概要
こんにちは。衛星画像による土地被覆分類は、これまでに広く行われてきました。また、Sentinel-2衛星やLandsat衛星のデータは無料でアクセスが可能であり、データの入手性も高まっています。これらの衛星画像とPythonの機械学習ライブラリを組み合わせる事で、GUIベースのソフトウェアでは難しい高速かつ大量の土地被覆分類が可能になりますが、その方法については(僕の調べた範囲では)余り紹介されていませんでした。そのため、この記事ではSentinel-2衛星とPythonライブラリ(Kerasとscikit-learn)によって3種類の手法(Neural network, Random forest, Support vector machine)を使った土地被覆分類の方法をご紹介したいと思います。
データ
ここで使用しているSentinel-2衛星画像(S2A_20210221_resampled.data、解像度10 mにリサンプリング処理済み)、及び訓練・テストデータ(DataBase.shp、6クラス700点)については、僕のGitHub上にあります。 追記:.cpg、.dbf、.shxファイルが不足していた為、これらを追加致しました。
対象領域の衛星画像(Sentinel-2衛星で撮影)はこんな感じです。

コード
必要なライブラリをインストールします。pipではgeopandasやrasterioのインストールで詰まった思い出があるので、Anacondaの実行環境を使うと楽だと思います。
import matplotlib.pyplot as plt
import numpy as np
import geopandas as gpd
import pandas as pd
import rasterio as rio
import pyproj
from pyproj import Proj
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from tqdm import tqdm
import keras
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation
from keras.optimizers import Adam
from sklearn.ensemble import RandomForestClassifier
from sklearn.svm import SVC
from PIL import Image
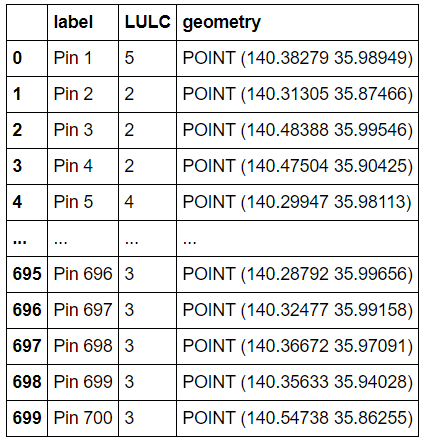
geopandasを使って訓練・テストデータの格納されたシェープファイルを読んでいきます。各点の緯度・経度と、その点における土地被覆クラスの番号が格納されています。土地被覆クラスと番号の対応関係は、以下の通りです。
0:裸地
1:都市域
2:農地
3:ソーラーパネル
4:植生
5:水域
DataBase=gpd.read_file("...\...\DataBase.shp")
DataBase
出力
衛星画像をArray形式で読み込みます。衛星画像処理ではgdalが有名ですが、pythonではgdalのC言語APIを引っ張ってきいるため、C言語譲りのポインタ処理がややこしいという問題があったりします。なので僕はrasterioを良く使っています。
# Sentinel-2衛星画像が格納されたフォルダへのパス
filepath="...\..."
NumOfClasses=6
# Array形式で読んだ画像を格納するリスト
S2Image=[]
# バンド名
BandNames=["B1","B2","B3","B4","B5","B6","B7","B8","B8A","B9","B11","B12"]
# バンド数
NumOfBands=len(BandNames)
for Band in BandNames:
ReadBand=rio.open(filepath+f"\S2A_20210221_resampled.data\{Band}.img")
ReadBandArray=ReadBand.read(1)
S2Image.append(ReadBandArray)
訓練・テストデータの位置は緯度経度表示なので、これを行列上の位置に変換する必要があります。Sentinel-2衛星画像はUTMへ投影されているため、先ず緯度経度からUTM座標に変換し、rasterioを使って行列上の位置を取得しています。
# 変換パラメータの取得
proj=((Proj(f"{ReadBand.crs}").definition_string()).split()[0]).replace("proj=","")
zone=int(((Proj(f"{ReadBand.crs}").definition_string()).split()[1]).replace("zone=",""))
ellps=((Proj(f"{ReadBand.crs}").definition_string()).split()[2]).replace("datum=","")
# 緯度経度からUTM座標変換への準備
p=Proj(proj=proj,zone=zone,ellps=ellps, preserve_units=False)
N=len(DataBase["label"])
# 各点におけるスペクトルデータを格納するリスト
spectrum_data=[]
for n in tqdm(range(N)):
#UTM座標の計算
UTMx,UTMy=p(DataBase["geometry"][n].x,DataBase["geometry"][n].y)
#行列上の位置の計算
x,y=ReadBand.index(UTMx,UTMy)
pixel_coords_on_matrix=(x,y)
#得られた行列上の位置におけるスペクトル情報を取得
spectrum_data_at_xy=[]
for m in range(NumOfBands):
spectrum_data_at_xy.append(S2Image[m][pixel_coords_on_matrix])
spectrum_data.append(spectrum_data_at_xy)
# 新たな列としてDataBaseに追加しておく
DataBase["Spectrum_data"]=spectrum_data
各点におけるスペクトル情報が得られたので、これらを訓練データとテストデータに分割しておきましょう。各クラスの20%をテストデータに配分しています。
trainData=[]
trainLabel=[]
testData=[]
testLabel=[]
for i in range(NumOfClasses):
Data_class_i=DataBase[DataBase["LULC"]==i]["Spectrum_data"]
Labels_class_i=DataBase[DataBase["LULC"]==i]["LULC"]
Data_train, Data_test, Label_train, Label_test = train_test_split(Data_class_i, Labels_class_i, test_size=0.2)
trainData.extend(Data_train)
trainLabel.extend(Label_train)
testData.extend(Data_test)
testLabel.extend(Label_test)
trainData=np.array(trainData)
testData=np.array(testData)
trainLabel=np.array(trainLabel)
testLabel=np.array(testLabel)
kerasを使ってNNのモデルを構築し、学習と精度検証を行います。テストデータと訓練データの組み合わせにも依りますが、何度か試した結果として精度は8割ちょいくらいかなと思います。
trainData_NN=np.array(trainData)
testData_NN=np.array(testData)
trainLabel_NN=keras.utils.to_categorical(trainLabel)
testLabel_NN=keras.utils.to_categorical(testLabel)
model=Sequential()
model.add(Dense(250,activation="relu",input_dim=12))
model.add(Dropout(0.1))
model.add(Dense(250,activation="relu"))
model.add(Dropout(0.1))
model.add(Dense(6,activation="softmax"))
adam=Adam(lr=0.001)
model.compile(loss="categorical_crossentropy",optimizer=adam,metrics=["accuracy"])
model.fit(trainData_NN,trainLabel_NN,epochs=500,batch_size=150,verbose=0)
loss,acc=model.evaluate(testData_NN,testLabel_NN)
print("The classification accuracy is {:.4f}".format(acc))
そこそこな精度が得られたので、学習済みのモデルを画像全体に適用します。各ピクセル毎に処理を行った場合はとんでもない時間(2~3時間)がかかったので、行毎に一括して処理を行っています。この変更を行った後は、処理時間は最速で2分未満になりました。
predicted_LULC_NN=[]
column_length=S2Image[0].shape[1]
for i in tqdm(range(S2Image[0].shape[0])):
spectrum_data_at_row_i=[]
for m in range(NumOfBands):
spectrum_data_at_row_i.append(S2Image[m][i])
spectrum_data_at_row_i_T=np.transpose(np.array(spectrum_data_at_row_i))
predicted_class=np.transpose(model.predict_classes(spectrum_data_at_row_i_T))
predicted_LULC_NN.append(predicted_class)
predicted_LULC_NN=np.array(predicted_LULC_NN).astype(np.uint8)
# 以下のコードを使うと、分類結果のうち任意のクラス(LULC_classを変えてください)についての結果が表示されます。
# LULC_class=5
# img=Image.fromarray(255*(predicted_LULC_NN==LULC_class).astype(np.uint8))
# img
tiff形式で保存しましょう。
OutputFilePath="...\...\Classified_NN.tif"
with rio.open(OutputFilePath,'w',driver='GTiff',width=ReadBand.width,height=ReadBand.height,count=1,crs=ReadBand.crs,transform=ReadBand.transform,dtype=np.uint8) as output:
output.write(predicted_LULC_NN,1)
output.close()
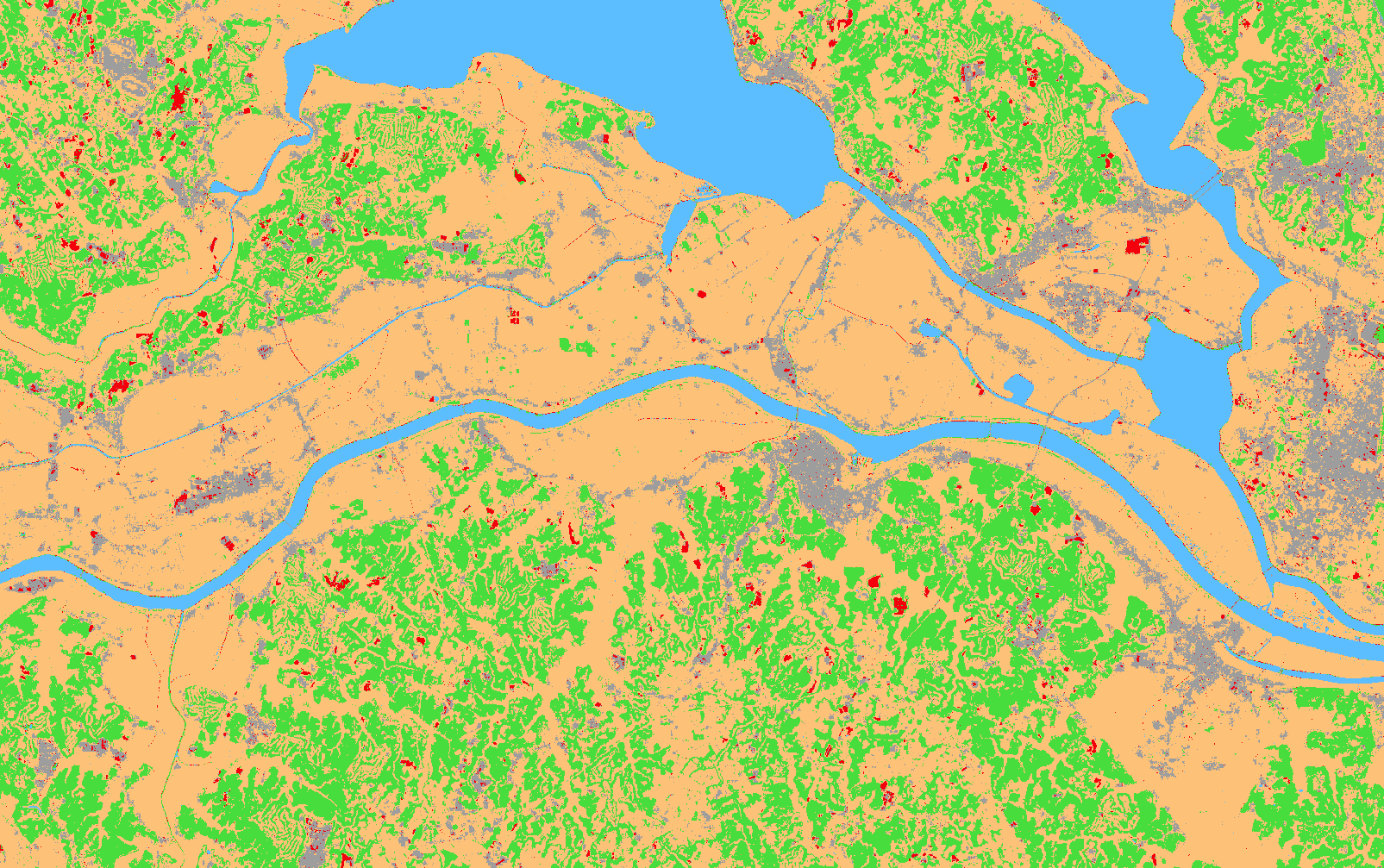
結果はこんな感じです。裸地(ゴルフ場、川岸など)が農地に誤分類されているのが気になりますが、おおよその傾向としてはそれっぽいのかなと思います。ソーラーパネルがやたら多いですが、都市域の真ん中のもの(誤分類)を除くと実際にあります。
濃橙色:裸地
灰色:都市域
肌色:農地
赤色:ソーラーパネル
緑色:植生
青色:水域
RF、SVMについても同様に分類していきましょう。テストデータへの分類精度についてはaccに格納されていますので、別途実行してください。
trainData_RF=np.array(trainData)
testData_RF=np.array(testData)
trainLabel_RF=keras.utils.to_categorical(trainLabel)
testLabel_RF=keras.utils.to_categorical(testLabel)
clf_RF=RandomForestClassifier(n_estimators=100)
clf_RF.fit(trainData_RF,trainLabel_RF)
pred_test=clf_RF.predict(testData_RF)
acc=np.sum(np.argmax(pred_test,axis=1)==np.argmax(testLabel_RF,axis=1))/(np.argmax(pred_test,axis=1).size)
predicted_LULC_RF=[]
column_length=S2Image[0].shape[1]
for i in tqdm(range(S2Image[0].shape[0])):
spectrum_data_at_row_i=[]
for m in range(NumOfBands):
spectrum_data_at_row_i.append(S2Image[m][i])
spectrum_data_at_row_i_T=np.transpose(np.array(spectrum_data_at_row_i))
predicted_class=clf_RF.predict(spectrum_data_at_row_i_T)
predicted_LULC_RF.append(np.argmax(predicted_class,axis=1))
predicted_LULC_RF=np.array(predicted_LULC_RF).astype(np.uint8)
OutputFilePath="...\...\Classified_RF.tif"
with rio.open(OutputFilePath,'w',driver='GTiff',width=ReadBand.width,height=ReadBand.height,count=1,crs=ReadBand.crs,transform=ReadBand.transform,dtype=np.uint8) as output:
output.write(predicted_LULC_RF,1)
output.close()
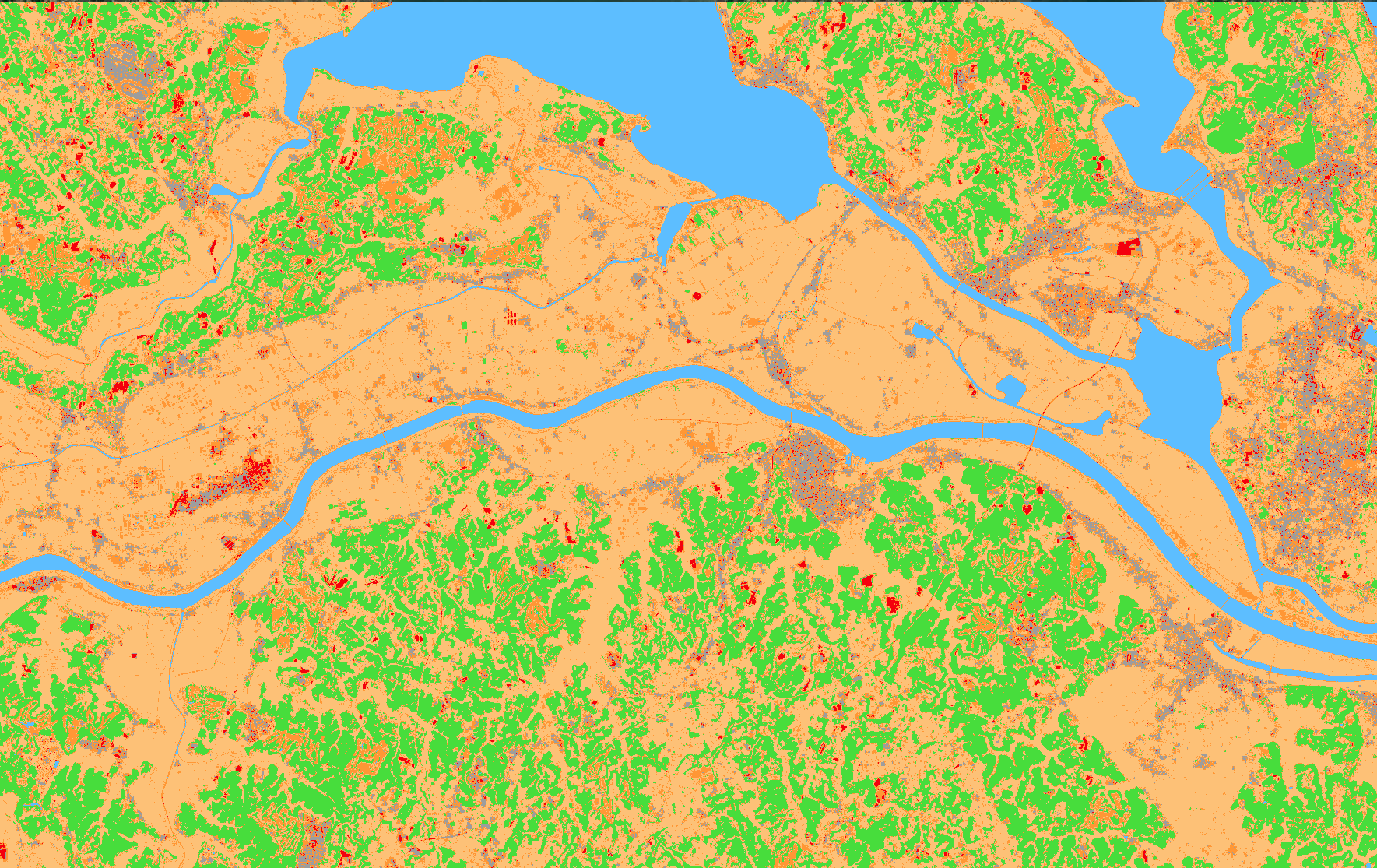
RF分類結果
裸地も検出出来ていて、いい感じです。
trainData_SVM=np.array(trainData)
testData_SVM=np.array(testData)
trainLabel_SVM=trainLabel
testLabel_SVM=testLabel
clf_SVM = SVC()
clf_SVM.fit(trainData_SVM, trainLabel_SVM)
pred_test= clf_SVM.predict(testData_SVM)
acc=np.sum(pred_test==testLabel_SVM)/(pred_test.size)
predicted_LULC_SVM=[]
column_length=S2Image[0].shape[1]
for i in tqdm(range(S2Image[0].shape[0])):
spectrum_data_at_row_i=[]
for m in range(NumOfBands):
spectrum_data_at_row_i.append(S2Image[m][i])
spectrum_data_at_row_i_T=np.transpose(np.array(spectrum_data_at_row_i))
predicted_class=np.transpose(clf_SVM.predict(spectrum_data_at_row_i_T))
predicted_LULC_SVM.append(predicted_class)
predicted_LULC_SVM=np.array(predicted_LULC_SVM).astype(np.uint8)
OutputFilePath="...\...\Classified_SVM.tif"
with rio.open(OutputFilePath,'w',driver='GTiff',width=ReadBand.width,height=ReadBand.height,count=1,crs=ReadBand.crs,transform=ReadBand.transform,dtype=np.uint8) as output:
output.write(predicted_LULC_SVM,1)
output.close()
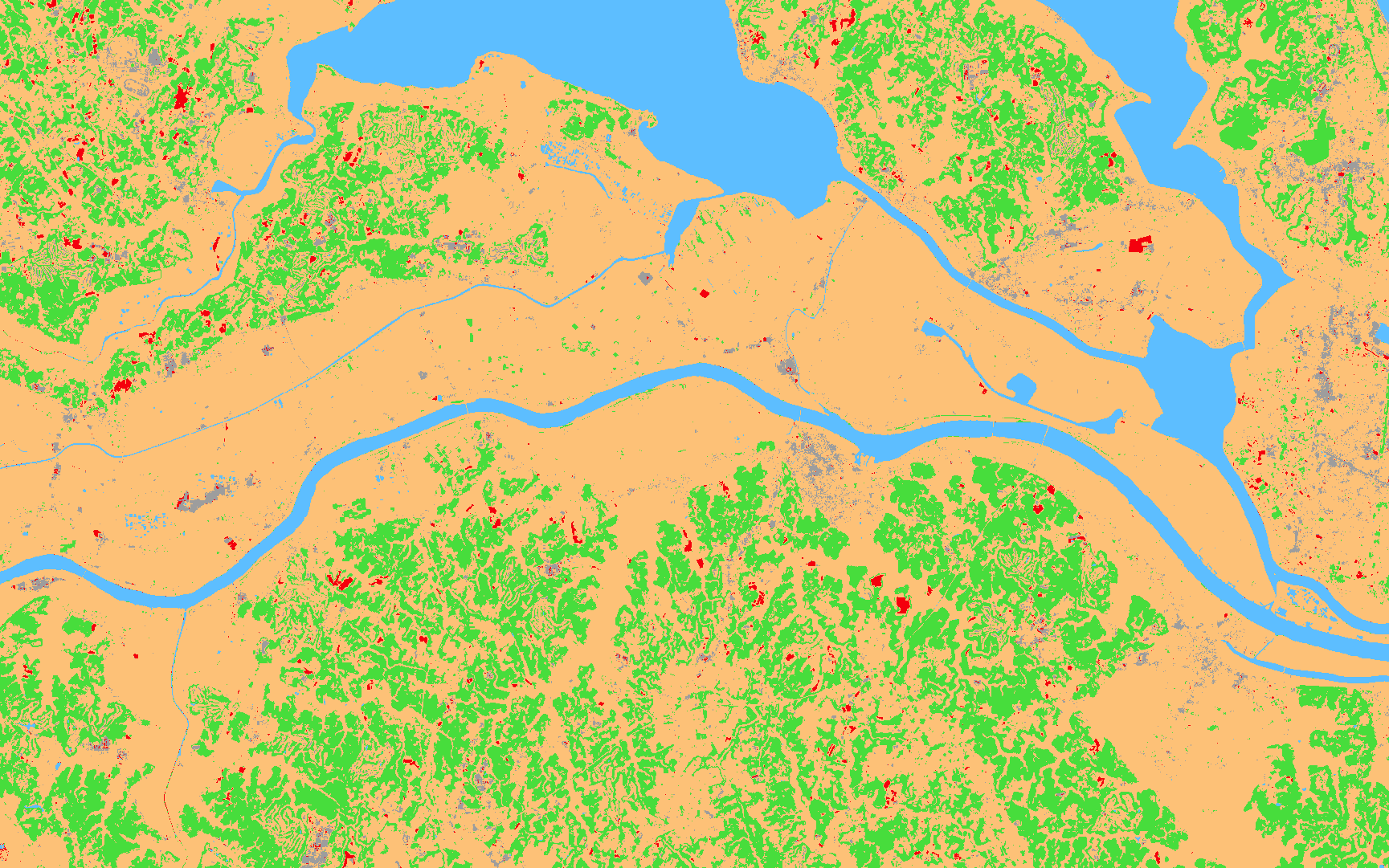
SVM分類結果
裸地、都市域のどちらも上手く検出出来ておらずRF,NNと比べると少々残念な結果になりましたが、おおよその土地被覆分類は行えていそうです。
本記事の内容については、以上となります。衛星画像と土地被覆に関心のある方がいらっしゃいましたら、ご参考に頂ければ幸いです!