Why 天気予報?
Global Mobility Service株式会社でCTOをしている@shorei-oです。
GMSはIoTデバイスとFintechを組み合わせたオートローンサービスを日本、インドネシア、カンボジア、インドネシアで提供しており、データ分析は関連する基盤構築や人材育成を含め、社内で非常に重要性の高い分野の一つです。
私自身、データ分析をテーマにお話する機会が度々あり、そうした際、そもそもデータ分析とは何なのか? なんのために取り組むのか? といったことを説明する必要に迫られました。
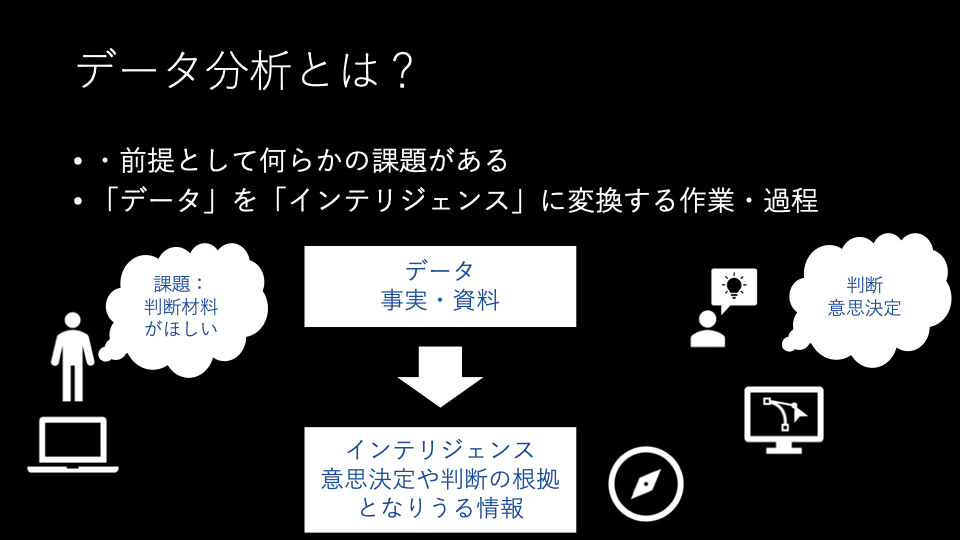
そういった際に、例としてよく取り上げていたのが天気予報です。
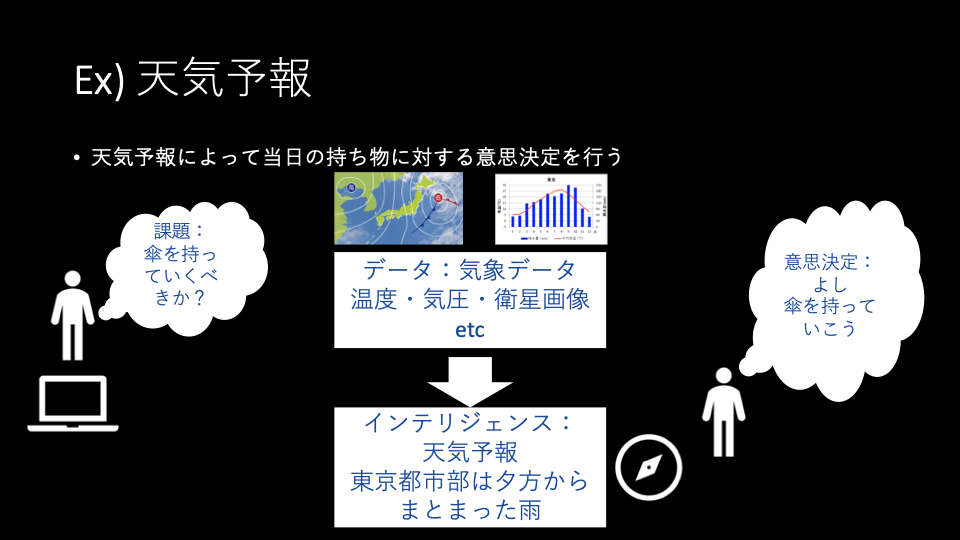
天気予報の課題は明確で、天気を予測することの重要性に疑問の余地はありません。
そこで天気予報のプロセスについてデータ分析の視点から調べてみました。
※本文章は参考情報をベースに書いてますが、記述の誤りについては筆者の理解不足によるものであることをお断りしておきます。
天気予報のプロセス
数値予報
数値予報とは、大気の状態を風向・風速、気温、気圧、湿度の4数値で表し、その変化を物理法則に基づいて計算することで、大気の将来の状態を予測することです。
観測データ収集
そのため、まず世界気象機関(WMO)の全球通信システム(GTS)やインターネット、国内通信網を通じ、地上気象観測、高層気象観測(気球)、海上気象観測(ブイ)、衛星観測、飛行観測などの手法で計測されたデータを収集します。数値予報はタイムリーに実施する必要があるため、日本付近を予測するためのメソ解析では観測時刻の50分後、地球全体を予測する全球解析では2時間50分後にデータ受信が打ち切られます。
客観解析
こうしたデータの多くはコード化された電文形式のため、デコードされた後明らかに誤りと思われるデータはスクリーニングされます。
また、観測データは地球上を均一にカバーしているわけではないため、観測データには空白域が存在します。時間的・空間的に不規則な分布をしている観測データから、格子点と呼ばれる水平方向、鉛直方向に規則的に分布した空間内の座標点での解析値を求めることを客観解析と呼びます。
ある気象を客観解析するために、ある時点での天気図が出発点となります(第一推定値)。これは直近の数値予報の結果を用いられていることが多いようです。その後、個々の観測データと数値予報の各格子点での値の偏差を求め、その偏差の分布状況から一番もっともらしいと推定される解析地を書く格子点について決定します。(雰囲気をつかめればヨシ、と思って書いてます)
客観解析ではこうした予報と解析のサイクルが繰り返されます。
アンサンブル予報
とはいえ、観測データには計測、伝送時の誤りや観測地点の偏りが含まれる可能性、解析上の誤り、加えて大気現象は時間・空間にまたがる非線形複雑系であることから客観解析による精度向上は限界があります。そこでアンサンブル予報と呼ばれる手法が用いられます。
アンサンブル予報では、50個程度の観測誤差レベルのばらつきをもった出発点(メンバーと呼ぶ)に対し数値予報モデルを適用した予測を行い、それらを平均した予報ということのようです。
ここで使われる数値予報モデルいくつもの種類があり、対処となるスケールにより使い分けられます。
代表的なモデルは以下の3つです。
寒波、高低気圧、台風といった大規模で寿命の長い大気現象の予測に用いられるのが全球数値予報モデル(Global Spectral Model:GSM)で、格子点の間隔は約20kmに相当します。ちなみに数値予報モデルが精度良く予測できる現象は、格子点間隔の5〜8倍以上だそうで、GSMは水平スケールが100km以上の現象に適応することになります。
一方地形の効果が大きくなる局地的な大雨や強風などはスケールが数十km程度であることが多いため、格子点間隔が5km程度のメソスケール数値モデル(Meso-Scale Model:MSM)が適用されます。
更に局地的な積乱雲や雷雨の予測には格子点が2kmの局地数値予報モデル(Local Forecast Model:LFM)が適用されます。
天気翻訳
天気翻訳とは
数値予報の予測結果は各格子点の数値なので、そのまま天気予報になるわけでは有りません。
(各格子点の数値は独立な評価だけでなく、周囲の格子点との整合性も考慮はされるようです)
それらの物理量がそのまま晴れ、曇り、雨といった天気を表すわけではないし、数値モデルにも実際に局地的な気象に大きな影響を与える地形や小さなスケールの現象の盛り込みの限界があるなどの理由によります。
そのため数値豫章の予測結果をもとに、各地の天気予報に置き換える天気翻訳と呼ばれる作業が行われ、その際に天気ガイダンスと呼ばれる資料が作成されます。ガイダンスはそのまま天気予報に利用できる形で表現されます。
ガイダンスの作成
現在ガイダンスの作成にメインで使われているのはMOS(Model Output Statistics)と呼ばれる手法で、数値予報モデルの出力値を統計処理し、それの予想値を、これまで実際に観測された天気要素の数値との統計的関係式に代入し、天気要素に翻訳するという工程で作成されます。
最終的には、実績値に基づいて天気予報を行うことになる点が非常に興味深く感じます。
予報精度
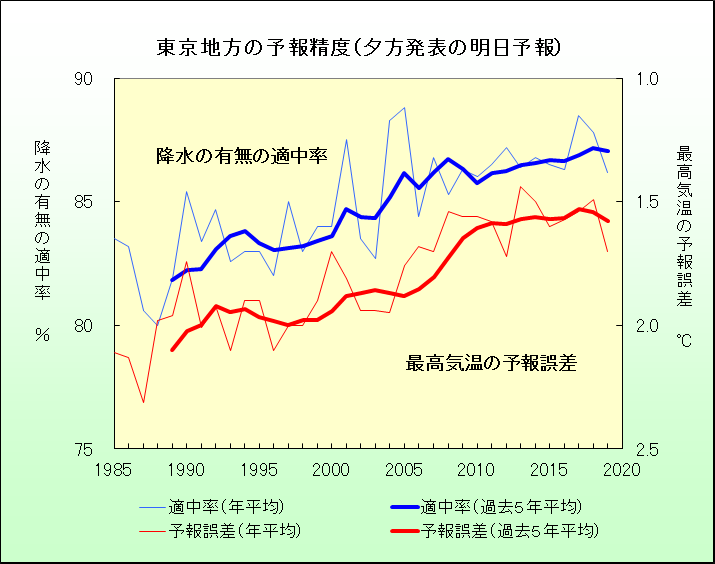
気象庁サイトから引用させていただきました、直近35年間の予報精度の推移だそうです。
天気予報はあたりはずれの判定が誰にでもできてしまいますが、特に最近は非常に頼りになる判断材料になっています。
ITを始めとする技術の進歩がめざましいとはいえ素晴らしい!
データ分析に携わる身としてはぜひ見習いたいものです。
最後に
天気予報について、気象学に関係する部分をすべてすっ飛ばし、データ分析作業のみに注目するという試みをやってみました。また、「気象」とは大気の諸現象を表し、同様に地震や火山活動など大地の諸現象を表す「地象」や陸水や海洋の諸現象を表す「水象」という言葉があることもこの度初めて知ることができました。
今回の記事の準備過程で、当然ながら精度を上げ、実用になる分析結果をデリバリーするための様々な工夫が凝らされていることがわかりました。結果のわかりやすさ、確実なデリバリー、精度向上への飽くなき取り組み、実際に社会に貢献する分析というのはこういうものなのだなぁ、という実感を新たにしました。ということでタイトルのデータ分析は「天気予報」を目指すに繋がります。
Last Christmas
Written by George Michael
Last Christmas, I gave you my heart
But the very next day you gave it away
This year, to save me from tears
I'll give it to someone special...
私が現職についたのは今年からで、去年のクリスマスにはもう退職の調整も済み、2020年にやりたいことをあれこれ考えて楽しくすごしていました。
ほとんどの人にそうだったように、まさかこんな年になろうとは思ってもおりませんでしたが、多くの方に支えられ、なんとか乗り切ることができました。
この記事を読んでいただいたすべての方に
Merry Christmas!
参考情報
「読んでスッキリ気象予報士試験合格テキスト」(ナツメ社)
気象庁HP https://www.data.jma.go.jp/