概要

皆様、こんにちは!
この記事では、Elastic のユニバーサルプロファイラとセキュリティソリューション が使用している eBPF という非常に興味深いテクノロジーの表面に触れ、なぜそれが現代の観測可能性にとって決定的に重要なテクノロジーであるかを説明したいと思います。
eBPF の仕組みと、それを使って強力な監視ソリューションを作る方法、そして将来的にeBPFが観測可能なユースケースに使われる可能性があることについて、少しお話しします。
eBPF とは何ですか?
eBPF または Extended Berkeley Packer Filter は、かなり面白い名前ですが、この技術が何をするものなのかをユーザーが概念化できるような形では説明されていません。この名前の理由は、この技術の本来の目的がネットワークであり、非常に複雑なファイアウォールルールを動的に適用するために使用されていたためです。
しかし、現在では、この技術は他の多くのことに利用することができ、セキュリティや観測可能な領域において幅広く適用することができます。
eBPF は、OS のカーネル空間で、カーネルのソースコードの変更や追加モジュールのコンパイルなしに、プログラムを実行できるようにする技術であり、その中核をなすものです。
関連記事:顧客からカーネルまで、クラウドネイティブな観測性を実現
観測可能性において eBPF が重要な理由
私は顧客として、また様々なテクノロジーベンダーで働きながら、長年 APM の領域に携わってきましたが、従来から行われてきたインストルメンテーションの方法は、かなり侵襲的なものでした。手動でインスツルメンテーションを追加していない場合、APM はコードに自分自身を挿入し、再コンパイルされます。このような導入は、本番環境を停止させるあらゆる種類の問題を引き起こす可能性があります。
私は APM の強力な支持者であり、問題の可能性は APM がもたらす価値よりはるかに低いものです。
カーネルで実行するために BPF コードを書くと、まず Clang を使って BPF の「バイトコード」にコンパイルされ、次にバイトコードが実行しても安全かどうかが検証されます。これらの厳しい検証により、機械コードが意図的または偶然に Linux カーネルを危険にさらすことはなく、BPF プローブがトリガーされるたびに、決められた数の命令を実行することが保証されます。
従来のインスツルメンテーションのもう一つの問題は、データを取得し、そのデータを処理する必要がある頻度が高いため、一般的にリソースを消費し、大きなオーバーヘッドになる可能性があることです。eBPF はカーネル内で直接実行できるため、データにアグリゲーションを適用し、ユーザーレベルにはサマリーを渡すだけで、ユーザースペースのソリューションで発生するオーバーヘッドを大幅に削減することが可能です。
BPF コンパイラコレクション(BCC)を使って裏側を見る
ボンネットの下を見始めるのによい場所は、ここにリストアップされている BCC ツールです。これらのツールについて私が気に入っているのは、以下に示すように、eBPF プログラムをカーネルにブートストラップするために必要なコードの多くを抽象化して、Python コードから簡単にアクセスできるようにしている点です。
手始めに、これを見てみましょう。これが eBPF の Hello world です。
from bcc import BPF
prog = ‘int kprobe__sys_clone(void *ctx) {
bpf_trace_printk("Hello, World!\\n");
return 0;
};’
BPF(text=prog).trace_print()
このプログラムが行うことは、ターミナルから作成されるそれぞれの新しい子プロセスに対して "hello world !" を表示することです。これは、マニュアルページにあるように "sys_clone" のフックを持っているからです。
このコードを Python ファイルに突っ込めば、(最初に BCC ツールをインストールしたと仮定して) 実行できるはずです。そして別のターミナルでいくつかのコマンドを書き始め、プロセスを起動するたびに "Hello World" が表示されるのを見ることができます。本当に簡単です。
このプログラムには4つの興味深い点があります。
- text='...': 単純なテキストを使った BPF プログラムを定義する。このプログラムはCで書かれている。
- kprobe__sys_clone(): kprobe によるカーネルダイナミックトレースのショートカットです。C の関数が kprobe__ で始まっていれば、残りはフックするカーネル関数名として扱われ、この場合は sys_clone() となります。
- bpf_trace_printk(): 共通の trace_pipe (/sys/kernel/debug/tracing/trace_pipe) への printf() のためのシンプルなカーネル機能です。
- trace_print(): trace_pipe を読み込み、その出力を表示する bcc ルーチンです。
もう一つの例を見てみましょう。観測の目的にはもう少し便利なもので、ここでは http サーバーの呼び出しをトレースしています。。
見てわかるように、これにはあまり多くのことはありませんが、非常に強力です。Node JS の http リクエストをインターセプトして、リクエストメソッドに渡される特定のパラメータを見ることができます。
このリポジトリにある他のBCCツール(下図)をチェックして、あなたが経験する厄介な問題、特に従来のツールではまだ解決できなかった問題に役立つ方法をすべて見てみる価値があります。私は、近い将来、これらのツールが私たちのお気に入りの観測可能性ソリューションに統合されることを信じています。
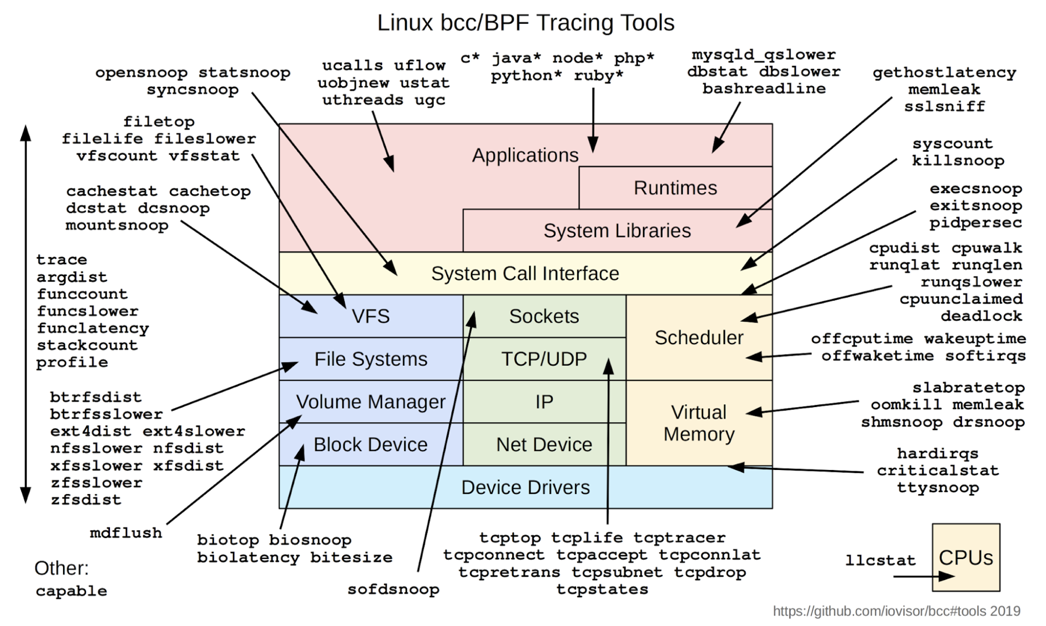
Elastic で、BCC ツールを使って eBPF でできることは、以下の通りです。
• ディスク IO レイテンシのデバッグ
• 遅い XFS ファイル操作のトレース
• XFS 操作のレイテンシを要約する
• カーネル関数コールをトレースし、md_flush_request の問題を発見し、ディスク書き込みのスローダウンを軽減する。
eBPF の技術はどこへ向かうのか?
ご覧のように、カーネルにフックをかけて、ネットワークや低レベルのサブシステムから、その上で動作するアプリケーションまで、システムで起きていることを簡単に調べ始めることができるのです。
さて、eBPF にはいくつかの制限があります。eBPF のコードを実行する仮想マシンは、コード内の変数に読み取り専用でアクセスすることができます。eBPF では APM のようにコードにタグやトレース ID を動的に追加することは現実的にはできません。技術的には可能ですが、メモリにパッチを当てることになり、安全ではありませんし、潜在的に高いオーバーヘッドを持つことになります。したがって、トレース情報、ログ、メトリックデータをコードに追加する必要があることを考えると、それらの問題が解決されるまでは、APM エージェントと OpenTelemetry は現在も存在することになります。
ここで起こるかもしれないと思うのは、従来の APM の責任の一部、特に収集の部分が eBPF ベースのエージェントに移っていくことです。トレース ID やメトリックを読み込んでコンテキストを生成したり、すべてのデータを結びつけたりする部分は、パフォーマンスの利点や要約のスピード、そしてより多くの基本システムにアクセスできることから、eBPF ベースのエージェントに移行する可能性があるのです。
同時に、eBPF はより深く、より興味深い情報、ネットワークデータ、セキュリティデータ、Kubernetes に関するデータ、その他従来 APM の手の届かなかったシステムサービスを収集するために使用することができるでしょう。
今後、eBPF についてもっと多くの情報が得られるようになることを期待します。Elasticのような観測可能なソリューションの大部分は、ますますこの技術を隠蔽して使用するようになるでしょう。もしかしたら、eBPFのプログラムに機械学習モデルを組み込んで、最も重要なデータや問題を特定し、これまでよりもずっと早く問題を知らせてくれるようになるかもしれません。eBPF は、現代の観測可能性とこれから登場するユースケースにおいて、重要な未来を担っています。
元ブログ
Elastic テクニカルプロダクトマーケティングマネージャー/エバンジェリスト
鈴木章太郎