はじめに
日頃から意識しておきたいテクニックを簡単にまとめました( ^ω^)
実行環境編
# mac
# python 3.9.0
pyenv install 3.9.0 # 指定のpython versionをインストール
pyenv virtualenv 3.9.0 py3.9.0 # py3.9.0という仮想環境を構築
pyenv local py3.9.0 # カレントディレクトリ配下ではpy3.9.0の環境を利用する
パッケージ管理編
パッケージ管理は、再現性のある開発環境を作成するのに重要です!!
パッケージ管理には、poetryがおすすめです。
PoetryはPythonでの依存関係管理とパッケージングのためのツールです。 Poetryを使うとプロジェクトが依存しているライブラリを宣言でき、それらを管理 (インストールおよびアップデート) してくれます。
コレだけ覚えよう
pip install poetry==1.1.4 # 仮想環境にpoetryをインストール
poetry init # pyproject.tomlを生成
poetry add numpy=1.19.5 # ライブラリのインストール
poetry add black -D # 開発用ライブラリのインストール
poetry remove numpy # ライブラリの削除
poetry install # pyproject.tomlを元に、環境を再現する
👇 のようなファイルが生成され、自動的にパッケージ管理をしてくれます!!
pyproject.toml
[tool.poetry]
name = "3.9"
version = "0.1.0"
description = ""
authors = ["Your Name <you@example.com>"]
[tool.poetry.dependencies] # インストールしたライブラリが記述されます
python = "^3.9"
numpy = "1.19.5"
[tool.poetry.dev-dependencies] # 開発用のライブラリが記述されます
black = "^20.8b1"
[build-system]
requires = ["poetry-core>=1.0.0"]
build-backend = "poetry.core.masonry.api"
poetry.lock
依存環境が自動的に記載されます
コードフォーマッタ編
手軽に綺麗なコードが書ける環境を手に入れましょう!!
- linter:コードの書き方が良くない部分をチェックしてくれるもの
- コードフォーマッタ:コードを自動整形してくれるもの
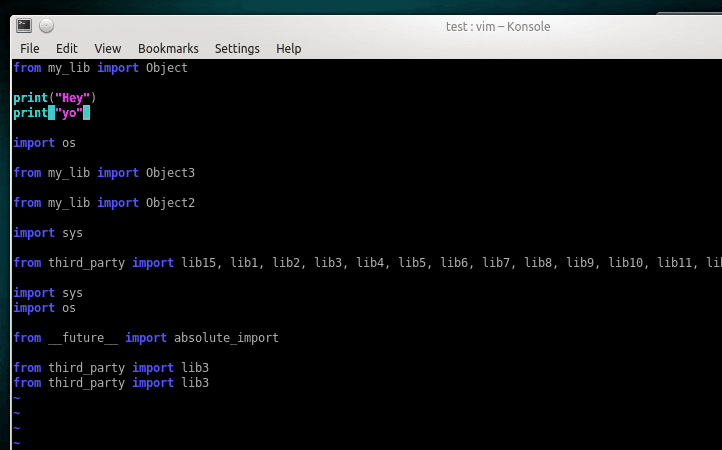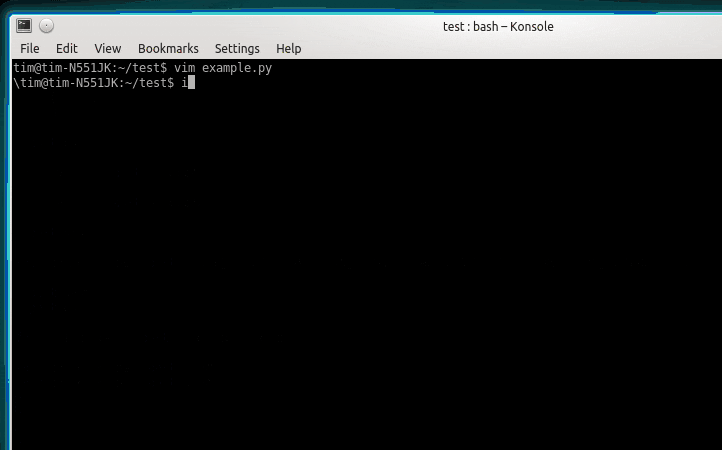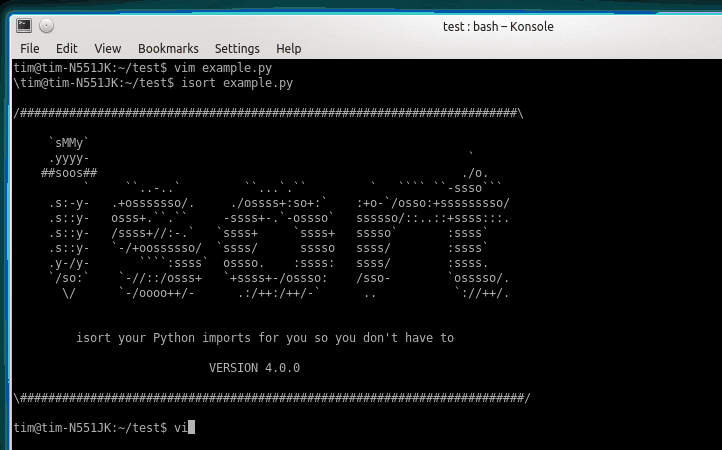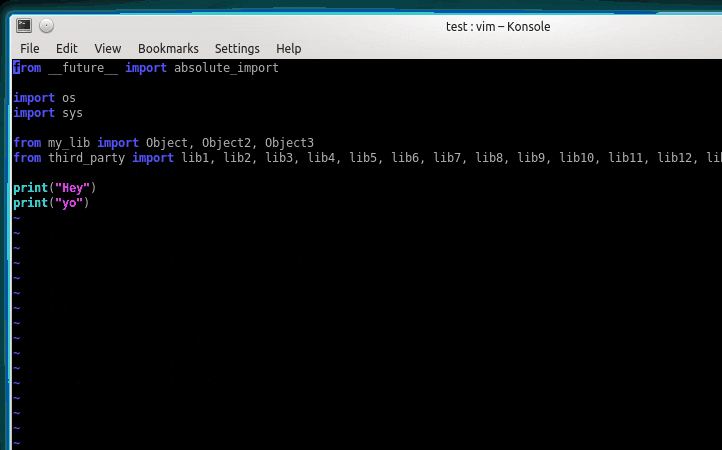
コレだけ覚えよう
poetry add flake8 mypy black isort -D
これらのツールで実際にコード整形を行ってみましょう。
bad.py
import numpy as np
import os
import sys
print(sys.path)
np.random.seed(seed=32)
apple: str = 'リンゴ'
apple = 100
コレだけ覚えよう
flake8 bad.py --max-line-length=120 # デフォルトでは、1行の文字数が80と短いので、オプションで変更
# bad.py:2:1: F401 'os' imported but unused ← os、使ってないよ
# bad.py:8:12: W292 no newline at end of file ← ファイルの最後に空行ないよ
mypy bad.py --ignore-missing-imports --check-untyped-defs --no-strict-optional
# bad.py:8: error: Incompatible types in assignment (expression has type "int", variable has type "str")
↑ str型の変数にintを挿入しようとしているよ
# mypyは個人的に鬱陶しいので、緩めの制限にするオプションをつけています
isort bad.py
# Fixing bad.py
black -l120 bad.py
# reformatted bad.py
# All done! ✨ 🍰 ✨
# 1 file reformatted.
good.py
import sys # isortで並び替え
# flake8が怒るので、osは手動で削除
import numpy as np
print(sys.path)
np.random.seed(seed=32)
apple: str = "リンゴ" # blackがダブルクォテーションに自動整形
apple = "100" # mypyが怒るので、文字型を代入するように変更
# blackが空行を自動挿入
ちなみに、Python 3.9からアノテーションが👇のように書けるようになったのですが、mypyがまだ対応できておらず、エラーになるようです…(追記. mypy:0.9以降で対応されたようです!!)
type.py
numbers: list[int] = [1, 2, 3]
mypy type.py
# type.py:1: error: "list" is not subscriptable, use "typing.List" instead
↑ 従来のtyping.Listを使ってね
命名規則編
プログラム高速化編
さくっとできる高速化はやっておきたいものです!! (Cythonレベルは置いておく)
コレだけ覚えよう
⭐️ループ処理: for文 (whileより高速)
⭐️算術演算 : numpy
左ほど高速でした(N=10000000)
np.sum(np.arange(N)) < sum(range(N)) < sum([i for i in range(N)]) < np.sum(range(N))
⭐️リストの初期化 : numpy
np.empty(N) < [0] * N < list(range(N)) < [0 for i in range(N)]
※初期値は自由とする
⭐️appendはできるだけ回避
# 偶数を抽出するロジック
good:X = [i for i in range(N) if i % 2 == 0]
bad: X = []
for i in range(N):
if i % 2 == 0:
X.append(i)
⭐️条件 in を使うときには、集合(set)と比較 (listより超高速)
nums = set(range(N)) ≃ nums = range(N) << nums = list(range(N))
X = [i for i in range(N) if i in nums]
⭐️基本、index指定が最強(key指定よりも)
配列 辞書
num_values[i] < num_dict[i]
※読みやすさとトレードオフ
⭐️pandasでも同様
df = pd.DataFrame(data=range(N), columns=["A"])
df_values = df["A"].values
[df_values[i] for i in range(N)] << [df.iat[i, 0] for i in range(N)], [df.at[i, "A"] for i in range(N)]
⭐️listはlist, numpyはnumpy 下手に混ぜると遅くなる
[num_lists[i] for i in range(N)] < [num_numpy[i] for i in range(N)]
※番外編
⭐️fileを開くなら with句
⭐️辞書にアクセスするなら.get (keyエラーが出そうな場合)
num_dict.get(i, DEFAULT)
- https://qiita.com/sotasato/items/cc36a532ba6487dd3dba
- https://python-guide-ja.readthedocs.io/en/latest/
おわりに
何かありましたら、コメント頂けると幸いです🙏