。Cloud ID は、下の画像に示すように Elastic Cloud UI で見つけることができます。API Key は、Create API key API を使って作成することができます。
[Elasticsearch index] に、データの読み込み先となるインデックス名を指定します。この例では [stack-posts] インデックスを使用しています。 BigQuery 内の表を読み込む際に使用する形式は、my-project:my-dataset.my-table です。この例の場合は、bigquery-public-data:stackoverflow.stackoverflow_posts となります。
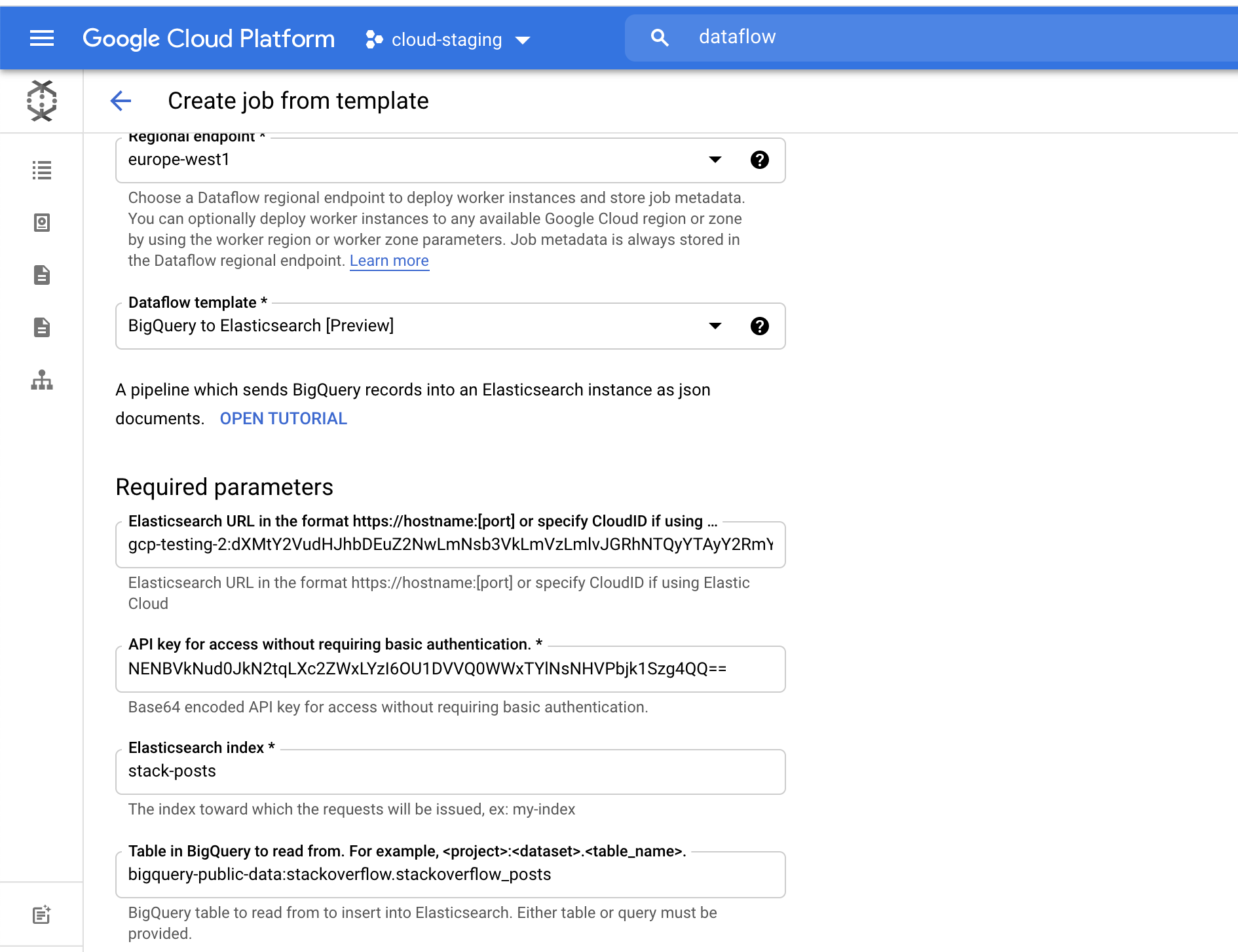
テンプレートからジョブを作成する
[Run Job](ジョブを実行)をクリックするとバッチ処理が始まります。
数分以内に、Elasticsearch インデックスがデータを取り込む様子を確認できます。このデータを可視化するには、Index pattern 作成のドキュメントの手順に沿ってインデックスパターンを作成します。
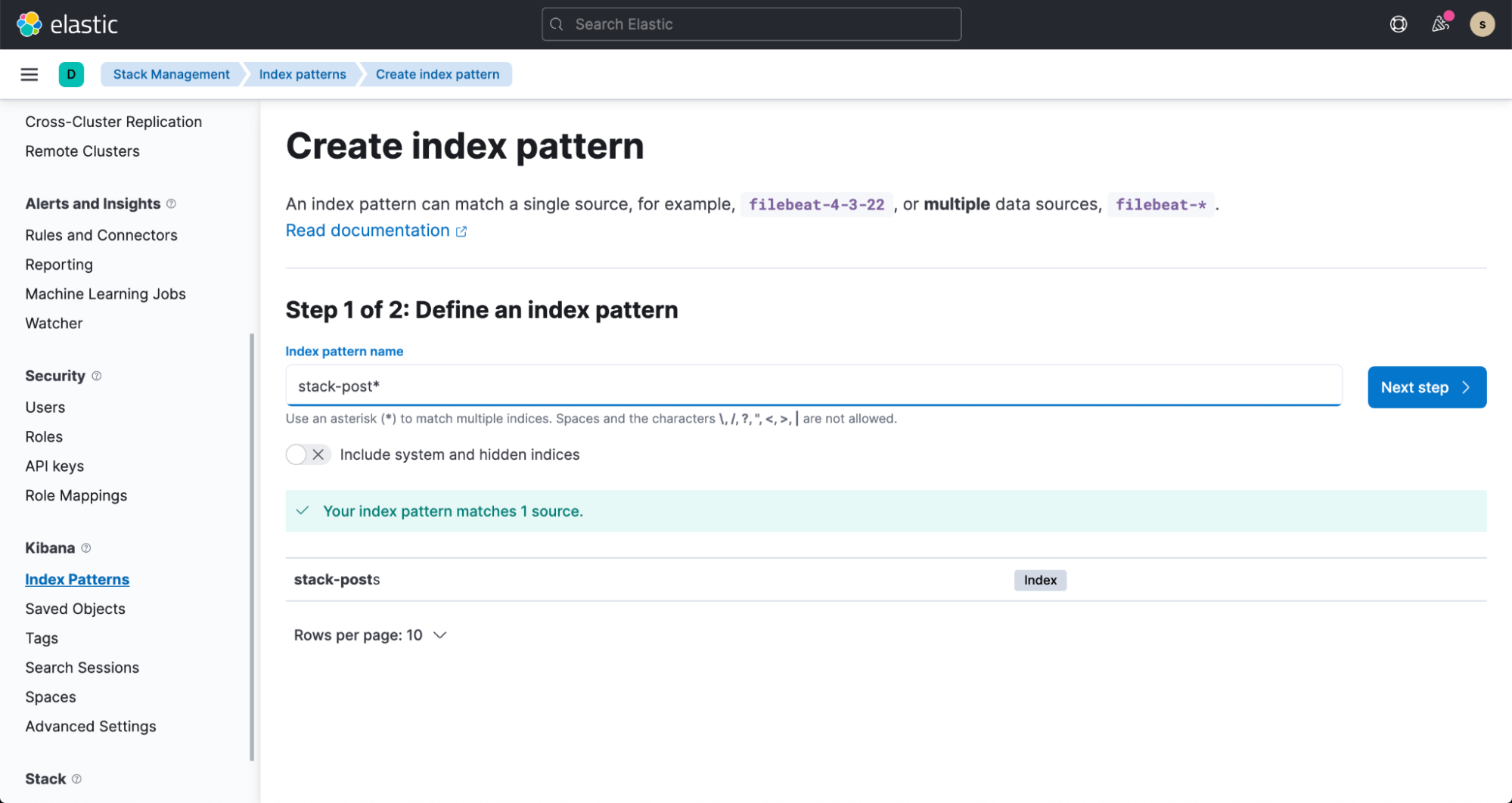
インデックスパターンを作成する
これで Kibana の [Discover] リンクから、データの検索をはじめることができます。
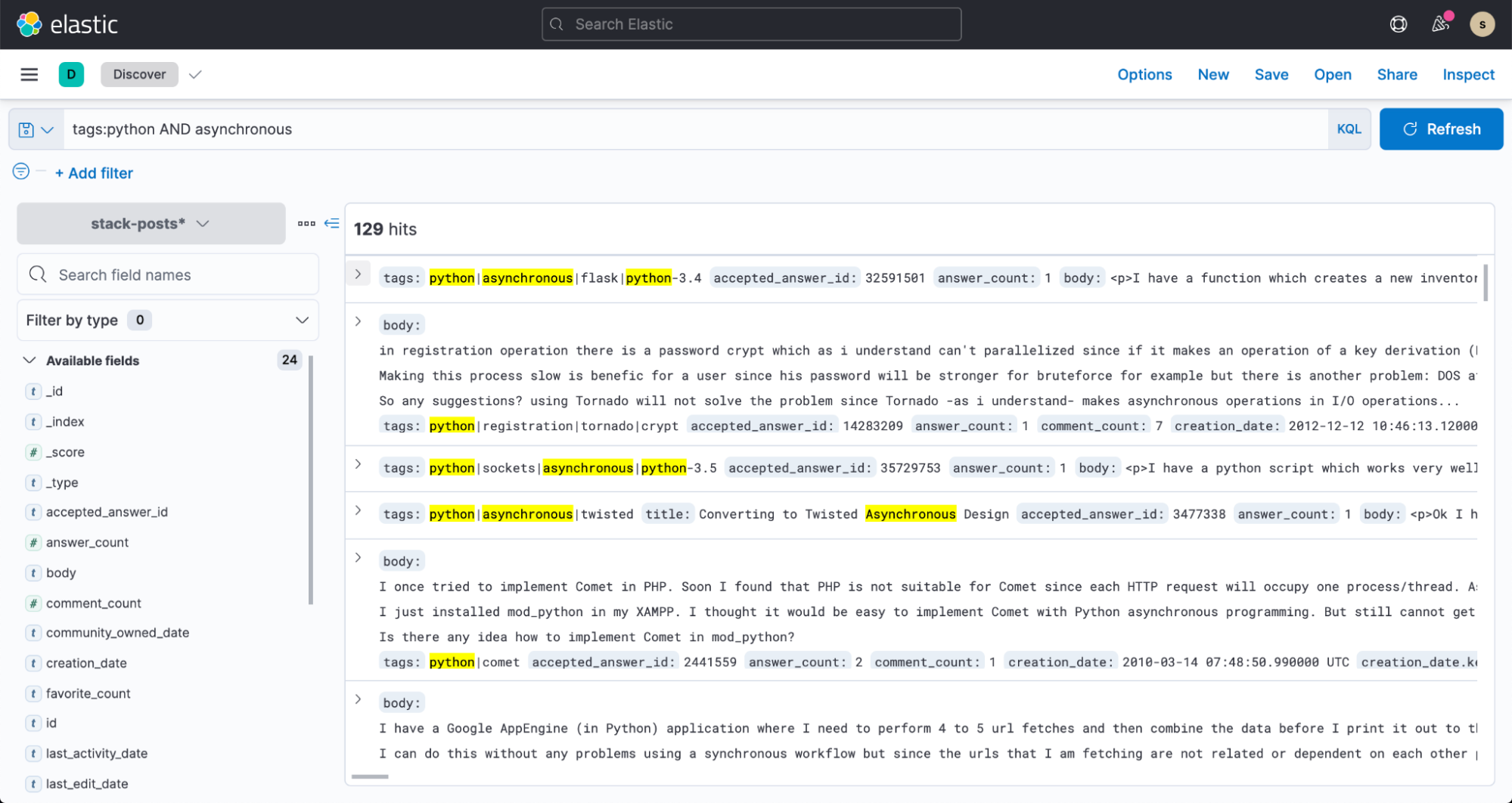
Kibana Lensを使って検索クエリ用に comment_count の上位5つのバケットを可視化したり、フィルターやダッシュボードを作成したりしてみましょう。
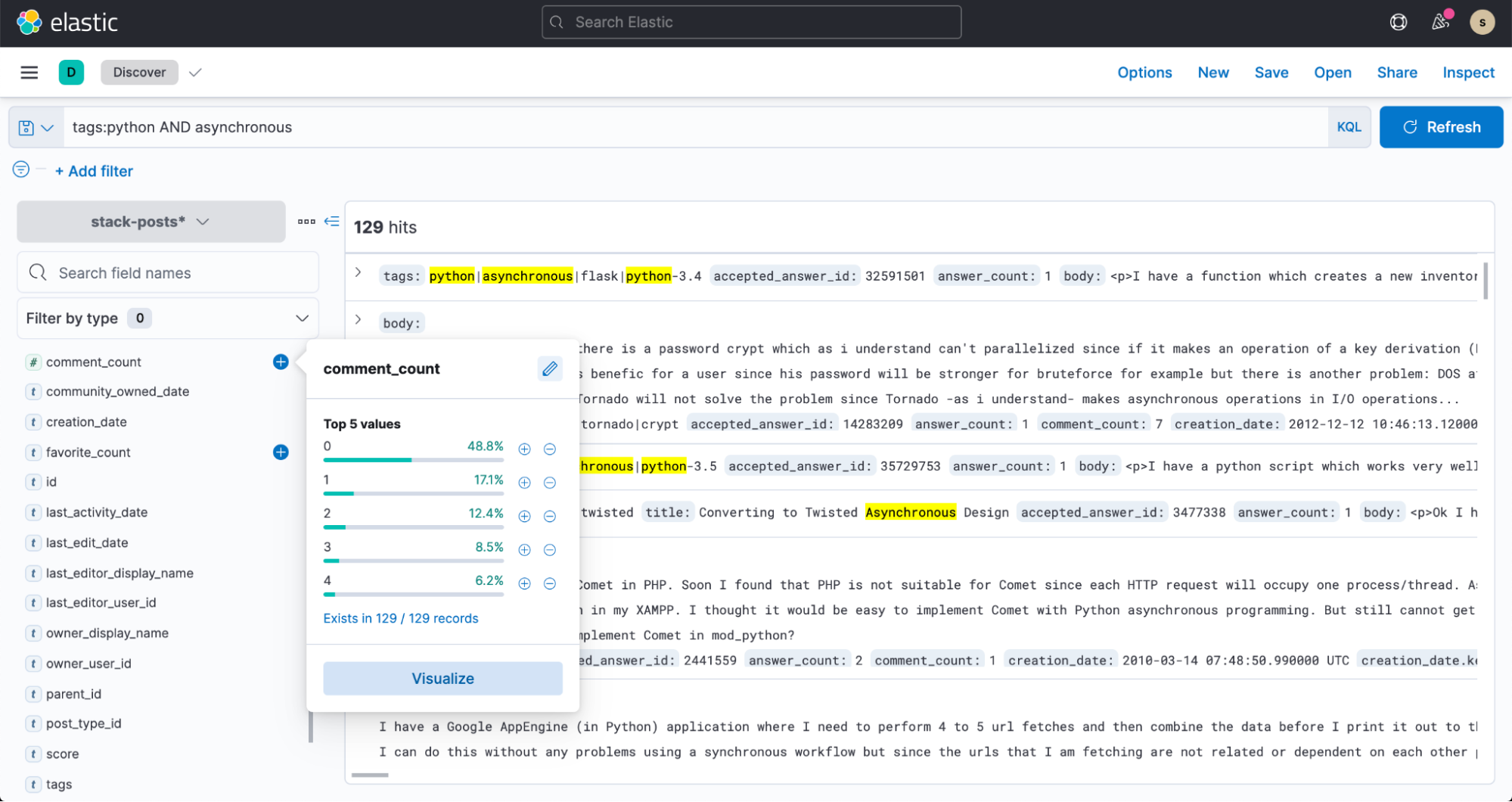
Firebase/Firestore & Elastic App Search 連携が可能
![]()
アプリに効果的な検索エクスペリエンスを追加する作業は、一筋縄ではいかないこともあります。ストアで商品を検索する場合も、サポートサイトで記事を検索する時も、公式ブログで記事を探す時も、エンドユーザーは結果が高速に表示されることを期待します。直近のリリースでは、Google Cloud Firebase/Firestore 向け Elastic App Search 連携の拡張機能を使って、Firestore を使用するアプリに高速でスケーラブル、関連性にすぐれた検索エクスペリエンスを手軽に構築することができるようになりました。モバイルアプリのバックエンド (mBaaS) として人気の高い Firebase は検索機能が弱く、Elastic を含むサードパーティ製検索機能を使うことが Google のドキュメントでも推奨されています。

Elastic は、Google Cloud Firestore 向け Elastic App Search 拡張機能をリリースしました。Firebase 拡張機能のディレクトリを数回クリックするだけで、Firestore をベースに構築されたモバイルアプリ、および Web ベースアプリに手軽に検索機能を追加できます。
カスタマーバリューの向上
顧客がモバイルアプリや Web ベースアプリに求める重要な要件の1つが、インタラクティブでリッチな検索機能です。ストアで商品を検索する場合も、サポートサイトで記事を検索する時も、公式ブログで記事を探す時も、顧客は結果が高速に表示されることを期待します。Google Cloud Firestore 向け Elastic App Search 拡張機能には堅牢な関連性調整機能が搭載されており、特定の Firebase アプリデータ、あるいは、顧客の好みに応じて検索結果をカスタマイズできます。さらに入力候補や誤入力対応、フィルターやファセット機能も内蔵されており、洗練された検索エクスペリエンスの提供に貢献します。また、Elastic App Search の分析機能で検索の測定、調整を実行し、要件の変化に応じて簡単に検索を適応、スケールさせることが可能です。アプリ上での顧客の検索行動や傾向について包括的な可視性を確立でき、改善すべき領域に集中して取り組むことができます。
インストールと管理をスムーズ化
開発者の多くは、モバイルアプリや Web ベースアプリの開発に伴うタスクを削減し、新製品を早期開発する、また顧客の要望にタイムリーに応える、という目的で Firebase を使用しています。Firestore は Firebase と Google Cloud のどちらからも利用可能なNoSQL データベースであり、アプリデータを格納、同期することができます。Google と Elastic は、アプリにパワフルな検索エクスペリエンスを構築する、使いやすくスムーズな手法の提供を実現させるべく協働してきました。その成果が、この Firestore 向け Firebase 拡張機能です。
かつては、アプリに効果的な検索エクスペリエンスを追加する作業が一筋縄ではいかないことも少なくありませんでした。しかし、この拡張機能がリリースされたことで、時間のかかるインストールやソフトウェア保守作業は不要となり、開発者はビジネスの目標やアプリの機能向上に注力できるようになりました。実際の検索向けに最適化された関連性モデルや直感的に操作できるダッシュボード、高速な立ち上げといった多数のメリットに加えて、Elasticsearch のスケーラビリティとスピードを活かすことができます。
使いはじめる
Google Cloud Firestore 向け Elastic App Search 拡張機能は、わずか数クリックで使い始めることができます。ここからは、開発者と顧客に最適なエクスペリエンスをもたらす導入の手順をご説明します。
はじめに、エンタープライズサーチのデプロイを立ち上げます。
Cloud で、App Search プロジェクトを作成します。この操作は、[Create Deployment](デプロイを作成)ページ で実行できます。
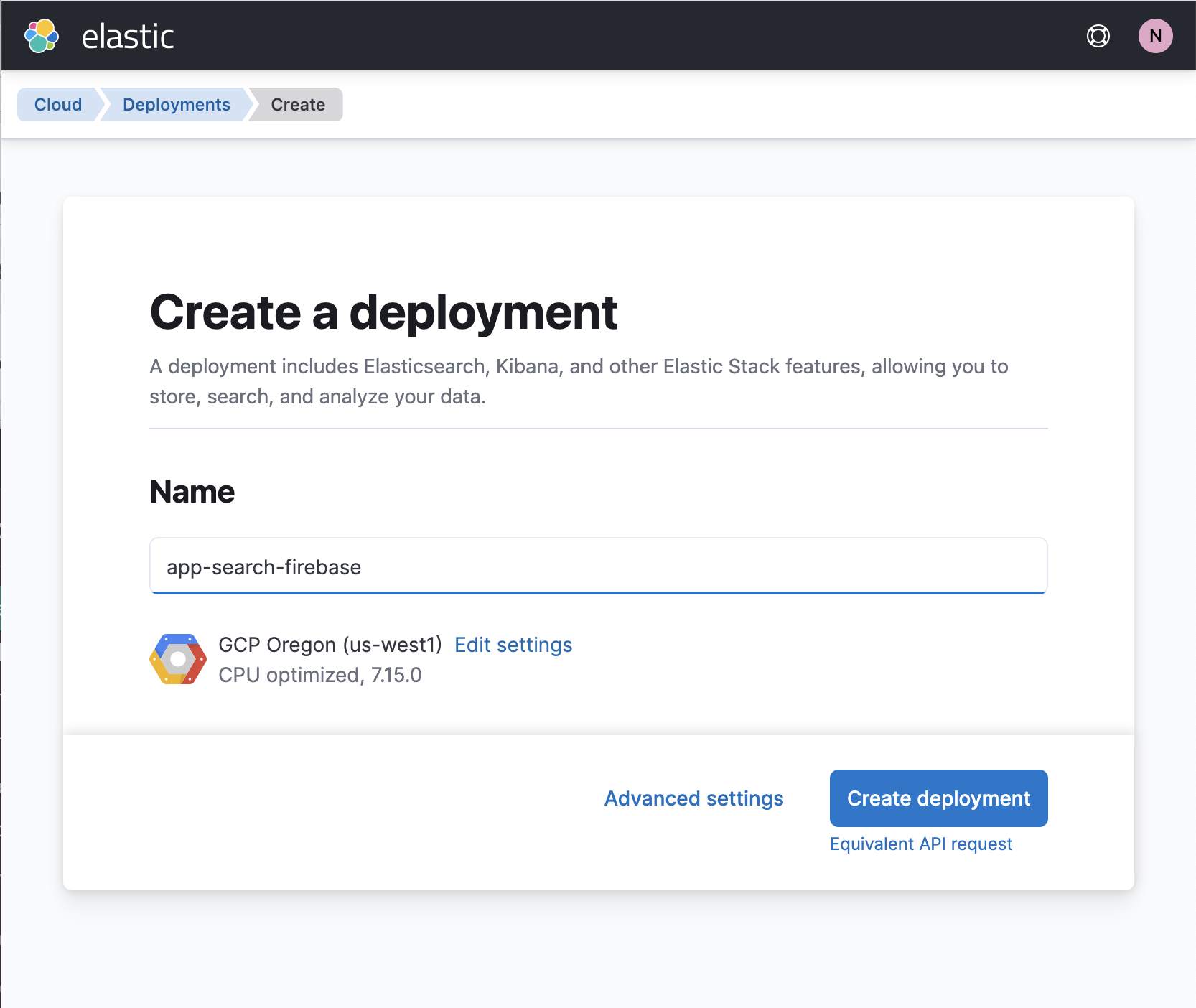
デプロイが作成されたら、Kibana のサイドバーで [App Search] をクリックし、使用する検索エンジンを作成します。
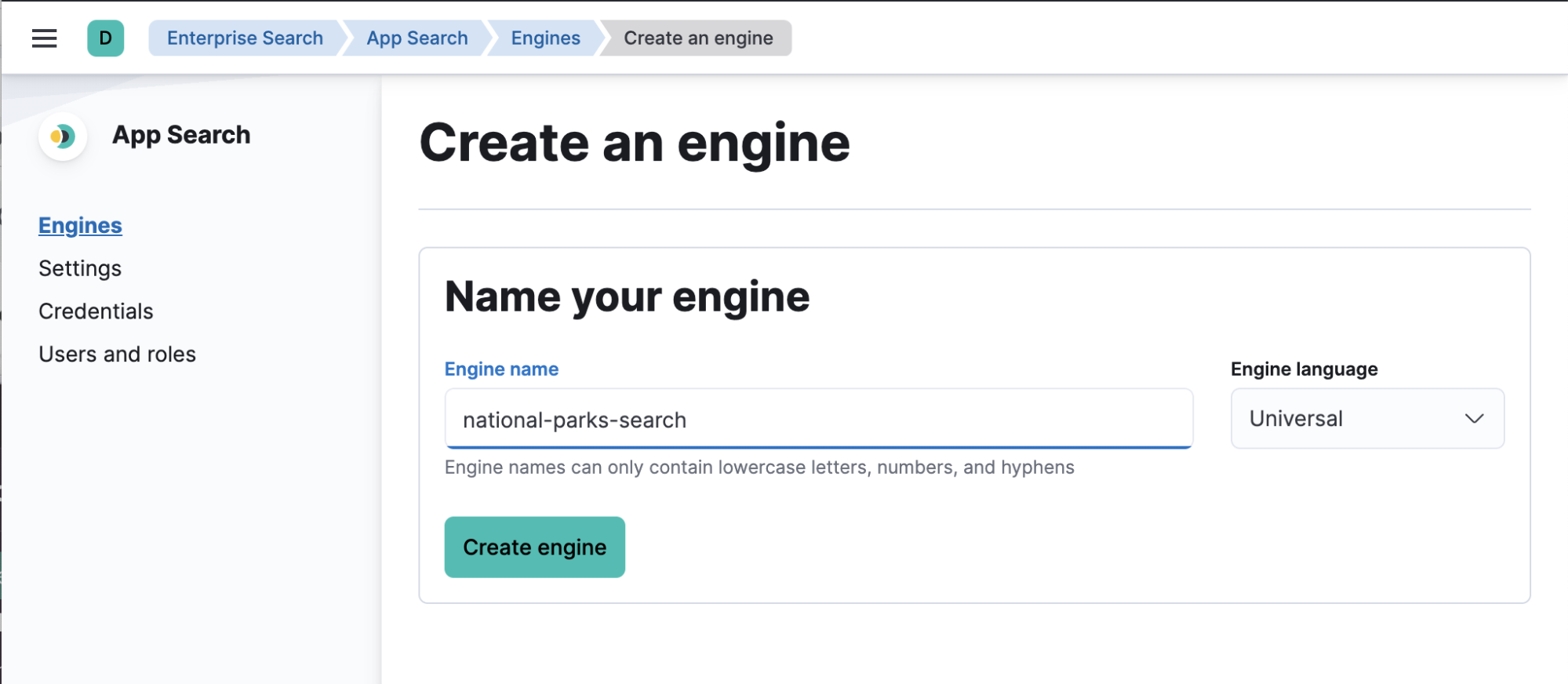
App Search に関する情報をいくつか入力します。
- 作成した検索エンジンの名前
- App Search プライベートキー
- エンタープライズサーチインスタンスのベース URL
プライベートキーとベース URL は、[Credentials](認証情報)ページで確認できます。このページを開くには、サイドバーで[App Search]→[Credentials]に進みます。

ここまでの手順で、App Search エンジンが Firestore からドキュメントを受信する準備が整っています。
Firebase 拡張機能のディレクトリで Elastic App Search 拡張機能を選択し、プロジェクトにインストールします。
App Search で収集した情報に加えて、いくつかのフィールドを記入する必要があります。
- [Collection path](収集パス)は、データを格納するコレクションの名前です。
- [Indexed fields](インデックス済みフィールド) — App Search は、ユーザーが定義したフィールドのみインデックスします。通常、検索を実行し、回答を返す対象のフィールドだけを選択します。

まだ作成していない場合は Firestore データベースとコレクションを作成し、コレクション ID とパスについて、入力済みの内容とかならず一致させます。
この段階で、関連性調整や分析など、包括的な検索インターフェースを構築するために必要なすべての検索ツールへのアクセスが確立されています。コレクションにドキュメントを追加すると、App Search にインデックスされます。
既存のドキュメントがある場合は、ドキュメントのバックフィルが必要です。バックフィルを実行するには、Firebase拡張機能ディレクトリの「Search with Elastic App Search extension」(「Elastic App Search拡張機能を使って検索する」)にある、「How this extension works」(「この拡張機能の動作」)セクションに記載された手順に従ってください。
拡張機能で App Search の検索エンドポイントをコールして、検索を行うことができます。詳しくは、App Search ドキュメントをご覧ください。
検索エクスペリエンスを立ち上げる必要がある場合、React コンポーネントを搭載した Javascript ライブラリ、Search UI が役立ちます。詳しくは、Search UI GitHub レポに公開されています。
Firestore 向け Elastic App Search 拡張機能について
Elastic はユーザーが望む場所で、ユーザーが望むメソッドで、より簡単にプロダクトを実行できるよう継続的な開発を進めています。Google Cloud Firestore 向け Elastic App Search 拡張機能は、その最新の事例です。Elastic App Search 拡張機能を立ち上げる手順は以上です。この手順については、Firebase 拡張機能ディレクトリや、elastic.co/jp/ でもご紹介しています。
Jagu'e'r Cloud Native #3 LT 登壇します
12/22 開催のJagu'e'r Cloud Native #3 みんなで語り合おう!クラウドネイティブLT祭りで、「Firebase/Firestore 拡張機能 による Elastic App Search 連携について」というタイトルで、実際にこの部分を、デモを交えて5分でご紹介予定です。Jagu'e'r 会員企業の方は、ぜひご登録・ご参加ください!

Google Dataflow を使って Google Cloud Storage に格納されたログとイベントを Elastic Stack にインジェスト可能
GCS(Google Cloud Storage) は、データのバックアップやシステムログのアーカイブに使用されることの多いオブジェクトストレージソリューションです。統合機能のリリースに伴い、Google Cloud Console を数クリックするだけで、GCSに格納されているログとイベントをElastic Stackにインジェストすることが可能になりました。Elasticsearch と Kibana でトラブルシューティングや監視を実施したり、セキュリティの異常を確認したりする際も、この統合機能を使えばデータを簡単に、スムーズにインジェストできます。
開発者や SREs(Site Reliability Engineers)、セキュリティアナリストなどのユーザーは、Google Cloud Console を数回クリックするだけで GCS のデータを Elastic Stack にインジェストできるようになりました。
Google Cloud 上のアプリやインフラが生成するログとイベントの格納に GCS を使用し、トラブルシューティングや監視、セキュリティ上の異常の確認には Elastic Stack を使用するという開発者や SRE、セキュリティアナリストは少なくありません。 Google と Elastic はこの2つのソリューションのエクスペリエンスを強化する目的で協働し、GCS に格納されたログとイベントを Elastic Stack にインジェストする、ストレスフリーで使いやすい手法の提供を実現させました。この手法はデータパイプラインアーキテクチャーをシンプル化するほか、運用上の手間を省き、トラブルシューティングの所要時間を短縮できるといったメリットをユーザーにもたらします。Google Cloud Console を数回クリックするだけで済み、カスタムのデータプロセッサーを作成する必要はありません。
ここでは、Google Dataflow を使って、エージェントを経由せずに GCS から Elastic Stack にデータをインジェストする方法をご紹介します。
GCSからのデータインジェストを最適化する
GCS(Google Cloud Storage) は、Amazon S3 や Azure Blob Storage ともよく比較されるオブジェクトストレージソリューションです。GCS はその魅力的な価格から、ストリーミング要件のないデータのバックアップやアーカイブ、データ分析に加え、シンプルなWebページやアプリのホスティングにもよく利用されています。開発者や SREs、セキュリティアナリストなどのユーザーは、バックアップやアーカイブのためにアプリやインフラのログとイベントを GCS に格納することがあります。また、Google Cloud ユーザーのデータパイプラインが、すべてのデータを Elastic Stack にインジェストする設定にはなっていないケースもあります。つまり、データの一部が GCS に格納され、後で必要な場合に分析できるように保持されているというケースです。
ログが GCS に送信された後、そのログを Elastic のようなサードパーティの分析ソリューションにインジェストするメソッドは、ユーザーが決定しなくてはなりません。もし Google Cloud Console を数回クリックするだけで GCS のデータを直接 Elastic Stack にインジェストすることができれば、理想的なメソッドとなります。実は現在、Apache Beam をベースとする人気のサーバーレスデータ処理製品、Google Dataflow のドロップダウンメニューからこのメソッドを実行することが可能になっています。Dataflow は実質的に、GCS からログとイベントを Elastic Stack にプッシュします。現時点でサポートされているファイル形式は CSV ですが、Elastic は近日、JSON のサポート開始を予定しています。
以下に、データインジェストのフローを示します。このインジェストフローは、Elastic Cloud の Elastic Stack から、Google Cloud Marketplace の Elastic Cloud、セルフマネージド環境まで、すべてのユーザーに共通です。
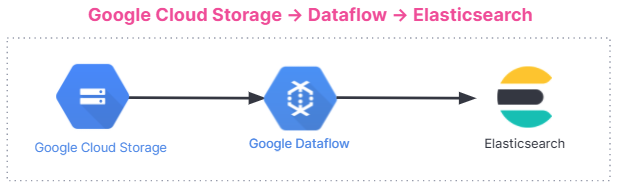
使い始める
GCS からのインジェスト機能を理解する最適な方法は、事例のデモンストレーションを見ることです。ここからは事例として、アメリカ地質調査所から取得した地震データを分析してみます。アメリカ地質調査所はリアルタイムの地震情報と震度統計データを提供しています。先月、アメリカ地質調査所がマグニチュード2.5以上を観測した地震のCSVファイルを使用します。このファイルの冒頭5行は次のようになっています。どのようなデータなのか、おおよそのイメージを掴めると思います。

Google Cloud Console の[Dataflow]ページで、[GCS to Elasticsearch template](GCS-Elasticsearchテンプレート)を選択します。このテンプレートは、次のいずれかを使用してJSONドキュメント向けのスキーマを作成します。
- Javascript UDF (該当する場合)
- JSON schema(該当する場合)
- CSV ヘッダー*(デフォルト)
UDF または JSON スキーマのいずれかに該当する場合は、CSV ヘッダーに代わってそれを使用します。

フォームの最初のフィールドに、GCS 内のファイルの場所を示すパラメーターを入力します。 Cloud ID は、下の画像に示すように Elastic Cloud UI で見つけることができます。API Key は、Create API key API を使って作成することができます。
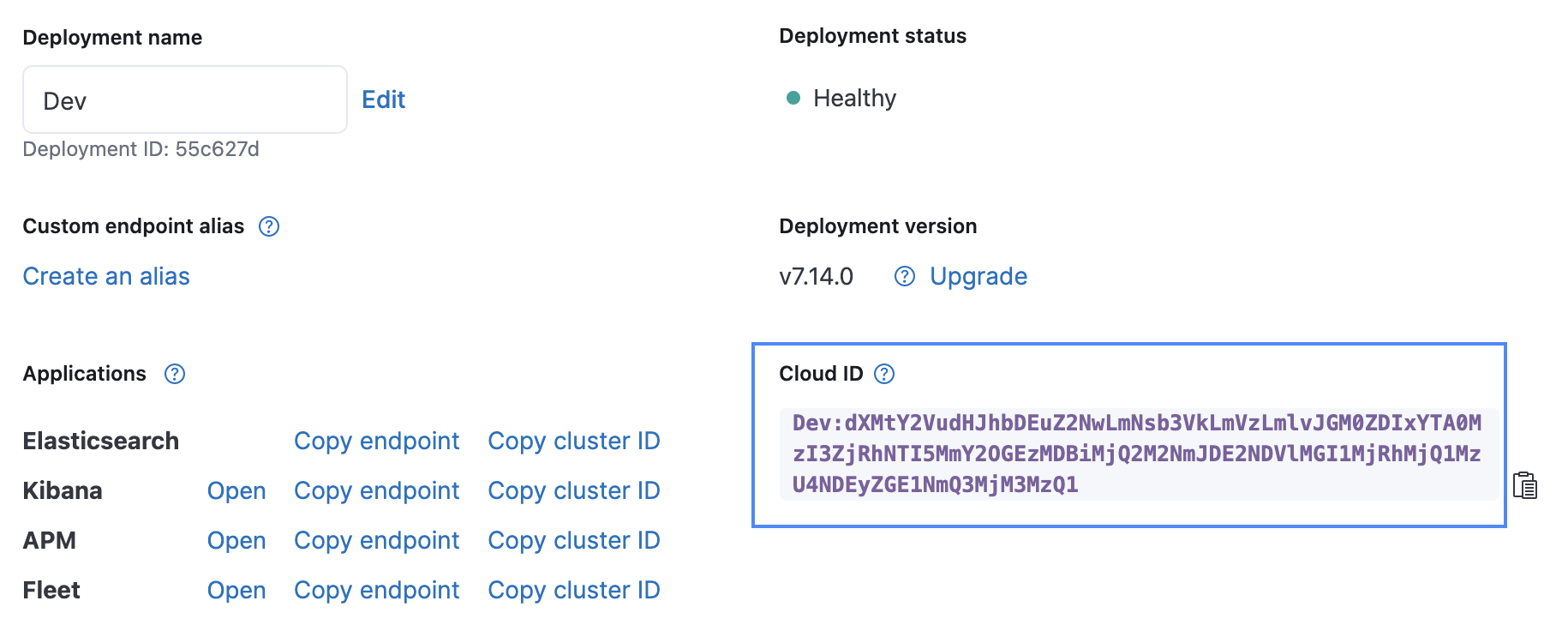
[Elasticsearch index] に、データの読み込み先となるインデックス名を指定します。この例では [quakes] インデックスを使用しています。
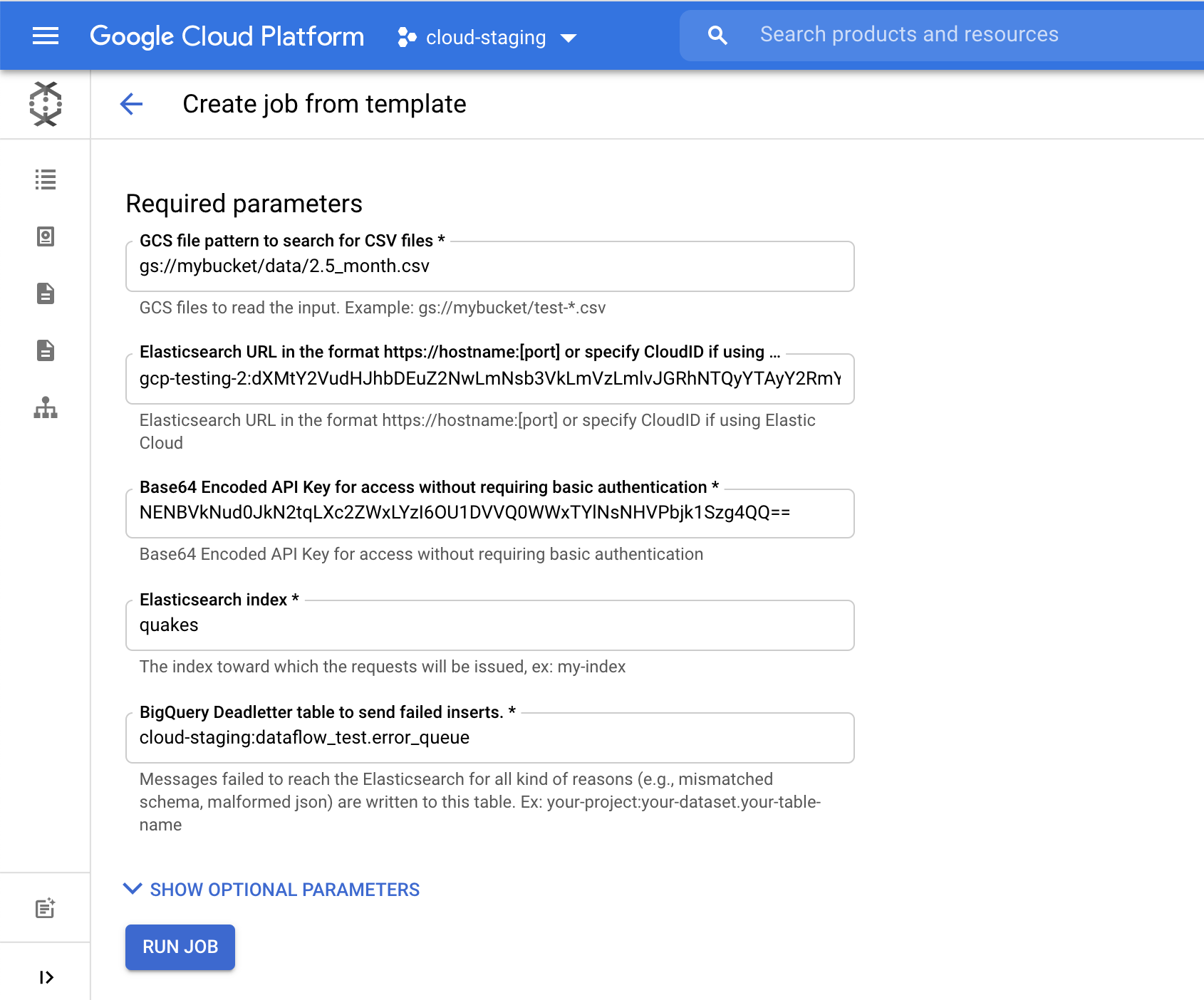
[Run Job](ジョブを実行)をクリックすると、GCS から Elasticsearch へ地震データのインジェストが始まります。Google Cloud Console しか操作していないところがポイントです。
ここまで来たら Kibana を開き、数分程度でインデックスパターンを作成し、可視化を始めることができます。
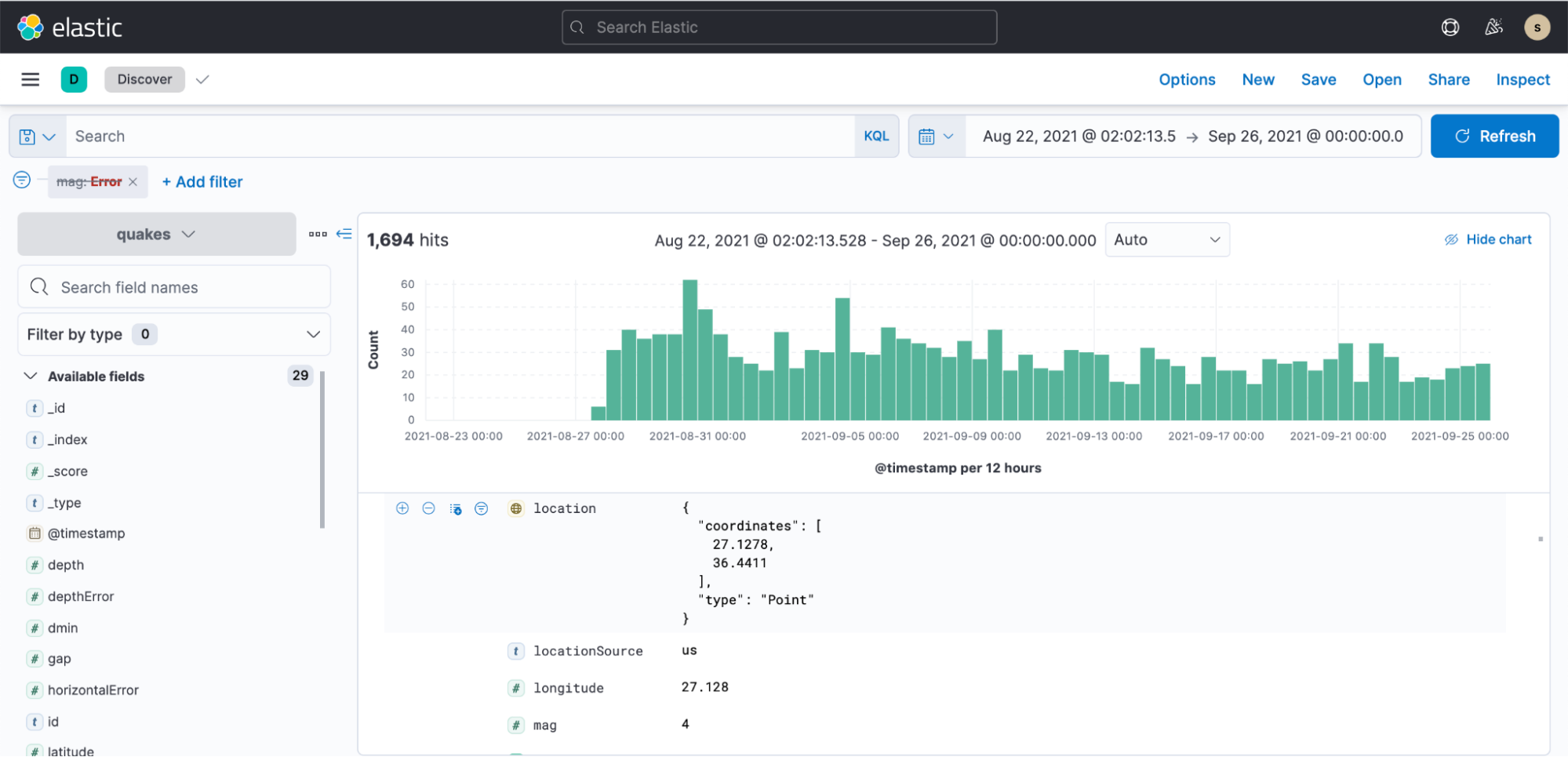
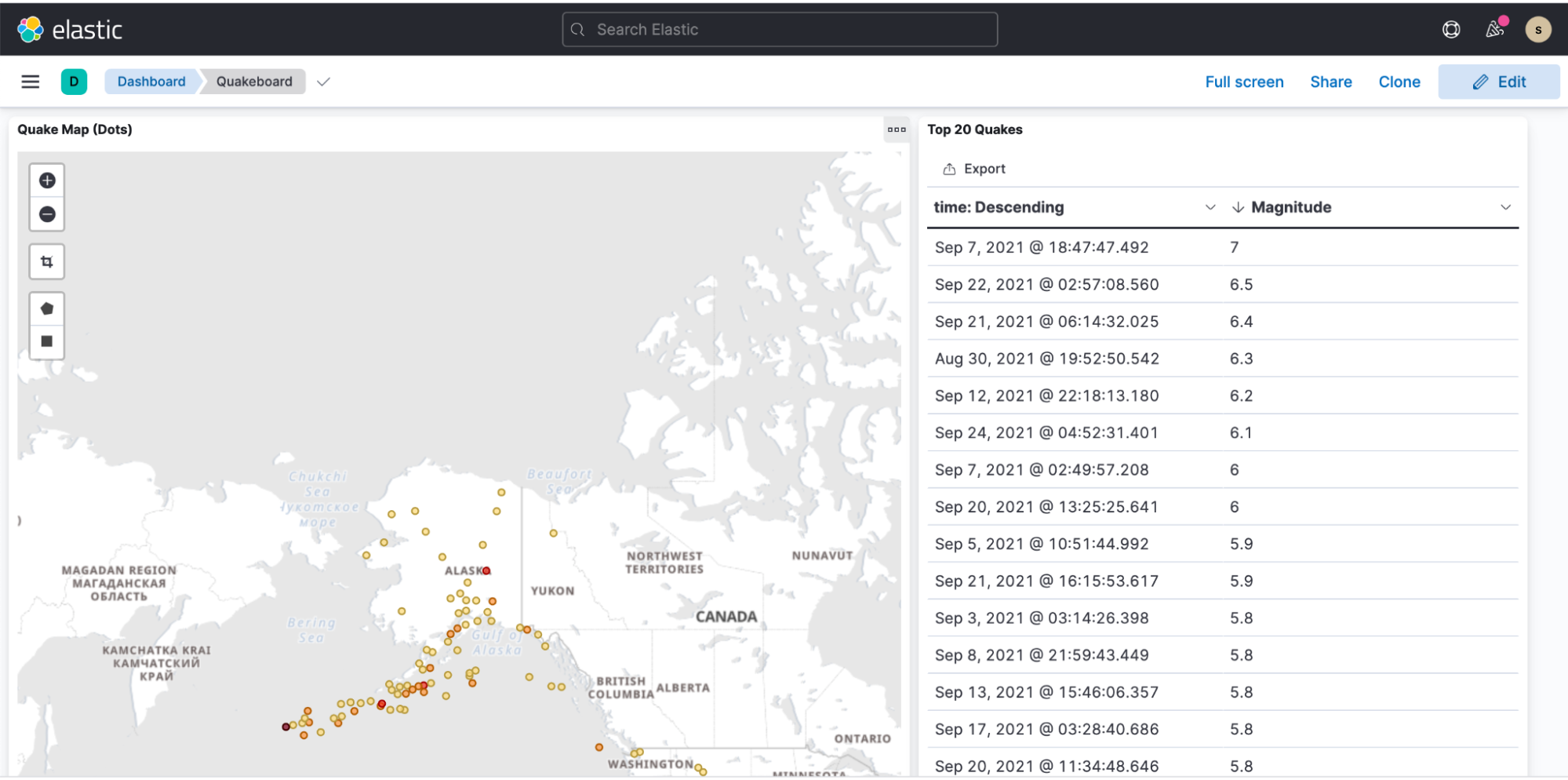
地震データのプレゼンテーションを表示したサンプルダッシュボード
Google Dataflow を使って、Google Pub/Sub から Elastic に直接データをインジェストする可能
Pub/Sub は人気のサーバーレス非同期メッセージングサービスで、Google Operations(旧Stackdriver)や Google Cloud のサービスを用いて開発されたアプリ、またストリーミングデータ統合パイプラインを活用するその他のユースケースからのデータストリーミングなどに使われています。Elastic は統合機能の提供を通じて、Google Cloud Audit ログや VPC Flow ログ、ファイアウォールのログをはじめとする各種のイベントとログを Elastic Stack に直接ストリーミングする手順を一層簡単にしました。この統合機能は DataFlow テンプレートを活用して動作し、ソフトウェアや設定を追加する必要はありません。
開発者やSREs(Site Reliability Engineers)、セキュリティアナリストなどのユーザーは Google Cloud Console で数回クリックするだけの操作で、Google Pub/Sub のデータを Elastic Stack にインジェストできるようになりました。具体的には、Google Cloud Audit、VPC Flow、ファイアウォールなどの Google Cloud サービスからくるイベントとログを、Google Dataflow テンプレートを活用して Elastic Stack に簡単にストリーミングすることが可能になっています。このテンプレートはデータパイプラインアーキテクチャーをシンプル化するほか、運用上の手間を省き、トラブルシューティングの所要時間を短縮できるといったメリットをユーザーにもたらします。
アプリの開発やインフラの立ち上げに Google Cloud を使用し、トラブルシューティングや監視、セキュリティに関する異常の特定には Elastic Stack を使用するという開発者や SRE、セキュリティアナリストは少なくありません。Google と Elastic は、Google Cloud サービスのアプリやインフラから Elastic にログやイベントをインジェストする、ストレスフリーで使いやすい手法を提供するために協働してきました。その結果、データシッパーを一切インストールすることなく、Google Cloud Console を数回クリックするだけでこうしたインジェストを行うことが可能になりました。
本ブログ記事では、Google Dataflow を使って、エージェントを経由せずに Google Pub/Sub から Elastic Stack にデータをインジェストする方法をご紹介します。
余分な手間を省く
Pub/Sub は、Google Operations(旧Stackdriver) や Google Cloud のサービスを用いて開発されたアプリ、またストリーミングデータ統合パイプラインを活用するその他のユースケースからのデータストリーミングに使われる、人気のサーバーレス非同期メッセージングサービスです。Google Cloud Audit や VPC Flow、ファイアウォールのログをサードパーティの分析ソリューション(例:Elastic Stack)にインジェストする場合、はじめに Google Operations にログをシッピングし、その後 Pub/Sub に送る必要があります。 ログが Pub/Sub に送信された後、Google Pub/Sub に格納されたメッセージをサードパーティーの分析ソリューションにシッピングする際のインジェストメソッドは、Google Cloud ユーザーが決定しなくてはなりません。
Google と Elastic を併用するユーザーに人気のオプションとしては、Google Compute Engine VM に Filebeat、Elastic Agent、または Fluentd のいずれかをインストールし、そのデータシッパーを使って Pub/Sub から Elastic Stack にデータを送信するという方法があります。しかしこの方法では、VM のプロビジョニングやデータシッパーのインストールに伴ってプロセスや管理の手間が生じます。この手順を省き、Pub/Sub から Elastic に直接データをインジェストする仕様は多くのユーザーに役立ちます。Google Cloud Console を数回クリックするだけで完了するとなれば、なおさらです。この新しい方法は現在、Google Dataflow のドロップダウンメニューから実行することが可能になっています。
データインジェストを最適化する
Google Dataflow は、Apache Beam をベースとするサーバーレス非同期メッセージングサービスです。Google Dataflow をFilebeat に代えて使うと、Google Cloud Console からログを直接シッピングすることができます。そこで Google と Elastic のチームは、Pub/Sub から Elastic にログとイベントをプッシュする、設定不要の Dataflow テンプレートを共同開発しました。このテンプレートは、従来 Filebeat が担っていたデータ形式変換などの軽負荷な処理をサーバーレスな手法で実行します。ユーザーは Filebeat をこのテンプレートに置換するにあたり、既存の Elasticsearch インジェストパイプラインに変更を加える必要はありません。
以下に、データインジェストのフローを示します。このインジェストフローは、Elastic Cloud の Elastic Stack から、Google Cloud Marketplace の Elastic Cloud、セルフマネージド環境まで、すべてのユーザーに共通です。
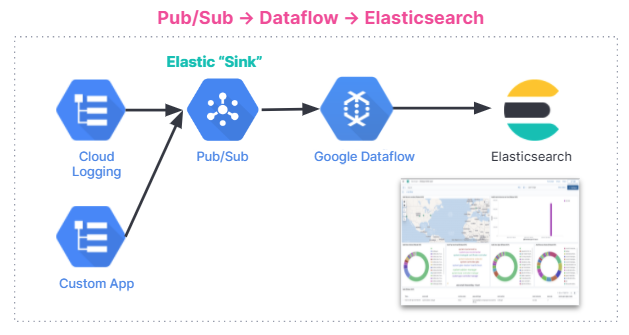
使い始める
このセクションでは、Dataflow を使って、Elastic Stack で GCP Audit Logs の分析を始める方法をステップバイステップのチュートリアルで説明します。
監査ログには、ユーザーの Google Cloud アカウントに生じた運用上の変更について、「どこで、どのように、いつ」を問う質問の回答を導くために役立つ情報が含まれます。Pub/Sub テンプレートを使うと、わずか数秒で GCP から Elasticsearch に監査ログをストリーミングし、インサイトを収集することができます。
はじめに Kibana の Web UI から Elastic GCP 統合機能をそのままインストールします。この統合機能には、事前構築済みダッシュボードやインジェストノード設定、インジェストする監査ログを最大活用する上で役立つその他のアセットも搭載されています。
Dataflow テンプレートの設定に入る前に、Google Cloud Console で Pub/Sub のトピックとサブスクリプションを作成する必要があります。Google Cloud Console には、Google Operations Suite からログを送信することが可能です。
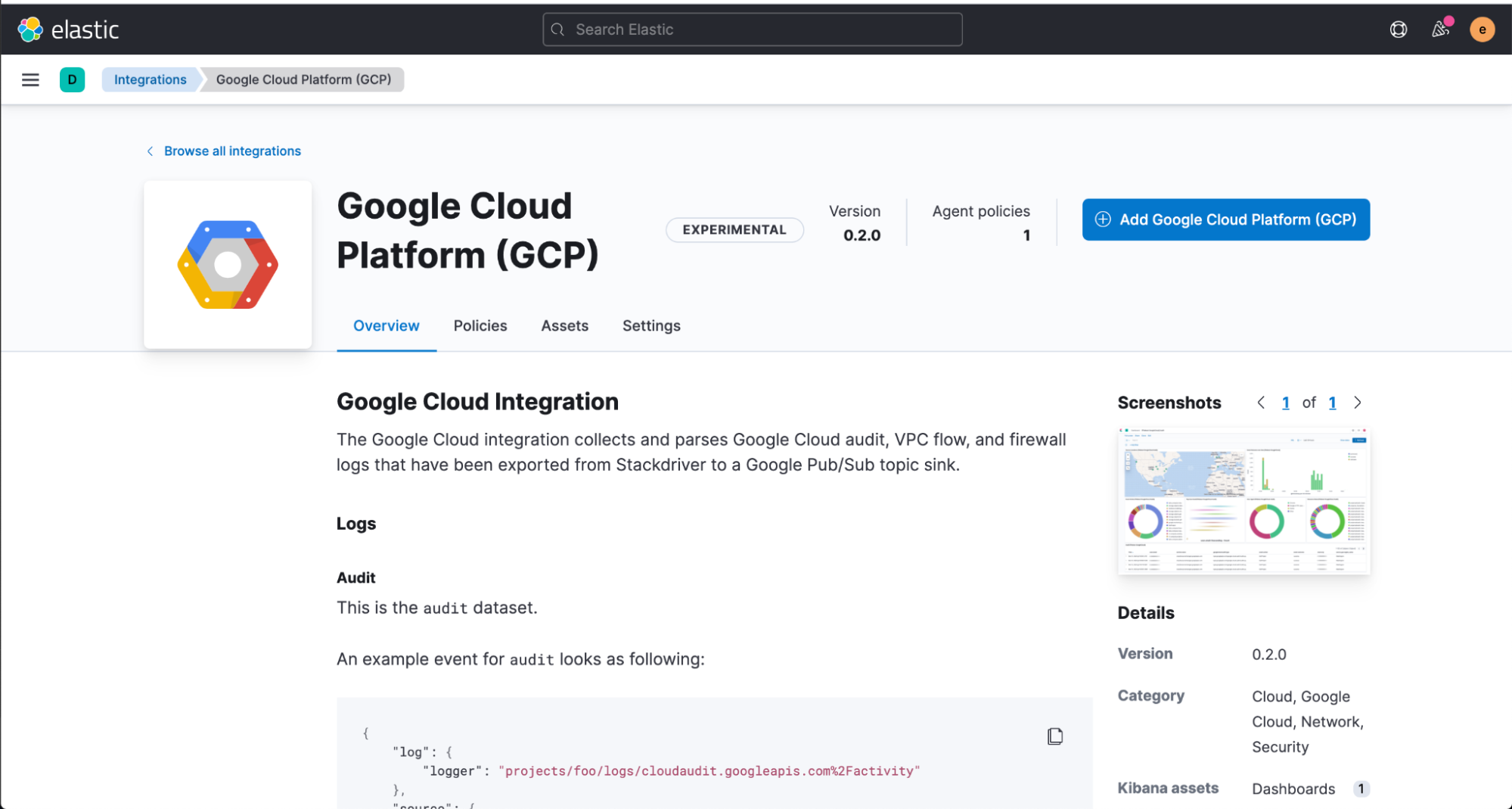
次に Google Cloud Console へ移動し、Dataflow ジョブを設定します。
Dataflow プロダクト内で [Create job from template](テンプレートからジョブを作成する)をクリックした後、Dataflow テンプレートドロップダウンメニューで[Pub/Sub to Elasticsearch](ElasticsearchへのPub/Sub)を指定します。
Elasticsearch の Cloud ID や Base64-encoded API Key を含む、必要なパラメーターを入力します。このチュートリアルでは監査ログをストリーミングするので、ログタイプのパラメーターとして[audit]を追加します。Cloud ID は、下の画像に示すように Elastic Cloud UI で見つけることができます。API Key は、Create API key APIを使って作成することができます。
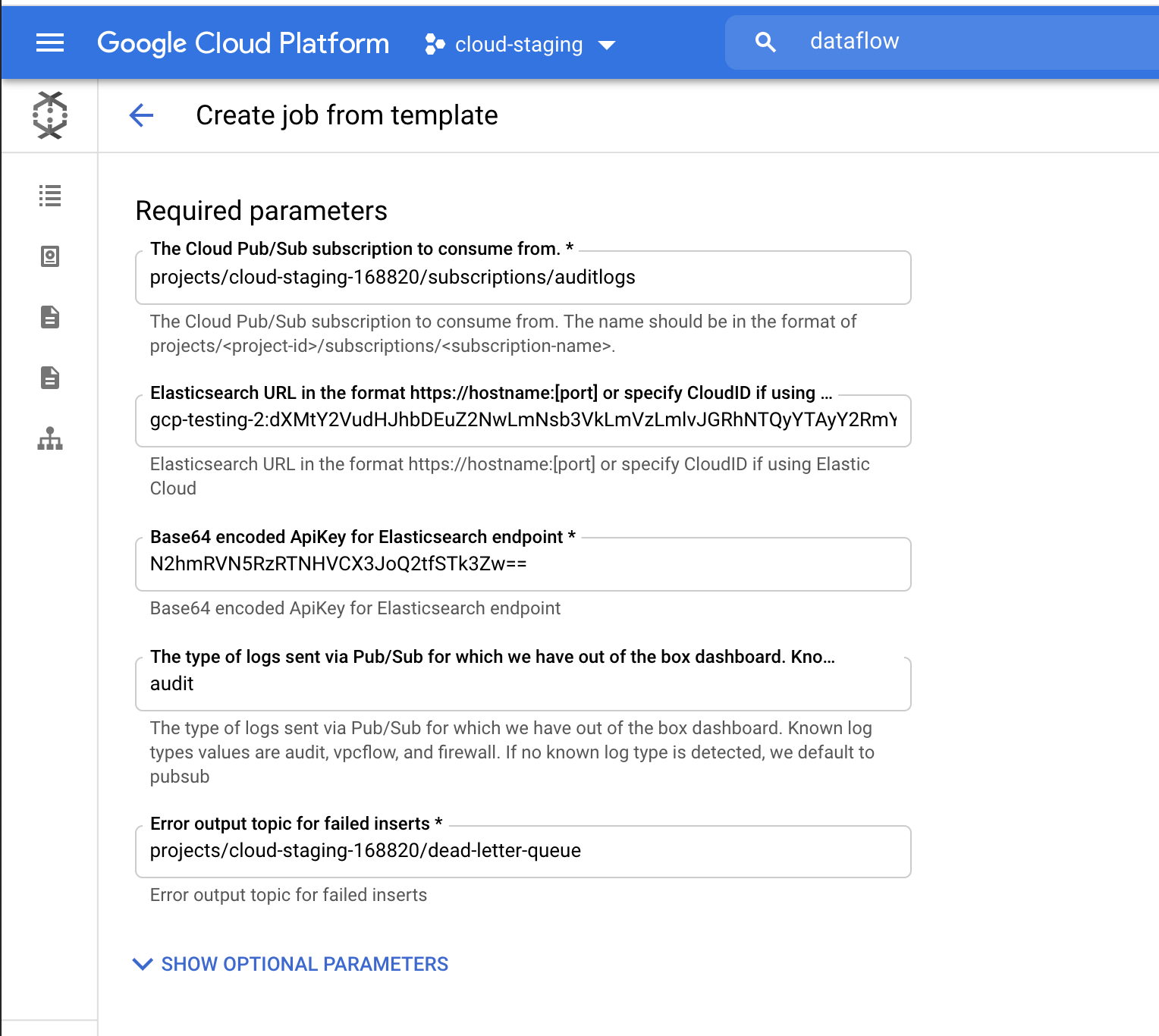
[Run Job] (ジョブを実行する)をクリックして、Dataflow がテンプレートの実行を完了するまで待機します。数分程度かかります。お気づきのように、この手順は Google Cloud Console の外部に移動せずに進めることができ、エージェントを管理したりする必要はありません。
最後に、Kibana を開いてパースしたログと、[Logs GCP]ダッシュボードの可視化を確認します。
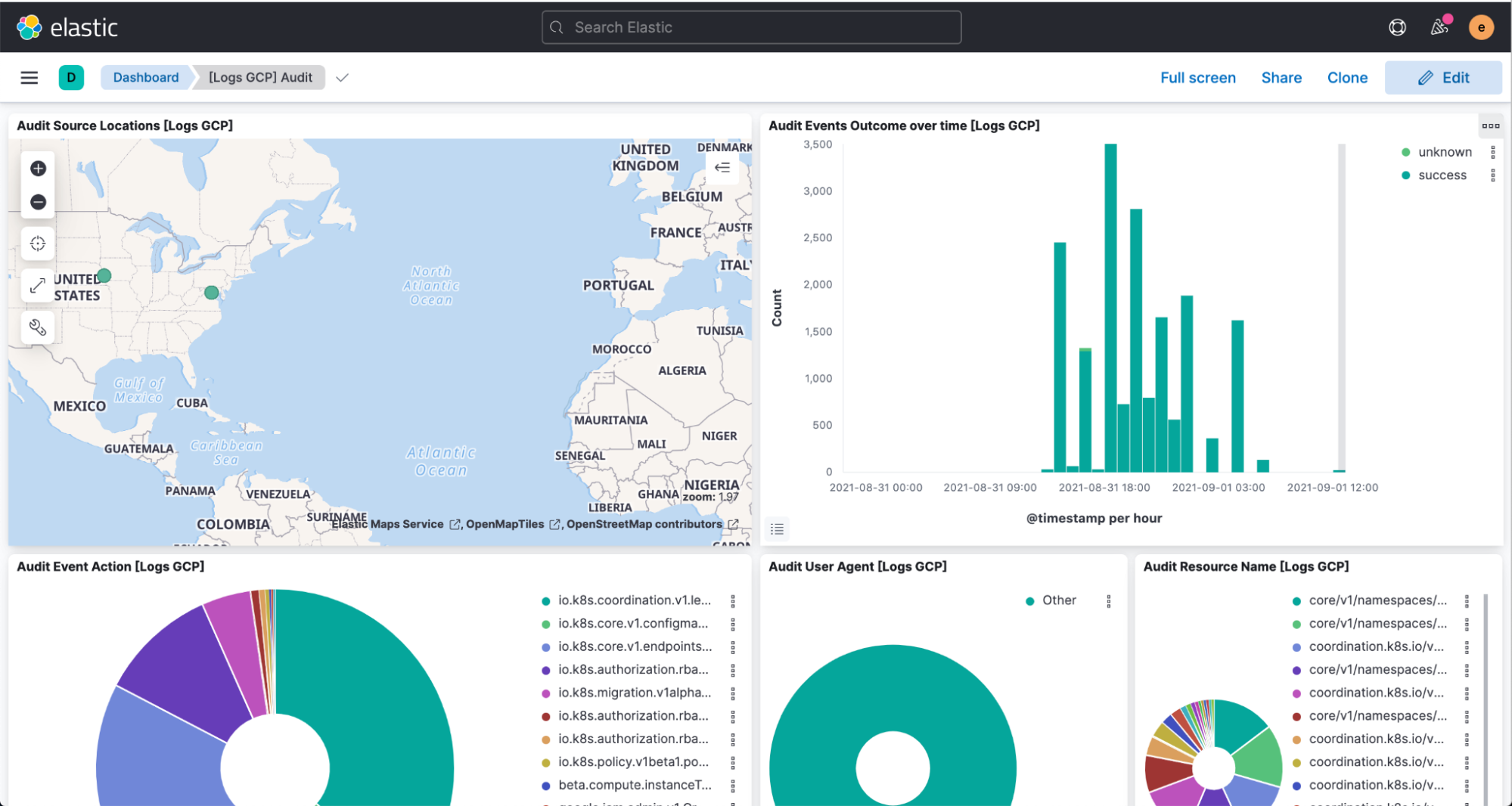
まとめ
Elastic はユーザーが望む場所で、ユーザーが望むメソッドで、より簡単かつストレスフリーにプロダクトを実行できるよう継続的な開発を進めています。この Google Cloud とのスムーズな統合機能は、その最新の事例です。Elastic Cloud は Elastic Stack のバリューを拡張し、ユーザーがより多くのことを、より高速に実行できるよう支援します。Elastic Cloud は、Elastic のプラットフォームから優れたエクスペリエンスを引き出す最高の方法です。この統合機能について詳しくは、Google が公開しているドキュメントをご確認ください。Google Cloud Marketplace または、https://www.elastic.co/jp にアクセスして、Elastic を Google Cloud で使い始めることができます。
告知
- 本日8日は、下記2つ、ハンズオンと Elastic Meetup があります。ぜひご参加ください!
Elastic オブザーバビリティワークショップ
Elastic Meetup

- 来週15日は、AWS さんとの初めてのダブルロゴでの共同 Webinar です。こちらもぜひご参加ください!
Elastic Observability で AWS 環境の健全性とパフォーマンスを監視する - Search. Observe. Protect.

- Firestore 連携の箇所でご紹介した通り、12/22 開催のJagu'e'r Cloud Native #3 みんなで語り合おう!クラウドネイティブLT祭りで、「Firebase/Firestore 拡張機能 による Elastic App Search 連携について」というタイトルで、実際にこの部分を、デモを交えて5分でご紹介予定です。Jagu'e'r 会員企業の方は、ぜひご登録・ご参加ください!
以上です。よろしくお願いします!
鈴木 章太郎
Elastic テクニカルプロダクトマーケティングマネージャー/エバンジェリスト