はじめに
現状(2019/7/14)、gRPCを使ったkubernetes上のアプリケーションは、Envoy => application という構成で通信するようになっていることが多いです。なぜこのような構成になっているのか自分で調べたことをまとめました。自分もまだまだ詳しくないので、フィードバックを頂けると嬉しいです。
ロードバランサーの概要
ロードバランサーの役割
ここでのロードバランサーはネットワーク経由でのタスクの割り当てを、複数のバックエンドサーバーに分散させる仕組み(ロードバランシング)を提供します。
それだけでなく、利用可能なバックエンドサーバーのIPアドレスを管理することで、クライアントはぞれぞれについて知る必要がなくなり、ロードバランサーのDNS名やIPアドレス、ポートを知っていれば通信が可能になります。(サービスディスカバリー)さらに、リクエストに応答可能かを確認し、利用可能なバックエンドサーバーにのみ通信を送ることで、不具合のあるバックエンドサーバーにリクエストが送られないようにすることができます(ヘルスチェッキング)。
そして、ロードバランサーには主にL4とL7という二つのカテゴリーがあります。
LはOSI参照モデルにおけるLayerを意味し、L4はトランスポート層、L7はアプリケーション層を示します。
それぞれのロードバランサーによってどのデータの単位で通信を分散させるかが変わってきます。
L4ロードバランサー
L4ロードバランサーはTCP/UDPのレベルでつまり、パケット単位でロードバランシングをします。
従って、L4ロードバランサーはL7におけるアプリケーションデータの中身には関知しません。
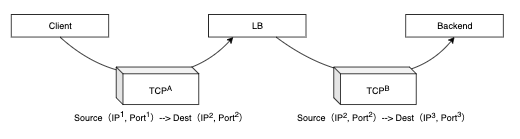
また、TCPの場合はコネクションが続く限りは同じバックエンドサーバーにパケットが送られます。
なぜなら、そうしないとSYN, SYN/ACK, ACKパケットを交換し、シーケンス番号を増分しながら通信ができないからです。
しかし、このようなL4ロードバランサーの特性が欠点になることがあります。
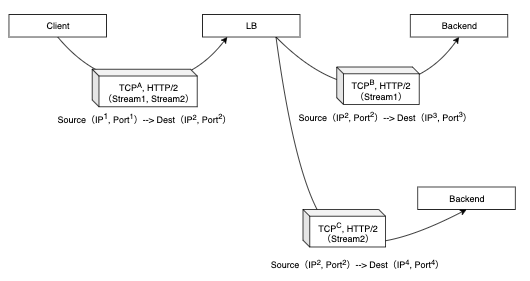
例えば、gRPCのようなHTTP/2による通信では、一つのTCPコネクションでHTTPレベルでのリクエスト/レスポンスを多重化することができます。
これは、バイナリフォーマットでHTTPのメソッド、ヘッダ、ボディなどの構成要素がHTTPのレイヤーにおいて表現される(バイナリフレーミング)ためです。
そして、一つのTCPコネクションにおいて、ストリームという双方向の論理的なフレームのまとまりを使って、アプリケーションデータの通信の状態を管理したり、優先順位をつけたりします。
そうすると、一つのコネクション上に三つのストリームが多重化されている場合でも、一つのバックエンドサーバーに全てが送られることになります。
これは、keep-aliveなどのTCPコネクションの使い回しの場合にも同じことが起こります。
gRPCやHTTP/2については、こちらの記事で詳しく説明しました。
L7ロードバランサー
上記の問題に対処するには、L7ロードバランサーが有効です。
L7ロードバランサーは一つのTCPコネクションにアプリケーションデータが多重化されている場合でも、アプリケーションデータ単位でバックエンドサーバーにTCPコネクションを接続し直し、通信を分散させることができます。
参考
- https://blog.envoyproxy.io/introduction-to-modern-network-load-balancing-and-proxying-a57f6ff80236
- https://www.atmarkit.co.jp/ait/articles/0302/05/news001.html
kubernetesにおけるロードバランシング
Serviceの仕組み
kubernetesのPodはデプロイなどで入れ替わるものであり、それぞれのPodはIPアドレスを持っています。
そのため、直接Podと通信するクライアントは動的に変わるPodのIPアドレス一覧を常に監視、更新する必要に迫られます。
ServiceはそのようなPodへのアクセス方法を抽象化する責務を担っています。
具体的には、クラスタIPというクラスタ内で一意の仮想IPアドレスを持ち、クライアントがこのIPアドレスにリクエストすると、予め指定されたラベルをもつPodの集合の一つにルーティングします。
仮想IPアドレスとは、実際のNetwork Interfaceに接続されたIPアドレスではないことを意味します。
そして、このServiceの仕組みを実現するために、kube-proxyがServiceのクラスタIPへのトラフィックをPodのIPアドレスの一覧のいずれかにルーティングします。
kube-proxyはノードごとに存在するkubernetesのコンポーネントの一種(Node Component)です。
kube-proxyのproxy方法はバージョンによって変わりますが、現在(2019/7/14)ではiptables proxy modeが広く利用されています。
ServiceやPodsに割り当てられたIPアドレスをkubernetesのコントロールプレーンの一つのEndpointsContollerがEndpointsオブジェクトとして管理しています。
iptables proxy mode の場合、kube-proxyはAPI経由でそれらを問い合わせて、Serviceの追加、削除や正常なPodのIPアドレスを確認し、ノードのiptablesに対してルールを追加および削除します。
そして、ServiceのClusterIPと正常なPodのIPアドレスをマッピングします。ClusterIPにリクエストされると、ランダムにPodのIPアドレスを選択し、ルーティングします。
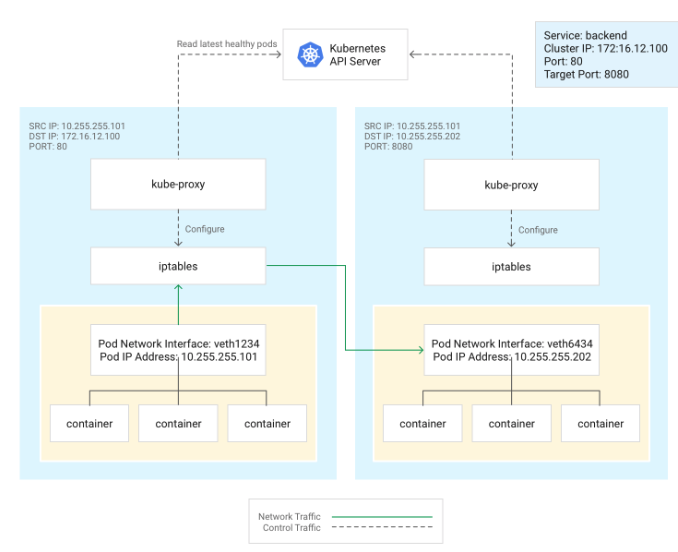
こちらの記事の画像を参照しています。
実際に確認してみます。
適当なPodを三つ作成します。
それぞれのPodにIPアドレスが割り当てられていることが確認できます。
$ kubectl create hello-minikube --image=k8s.gcr.io/echoserver:1.10
deployment.apps/hello-minikube created
$ kubectl scale --replicas=3 deployment hello-minikube
deployment.extensions/hello-minikube scaled
$ kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
hello-minikube-856979d68c-5lc8n 1/1 Running 0 86m 172.17.0.8 minikube <none> <none>
hello-minikube-856979d68c-692mk 1/1 Running 0 86m 172.17.0.7 minikube <none> <none>
hello-minikube-856979d68c-kzjb5 1/1 Running 0 86m 172.17.0.9 minikube <none> <none>
Serviceを作成すると、先ほどのPodのIPアドレスがEndpointsに登録されています。
$ kubectl expose deployment hello-minikube --port=80
service/hello-minikube exposed
$ kubectl describe service hello-minikube
Name: hello-minikube
Namespace: default
Labels: run=hello-minikube
Annotations: <none>
Selector: run=hello-minikube
Type: ClusterIP
IP: 10.104.86.8
Port: <unset> 80/TCP
TargetPort: 80/TCP
Endpoints: 172.17.0.7:80,172.17.0.8:80,172.17.0.9:80
Session Affinity: None
Events: <none>
次に、kube-proxyのPodに入り、iptablesの設定を確認します。
$ kubectl --namespace kube-system get pods
NAME READY STATUS RESTARTS AGE
...
kube-proxy-lc84b 1/1 Running 0 137m
$ kubectl --namespace kube-system exec -it kube-proxy-lc84b -- /bin/sh
# iptables -t nat -L KUBE-SERVICES // serviceに関するルールの一覧を見ると、hello-minikubeのクラスタIP(10.104.86.8)に関するルールが含まれている
Chain KUBE-SERVICES (2 references)
target prot opt source destination
...
KUBE-SVC-OJVYVGJ6XUZQDPN7 tcp -- anywhere 10.104.86.8 /* default/hello-minikube: cluster IP */ tcp dpt:http
# iptables -t nat -L KUBE-SVC-OJVYVGJ6XUZQDPN7 // そのルールでは、33.3%の確率でKUBE-SEP-EQE5Q6T32QGIM6VXというルールを使用する設定になっている
Chain KUBE-SVC-OJVYVGJ6XUZQDPN7 (1 references)
target prot opt source destination
KUBE-SEP-EQE5Q6T32QGIM6VX all -- anywhere anywhere statistic mode random probability 0.33332999982
KUBE-SEP-KGLS4AVE3VFMR2HX all -- anywhere anywhere statistic mode random probability 0.50000000000
KUBE-SEP-FFO3E7UZY73I7HTC all -- anywhere anywhere
# iptables -t nat -L KUBE-SEP-EQE5Q6T32QGIM6VX // そのルールは送信先のIPアドレスをPodのIPアドレス(172.17.0.7)の80番ポートへ変換する設定(DNAT)になっている
Chain KUBE-SEP-EQE5Q6T32QGIM6VX (1 references)
target prot opt source destination
...
DNAT tcp -- anywhere anywhere tcp to:172.17.0.7:80
このように、kubernetesのServiceはiptablesでNATを用い、クラスタIPをランダムに特定のPodのIPアドレスに書き換えることで、ロードバランスを実現しています。
したがって、kubernetesのServiceはL4ロードバランサーであることがわかります。
これは、上述のようにHTTP/2における一つのTCPコネクションに多重化されたリクエストを分散できない問題に直面します。
この問題を解消するために、EonvyなどのL7ロードバランサーを使います。
EnvoyをHeadless Serviceと使う
EnvoyはL4/L7の両方に対応したロードバランサーです。HTTP/2やgRPCのロードバランシングにも対応しています。
高いパフォーマンスが出せるようにC++で実装されています。またEnvoyはサイドカーパターンでも利用されます。
c.f https://www.envoyproxy.io/
クライアントサイドでのロードバランシングや他のロードバランサーとの比較はBugsnagでEnvoyを導入した記事に分かりやすくまとめられています。
kubernetes上でEnvoyを使って、HTTP/2のロードバランスを行うにはHeadless Serviceと併用することで、Envoyから直接、PodにL7ロードバランスすることができます。
Healess Serviceは、kube-proxyの管理の対象外になり、iptablesによるロードバランスはされません。
そして、対象とするPodのラベルが指定されている場合は、Headless ServiceのDNS名を問い合わせると、APIサーバー経由で、それらのPodのIPアドレス一覧が返ってきます。
EnvoyではこのHeadless ServiceのDNS名を使ってService Discoveryをし、直接Podへロードバランスします。
実際に、Headless Serviceを作って、Podの中からServiceを名前解決するとPodのIPアドレス一覧が返ってきます。
# dig hello-minikube.default.svc.cluster.local +short
172.17.0.7
172.17.0.8
172.17.0.9