はじめに
5年ほどまともな開発(≒プログラミング)から離れていたシステムエンジニアです。
久方ぶりにモノヅクリがしたいと殆ど開発経験のないJavaScript&APIの活用に挑んでいます。
生暖かい目でご覧ください。
目的
何をするにもやっぱり一人じゃ無理!ってことでQiitaには色々お世話になっています。
そのQiitaの偉大な先輩方は「どの辺に住んでいるんだろう?」ということで調べて行きます。
あと、**せっかくモノヅクリやるんだから発信していかないとね!**ということで、
Qiita投稿にも初挑戦です。
使用した環境
Visual Studio Code v1.55.2
node.js v15.12.0
axios v0.21.1
nodeplotlib v0.7.3
ユーザー情報を取得してみる
先ずはデータを見てみようということで、QiitaのAPI仕様を確認。
ユーザー情報の取得方法を探すと以下の記載がありました。
GET /api/v2/users
全てのユーザの一覧を作成日時の降順で取得します。
page
ページ番号 (1から100まで)
Example: 1
Type: string
Pattern: /^[0-9]+$/
per_page
1ページあたりに含まれる要素数 (1から100まで)
Example: 20
Type: string
Pattern: /^[0-9]+$/
GET /api/v2/users?page=1&per_page=20 HTTP/1.1
Host: api.example.com
とりあえず1件取得してみます。
const axios = require('axios');
async function main() {
let response = await axios.get('https://qiita.com/api/v2/users?page=1&per_page=1');
console.log(response.data);
}
main();
取得したデータを確認すると、ほとんど何も入っていない・・・
作成日の降順でしか取得できないので、同じようなデータが続きそうですね。
なので、居住地が入ってるユーザーをピンポイントで抜き出すことを考えました。
それなりに読まれている記事を書いているユーザーの方が期待値が高いだろうということで、
記事のストック数で条件を付けて抜き出してみました。
書いたコードは以下の通りです。
const axios = require('axios');
const api_token = [自分のAPIトークン];
const per_page = 100;
const fs = require('fs');
async function main() {
var users = new Array();
for(let page=1;page<=100;page++){
//ストック数500以上の記事を取得
let response = await axios.get('https://qiita.com/api/v2/items?page=' + page + '&per_page=' + per_page + '&query=stocks:' + encodeURIComponent('>=500'),{headers:{Authorization: 'Bearer ' + api_token}});
//取得した記事データ分繰り返し
for(item of response.data){
//記事の投稿者でユニークにしつつ、居住地が入っていないデータを除く
if(users.indexOf(item.user.id)==-1 && item.user.location){
//配列にIDを追加
users.push(item.user.id);
//ファイルにIDと居住地を書き出し
try{
fs.appendFileSync("qiita_users.csv",item.user.id + "," + item.user.location + "\n");
}catch(e){
console.log(e);
}
}
}
}
};
main();
これで750件程度の居住地入りユーザー情報を取得することができました。
可視化と考察
可視化にはnodeplotlibを使いました。
※参考にした記事はこちら
Node.jsでお手軽グラフ表示
どんなデータが入っているかをヒストグラム形式で可視化してみます。
const npl = require('nodeplotlib');
const csvSync = require('csv-parse/lib/sync');
const fs = require('fs');
//CSVファイルを読み込む
let data = fs.readFileSync('qiita_users.csv');
let res = csvSync(data, {
columns: true,
skip_empty_lines: true
});
let locations = new Array();
//居住地を配列に格納
for(item of res){
locations.push(item.location.trim());
};
//ヒストグラム形式に設定
const hist = [{
x:locations,
type: 'histogram'
}];
//描画
npl.stack(hist);
npl.plot();
結果はこのようになりました。
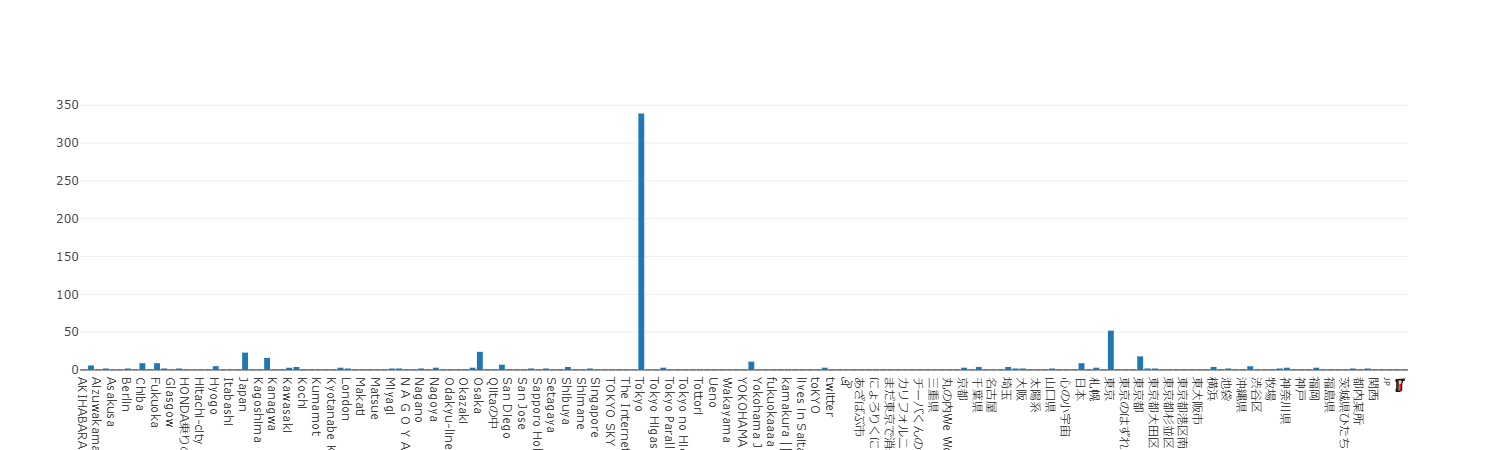
圧倒的東京率ですね。
「Tokyo」が多いのに加えて、「Tokyo~」や「東京~」みたいなのもあって、これらを統合するとかなりの割合を東京在住の方が占めているようです。
東京以外だと大阪や神奈川の方が多いようです。海外の方も居ますね。
個人的に気になったのが以下の3つ。遊び心に溢れていてステキです。
・心の小宇宙・・・聖闘士の方でしょうか。
・あざばぶ市・・・ぷりきゅあでしたか。。。ここは守備範囲外ですね。
・のんほいパーク・・・愛知県豊橋市にある動植物園らしいです。私はお隣の三重県出身なのですが知りませんでした。
最後に
久しぶりのプログラミングで中々大変でしたが非常に楽しかったです。
今回はヒストグラムにして終わりましたが、折角居住地を取ったので地図を使った可視化にもチャレンジしてみたいですね。