この記事は、CyberAgent Developers Advent Calendar 2020 の23日目の記事です。
CDKとは
CDKとはAWSの構成管理をjs製のコマンドと、TypeScriptやPythonなどのプログラミング言語で利用することができるCloudFormationAPIのラッパーライブラリです。
書き慣れている言語で記述できるため、YAMLやJSONでの構成管理に慣れていないサーバーサイドエンジニアにもとっつきやすく、サーバーサイドエンジニアにインフラ管理も任せていきたい、というプロジェクトにおすすめです。
また、抽象化や共通化ができるため、幅広い表現が可能です。
今回は、そんなSDKでStepFunctionsの構成管理をした際に使用した、初歩的な部分から、ちょっと突っ込んだ部分までを書いていきたいと思います。
CDK + Python + StepFunctions
CDKの基本的な書き方については、githubのgetting-started 等を参照してください。
本記事では、StepFunctionsを扱う部分にスコープして記述して行きます。
StepFunctionsをデプロイする
まず、基本的な書き方は下記のようになります。
from aws_cdk import (
core,
aws_lambda as lambdas,
aws_stepfunctions_tasks as tasks,
aws_stepfunctions as sf
)
class SampleStack(core.Stack):
def __init__(self,
scope: core.Construct,
id: str,
**kwargs) -> None:
super().__init__(scope, id, **kwargs)
hello_lambda: lambdas.Function = # Lambdaの定義
hello_task: tasks.LambdaInvoke = tasks.LambdaInvoke(self,
"[Lambda] hello",
lambda_function=hello_lambda)
world_lambda: lambdas.Function = # Lambdaの定義
world_task: tasks.LambdaInvoke = tasks.LambdaInvoke(self,
"[Lambda] world",
lambda_function=world_lambda)
definition: sf.Chain = hello_task.next(world_task)
sf.StateMachine(self, "hello_workflow", definition=definition)
上記のコードでは、
- 必要なリソースの定義
- リソースを実行するtaskの定義
- workflowの定義
- StateMachineの定義
が行われています。
生成されたワークフロー
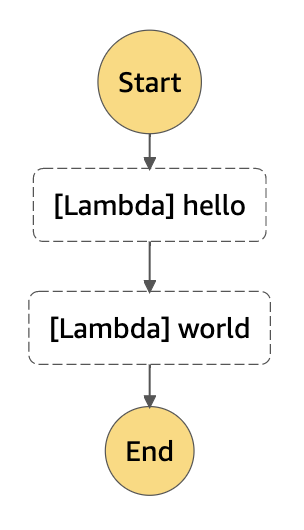
値の受け渡し
各タスクへのタスクの受け渡しは下記のように記述します。
from aws_cdk import (
core,
aws_stepfunctions_tasks as tasks,
aws_stepfunctions as sf
)
class SampleStack(core.Stack):
def __init__(self,
scope: core.Construct,
id: str,
**kwargs) -> None:
super().__init__(scope, id, **kwargs)
hello_lambda: lambdas.Function = # Lambdaの定義
hello_task: tasks.LambdaInvoke = tasks.LambdaInvoke(self,
"[Lambda] hello",
lambda_function=hello_lambda,
result_path="$.helloLambda")
world_lambda: lambdas.Function = # Lambdaの定義
world_task: tasks.LambdaInvoke = tasks.LambdaInvoke(self,
"[Lambda] world",
lambda_function=world_lambda,
payload=sf.TaskInput.from_json_path_at("$.helloLambda.Payload"))
definition: sf.Chain = sf.Chain.start(hello_task).next(world_task)
sf.StateMachine(self, "hello_workflow", definition=definition)
StepFunctionではresult_pathを記載することで、jsonに対して実行結果を追加することができます。
このように記述することで、hello_task の実行結果を world_task に渡すことができます。
詳しくは、StepFunctionsの公式ドキュメント を参照してください。
エラーハンドリング
add_catch を利用することでエラーの通知等を楽に行える。
$$.Execution.id , $.Error, $.Cause 等を出力すると原因の究明、再実行等が楽に行えるのでおすすめです。
from aws_cdk import (
core,
aws_lambda as lambdas,
aws_stepfunctions_tasks as tasks,
aws_stepfunctions as sf
)
class SampleStack(core.Stack):
def __init__(self,
scope: core.Construct,
id: str,
**kwargs) -> None:
super().__init__(scope, id, **kwargs)
hello_lambda: lambdas.Function = # Lambdaの定義
hello_task: tasks.LambdaInvoke = tasks.LambdaInvoke(self,
"[Lambda] hello",
lambda_function=hello_lambda,
result_path="$.helloLambda")
world_lambda: lambdas.Function = # Lambdaの定義
world_task: tasks.LambdaInvoke = tasks.LambdaInvoke(self,
"[Lambda] world",
lambda_function=world_lambda,
payload=sf.TaskInput.from_json_path_at("$.helloLambda.Payload"))
notification_error: lambdas.Function = # lambdaの定義
execution_id: str = sf.TaskInput.from_data_at("$$.Execution.Id").value
err: str = sf.TaskInput.from_data_at("$.Error").value
cause: str = sf.TaskInput.from_data_at("$.Cause").value
notification_error_task: tasks.LambdaInvoke = tasks.LambdaInvoke(self,
"[Lambda] notification_error",
lambda_function=notification_error,
payload=sf.TaskInput.from_object({
"execution_id": execution_id,
"error": err,
"cause": cause
}))
job_failed: sf.Fail = sf.Fail(self,
"Job Failed",
cause="Job Failed",
error="Workflow FAILED")
error_handler: sf.Chain = notification_error_task.next(job_failed)
hello_task.add_catch(error_handler, errors=['States.ALL'])
world_task.add_catch(error_handler, errors=['States.ALL'])
definition: sf.Chain = sf.Chain.start(hello_task).next(world_task)
sf.StateMachine(self, "hello_workflow", definition=definition)
気を付けるポイントがいくつかあります。
- エラーハンドリング用のタスクの後に、
.next()でsf.Failを紐づけてあげないと、StepFunctions上で成功判定になってしまいます。 -
notification_error_task.next(job_failed)をそれぞれのところで書いてしまうと、Error: State '[Lambda] notification_error' already has a next stateとなってしまいます。
生成されたワークフロー
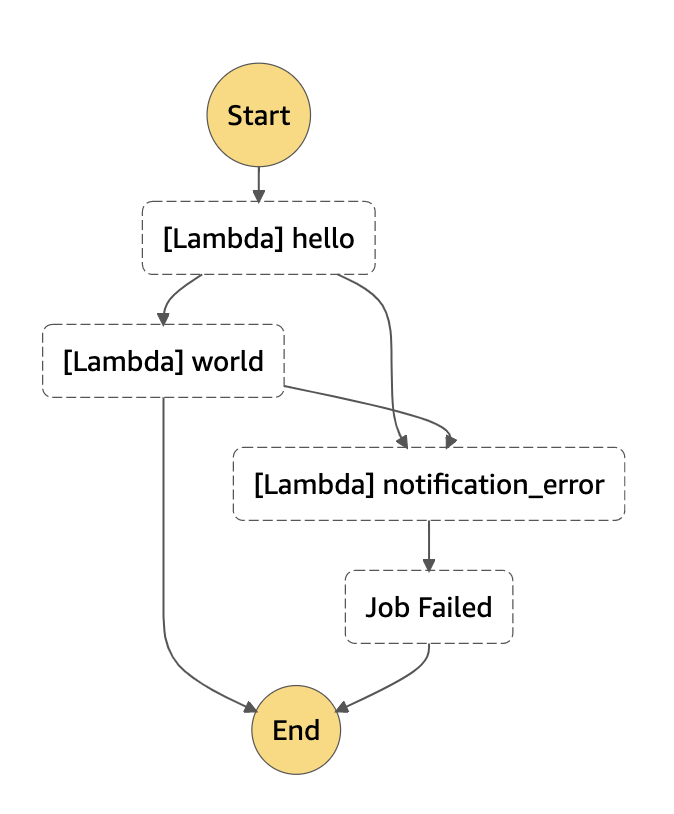
パラレルを使ってエラーハンドリングをきれいに書く
上記の方法でもエラーハンドリングができますが、sf.Parallel を利用するともう少しきれいに書けます。
from aws_cdk import (
core,
aws_lambda as lambdas,
aws_stepfunctions_tasks as tasks,
aws_stepfunctions as sf
)
class SampleStack(core.Stack):
def __init__(self,
scope: core.Construct,
id: str,
**kwargs) -> None:
super().__init__(scope, id, **kwargs)
hello_lambda: lambdas.Function = # Lambdaの定義
hello_task: tasks.LambdaInvoke = tasks.LambdaInvoke(self,
"[Lambda] hello",
lambda_function=hello_lambda,
result_path="$.helloLambda")
world_lambda: lambdas.Function = # Lambdaの定義
world_task: tasks.LambdaInvoke = tasks.LambdaInvoke(self,
"[Lambda] world",
lambda_function=world_lambda,
payload=sf.TaskInput.from_json_path_at("$.helloLambda.Payload"))
notification_error: lambdas.Function = # lambdaの定義
execution_id: str = sf.TaskInput.from_data_at("$$.Execution.Id").value
err: str = sf.TaskInput.from_data_at("$.Error").value
cause: str = sf.TaskInput.from_data_at("$.Cause").value
notification_error_task: tasks.LambdaInvoke = tasks.LambdaInvoke(self,
"[Lambda] notification_error",
lambda_function=notification_error,
payload=sf.TaskInput.from_object({
"execution_id": execution_id,
"error": err,
"cause": cause
}))
job_failed: sf.Fail = sf.Fail(self,
"Job Failed",
cause="Job Failed",
error="Workflow FAILED")
definition: sf.Chain = sf.Chain.start(hello_task).next(world_task).to_single_state("definition")
definition.add_catch(notification_error_task.next(job_failed))
sf.StateMachine(self, "hello_workflow", definition=definition)
このように定義することで、Parallelの中のタスクのどれかが失敗した場合にハンドリングをしてくれます。
生成されたワークフロー
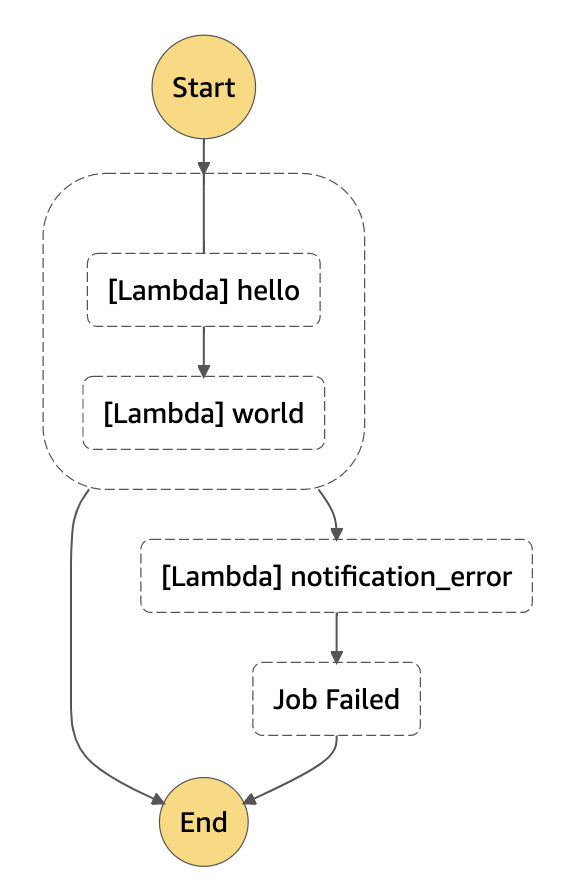
条件分岐
sf.Choice を利用することで条件分岐を実装できます。
複数の条件分岐を書こうと思うと見づらくなりそうですが、その辺りはあえてそうなるようにしたのかなと感じています。
from aws_cdk import (
core,
aws_lambda as lambdas,
aws_stepfunctions_tasks as tasks,
aws_stepfunctions as sf
)
class SampleStack(core.Stack):
def __init__(self,
scope: core.Construct,
id: str,
**kwargs) -> None:
super().__init__(scope, id, **kwargs)
hello_or_world: lambdas.Function = # Lambdaの定義
hello_or_world_task: tasks.LambdaInvoke = tasks.LambdaInvoke(self,
"[Lambda] hello or world",
lambda_function=hello_or_world,
result_path="$helloOrWorld")
hello_lambda: lambdas.Function = # Lambdaの定義
hello_task: tasks.LambdaInvoke = tasks.LambdaInvoke(self,
"[Lambda] hello",
lambda_function=hello_lambda)
world_lambda: lambdas.Function = # Lambdaの定義
world_task: tasks.LambdaInvoke = tasks.LambdaInvoke(self,
"[Lambda] world",
lambda_function=world_lambda)
job_failed: sf.Fail = sf.Fail(self,
"Job Failed",
cause="Job Failed",
error="Workflow FAILED")
definition: sf.Chain = sf.Chain.start(hello_or_world_task)\
.next(
sf.Choice(self, "hello or world ?")
.when(sf.Condition.string_equals("$.helloOrWorld.Payload", "hello"), hello_task)
.when(sf.Condition.string_equals("$.helloOrWorld.Payload", "world"), world_task)
.otherwise(job_failed)
)
sf.StateMachine(self, "hello_workflow", definition=definition)
生成されたワークフロー
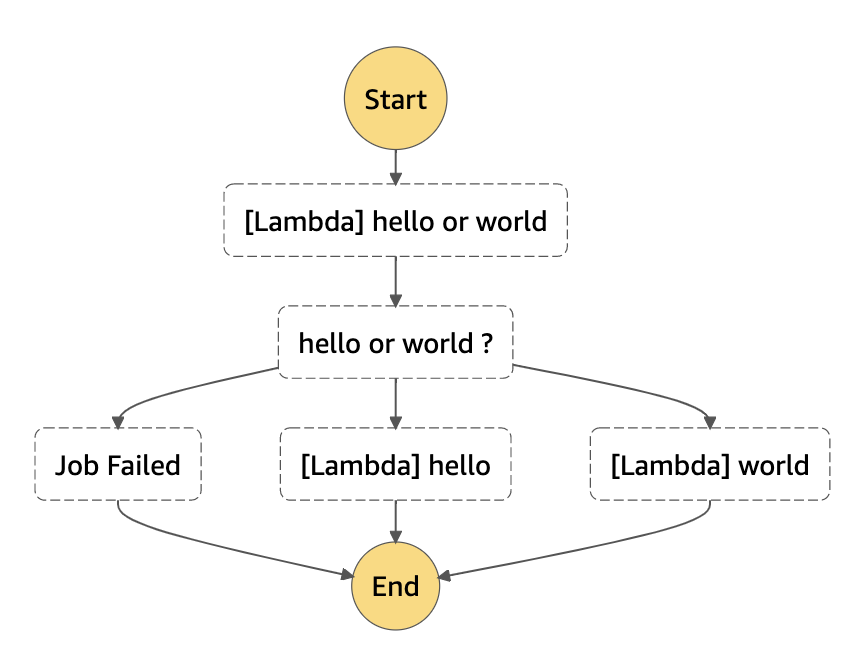
ハマりどころ
result_pathをちゃんと設定する
とても単純なことですが、result_path をうっかり定義し忘れていると、前段階で演算した結果が全部上書きされるので注意しましょう。
型を無理やり回避する
今回触ってみて、一番困ったのがこれです。
StepFunctionsからEMRのタスクを実行(EMRではEmrAddStep)しようとした時に、引数を配列で渡します。
args=[
"spark-submit",
"--deploy-mode",
"cluster",
"--master",
"yarn",
"--class",
"Main",
"hoge.jar",
"2020/12/23/01",
"--tz",
"utc"
]
例えば、その中に前段階の処理結果を渡そうとすると、
args: typing.Optional[typing.List[str]]
なので、怒られます。
そのため、いったん適当な文字列を入れて、
args=[
"<$.hoge.Payload>"
],
あとで定義を文字列に起こして、Lambdaで整形した結果と置換しています。
(もっといい方法があれば教えてください。)
prerpare_workflow: sf.Chain = sf.Chain.start(emr_create_cluster).next(emr_add_step)
definition: sf.Parallel = sf.Parallel(self, id="definition")
definition.branch(prerpare_workflow)
definition_json = definition.to_state_json()["Branches"][0]
definition_str = json.dumps(definition_json) \
.replace('"Args": ["<$.hoge.Payload>"]',
'"Args.$": "$.hoge.Payload"', 1)