過去3ヶ月間のPythonプログラミング講座に励んだだけでしたが、会社の支援が得られることもありもっと学んでみたいという軽いノリで大学院に入学してしまいました。
仕事をしながら平日夜間と土曜日に授業をうけ、2年で卒業の予定です。
平日夜は1コマです。自身の復習とこの軌跡が文系から理系転向するような同様の経験をする人の参考になればと考えて記録をすることにしました。
記念すべき初日の授業は機械学習の授業でした。
内容:
・機械学習の歴史
・機械学習とは
・機械学習アルゴリズム紹介
各項目でのポイントをかいつまんで紹介します。
■機械学習の歴史
・前史として、多くの数理的学習法の基になっているベイズの定理の発見(1760年くらい)が重要なエピソードとして挙げられるようです
・以降統計的なデータ解析が行われるようになっていき、19世紀後半には統計学が確立されていきました
・戦後人間の脳の構造を模したニューラルネットワークの概念が流行り始めてブームとなりますが、1970年ごろまで続いたブームも当時の技術では単純な問題しか解くことができないという風潮となりブームが終わります(AIの冬)
・一方統計的手法は進歩を続け、計算機能力を背景に非線形な統計モデリングが本格化されていき現在でも使われるようなアルゴリズムが出てきました。また、さまざまな方法を組み合わせたアンサンブル法が発展していきます
・1980年ごろ、またニューラルネットワークのブームが起こりますが、また1990年ごろに終了します。
・そして2005年ころのディープラーニングの発見以降、現在に至るまでニューラルネットワークはAIにおける主役となっています。その背景として急増するデータや高度な処理が行える機器の出現によりより高度な活用が可能になったことがあげられます。※ChatGPTなど本当にすごい技術が出てきてますよね
■機械学習とは
最近よく使われるデータサイエンスや機械学習などの概念の整理として授業でも紹介されたDrew Conwayのベン図がわかりやすかったので紹介します

・赤:コンピュータサイエンス
・黄緑:数学・統計
・青緑:実践的専門知識
・機械学習は赤と黄緑が重なる部分
・データサイエンスは3点の重なる部分
※統計的なアプローチのない古典的なソフトウェアや、コンピュータを利用しないデータ分析の部分も面白いですね
機械学習は業務分野等の専門知識がなくともさまざまな分野・シーンで汎用的に活用できる技術で、データサイエンスはそこに専門知識を付け加えたものであると今日時点では理解をしました。※誤ってたらごめんなさい。また、先生の話では機械学習とデータサイエンスはここまで厳密に分かれているものでもないからおおおよそのイメージとして捉えれば良いとのことですが、大事なのは現在は統計的かつ技術を活用して専門分野において活躍できる人材に近づくために頑張ろうというところかと思います。
機械学習とは、コンピュータ上で経験(データ)を知識・問題解決能力に変換が可能なプログラムを作成することで、すでに学んだ問題(訓練データ)を解けることではなく、見たことのない新しい問題・データにも正しく推論を行える(汎化)ことが重要になるとのことです。
帰納推論するということですが、帰納は合理的正当化が不可能と言われているようです※日本のカラスは黒い、アメリカのカラスは黒い、中国のカラスも黒いから全てのカラスは黒いっていっても全部のカラスを確認してないから絶対に黒以外のカラスがいないとは言い切れない、たぶんそんな感じ。https://ja.wikipedia.org/wiki/%E5%B8%B0%E7%B4%8D
考えるモデル・学習法に何の偏向(バイアス)も持たせないということは汎化ができないということになります。人間の与える帰納バイアスによって普遍的なパターンの獲得や、未来への予測が可能になります。
つまり人間の仮説や仮定を持った方向性付けをなくして汎化したモデルはつくれないけれども、バイアスがかかりすぎると恣意的なモデルができてしまうのでバランスの取れるいいところを探しましょうということですね(その塩梅が難しいのでしょうね)
■機械学習アルゴリズムの紹介
最近傍法とK近傍法
・最近傍法
クラスAとBのデータが存在し、その中に未知データがある場合、そのデータに対し最も近いものと同じクラスであると予測
→ノイズデータに弱い
・K近傍法
クラスAとBのデータが存在し、その中に未知データがある場合、そのデータに対し周辺のK個のデータの多数決で予測
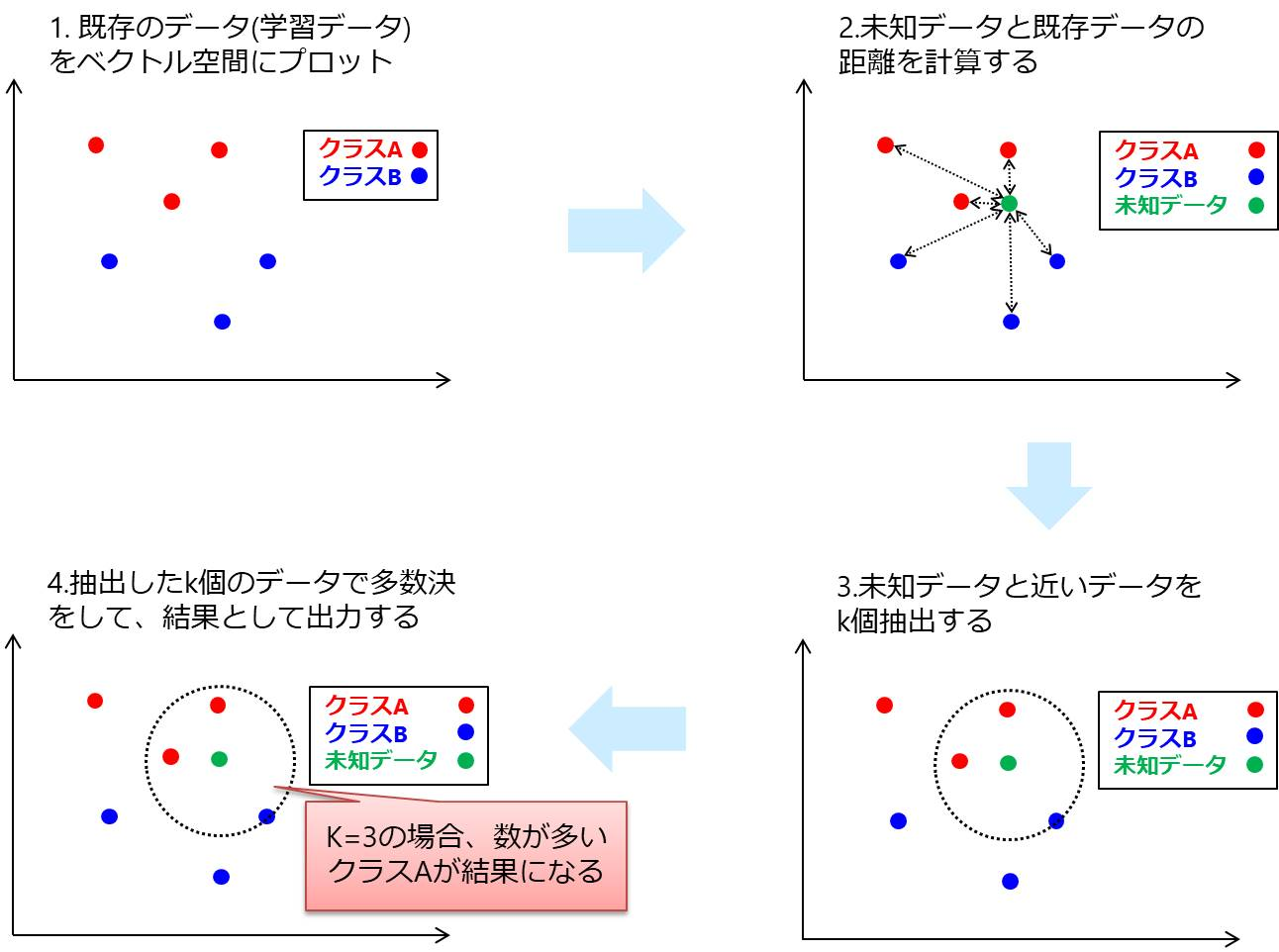
→Kの数が小さければ分散が小さく最近傍法同様ノイズの影響を受けやすい、Kの数が大きいと分散が小さくノイズの影響は受けにくいが、バイアスが大きくなってしまうのでバランスが大切(やはりその塩梅が難しいのでしょうね)
■その他
本日の学習時間
・予習:1.5H
・授業:1.5H
・復習:1.5H
計4.5H
いきなり難しくてつらいですが、頑張っていきます。